一、前言
前面简单用TensorFlow的全连接网络做了气温预测然后深入了解了一下全连接网络的数学计算,接着用CNN(卷积)网络做了手写数字识别,本篇就接着这个节奏来看卷积网络的数学计算。
二、卷积网络回顾
前面我们使用卷积网络时并没有说太明白,特别是一些参数的含义,这里先补一下功课。

从上面的图看,我们构建的网络内部有4种不同的层(layers):卷积层(Conv2D)、池化层(MaxPooling2D)、转一维(Flatten)、全连接层(Dense),下面逐一说下。
1、卷积层
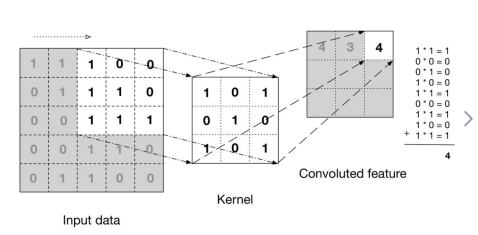
上图很好的阐释了卷积层工作原理,网上还有一些动图效果非常直观。卷积计算就是从输入中找到与卷积核(kernel)一样大小的矩阵,做对应位的乘积后加起来,得到结果的一个位。
1)Conv2D
这里的2D含义是二维数据,也就是处理输入数据为二维的卷积层,那自然还有Conv1D、Conv3D的,分别是处理一维和三维输入数据的卷积层。
2)Filters
含义是卷积核的个数,也就是上图中Kernel的数量。卷积核的数量越多则这一层输出就越多。
3)Kernel_size
含义是卷积核的大小,上面图片中的卷积核大小是3x3,我们示例用的是5x5的大小。卷积核的数量和大小共同组成了参数W、b的大小,这是类比全连接网络的概念。
4)Padding
Padding有两个参数值:VALID舍弃、SAME补足。
我们主要会使用SAME这个参数值,含义是当卷积计算结果大小较原始输入更小的话,在输入的边缘补0,使得输入输出的大小一致。下面举例:
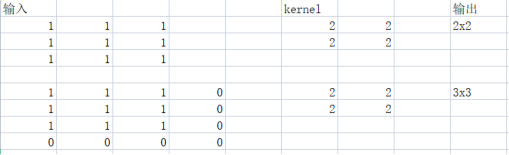
可以看到原本的输出是2x2,为了将输出的尺寸修正为3x3,我们可以在输入的边缘增加0。
5)步长
这里隐含了一个参数是“步长=1”(stride),前面有提到卷积计算的原理是从输入中找到与卷积核一样大小的矩阵,向下图这样:
第一个矩阵:

第二个矩阵:

这里我们使用了步长为1,如果修改下步长为2则:

6)padding:VALID
知晓了步长后,我们再来看padding的VALID,为何需要丢弃。
假设kernel的大小为3x3,步长为2,则:

可以看到,由于输入的尺寸小了,导致6这一列无法被计算到,如果是padding=SAME,则会在后面补0以扩充尺寸,但对于VALID则会将6这一列丢弃,相应的计算结果的尺寸也会较小。
7)input_shape
限制输入的尺寸。
2、池化层
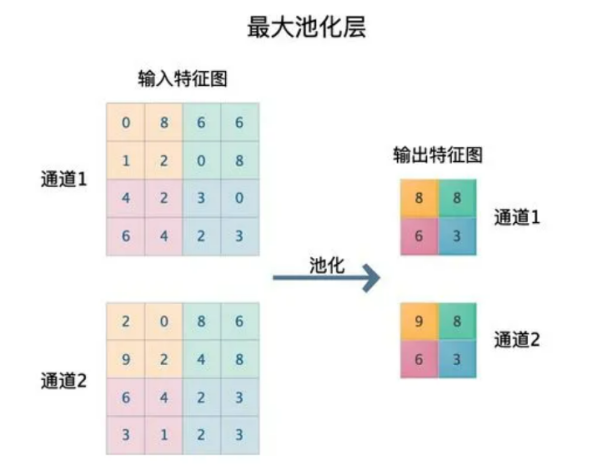
上图可以很直观看明白什么是池化,池化有两种,一种是求最大值的池化,另一种是求平均值池化。我们这里使用的是求最大值。
Pool_size就是池的大小,上图也是一个2x2的池。
3、一维化
所谓一维化就是将矩阵转为一维,比如下面这样:

三、精简示例
之前的示例输入是28x28,稍微大了点,我们只是要看看计算过程,所以将输入尺寸变小,同时卷积核的数量和大小也都缩小。
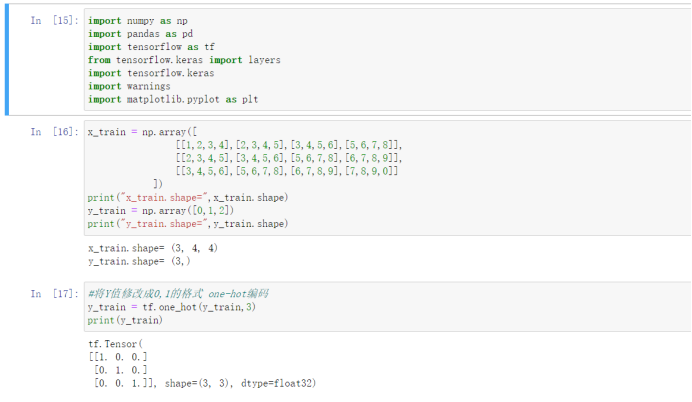
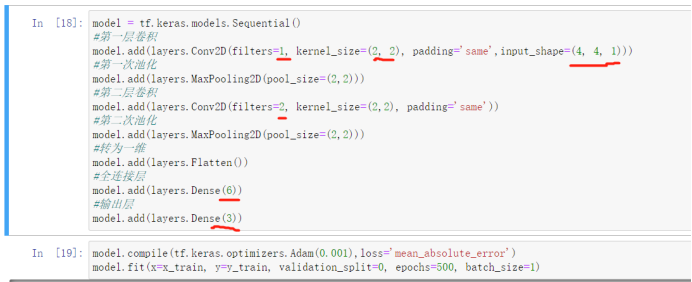

通过下面代码可以输出每一层的参数情况。
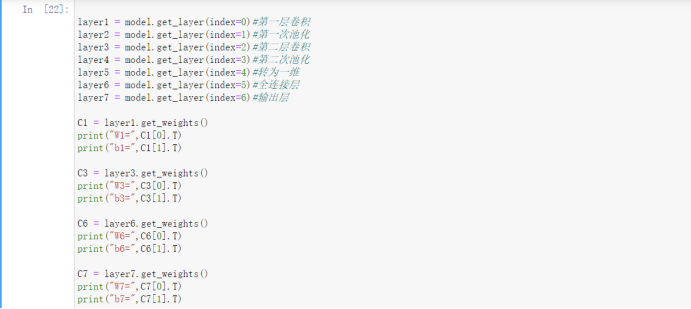
1)不是每一层都有参数
可以看到我们只输出了1、3、6、7层的参数,原因是池化层、转一维只是操作不带参数。
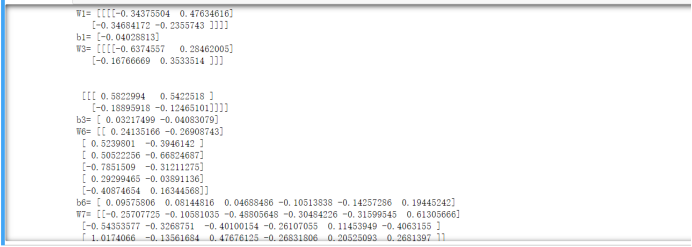
2)参数输出转置
注意看输出的时候参数矩阵是带了个T的,也就是将矩阵转置后输出。原因是矩阵表达的原因,如果不转置咱们会看不明白,所以在计算时,我们将输入也转置这样计算的结果就是一样的了。
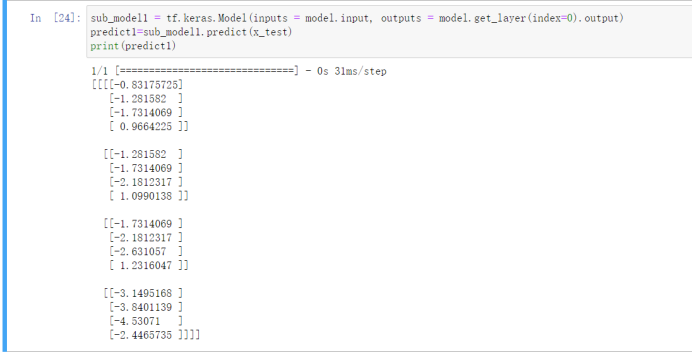
3)各层计算结果
我们可以用下面的代码输出各层的计算结果来看,这样可以帮助我们检查每一层的手算是否都正确。下面只演示了第一层的计算结果。
四、计算过程
1、输入调整

如上图,我们先将输入转置,然后在矩阵的边缘补0。
2、卷积核与输入的“分拆”
前面说过卷积计算实际是从输入中找一个与卷积核一样大小的矩阵来做对应计算,所以我们可以将输入按规则进行“分拆”,像下面这样:
第一个小矩阵:
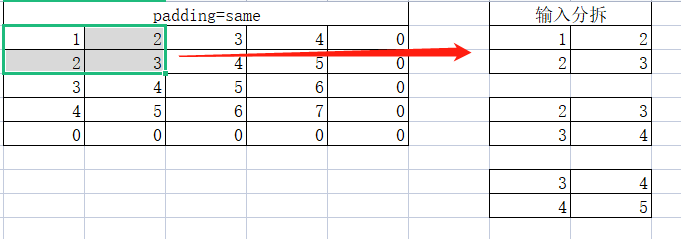
第二个小矩阵:
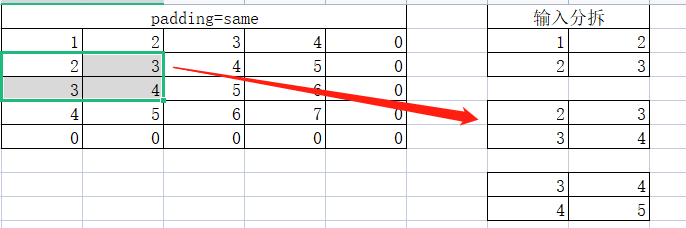
第三个小矩阵:
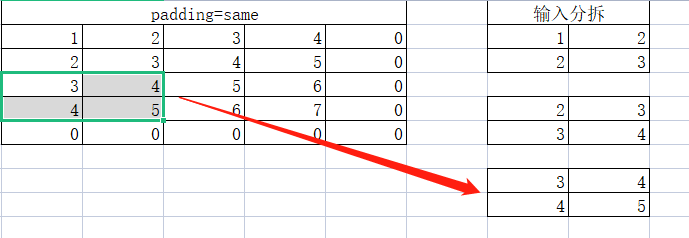
第四个小矩阵:
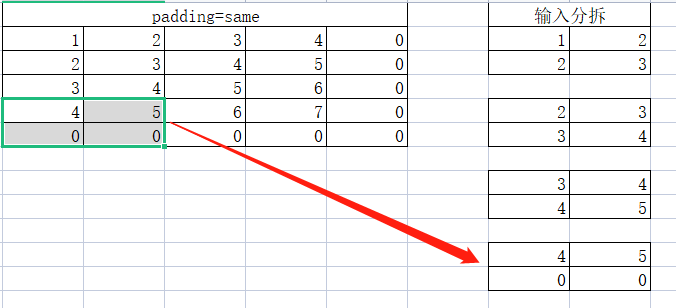
第五个小矩阵:
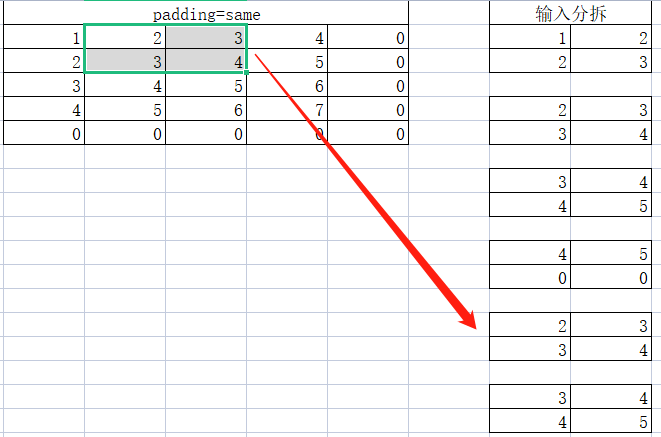
依次类推,我们可以得到16个小矩阵。每一个小矩阵与卷积核进行计算可以得到16个值,所以我们计算结果是一个4x4的矩阵。
需要注意,网上分拆小矩阵一般是从左到右,再从上到下。但是由于我们的输入是做了转置的,所以这里我们是先从上到下再从左到右,计算结果是一样的。
3、卷积核计算
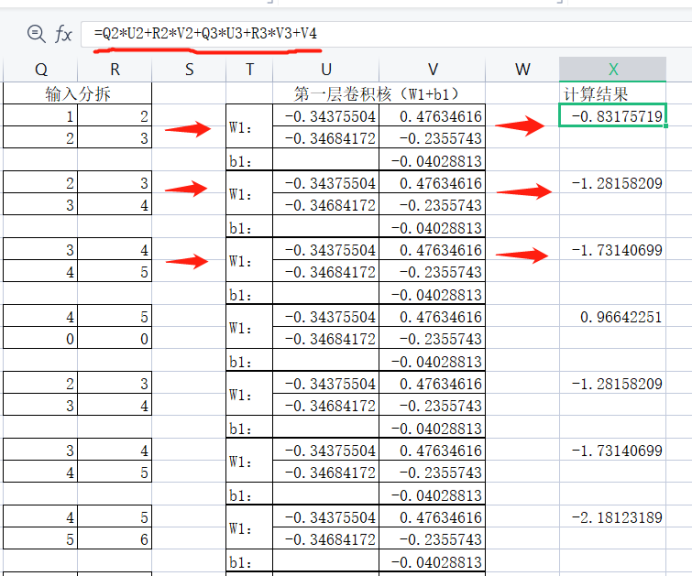
看上图,需要注意卷积核只有一组值,也就是输入分拆出来的16个小矩阵,依次与同样的W1+b1进行计算,计算方式是输入的每一个位与W1的对应位相乘,将乘积相加然后再与b1求和。
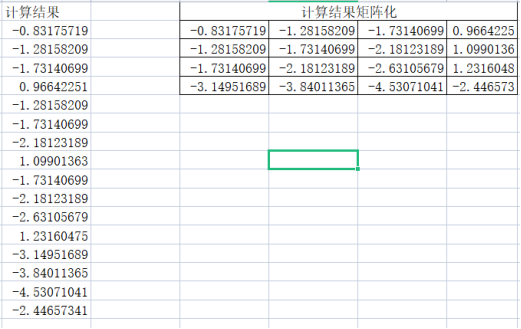
4、池化层
所谓池化就是将矩阵进行浓缩,浓缩的办法是从矩阵中提取其“较大”值,具体过程是根据池的大小(pool_size)将输入矩阵进行分拆,分拆成数个小矩阵,然后求出各小矩阵的最大值,最后将这些取出的最大值组成新的矩阵就是池化层的输出了。
1)池化层的分拆
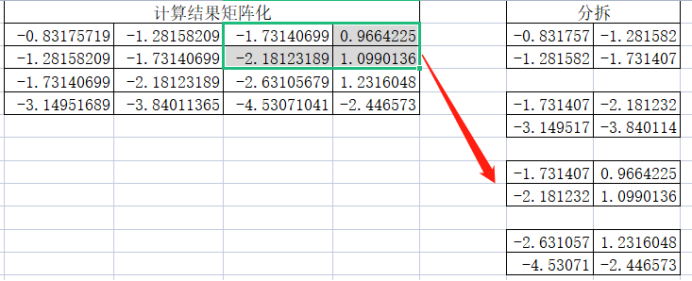
第一个小矩阵:
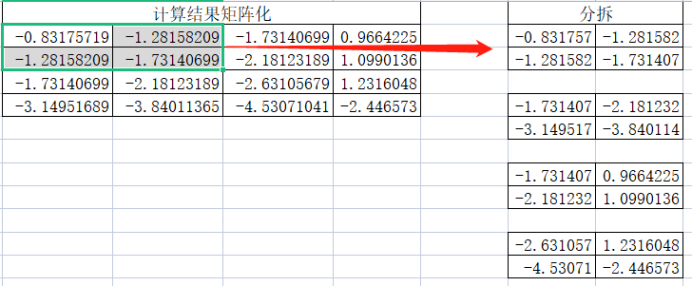
第二个小矩阵:
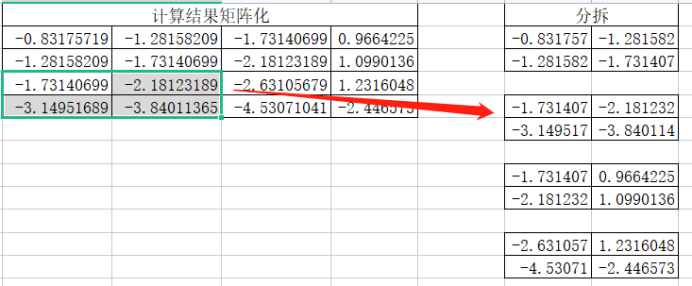
第三小矩阵:
第四个小矩阵:
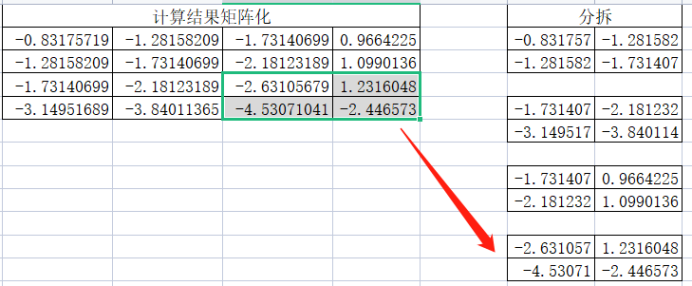
需要注意由于转置的原因,这里分拆过程也是先从上到下再从左到右,其次这里的分拆与卷积层分拆是不一样的,卷积层有滑动步数,这里默认就是根据pool_size进行滑动了。
2)池化计算
池化非常简单,就是求最大值而已。最后将结果矩阵化就得到了下一层卷积层需要的输入了。
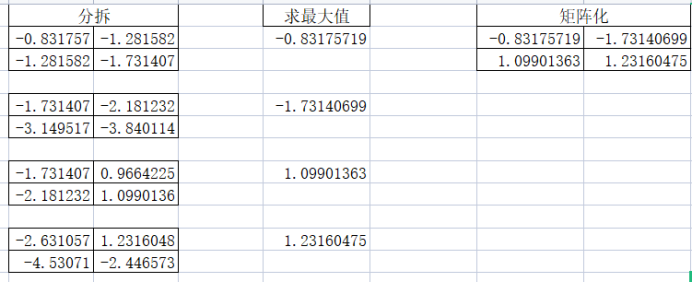
5、第二层卷积
有了前面的经验,第二层卷积计算更简单了。但第二层卷积有2个卷积核怎么办?其实只是多了一组W和b而已,所以同样的输入矩阵,按不同的卷积核参数计算2次即可。这样我们得到了2组输出。
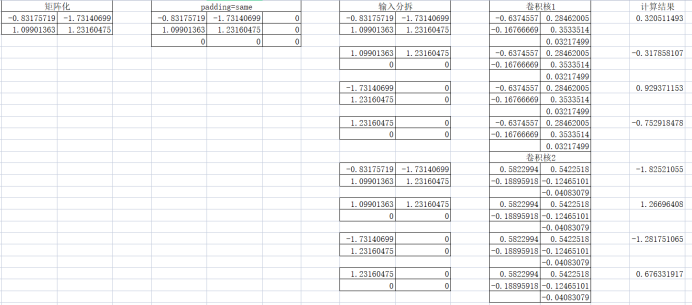
6、第二次池化
将前面的计算结果分别组成2个矩阵,然后分别做池化。由于尺寸的原因导致池化后就只有一个值了,实际如果输入够大的话,池化后的结果应该是2个矩阵。
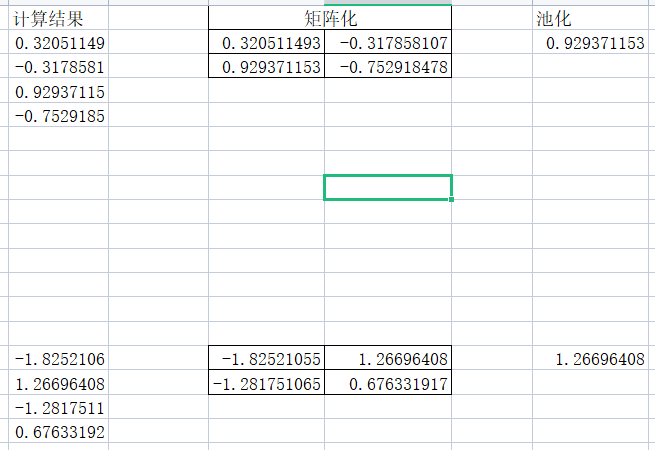
7、一维化
由于输出很少,所以一维化也很简单。如果池化结果是2个较大矩阵,一维化的过程就不那么直观了。
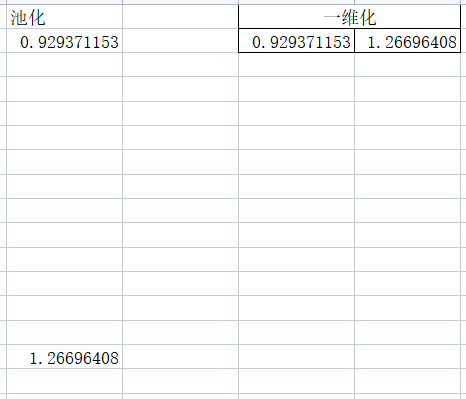
下面示例一下较大矩阵的一维化,其实就是两个矩阵穿插在一起了,而不是简单的左右拼接。

8、全连接层计算
全连接层计算非常简单了。
1)第一个全连接层
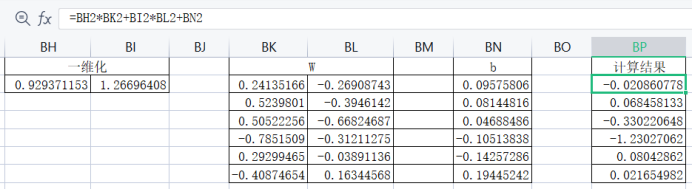
2)第二个全连接层计算
五、回顾
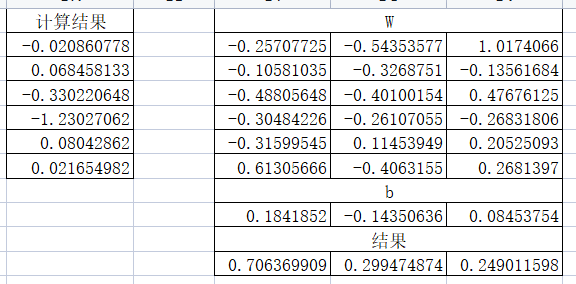
可以看到,我们手算的结果与TensorFlow计算结果大差不大,但还是有一点点的区别,可能原因是数值精度问题。
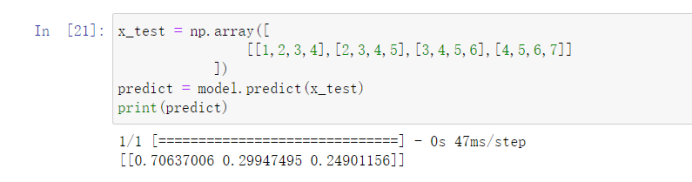
最后,一定要注意我们的输入是做了转置的。