一. motivation
以前的大多数LIE算法使用单个输入图像和几个手工制作的先验来调整照明。然而,由于单幅图像信息有限,手工先验的适应性较差,这些解决方案往往无法揭示图像细节。
二. contribution
1. 提出一个成对低光图像输入(相同内容,不同的曝光度)
2. 在输入之前进行了一个去噪操作,再进行Retinex分解
三. Network

训练阶段:
1 I1 和 I2 是两个曝光度不同的低光输入,分别输入到P-Net进行去噪,再分别输入到L-Net和R-Net得到光照分量和反射分量
2 P-Net 和 R-Net有相同的网络结构,P-Net 是进行一个去噪操作,使得 i1更加满足于Retinex分解
class R_net(nn.Module): def __init__(self, num=64): super(R_net, self).__init__() self.R_net = nn.Sequential( nn.ReflectionPad2d(1), nn.Conv2d(3, num, 3, 1, 0), nn.ReLU(), nn.ReflectionPad2d(1), nn.Conv2d(num, num, 3, 1, 0), nn.ReLU(), nn.ReflectionPad2d(1), nn.Conv2d(num, num, 3, 1, 0), nn.ReLU(), nn.ReflectionPad2d(1), nn.Conv2d(num, num, 3, 1, 0), nn.ReLU(), nn.ReflectionPad2d(1), nn.Conv2d(num, 3, 3, 1, 0), ) def forward(self, input): return torch.sigmoid(self.R_net(input))
3 L-Net和P-Net只有输出的通道数不一样,Channel-L = 1,Channel-R = 3
测试阶段:
测试阶段只用到低光输入,将低光图像I输入到P-Net中进行去噪操作,再分别经过L-Net和R-Net得到光照分量和反射分量,g(L)是对光照L的一个指数级的操作,文章中去的是0.2次方,再经过逐元素相乘得到最后增强后的效果
四. 损失Loss

1 Projection Loss 计算的去噪后的图像和原图像的一个均方误差操作,物理含义:使得噪声越来越小,如果原图像没有噪声,则Lp逼近为0
2 Reflectance Consistency Loss 计算的是两张曝光度不同的图像分离后的反射分量,按照Retinex理论,R只和物体本身的性质有关,则内容相同,曝光度不同的图像应该含有相同的反射分量R
3 Retinex第一项: 计算分离R和L与i的程度; 第二项
第三项,L0是rgb中最大的值,物理含义,我感觉要是L是正常光的话,应该rgb三个通道的值都和L0是接近的

第四项, 光照水平和竖直的梯度应该变化不大,所以用光照梯度来约束光照变化

五、实验结果
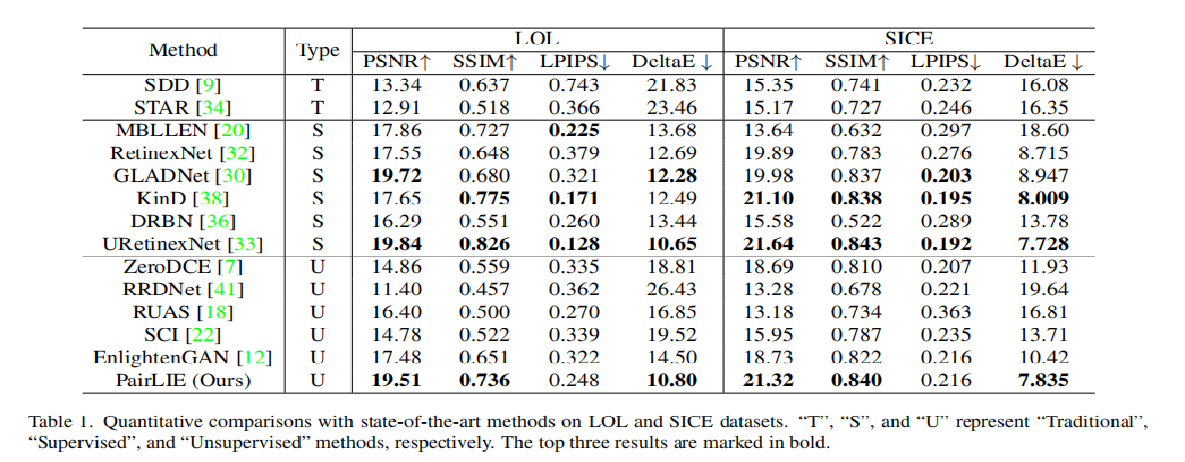
在无监督中取得了一个SOTA
在g(L)中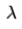 取值的变化对与R进行逐元素相乘的时候变化
取值的变化对与R进行逐元素相乘的时候变化


原始图像Original Image - 去噪后的图像Projected Image = Difference Map
- Low-light light CVPR_Learning Instances Lowlow-light light cvpr_learning instances low-light cvpr_snr-aware enhancement snr low-light cvpr_toward enhancement low-light flexible cvpr_low-light cvpr_low-light enhancement structure guidance cvpr_learning instances server sql clustered instances reserved ri-reserved instances instance