大语言模型微调是指对已经预训练的大型语言模型(例如Llama-2,Falcon等)进行额外的训练,以使其适应特定任务或领域的需求。微调通常需要大量的计算资源,但是通过量化和Lora等方法,我们也可以在消费级的GPU上来微调测试,但是消费级GPU也无法承载比较大的模型,经过我的测试,7B的模型可以在3080(8G)上跑起来,这对于我们进行简单的研究是非常有帮助的,但是如果需要更深入的研究,还是需要专业的硬件。

我们先看看硬件配置:
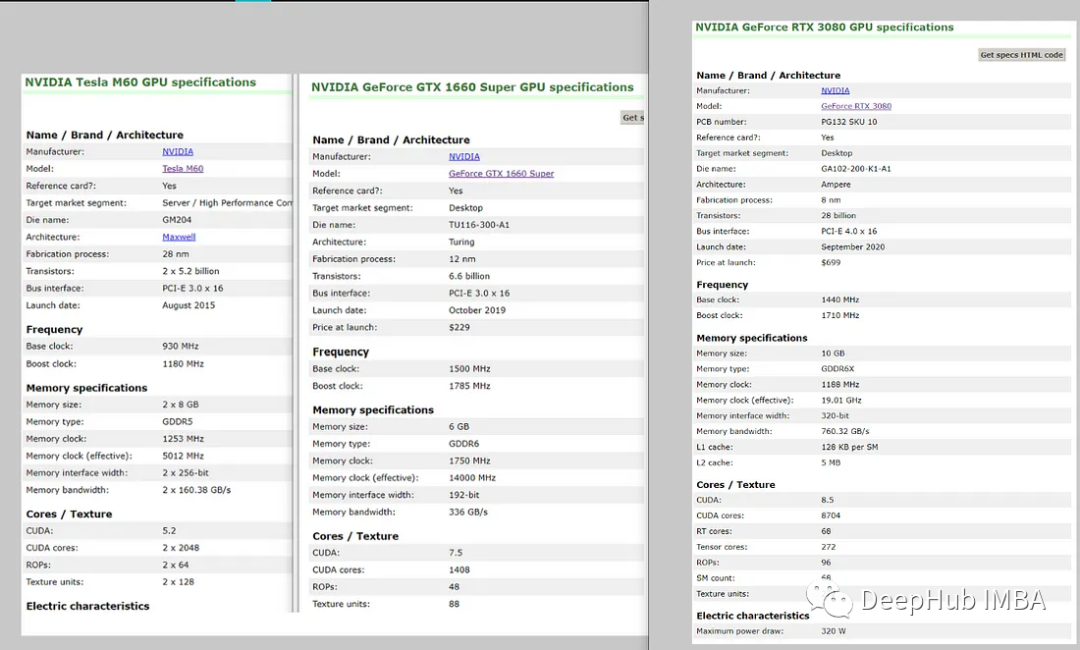
亚马逊的g3.xlarge M60是8GB的VRAM和2048个CUDA内核。3080是10Gb的GDDR6 VRAM,这两个GPU基本类似。
https://avoid.overfit.cn/post/0dd29b9a89514a988ae54694dccc9fa6