前置环境:两台可以互通的centos服务器(服务器1、服务器2),docker,NVIDIA驱动
docker创建overlay共享网络
1)选用服务器1作为manage节点进行初始化,执行docker swarm init
Swarm initialized: current node (ly4dipghh8734nys3t7t68sfx) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-1zag1cf7n1o21cu88dyanbhlrbhrjicztf9qlyryt08w56k3ba-9pu6zhn2klfv2qm0bnaysm4lo 192.168.6.98:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
2)将服务器2加入集群
进入服务器2执行上面的join命令:
docker swarm join --token SWMTKN-1-1zag1cf7n1o21cu88dyanbhlrbhrjicztf9qlyryt08w56k3ba-9pu6zhn2klfv2qm0bnaysm4lo 192.168.6.98:2377
3)创建deepspeed环境需要的网络
docker network create --driver=overlay --attachable sharednet
4) 查看当前网络状态
在manage节点执行docker network ls
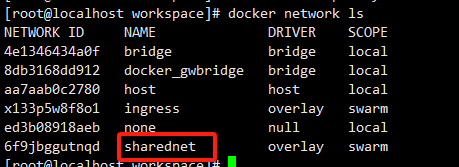
在work节点执行docker network ls
会发现没有 这条网络。
这条网络。
这时候我们只需要开启一个容器,强制指定网络为sharednet,docker就会自动同步对应网络了
docker run -dit --name alpine2 --network sharednet alpine
再次查看work节点的网络:
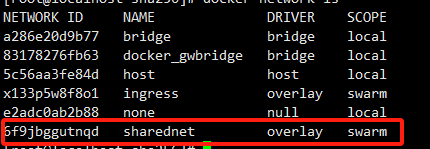
1、容器环境配置
以下步骤均需要在manage、work节点执行
创建一个 workspace 文件夹,内部的文件列表如下:
├── workspace/
├── code/
├── docker-compose.yml
├── Dockerfile
Dockerfile文件如下:
FROM nvidia/cuda:11.7.1-devel-ubuntu22.04 # 更新系统包 RUN apt-get update && apt-get install -y git build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev libreadline-dev libffi-dev liblzma-dev libbz2-dev curl wget net-tools iputils-ping pdsh # 安装Python WORKDIR /home/user RUN wget https://www.python.org/ftp/python/3.10.6/Python-3.10.6.tgz && \ tar -zvxf Python-3.10.6.tgz && cd Python-3.10.6 && \ ./configure --enable-optimizations && make -j 4 && make install
docker-compose.yml文件如下:
version: "3" services: llm: build: context: . dockerfile: Dockerfile container_name: llm tty: true restart: always ulimits: memlock: -1 stack: 67108864 shm_size: 40G deploy: resources: reservations: devices: - capabilities: [gpu] volumes: - ./code:/home/user/code:cached networks: - sharednet networks: sharednet: external: true
使用LLaMA-Factory项目中的chatglm2-6b进行微调:
# 进入工作目录 $ cd workspace # 克隆项目到code文件夹 $ git clone https://github.com/hiyouga/LLaMA-Factory code
使用 docker compose up -d --build 命令启动容器
分别进入容器内部docker exec -it 容器ID /bin/bash
1、验证网络是否畅通
分别进入manage节点与work节点查看ip
执行ifconfig
Manager:
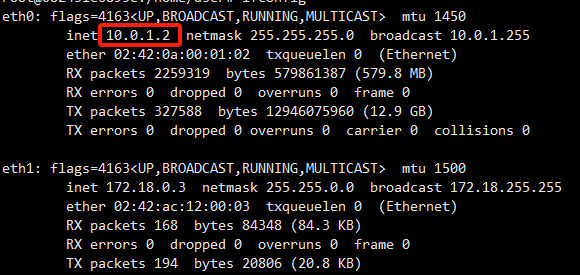
Worker:

两个环境互ping
root@453417f7b6d7:/home/user# ping 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.580 ms
64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.293 ms
64 bytes from 10.0.1.2: icmp_seq=3 ttl=64 time=0.321 ms
64 bytes from 10.0.1.2: icmp_seq=4 ttl=64 time=0.318 ms
root@082431c6895e:/home/user# ping 10.0.1.4
PING 10.0.1.4 (10.0.1.4) 56(84) bytes of data.
64 bytes from 10.0.1.4: icmp_seq=1 ttl=64 time=0.429 ms
64 bytes from 10.0.1.4: icmp_seq=2 ttl=64 time=0.347 ms
64 bytes from 10.0.1.4: icmp_seq=3 ttl=64 time=0.394 ms
64 bytes from 10.0.1.4: icmp_seq=4 ttl=64 time=0.364 ms
可以看到两服务器网络互通
1、开启免密访问
分别去manager,worker节点的容器中安装openssh-server服务并启动
# 安装ssh服务 apt-get install openssh-server -y # 启动ssh服务 /etc/init.d/ssh start
配置免密登录
1)在manage、worker节点的容器中执行ssh-keygen -t rsa,全部回车
2)将manager节点中的~/.ssh/id_rsa.pub的内容复制写入到manager节点和worker节点中的~/.ssh/authorized_keys文件中。
将worker节点中的~/.ssh/id_rsa.pub的内容复制写入到manager节点和worker节点中的~/.ssh/authorized_keys文件中。
3)在manage、worker节点的/etc/hosts添加:
10.0.1.2 node1 10.0.1.4 node2
4)测试两服务器之间是否可以ssh登录
manager节点:ssh root@10.0.1.4
work节点:ssh root@10.0.1.2
1、配置NCCL网络
查看容器使用的网卡:
这里我使用的网卡是eth0
配置命令:export NCCL_SOCKET_IFNAME=eth0
1、分布式训练
1)准备chatglm2-6b模型,放到/home/user/code
2)安装依赖
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3)hostfile文件配置
/home/user/code/目录下新建 hostfile 文件,内容如下:
node1 slots=2 node2 slots=2
slots代表使用2个GPU
4) ds_config.json配置
/home/user/code/目录下新建 ds_config.json 文件,写入:
{ "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "zero_allow_untested_optimizer": true, "fp16": { "enabled": "auto", "loss_scale": 0, "initial_scale_power": 16, "loss_scale_window": 1000, "hysteresis": 2, "min_loss_scale": 1 }, "zero_optimization": { "stage": 2, "allgather_partitions": true, "allgather_bucket_size": 5e8, "reduce_scatter": true, "reduce_bucket_size": 5e8, "overlap_comm": false, "contiguous_gradients": true } }
5、训练
在manager节点执行命令
deepspeed --hostfile hostfile src/train_bash.py \ --deepspeed ds_config.json \ --stage sft \ --model_name_or_path /home/user/code/chatglm2-6b \ --do_train \ --dataset alpaca_gpt4_zh \ --template chatglm2 \ --finetuning_type lora \ --lora_target query_key_value \ --output_dir chatglm2_sft \ --overwrite_cache \ --overwrite_output_dir \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 10000 \ --learning_rate 5e-5 \ --num_train_epochs 0.25 \ --plot_loss \ --fp16
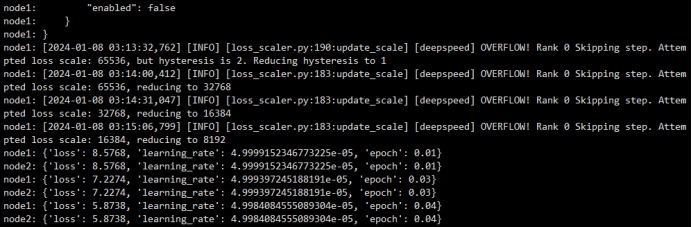
训练日志:
参考:
https://juejin.cn/post/7304182487683923994