作业一.天气预报
1.内容
代码如下:
import requests
from bs4 import BeautifulSoup
import sqlite3
import logging
logging.basicConfig(level=logging.INFO)
class WeatherDB:
def __init__(self, db_name):
self.db_name = db_name
def __enter__(self):
self.con = sqlite3.connect(self.db_name)
self.cursor = self.con.cursor()
self.create_table()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.con.commit()
self.con.close()
def create_table(self):
self.cursor.execute(
"CREATE TABLE IF NOT EXISTS weathers (wCity VARCHAR(16), wDate VARCHAR(16), wWeather VARCHAR(64), wTemp VARCHAR(32), PRIMARY KEY (wCity, wDate))")
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("INSERT INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)",
(city, date, weather, temp))
except sqlite3.IntegrityError:
logging.warning(f"Duplicate entry for {city} on {date}")
except Exception as e:
logging.error(str(e))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601", "福州": "101230101"}
def get_forecast(self, city):
if city not in self.cityCode:
logging.error(f"{city} code cannot be found")
return None
url = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml"
response = requests.get(url, headers=self.headers)
if response.status_code != 200:
logging.error(f"Failed to get data for {city}")
return None
response.encoding = 'utf-8' # Ensure using UTF-8 encoding
soup = BeautifulSoup(response.text, 'lxml')
lis = soup.select("ul[class='t clearfix'] li")
forecasts = []
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
forecasts.append((city, date, weather, temp))
except Exception as e:
logging.error(f"Error processing data for {city}: {str(e)}")
return forecasts
def print_forecasts(self, city):
forecasts = self.get_forecast(city)
if forecasts:
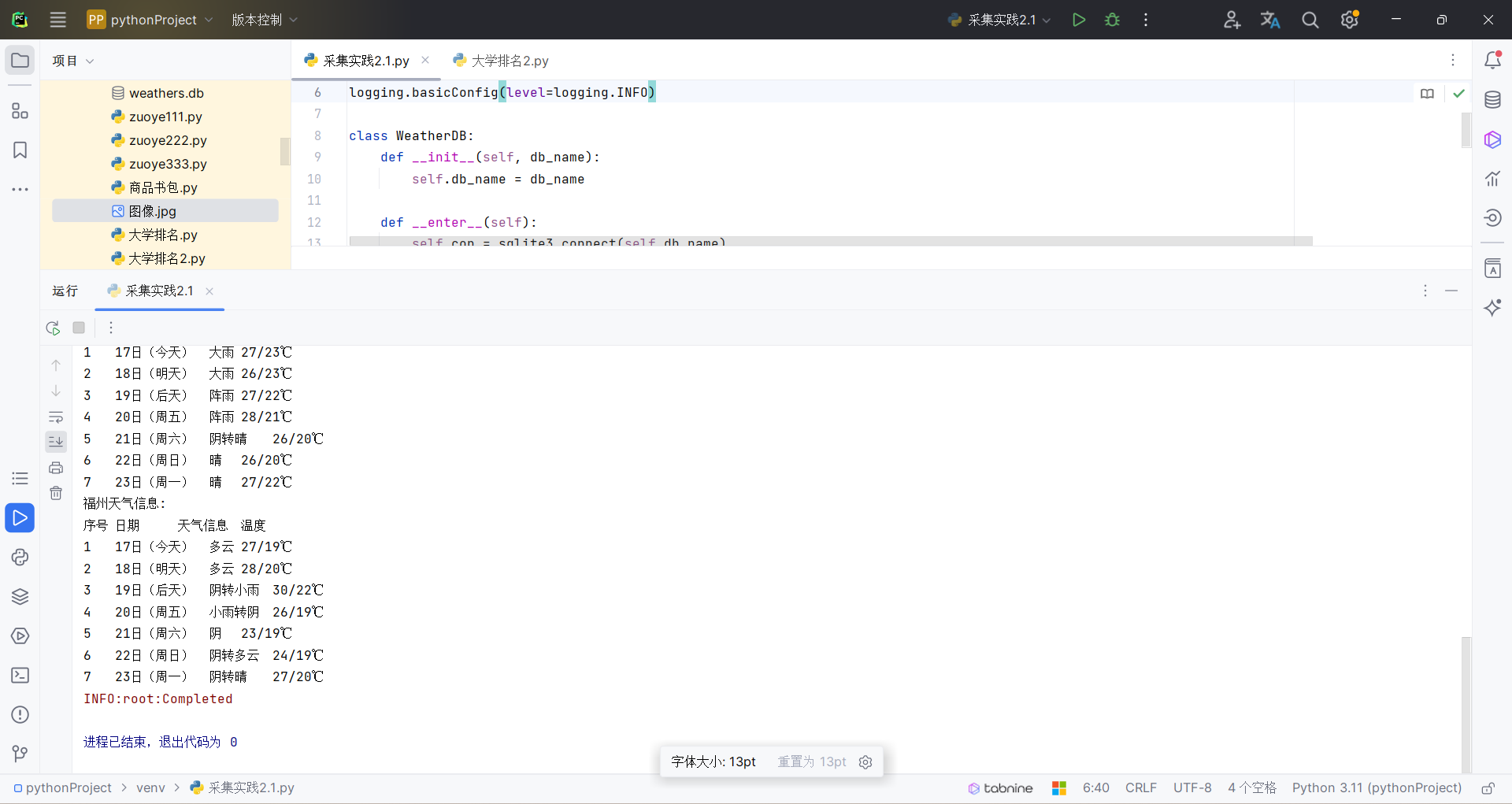
print(f"{city}天气信息:")
print("序号\t日期\t\t天气信息\t温度")
for i, (c, date, weather, temp) in enumerate(forecasts, start=1):
print(f"{i}\t{date}\t{weather}\t{temp}")
else:
print(f"No forecast data available for {city}")
with WeatherDB("weathers.db") as db:
wf = WeatherForecast()
for city in ["北京", "上海", "广州", "深圳", "福州"]:
forecasts = wf.get_forecast(city)
if forecasts:
for forecast in forecasts:
db.insert(*forecast)
wf.print_forecasts(city) # Print weather forecast
logging.info("Completed")
结果如下:

2.心得
第一题即对书中内容复现,从中我学习到的是如何利用bs4库将数据从网站中爬取后,利用sqlite3的数据库将数据持久化
作业二.股票爬取
1.内容
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
def fetch_stock_data(num_pages_to_scrape=5):
print(f"开始运行脚本,将爬取前 {num_pages_to_scrape} 页的股票数据...")
service = Service(executable_path="C:/Users/668/Desktop/chromedriver-win64/chromedriver.exe")
driver = webdriver.Chrome(service=service)
print("打开网页...")
url = 'http://quote.eastmoney.com/center/gridlist.html#sz_a_board'
driver.get(url)
print("等待页面加载...")
time.sleep(10)
all_data = pd.DataFrame()
for _ in range(num_pages_to_scrape):
try:
print(f"开始抓取第 {_+1} 页的股票数据...")
time.sleep(2)
table = driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[5]/div/table')
table_html = table.get_attribute('outerHTML')
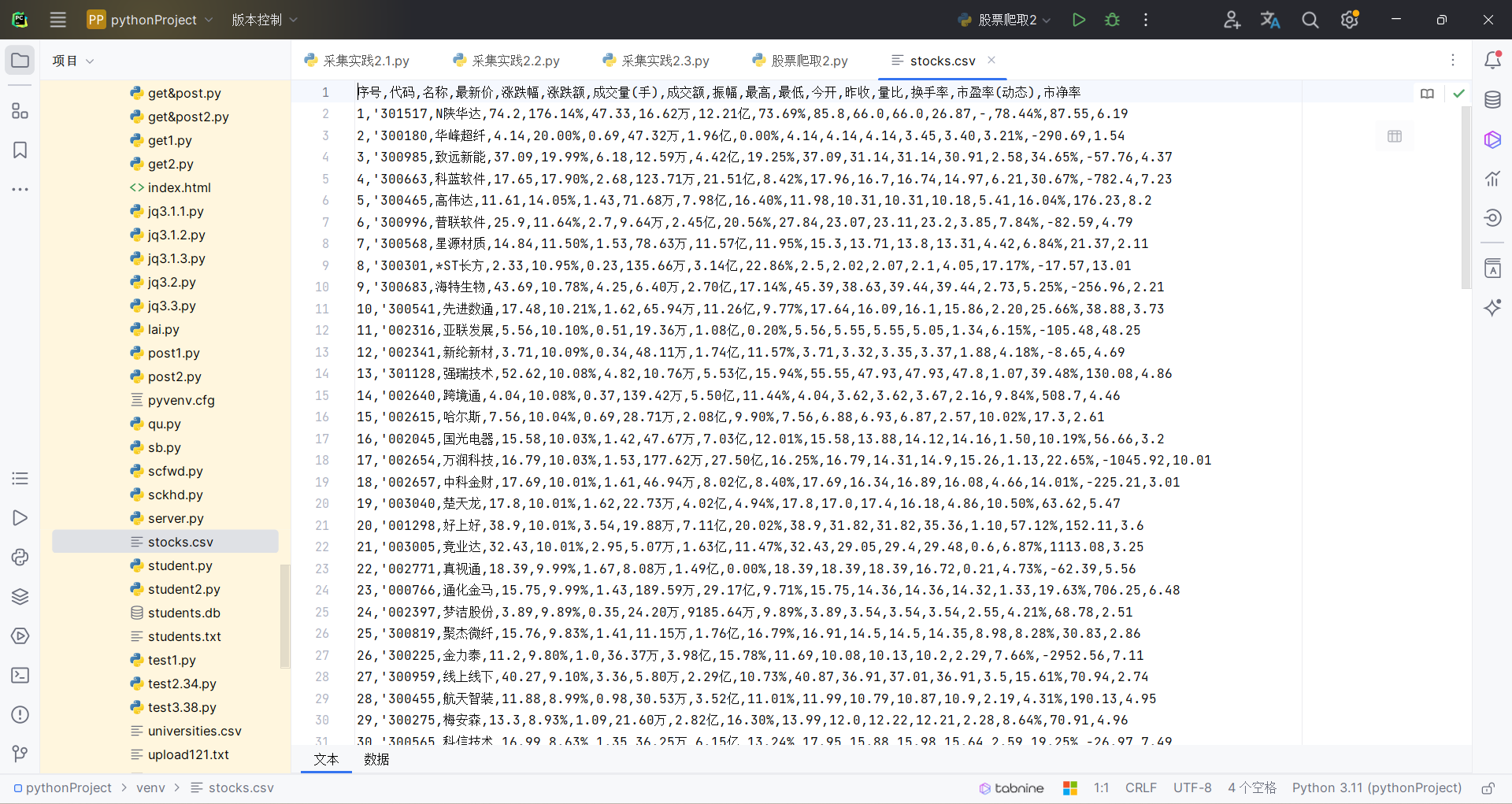
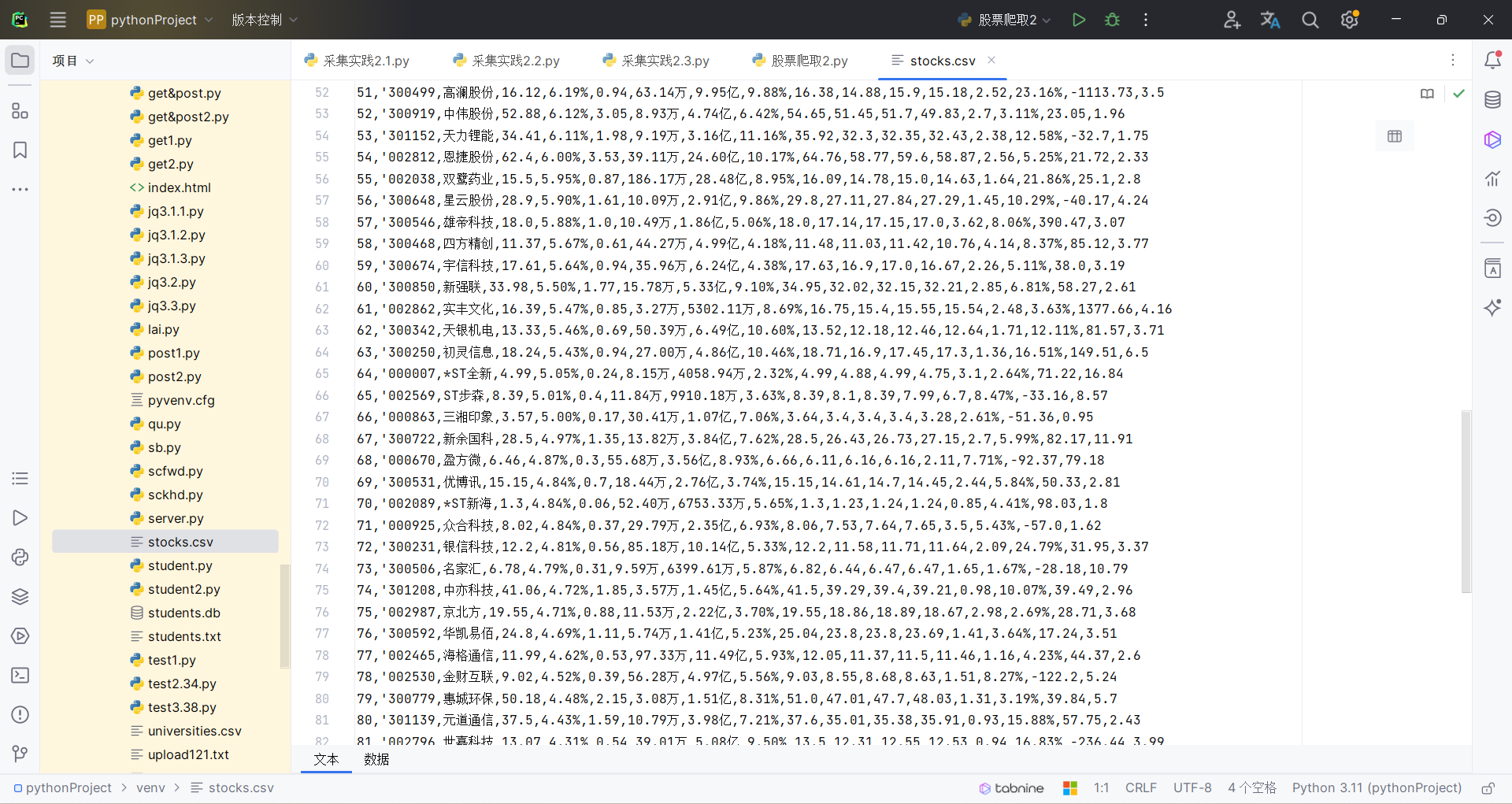
df = pd.read_html(table_html, header=0, converters={'代码': str})[0]
df = df.drop(columns=['相关链接', '加自选'])
df['代码'] = df['代码'].apply(lambda x: "'" + str(x).zfill(6))
all_data = pd.concat([all_data, df], ignore_index=True)
next_button = driver.find_element(By.XPATH, '//a[text()="下一页"]')
next_button.click()
time.sleep(2)
except Exception as e:
print(f"抓取第 {_+1} 页股票数据时出错:{e}")
break
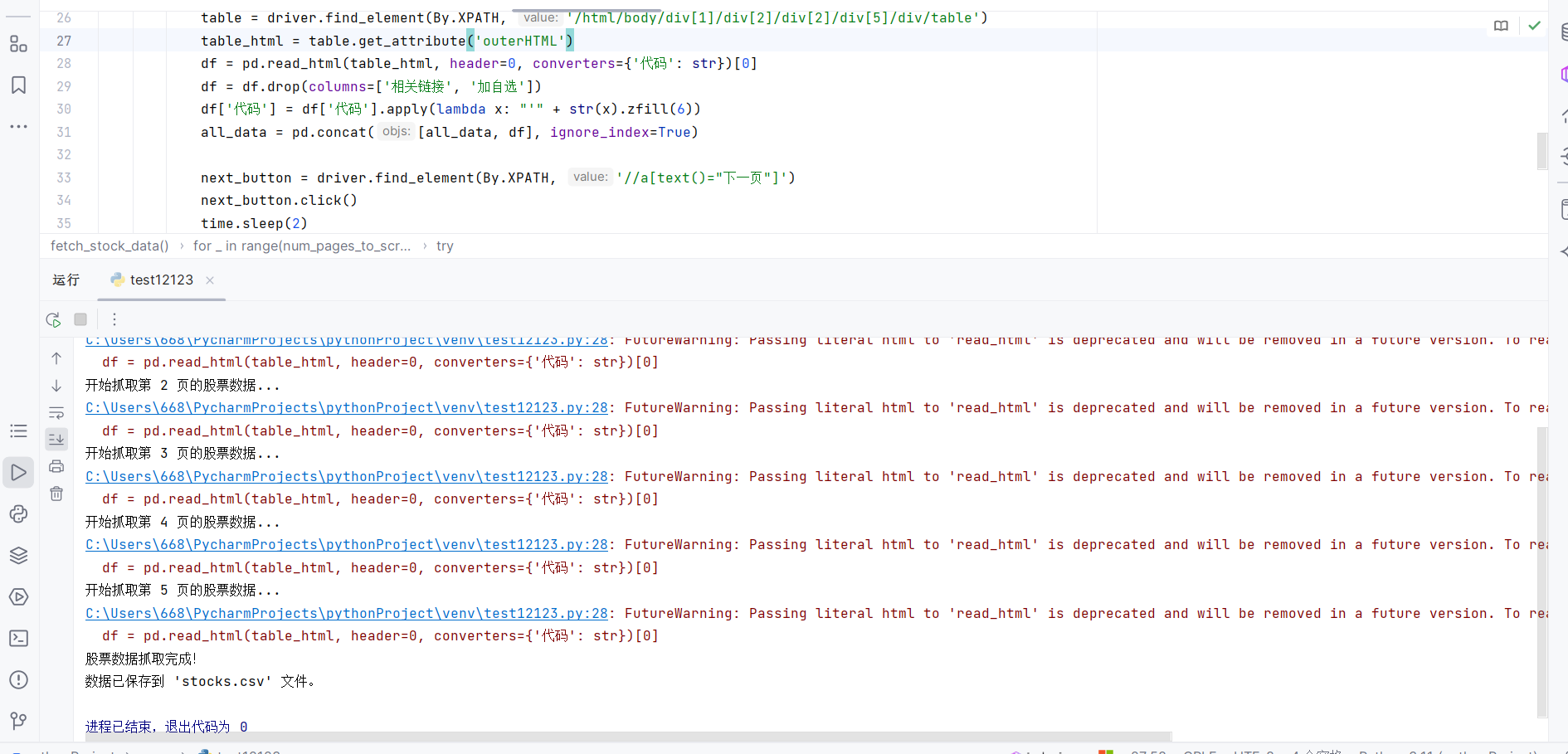
print("股票数据抓取完成!")
all_data.to_csv('stocks.csv', index=False, encoding='utf-8-sig')
print("数据已保存到 'stocks.csv' 文件。")
driver.quit()
fetch_stock_data()
代码分析:
这是一个使用Python和Selenium库爬取股票数据的脚本。具体而言,它首先打开了东方财富网的股票列表页面,然后循环遍历前num_pages_to_scrape(默认为5)页的股票数据,将每页的股票数据抓取到一个Pandas DataFrame中,最后将所有DataFrame合并成一个大的DataFrame,并将结果保存到名为'stocks.csv'的文件中。
以下是关于代码的一些解释:
Service和webdriver.Chrome:这两行是设置Chrome浏览器驱动,以便使用Selenium库进行网页操作。driver.get(url):打开指定的URL,这里是东方财富网的股票列表页面。table = driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[2]/div[5]/div/table'):找到表格元素,这里是整个页面的中心内容,包含所有股票数据。table_html = table.get_attribute('outerHTML'):获取表格的HTML代码。pd.read_html(table_html, header=0, converters={'代码': str})[0]:将HTML代码转换为Pandas DataFrame,header=0表示第一行是表头,converters={'代码': str}表示将'代码'列转换为字符串类型。df = df.drop(columns=['相关链接', '加自选']):删除不需要的列。df['代码'] = df['代码'].apply(lambda x: "'" + str(x).zfill(6)):将股票代码转换为字符串,并在左侧填充零,使其长度为6位。all_data = pd.concat([all_data, df], ignore_index=True):将当前页面的DataFrame合并到all_data中,ignore_index=True表示忽略原来的索引。next_button = driver.find_element(By.XPATH, '//a[text()="下一页"]'):找到下一页按钮。next_button.click():点击下一页按钮。all_data.to_csv('stocks.csv', index=False, encoding='utf-8-sig'):将最终的DataFrame保存到名为'stocks.csv'的文件中,index=False表示不保存索引。
结果如下:
2.心得
在初次写程序时一直报错没有找到原因,后面发现是新版本selenium定位元素以及语法的更新导致的,对进入F12进行抓包,查找使用的url,并分析api返回的值的方法有了一定了解


作业三.大学排名
1.内容
点击查看代码
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
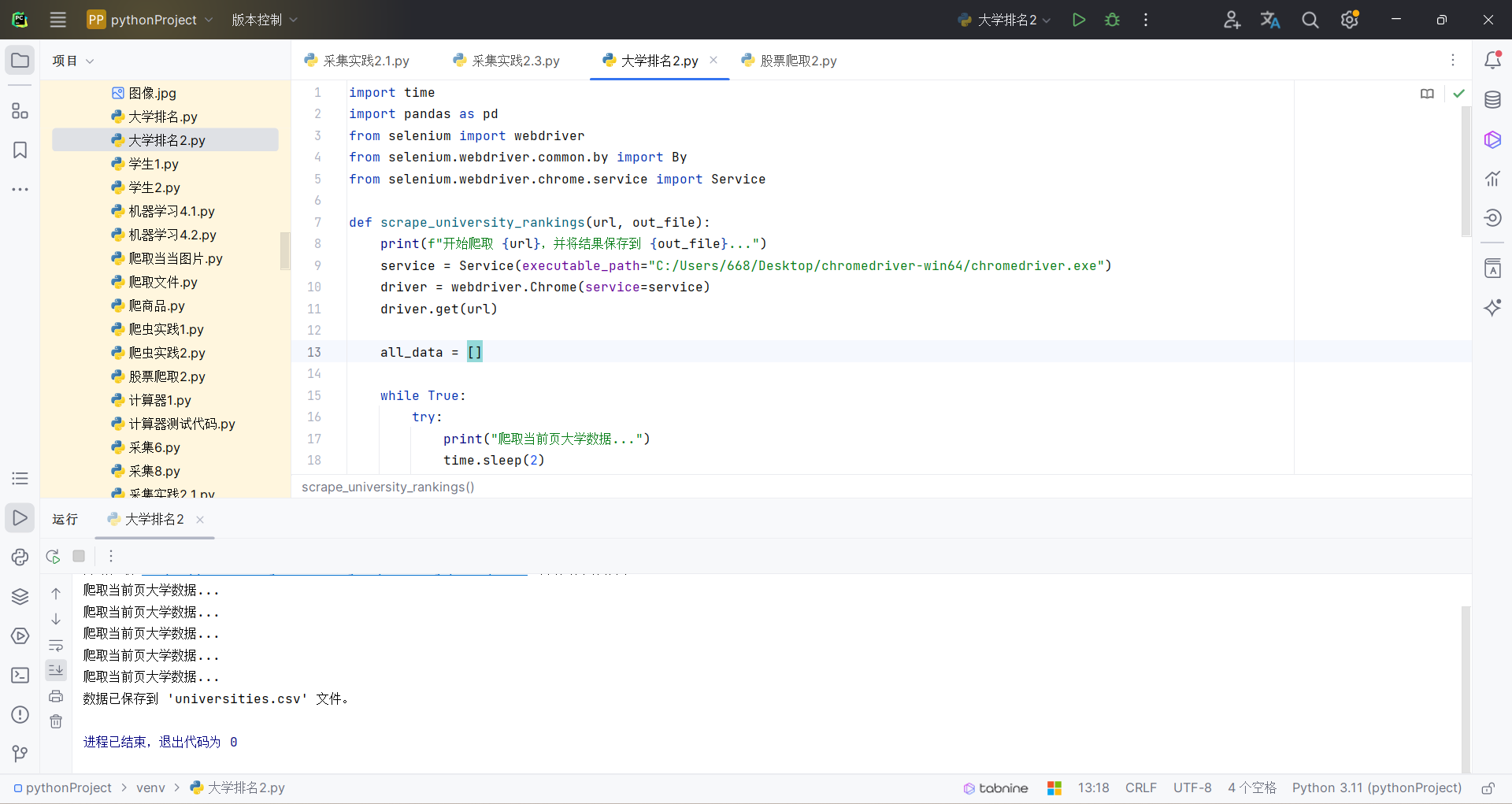
def scrape_university_rankings(url, out_file):
print(f"开始爬取 {url},并将结果保存到 {out_file}...")
service = Service(executable_path="C:/Users/668/Desktop/chromedriver-win64/chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get(url)
all_data = []
while True:
try:
print("爬取当前页大学数据...")
time.sleep(2)
rows = driver.find_elements(By.XPATH, '//tbody/tr')
for row in rows:
columns = row.find_elements(By.TAG_NAME, 'td')
ranking = int(columns[0].text)
university = columns[1].text
province = columns[2].text
type_ = columns[3].text
score = float(columns[4].text)
all_data.append([ranking, university, province, type_, score])
next_page_button = driver.find_element(By.XPATH, '/html/body/div/div/div/div[2]/div/div[3]/div[2]/div[1]/div/ul/li[9]')
if next_page_button.get_attribute('class') == 'ant-pagination-disabled ant-pagination-next':
break
next_page_button.click()
time.sleep(2)
except Exception as e:
print(f"爬取大学数据出错:{e}")
break
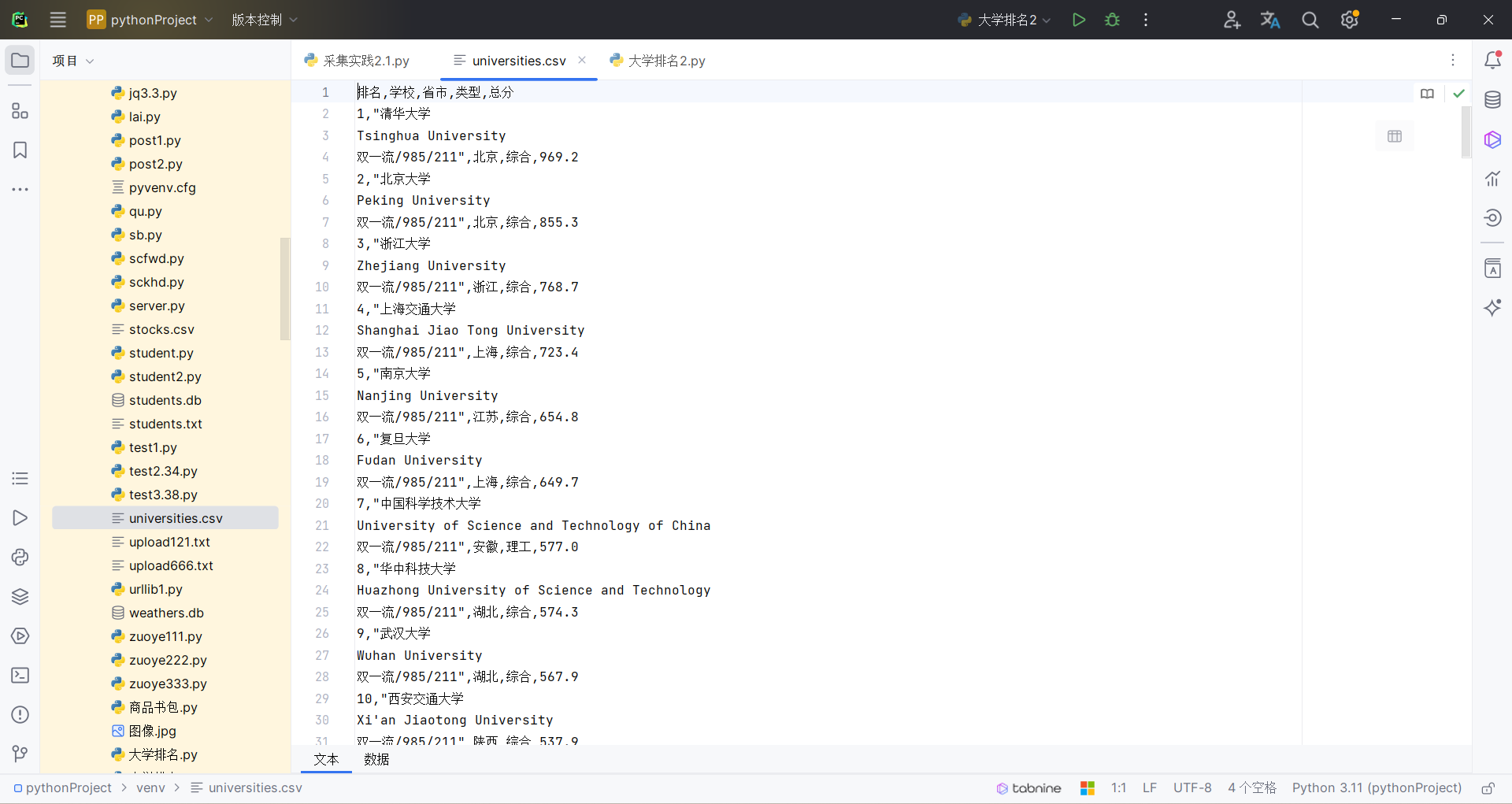
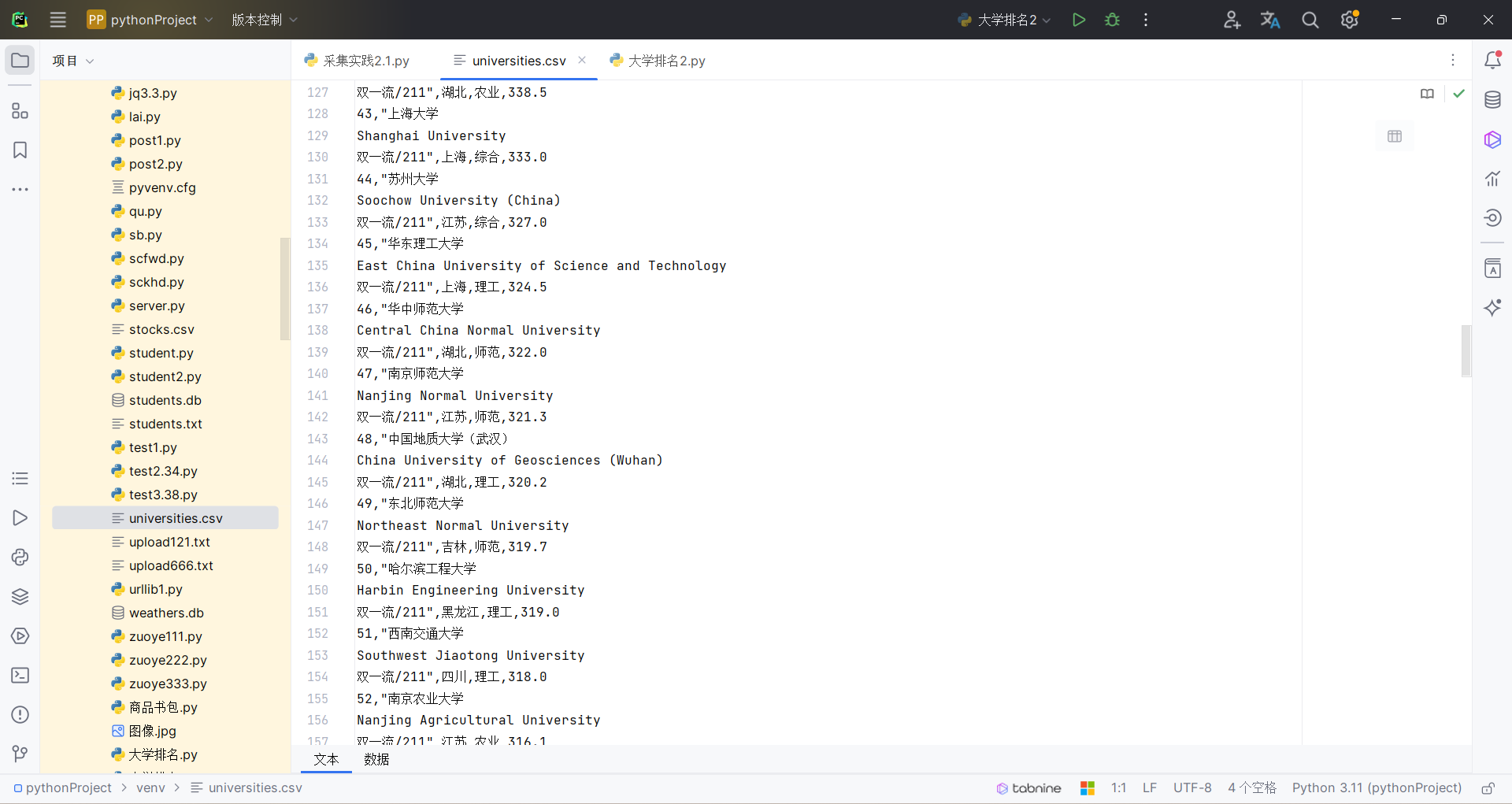
df = pd.DataFrame(all_data, columns=['排名', '学校', '省市', '类型', '总分'])
df.to_csv(out_file, index=False, encoding='utf-8-sig')
print(f"数据已保存到 '{out_file}' 文件。")
driver.quit()
scrape_university_rankings("https://www.shanghairanking.cn/rankings/bcur/2021", "universities.csv")
以下是关于代码的一些解释:
service = Service(executable_path="C:/Users/668/Desktop/chromedriver-win64/chromedriver.exe"):设置Chrome浏览器驱动,以便使用Selenium库进行网页操作。driver = webdriver.Chrome(service=service):创建Chrome浏览器实例。driver.get(url):打开指定的URL,这里是大学排名页面。all_data = []:初始化一个空列表,用于存储爬取的大学数据。while True::开始无限循环,直到爬取到最后一页。rows = driver.find_elements(By.XPATH, '//tbody/tr'):找到表格的所有行。for row in rows::遍历行。columns = row.find_elements(By.TAG_NAME, 'td'):找到当前行中的所有单元格。ranking = int(columns[0].text):获取排名,并将其转换为整数。university = columns[1].text:获取大学名称。province = columns[2].text:获取省份。type_ = columns[3].text:获取类型。score = float(columns[4].text):获取总分,并将其转换为浮点数。all_data.append([ranking, university, province, type_, score]):将爬取的数据添加到all_data列表中。next_page_button = driver.find_element(By.XPATH, '/html/body/div/div/div/div[2]/div/div[3]/div[2]/div[1]/div/ul/li[9]'):找到下一页按钮。if next_page_button.get_attribute('class') == 'ant-pagination-disabled ant-pagination-next'::如果下一页按钮不可点击,说明已经爬取到最后一页,此时跳出循环。next_page_button.click():点击下一页按钮。df = pd.DataFrame(all_data, columns=['排名', '学校', '省市', '类型', '总分']):将all_data列表转换为Pandas DataFrame。df.to_csv(out_file, index=False, encoding='utf-8-sig'):将DataFrame保存到指定的CSV文件中。driver.quit():退出浏览器。
结果如下:
2.心得
学会使用selenium来获取网页中的大学排名信息。需要注意的是,selenium的使用需要安装相应的浏览器驱动,如ChromeDriver