Python 爬虫 模拟手机 爬取听力资料
目录
需求
想要得到雅思王听力的听力资料,但是没有光驱,只能扫码
于是想要把所有资源给爬下来就不用每次扫码了
遇到问题
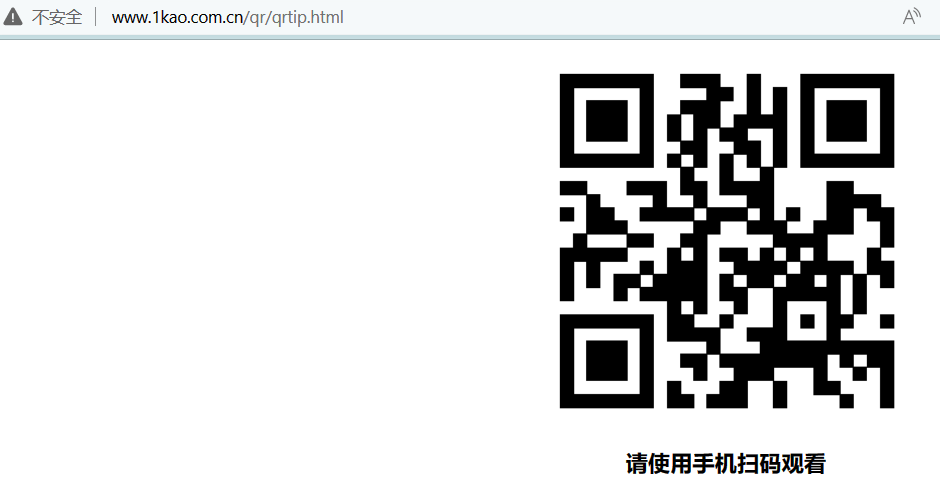
于是查阅资料,使用pyppeteer模拟手机进行登陆,爬取资料
思路1 使用 Pyppeteer
参考
pyppeteer如何开启手机模式 - 『悬赏问答区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
老哥的回复

browser = await launch({'headless':False, 'args':['--no-sandbox']})
page=await browser.newPage()
await page.setUserAgent(
'Mozilla/5.0 (Linux; Android 9; V1813A Build/P00610; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/11.16 SP-engine/2.12.5 baiduboxapp/11.16.5.10 (Baidu; P1 9)')
await page.goto(url)
功能强大的python包(七):BeautifulSoup(HTML解析) - 知乎 (zhihu.com)
实现
1 测试模拟手机效果
先试一下能不能模拟浏览器登录进入
from pyppeteer import launch
import asyncio
import os
import time
async def login_pyppeteer():
"""
使用pyppeteer模拟手机进行一次登录
:param username: 平台用户名名
:param password: 平台密码
:return:
"""
# 涉及到的相关文件路径
browser = await launch({
# Windows 和 Linux 的目录不一样,情换成自己对应的executable文件地址
'executablePath': 'C:/Users/----/AppData/Local/pyppeteer/pyppeteer/local-chromium/588429/chrome-win32/chrome.exe',
'headless': False
})
page = await browser.newPage()
await page.setUserAgent('Mozilla/5.0 (Linux; Android 9; V1813A Build/P00610; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/11.16 SP-engine/2.12.5 baiduboxapp/11.16.5.10 (Baidu; P1 9)')
await page.goto('http://')
xvliehao = ''
# 输入序列号
uniqueIdElement = await page.querySelector('#serial')
await uniqueIdElement.type(xvliehao, delay=5)
# 点击登录
okButtonElement = await page.querySelector('#submit')
await okButtonElement.click()
time.sleep(10000)
asyncio.get_event_loop().run_until_complete(login_pyppeteer())
效果
成功登录进入
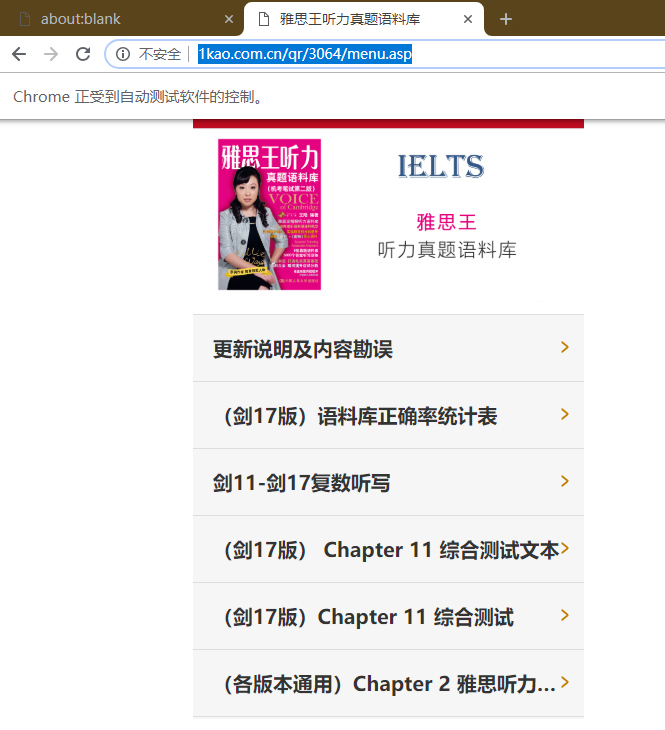
2 爬取资源
接下来就可以愉快地爬取资源了
打开开发者模式,定位资源
首页资源列表
首先是首页资源列表的布局
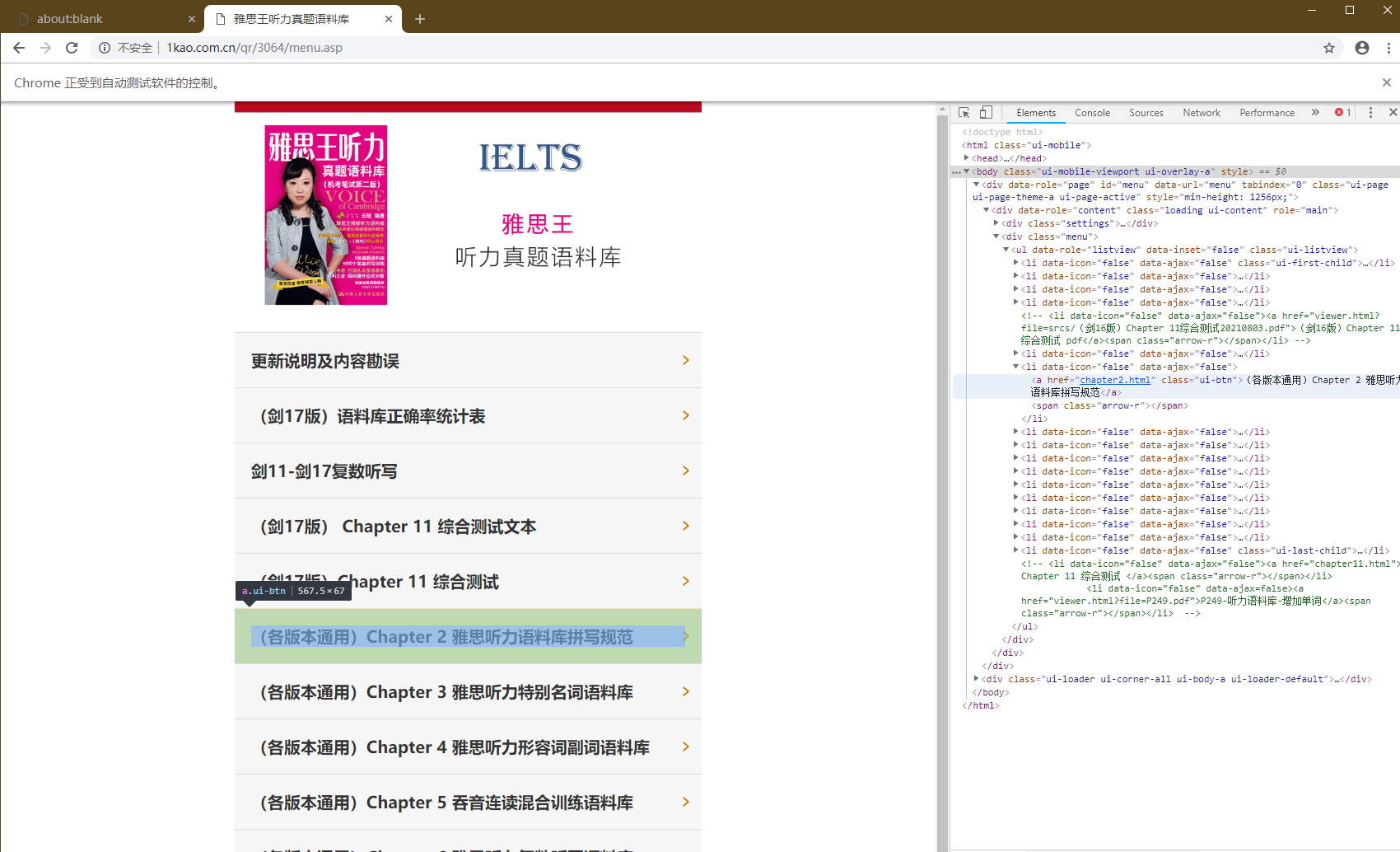
selector
'#menu > div > div.menu > ul > li:nth-child(5) > a'
'#menu > div > div.menu > ul > li:nth-child(6) > a'
'# menu > div > div.menu > ul > li:nth-child(6) > a'
xpath
//*[@id="menu"]/div/div[2]/ul/li[5]/a
//*[@id="menu"]/div/div[2]/ul/li[7]/a
详情与音频
xpath
'//*[@id="box"]/div[1]/div/audio'
'//*[@id="box"]/div[2]/div/audio'
以chapter2 的音频爬取为例
#点击跳转
chapter2_xpath = await page.xpath('//*[@id="menu"]/div/div[2]/ul/li[5]')
chapter2_selector = await page.querySelector('#menu > div > div.menu > ul > li:nth-child(5) ') #menu > div > div.menu > ul > li:nth-child(5) > a
# await page.goto('http://www.1kao.com.cn/qr/3064/chapter2.html') 直接跳转失败
chapter2_xpath_c = chapter2_xpath[0]
await chapter2_xpath_c.click()
await asyncio.sleep(3)
# menu > div > div.menu > ul > li.ui-last-child > a #menu > div > div.menu > ul > li:nth-child(5) //*[@id="menu"]/div/div[2]/ul/li[5]
# menu > div > div.menu > ul > li:nth-child(15) > a
# #解析页面数据
# // *[ @ id = "menu"] / div / div[2] / ul / li[5] / a
# // *[ @ id = "menu"] / div / div[2] / ul / li[16] / a
page_text = await page.content()
soup = BeautifulSoup(page_text, 'html.parser', from_encoding='utf-8')
name_tag = soup.select('body > div.ui-page.ui-page-theme-a.ui-page-active > div.ui-header.ui-bar-inherit > h1')
name_text = name_tag[0].string
audio=soup.select('audio')
print(audio)
audio_list = []
audio_dict ={}
for a in audio:
audio_link = a.attrs['src']
audio_name = a.attrs['data-src']
print(audio_link)
print(audio_name)
audio_dict[audio_name] = audio_link
audio_list.append(audio_link)
#print(audio_list)
print(audio_dict)
完整代码
# -*- coding: utf-8 -*-
"""
@author : zuti
@software : PyCharm
@file : pyppeteer_wangtingli.py
@time : 2023/3/27 10:48
@desc :
"""
import json
from PIL import Image
from bs4 import BeautifulSoup
from pyppeteer import launch
import asyncio
import os
import time
import requests
async def login_pyppeteer():
"""
使用pyppeteer进行一次登录,有可能因为验证码错误导致登录失败
:param username: 平台用户名名
:param password: 平台密码
:return:
"""
# 涉及到的相关文件路径
browser = await launch({
# Windows 和 Linux 的目录不一样,情换成自己对应的executable文件地址
'executablePath': 'C:/Users/asus/AppData/Local/pyppeteer/pyppeteer/local-chromium/588429/chrome-win32/chrome.exe',
'headless': False
})
page = await browser.newPage()
await page.setUserAgent(
'Mozilla/5.0 (Linux; Android 9; V1813A Build/P00610; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/11.16 SP-engine/2.12.5 baiduboxapp/11.16.5.10 (Baidu; P1 9)')
await page.goto('http://sn.1kao.com.cn/')
xvliehao = '7947677611254k180104'
# 输入序列号
uniqueIdElement = await page.querySelector('#serial')
await uniqueIdElement.type(xvliehao, delay=5)
# 点击登录
okButtonElement = await page.querySelector('#submit')
await okButtonElement.click()
await asyncio.sleep(3)
# soup = BeautifulSoup(page_text , 'html.parser', from_encoding='utf-8')
# a = soup.select('a')
# #print(a)
# // *[ @ id = "menu"] / div / div[2] / ul / li[15] / a
# #遍历抓取所有的chapter
dict_chapter = {}
for i in range(5, 6):
print(f'chapter:{i}')
# 点击chapter 跳转页面
xpath = '//*[@id="menu"]/div/div[2]/ul/li[' + str(i) + ']'
chapter_i_xpath = await page.xpath(xpath)
chapter_i_xpath_c = chapter_i_xpath[0]
await chapter_i_xpath_c.click()
await asyncio.sleep(1)
# 解析页面数据
page_text = await page.content()
soup = BeautifulSoup(page_text, 'html.parser', from_encoding='utf-8')
name_tag = soup.select('body > div.ui-page.ui-page-theme-a.ui-page-active > div.ui-header.ui-bar-inherit > h1')
name_text = name_tag[0].string
audio = soup.select('audio')
# print(audio)
# audio_list = []
audio_dict = {}
for a in audio:
audio_link = a.attrs['src']
audio_name = a.attrs['src']
print(audio_name)
print(audio_link)
audio_dict[audio_name] = audio_link
if audio_link.find('http') == -1: # 当连接不包含http头
audio_link = "http://1kao.com.cn/qr/3064/" + audio_link
print(audio_link)
res = requests.get(audio_link)
music = res.content
file_name = name_text + audio_name.replace('/', ' ')
with open(file_name, 'ab') as file: # 保存到本地的文件名
file.write(music)
file.flush()
# audio_list.append(audio_link)
# print(audio_dict)
dict_chapter[name_text] = audio_dict
print('章节爬取结果')
print(audio_dict)
# 再点击跳转 回到前一页
return_button_selector = await page.querySelector(
'body > div.ui-page.ui-page-theme-a.ui-page-active > div.ui-header.ui-bar-inherit > a')
return_button_xpath = await page.xpath('/html/body/div[1]/div[1]/a')
return_button_xpath_c = return_button_xpath[0]
await return_button_xpath_c.click()
await asyncio.sleep(1)
# 将字典内容保存到json文件中
if isinstance(dict_chapter, str):
dict_chapter = eval(dict_chapter)
with open('dict_chapter.txt', 'w', encoding='utf-8') as f:
# f.write(str(dict)) # 直接这样存储的时候,读取时会报错JSONDecodeError,因为json读取需要双引号{"aa":"BB"},python使用的是单引号{'aa':'bb'}
str_ = json.dumps(dict_chapter, ensure_ascii=False) # TODO:dumps 使用单引号''的dict ——> 单引号''变双引号"" + dict变str
print(type(str_), str_)
f.write(str_)
print('保存成功')
#
# #点击跳转
# chapter2_xpath = await page.xpath('//*[@id="menu"]/div/div[2]/ul/li[5]')
# chapter2_selector = await page.querySelector('#menu > div > div.menu > ul > li:nth-child(5) ') #menu > div > div.menu > ul > li:nth-child(5) > a
# # await page.goto('http://www.1kao.com.cn/qr/3064/chapter2.html') 直接跳转失败
# chapter2_xpath_c = chapter2_xpath[0]
# await chapter2_xpath_c.click()
# await asyncio.sleep(3)
# # menu > div > div.menu > ul > li.ui-last-child > a #menu > div > div.menu > ul > li:nth-child(5) //*[@id="menu"]/div/div[2]/ul/li[5]
# # menu > div > div.menu > ul > li:nth-child(15) > a
# # #解析页面数据
# # // *[ @ id = "menu"] / div / div[2] / ul / li[5] / a
# # // *[ @ id = "menu"] / div / div[2] / ul / li[16] / a
#
# page_text = await page.content()
#
# soup = BeautifulSoup(page_text, 'html.parser', from_encoding='utf-8')
# name_tag = soup.select('body > div.ui-page.ui-page-theme-a.ui-page-active > div.ui-header.ui-bar-inherit > h1')
# name_text = name_tag[0].string
# audio=soup.select('audio')
# print(audio)
# audio_list = []
# audio_dict ={}
# for a in audio:
# audio_link = a.attrs['src']
# audio_name = a.attrs['data-src']
# print(audio_link)
# print(audio_name)
# audio_dict[audio_name] = audio_link
# audio_list.append(audio_link)
# #print(audio_list)
# print(audio_dict)
# 将
# video1 = await page.xpath('//*[@id="box"]/div[1]/div/audio')
# video1
# 获得资源列表
time.sleep(10)
asyncio.get_event_loop().run_until_complete(login_pyppeteer())
3 下载音频
思路2 使用Request_html
模拟手机
只需要修改发送头即可
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 9; V1813A Build/P00610; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/11.16 SP-engine/2.12.5 baiduboxapp/11.16.5.10 (Baidu; P1 9)',
'Content-Type': 'application/json;charset=UTF-8'
}