description
给定 \(n\) 个字符串 \(S_i\),可以给每个串删除一个字符或者不动。求有多少种操作方案使得最后的 \(n\) 个字符串(可能有空的),字典序单调不降。
-
\(n\leq 10^5\)
-
\(\sum|S_i|\leq 10^6\)
solution
设 \(f_{i,j}\) 表示考虑前 \(i\) 个字符串,第 \(i\) 个字符串删去第 \(j\) 个位置(如果 \(j\) 为 \(0\) 则不删),前 \(i\) 个串的字典序单调不降的方案数。
有转移:
-
\(f_{1,j}=1\)
-
\(f_{i,j}=\sum\limits_{p=0}^{|S_{i-1}|} f_{i-1,p}[S_{i-1,p}\leq S_{i,j}]\)
其中 \(S_{i,p}\) 表示第 \(i\) 个字符串删去第 \(p\) 个字符(\(p\) 为 \(0\) 则不删)后剩下的字符串。
这么做的状态数是 \(O(\sum |S_i|)\) 的。
转移可以外层枚举 \(p\),内层枚举 \(j\),问题相当于对于一个给定的 \(S_{i-1,p}\),求有哪些位置 \(j\) 满足 \(S_{i-1,p}\leq S_{i,j}\)。
当 \(j=0\) 时扫一遍特殊处理一下,不影响复杂度。预处理 \(S_{i-1,p}\) 每个位置和 \(S_{i}\) 左移一位后最远可以匹配到哪里,再在处理 \(j=0\) 时顺便求出 \(S_{i-1,p}\) 和 \(S_{i,0}\) 的第一个失配的位置 \(maxpos\)。这样,对于每个 \(j\) 都可以通过下面的方式得到它和 \(S_{i-1,p}\) 的字典序大小关系。
如果 \(j>maxpos\),那么意味着只看在 \(j\) 之前的字符就可以得出 \(S_{i-1,p}\) 和 \(S_{i,j}\) 的大小关系,直接比较 \(maxpos\) 处的字符就行。如图:
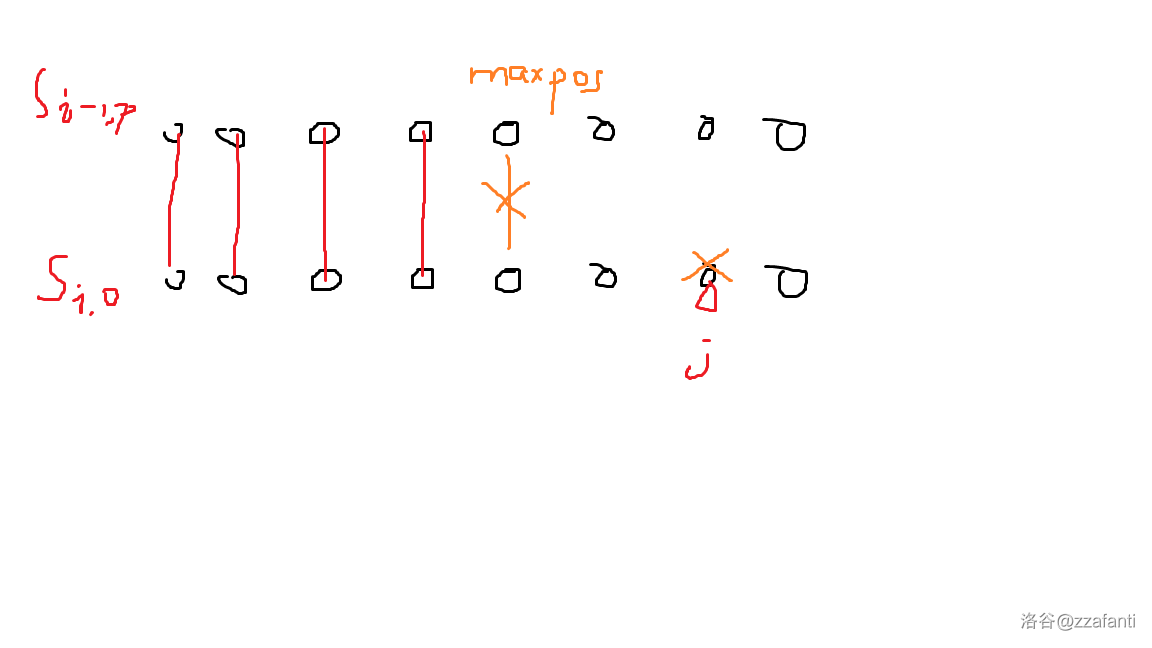
如果 \(j\leq maxpos\),那么删去 \(S_i\) 的第 \(j\) 个字符可能会影响两个字符串的第一个失配位置。利用之前预处理的 \(S_{i-1,p}\) 每个位置和 \(S_i\) 左移一位后最远可以匹配到的位置就可以比较了。如图:
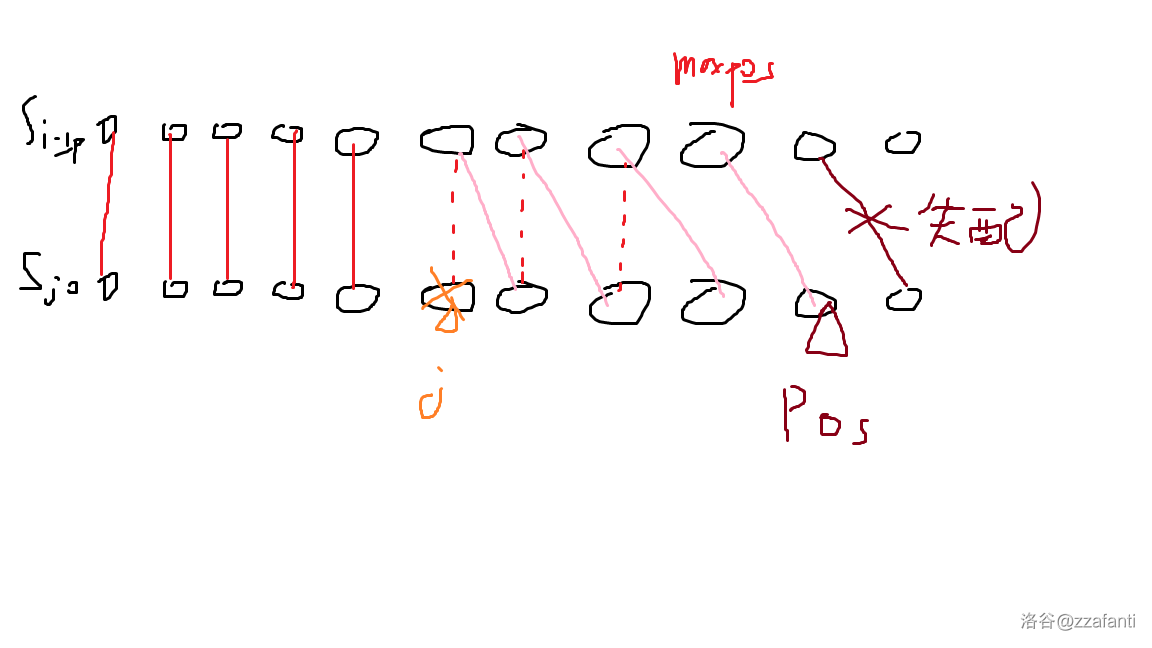
图中的 \(pos\) 就是我们预处理的位置。
这么做固定了 \(S_{i,p}\) 后每一步都线性的。整体时间复杂度 \(O((\sum |S_i|)^2)\)。可以通过 easier version。
考虑如何做 harder version。
打表发现按照上面的顺序转移没什么规律,转移过来的位置也比较乱。
思考一会儿可以发现,对于所有 \(i\),如果已知其删去一个字符的所有生成出来的字符串(包括原串)的字典序大小关系,按照从小到大的顺序枚举,则转移点集合也是单调不减的,这点很好理解,对于大的串,应该有更多串比它小。
这样就可以把所有这些串排序,然后维护指针,其前方的字符串都比当前串非严格地小,从前面那些 dp 值转移就好了。
理一下思路,现在有两个问题:给一个字符串的所有删去一个字符的串(和它自己)排序;以及快速询问输入的两个相邻的字符串各自删去不超过一个字符后剩下字符串的字典序大小关系。
part 1.
考虑第一个问题。
它等同于SNOI2019 字符串。
问题就是给定字符串 \(S\),\(S_i\) 表示 \(S\) 删掉第 \(i\) 个字符(\(i=0\) 则不删)后剩下的字符串,给序列 \(a=0,1,2,\dots,|S|\) 排序,使得 \(S_{a_1}\leq S_{a_2}\leq\dots\leq S_{a_{|S|+1}}\)。
考虑像上面 easier version 处理删去字符导致的偏移的情况的方法。预处理每个位置 \(x\) 和原字符串左移一位后的最远匹配位置 \(nxt_x\),排序的时候用这个位置比较就行了。如下图,比较 \(x\) 和 \(y\) 的时候,假设 \(x<y\),仿照上面 easier version 讨论的方法,分别处理 \(nxt_x<y\) 和 \(nxt_{x}\ge y\) 的情况即可。注意特殊处理 \(0\)。
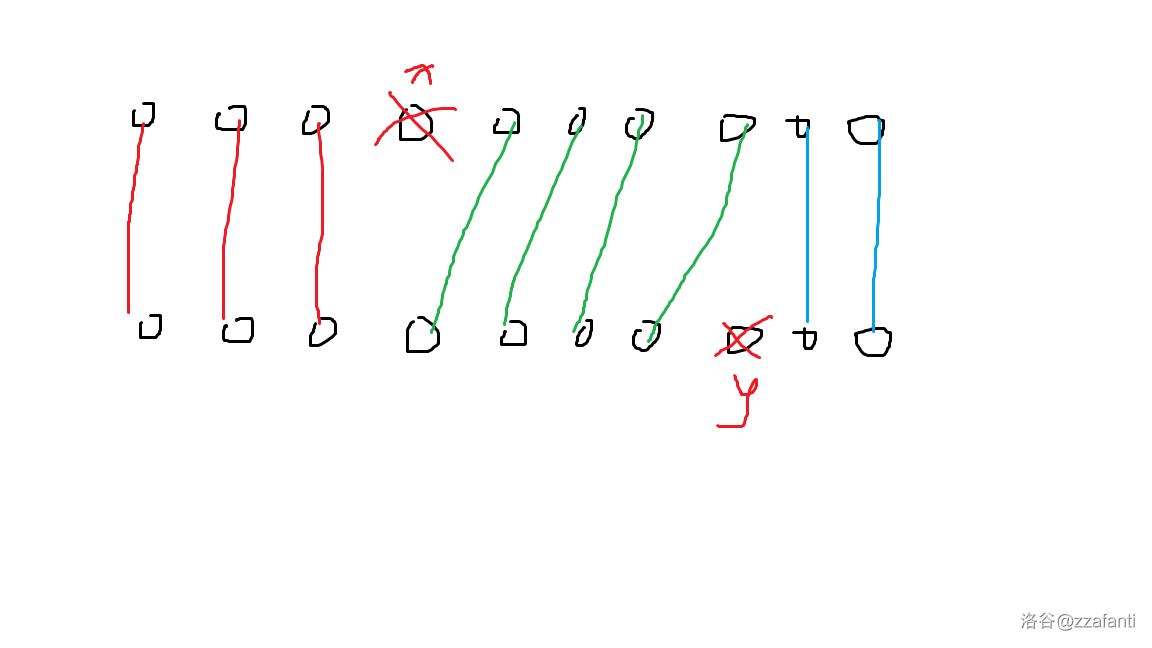
一个可行的排序方式:
...
sort(now.begin(),now.end(),[&](const int x,const int y)->bool{
int a=min(x,y),b=max(x,y);
if(a==-1){
return (x>y)^(s[nxt[b]-1]<s[nxt[b]]);
}
if(nxt[a]>b) return x<y;
return (x>y)^(s[nxt[a]]<s[nxt[a]-1]);
});
...
时间复杂度 \(O(|S|\log |S|)\)
对于原问题,把每个串都这样排序,时间复杂度 \(O(\sum |S|\log \sum |S|)\)。
part 2.
再考虑第二个问题。
快速询问两个相邻字符串各删去不超过一个字符后剩下的字符串的字典序。
相当于分成三段比较,从前到后每一段分别二分失配位置就行了,比较两个子串是否相等可以使用字符串哈希。单次询问是 \(\log\) 的。
理论上这题就做完了,时间复杂度 \(O(\sum |S| \log \sum |S|)\)。
但是第二个问题中二分的过程细节很多,有不少边界情况要处理。
这里建议:
-
给输入的串末尾都插入两个 ASCII 值小于
a的字符,防止越界。 -
第二个问题先用暴力实现,可以轻松跑过 easier version,确认第一个问题没有写挂之后再写二分。
-
对于不删字符的情况,转化为删去末尾人为添加的倒数第二个特殊字符。
-
仔细检查是否越界,不然会有玄学错误,建议多 assert。
-
此题不卡哈希,自然溢出可过。