https://blog.csdn.net/Hehuyi_In/article/details/106579031
一、 问题背景
给一个业务表online建索引时遇到了ORA-01450 maximum key length (3215) exceeded报错,看字面意思是字段太长了,检查表字段类型发现基本都是nvarchar2(2000),有些字段(例如unit)明显是不需要这么长的,表的设计有问题,联系开发按实际需求改短后能正常创建。
奇怪的是表的id字段类型也是nvarchar2(2000),但上面是有索引的,好奇为啥这个字段就能建上,以及为啥maximum key length是3215。
二、 报错分析
根据网上文章,9i之后每个index key最大只能为block size的80%。理论上8k的块可以创建最大长度为8096*80%约为6400左右长度的index。但是,online创建(包括rebuild)的过程中会生成一个中间的IOT表,用来记录创建过程中的变化。IOT表的限制比较严格,导致8k的block size最大长度只能有3215。当然普通创建的索引也是有限制的:ORA-01450: maximum key length (6398) exceeded。
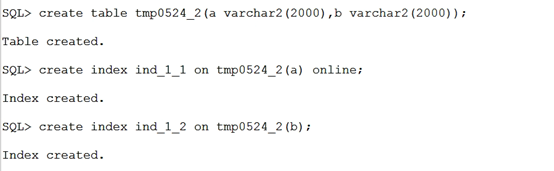
按上面的建测试表和索引,发现的确online创建报错,而普通创建可以成功。因为nvarchar2(2000)字段最大可能长度是4000,创建索引时并不会看实际字段长度,直接按的最大长度。

建联合索引会报错,因为nvarchar2(2000)+nvarchar2(2000)字段最大可能长度是8000

再测试varchar2(2000)类型,发现普通创建和online都能成功,因为varchar2(2000)字段最大可能长度是2000
关于索引key最大长度,在文档 ID 136158.1中给出了不同BLOCK SIZE的限制,你会发现8K BLOCK SIZE的maximum key length 文档中写的是3218而不是我们遇到的3215。这可能是由于文档是针对8i的版本,在新版本中这个值变成了3215。
ORA-01450 maximum key length (758) exceeded ->(2K Block)
ORA-01450 maximum key length (1578) exceeded ->(4K block)
ORA-01450 maximum key length (3218) exceeded ->(8K Block)
ORA-01450 maximum key length (6498) exceeded ->(16K Block)
报错中限制的KEY SIZE包含:索引的长度+存储索引长度的空间(2字节) + ROWID (6字节)+存储ROWID长度占用空间 (1字节),所以真正能够存放的列数据的长度只有3218-2-6-1=3209,新版本应该是3215-2-6-1=3206。
- 这里的3209并不是实际的数据的长度,而是定义的列的长度。就像前面的例子,定义NVARCHAR2(2000),即使里面只存放了一个字符,创建索引时也会报这个错。ORACLE担心以后里面存放的数据万一超过了,索引那边没办法交代,所以干脆从源头上掐死。
- 那能不能先定义一个小列,创建完索引后再把这个列的值改大?不行,你会遇到报错:ORA-01404: ALTER COLUMN will make an index too large,告诉你加大列长度的命令可能会导致索引太大
- 这里面还有一个陷阱,就是你索引创建好了,一直使用也没问题,但是当你ONLINE REBUILD的时候却发现他的KEY SIZE超过限制了,导致索引只能不ONLINE的REBUILD,这对于24*7的系统而且必须REBUILD的情况比较痛苦。
常用的数据类型的KEY长度计算如下:
日期类型的长度是7;字符类型就是字段定义时候的长度;数字类型是22(数字类型的长度=精度/2+1),如果是负数,那么长度要再加1;如果是函数索引,那就要按照函数索引的返回值来进行计算。
为什么ONLINE创建只能使用不到BLOCK SIZE一半的空间?
ORACLE的管理手册中指明了索引的大小不能大于BLOCK_SIZE的一半,然后这一半的空间去掉ORACLE自己的PCTFREE、INITRANS以及BLOCK HEADER等等预留空间,实际可以使用的空间比一半要小很多。
当ONLINE创建一个索引,ORACLE为这个表的变化创建一个中间表,创建好后,ORACLE用表数据的一致性拷贝去创建一个新的索引,然后再把变化的记录拷贝到新创建的索引中,最后更新数据字典,删除临时段并删除这个中间表。这个过程将会锁表两次(ROW SHARE MODE)。一次是开始创建中间表时,另一次是结束时删除中间表。
中间表是一个名字类似SYS_JOURNAL_NNNNN的IOT表,其中的NNNNN是ONLINE REBUILD的索引的OBJECT_ID。因为IOT表的限制只能使用BLOCKSIZE的40%左右,而且这个IOT表的KEY就是索引中使用的KEY并加上ROWID的值,所以只有ONLINE创建或者REBUILD索引的时候会碰到这个问题。
下面来做一个演示,先创建一个表:
create table test(a varchar2(10),b varchar2(11),c varchar2(12),d number(10),e varchar2(13));然后打开跟踪并ONLINE的创建索引:
create index idx_test on test(a,b,c,d,e) online;关闭跟踪并查看TRACE文件,可以发现如下语句:
- create table "SYS"."SYS_JOURNAL_74346" (C0 VARCHAR2(10), C1 VARCHAR2(11), C2 VARCHAR2(12), C3 NUMBER(10,0), C4
- VARCHAR2(13), opcode char(1), partno number, rid rowid, primary key( C0, C1, C2, C3, C4 , rid )) organization
- index TABLESPACE "SYSTEM"
其中前面的C0,C1等列就是索引的KEY值,索引由几列组成,临时IOT表也会对应创建,后面三列是不变的,根据字面意思推测应该是操作的代码(增加、删除、更新) 、分区号(分区索引用到)、ROWID。而主键是由所有的KEY值和ROWID列组成,这也正好跟前面的长篇大论相吻合。至于IOT为啥只能用一半,有些说是为了B*TREE的分裂,有些说是ORACLE老版本的小问题,结果为了兼容一直没改。
四、解决方法
查询文档,这个问题其实有挺多绕过的方法,整理学习一下。
1. 改短字段后创建
对于表设计明显不合理的情况,这是比较合理的方法。
查看字段实际最大长度
- select max ( length ( text_column ) ) mx_char_length,
- max ( lengthb ( text_column ) ) mx_byte_length
- from some_table;
改短字段长度
alter table some_table modify text_column nvarchar2(100);如果确实不能改短,下面有一些workaround,但它们都有各自的限制,需要根据实际选择。
2. 不使用online创建
对于前面的例子,nvarchar2(2000)的字段可以用这个方法绕过最大长度限制。但也就像之前写的,这个长度没办法创建联合索引,以后也不能使用online rebuild,对于7*24小时的系统,如果是大表可能难以接受。
3. 使用更大的block size存储索引
将索引存放在单独的表空间,并将表空间block size设为16k或32k,当然也需要先设置好DB_nK_CACHE_SIZE 参数。这种方法打破了DB的标准化,可能会使运维管理更加复杂。
- alter system set DB_32K_CACHE_SIZE=256M;
- create tablespace tblsp_32k_blocks datafile 'tblsp_32k_blocks' size 1m blocksize 32768;
- create index text_index on some_table(text_column) tablespace tblsp_32k_blocks;
4. 创建基于STANDARD_HASH函数的索引
standard_hash函数会返回一个固定长度的值,在等值查询时能用到该索引。
- create index text_index on some_table(standard_hash(text_column));
-
- select * from some_table where text_column = 'this';
- ----------------------------------------------------------
- | Id | Operation | Name |
- ----------------------------------------------------------
- | 0 | SELECT STATEMENT | |
- |* 1 | TABLE ACCESS BY INDEX ROWID BATCHED| SOME_TABLE |
- |* 2 | INDEX RANGE SCAN | TEXT_INDEX |
- ----------------------------------------------------------
但范围查询和like查询都用不到
- select * from some_table where text_column >= 't' and text_column<'u';
- ----------------------------------------
- | Id | Operation | Name |
- ----------------------------------------
- | 0 | SELECT STATEMENT | |
- |* 1 | TABLE ACCESS FULL| SOME_TABLE |
- ----------------------------------------
-
- select * from some_table where text_column like 'this%';
- ----------------------------------------
- | Id | Operation | Name |
- ----------------------------------------
- | 0 | SELECT STATEMENT | |
- |* 1 | TABLE ACCESS FULL| SOME_TABLE |
- ----------------------------------------
5. 创建基于substr函数的索引
对于范围查询,可以使用基于substr函数的索引(like依然用不到),但是它可能会导致查询效率较低。
- create index text_substr_index on some_table(substr(text_column,1,10));
-
- select * from some_table where text_column = 'this';
- -----------------------------------------------------------------
- | Id | Operation | Name |
- -----------------------------------------------------------------
- | 0 | SELECT STATEMENT | |
- |* 1 | TABLE ACCESS BY INDEX ROWID BATCHED| SOME_TABLE |
- |* 2 | INDEX RANGE SCAN | TEXT_SUBSTR_INDEX |
- -----------------------------------------------------------------
-
- select * from some_table where text_column >= 't' and text_column < 'u';
- -----------------------------------------------------------------
- | Id | Operation | Name |
- -----------------------------------------------------------------
- | 0 | SELECT STATEMENT | |
- | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| SOME_TABLE |
- | 2 | INDEX RANGE SCAN | TEXT_SUBSTR_INDEX |
- -----------------------------------------------------------------
-
- select * from some_table where text_column like 'this%';
- ----------------------------------------
- | Id | Operation | Name |
- ----------------------------------------
- | 0 | SELECT STATEMENT | |
- | 1 | TABLE ACCESS FULL| SOME_TABLE |
- ----------------------------------------

6. 定义virtual列
虚拟列其实就是对列进行运算或者在列上使用函数,oracle在运行时才会计算该列的值。我们可以用standard_hash函数建虚拟列,然后对该列建普通索引。虚拟列相比函数索引有以下好处:
- 优化器可获得虚拟列的统计信息
- 能够看到索引值,更易于理解
- alter table some_table add text_hash varchar2(40 char) as (standard_hash(text_column));
- create index vc_text_hash_index on some_table (text_hash);
7. 使用全文索引(Oracle Text Index)
创建时需要指定indextype子句,查询时使用contains操作符
- create index oracle_text_index on some_table(text_column) indextype is ctxsys.context;
-
- select * from some_table where contains (text_column,'value')>0;
参考
https://blog.csdn.net/tnndwdl/article/details/78452967
https://blogs.oracle.com/sql/how-to-fix-ora-01450-maximum-key-length-6398-exceeded-errors
ORA-01450 and Maximum Key Length - How it is Calculated (文档 ID 136158.1)
</article>