一、malloc申请内存过程
malloc() 并不是系统调用,也不是运算符,而是 C 库里的函数,用于动态分配内存。
malloc申请内存的时候,会有两种方式向操作系统申请堆内存:
- 方式一:通过brk()系统调用从堆分配内存。
- 方式二:通过mmap()系统调用在文件映射区域分配内存。
二、brk()系统调用
2.1 brk()的申请方式
般如果用户分配的内存小于 128 KB,则通过 brk() 申请内存。而brk()的实现的方式很简单,就是通过 brk() 函数将堆顶指针向高地址移动,获得新的内存空间。如下图:
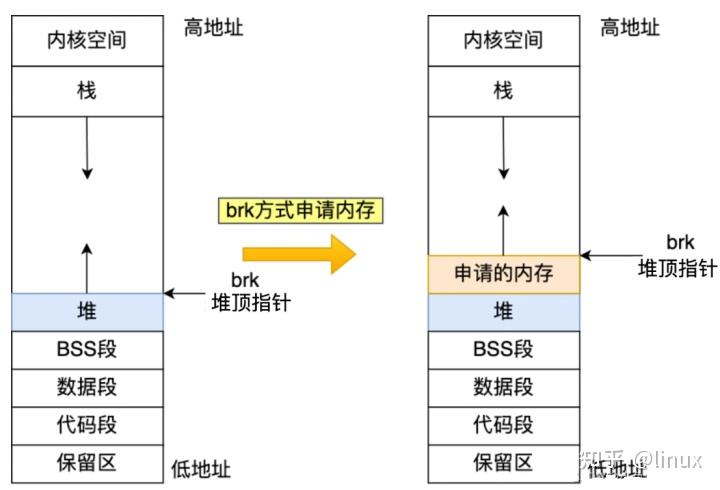
malloc通过brk()方式申请的内存,free释放内存的时候,并不会把内存归还给操作系统,而是缓存在malloc的内存池中,以便可以重复使用。
2.2 brk()系统调用的优缺点
优点:可以减少缺页异常的发生,提高内存访问效率。
缺点:由于申请的内存没有归还系统,频繁的内存分配和释放会造成内存碎片。brk()方式之所以会产生内存碎片,是由于brk通过移动堆顶的位置来分配内存,并且使用完不会立即归还系统,如果高地址的内存不释放,低地址的内存是得不到释放的。
为了解决使用brk()会出现内存碎片,在申请大块内存的时候才会使用mmap()方式,mmap()是以页为单位进行内存分配和管理的,释放后就直接归还系统了,不会出现这种小碎片的情况。
三、ptmalloc
ptmalloc 是我们当前使用的glibc malloc版本。
3.1 多线程支持
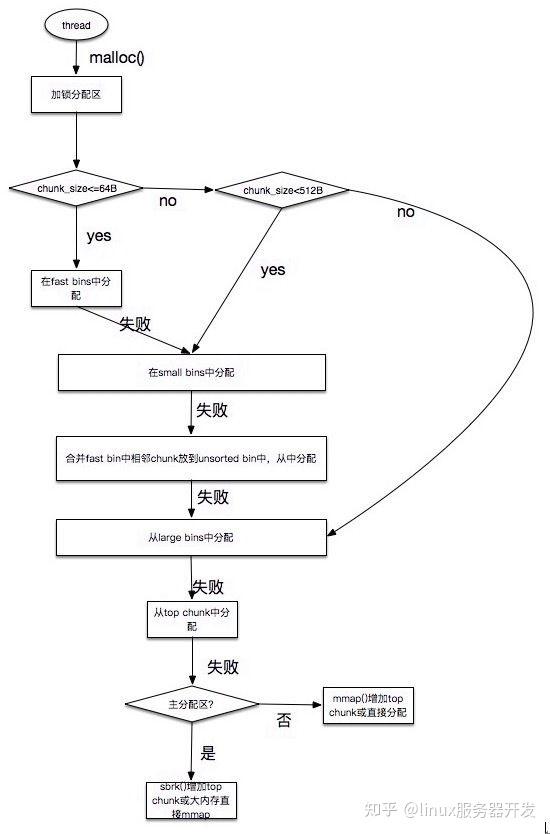
- Ptmalloc2有一个主分配区(main arena), 有多个非主分配区。 非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。 当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。
- free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的开销就会增大。
3.2 内存管理
- 用户请求分配的内存在ptmalloc中使用chunk表示, 每个chunk至少需要8个字节额外的开销。 用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。
- ptmalloc 将相似大小的 chunk 用双向链表链接起来, 这样的一个链表被称为一个 bin。Ptmalloc 一共 维护了 128 个 bin,并使用一个数组来存储这些 bin(如下图所示)。

数组中的第一个为 unsorted bin, 数组中从 2 开始编号的前 64 个 bin 称为 small bins, 同一个small bin中的chunk具有相同的大小。small bins后面的bin被称作large bins. - 当free一个chunk并放入bin的时候, ptmalloc 还会检查它前后的 chunk 是否也是空闲的, 如果是的话,ptmalloc会首先把它们合并为一个大的 chunk, 然后将合并后的 chunk 放到 unstored bin 中。 另外ptmalloc 为了提高分配的速度,会把一些小的(不大于64B) chunk先放到一个叫做 fast bins 的容器内。
- 在fast bins和bins都不能满足需求后,ptmalloc会设法在一个叫做top chunk的空间分配内存。 对于非主分配区会预先通过mmap分配一大块内存作为top chunk, 当bins和fast bins都不能满足分配需要的时候, ptmalloc会设法在top chunk中分出一块内存给用户, 如果top chunk本身不够大, 分配程序会重新mmap分配一块内存chunk, 并将 top chunk 迁移到新的chunk上,并用单链表链接起来。如果free()的chunk恰好 与 top chunk 相邻,那么这两个 chunk 就会合并成新的 top chunk,如果top chunk大小大于某个阈值才还给操作系统。主分配区类似,不过通过sbrk()分配和调整top chunk的大小,只有heap顶部连续内存空闲超过阈值的时候才能回收内存。
- 需要分配的 chunk 足够大,而且 fast bins 和 bins 都不能满足要求,甚至 top chunk 本身也不能满足分配需求时,ptmalloc 会使用 mmap 来直接使用内存映射来将页映射到进程空间。
3.3 ptmalloc 分配流程
3.4 ptmalloc的缺点
- 多线程锁开销大, 需要避免多线程频繁分配释放。
- 后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
- 内存从thread的areana中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。 比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用了。
- 每个chunk至少8字节的开销很大
- 不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值。
四、tcmalloc
tcmalloc是Google开源的一个内存管理库, 作为glibc malloc的替代品。
4.1 小对象分配
- tcmalloc为每个线程分配了一个线程本地ThreadCache,小内存从ThreadCache分配,此外还有个中央堆(CentralCache),ThreadCache不够用的时候,会从CentralCache中获取空间放到ThreadCache中。
- 小对象(<=32K)从ThreadCache分配,大对象从CentralCache分配。大对象分配的空间都是4k页面对齐的,多个pages也能切割成多个小对象划分到ThreadCache中。
小对象有将近170个不同的大小分类(class),每个class有个该大小内存块的FreeList单链表,分配的时候先找到best fit的class,然后无锁的获取该链表首元素返回。如果链表中无空间了,则到CentralCache中划分几个页面并切割成该class的大小,放入链表中。
4.2 CentralCache分配管理
-
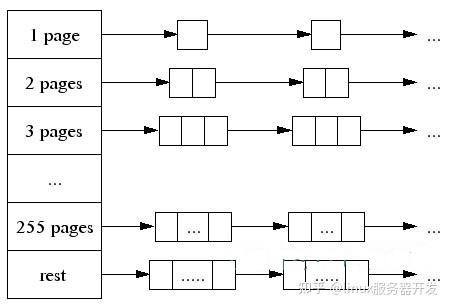
大对象(>32K)先4k对齐后,从CentralCache中分配。 CentralCache维护的PageHeap如下图所示, 数组中第256个元素是所有大于255个页面都挂到该链表中。
-
当best fit的页面链表中没有空闲空间时,则一直往更大的页面空间则,如果所有256个链表遍历后依然没有成功分配。 则使用sbrk, mmap, /dev/mem从系统中分配。
-
tcmalloc PageHeap管理的连续的页面被称为span.
如果span未分配, 则span是PageHeap中的一个链表元素
如果span已经分配,它可能是返回给应用程序的大对象, 或者已经被切割成多小对象,该小对象的size-class会被记录在span中 -
在32位系统中,使用一个中央数组(central array)映射了页面和span对应关系, 数组索引号是页面号,数组元素是页面所在的span。 在64位系统中,使用一个3-level radix tree记录了该映射关系。
4.3 内存回收
- 当一个object free的时候,会根据地址对齐计算所在的页面号,然后通过central array找到对应的span。
- 如果是小对象,span会告诉我们他的size class,然后把该对象插入当前线程的ThreadCache中。如果此时ThreadCache超过一个预算的值(默认2MB),则会使用垃圾回收机制把未使用的object从ThreadCache移动到CentralCache的central free lists中。
- 如果是大对象,span会告诉我们对象锁在的页面号范围。 假设这个范围是[p,q], 先查找页面p-1和q+1所在的span,如果这些临近的span也是free的,则合并到[p,q]所在的span, 然后把这个span回收到PageHeap中。
- CentralCache的central free lists类似ThreadCache的FreeList,不过它增加了一级结构,先根据size-class关联到spans的集合, 然后是对应span的object链表。如果span的链表中所有object已经free, 则span回收到PageHeap中。
4.4 tcmalloc优点
- hreadCache会阶段性的回收内存到CentralCache里。 解决了ptmalloc2中arena之间不能迁移的问题。
- Tcmalloc占用更少的额外空间。例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。Ptmalloc2使用最少8字节描述一个chunk。
- 更快。小对象几乎无锁, >32KB的对象从CentralCache中分配使用自旋锁。 并且>32KB对象都是页面对齐分配,多线程的时候应尽量避免频繁分配,否则也会造成自旋锁的竞争和页面对齐造成的浪费
资料:
https://zhuanlan.zhihu.com/p/581863694
https://zhuanlan.zhihu.com/p/497509956?utm_id=0