0.配置
import os
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
# os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
!pip install torchmetrics
import torch
import torchvision
import torchkeras
import torchmetrics
print('torch', torch.__version__)
print('torchvision', torchvision.__version__)
print('torchkeras', torchkeras.__version__)
print('torchmetrics', torchmetrics.__version__)
"""
torch 2.1.1+cu118
torchvision 0.16.1+cu118
torchkeras 3.9.4
torchmetrics 1.2.1
"""
1.准备数据
cifar2数据集为cifar10数据集的子集,只包括前两种类别airplane和automobile。
训练集有airplane和automobile图片各5000张,测试集有airplane和automobile图片各1000张。
cifar2任务的目标是训练一个模型来对飞机airplane和机动车automobile两种图片进行分类。
我们准备的Cifar2数据集的文件结构如下所示。
在Pytorch中构建图片数据管道有两种方法。
第一种是使用torchvision中的dataset.ImageFolder来读取图片然后用DataLoader来并行加载。
第二种是通过继承torch.utils.data.Dataset实现用户自定义读取逻辑,然后用DataLoader来并行加载。
第二种方法是读取用户自定义数据集的通用方法,既可以读取图片数据集,也可以读取文本数据集。
本篇我们介绍第一种方法。
import torch
from torchvision import transforms as T
from torchvision import datasets
import numpy as np
import pandas as pd
transform_img = T.Compose(
[T.ToTensor()]
)
def transform_label(x):
return torch.tensor([x]).float()
ds_train = datasets.ImageFolder('./dataset/cifar2/train/',
transform=transform_img, target_transform=transform_label)
ds_val = datasets.ImageFolder('./dataset/cifar2/test/',
transform=transform_img, target_transform=transform_label)
print(ds_train.class_to_idx)
"""
{'0_airplane': 0, '1_automobile': 1}
"""
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=50, shuffle=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=50, shuffle=False)
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
# 查看部分样本
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
for i in range(9):
img, label = ds_train[i]
img = img.permute(1, 2, 0)
ax = plt.subplot(3, 3, i+1)
ax.imshow(img.numpy())
ax.set_title('label=%d' % label.item())
ax.set_xticks([])
ax.set_yticks([])
plt.show()

# Pytorch的图片默认顺序是Batch,channel,Width,Height
for features, labels in dl_train:
print(features.shape, labels.shape)
break
"""
torch.Size([50, 3, 32, 32]) torch.Size([50, 1])
"""
2.定义模型
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器
(nn.Sequential,nn.ModuleList,nn.ModuleDict)进行封装。
此处选择通过继承nn.Module基类构建自定义模型。
# 自适应最大池化与普通最大池化的区别在于无论输入特征的大小如何,其输出特征大小由我们自己通过output_size参数指定
pool = torch.nn.AdaptiveMaxPool2d((1, 1))
t = torch.randn(10, 8, 32, 32)
pool(t).shape
"""
torch.Size([10, 8, 1, 1])
"""
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)
self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5)
self.dropout = torch.nn.Dropout2d(p=0.1)
self.adaptive_pool = torch.nn.AdaptiveMaxPool2d((1, 1))
self.flatten = torch.nn.Flatten()
self.linear1 = torch.nn.Linear(64, 32)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(32, 1)
def forward(self, x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
return x
net = Net()
print(net)
"""
Net(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1))
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=64, out_features=32, bias=True)
(relu): ReLU()
(linear2): Linear(in_features=32, out_features=1, bias=True)
)
"""
import torchkeras
print(torchkeras.summary(net, input_data=features))
"""
--------------------------------------------------------------------------
Layer (type) Output Shape Param #
==========================================================================
Conv2d-1 [-1, 32, 30, 30] 896
MaxPool2d-2 [-1, 32, 15, 15] 0
Conv2d-3 [-1, 64, 11, 11] 51,264
MaxPool2d-4 [-1, 64, 5, 5] 0
AdaptiveMaxPool2d-5 [-1, 64, 1, 1] 0
Flatten-6 [-1, 64] 0
Linear-7 [-1, 32] 2,080
ReLU-8 [-1, 32] 0
Linear-9 [-1, 1] 33
==========================================================================
Total params: 54,273
Trainable params: 54,273
Non-trainable params: 0
--------------------------------------------------------------------------
Input size (MB): 0.000076
Forward/backward pass size (MB): 0.347420
Params size (MB): 0.207035
Estimated Total Size (MB): 0.554531
--------------------------------------------------------------------------
"""
3.训练模型
Pytorch通常需要用户编写自定义的训练循环,训练循环的代码风格因人而异。
有三种典型的训练循环代码风格:脚本形式训练循环,函数形式训练循环,类形式训练循环。
此处介绍一种较为通用的仿照Keras风格的函数形式的训练循环。
import os
import sys
import time
import datetime
from tqdm import tqdm
import torch
from copy import deepcopy
def printlog(info):
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print(str(info)+"\n")
class StepRunner():
def __init__(self, net, loss_fn, stage='train', metrics_dict=None, optimizer=None):
self.net, self.loss_fn, self.metrics_dict, self.stage = net, loss_fn, metrics_dict, stage
self.optimizer = optimizer
def step(self, features, labels):
# loss
preds = self.net(features)
loss = self.loss_fn(preds, labels)
# backward
if self.optimizer is not None and self.stage == 'train':
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
# metrics
step_metrics = {self.stage + '_' + name: metric_fn(preds, labels).item() for name, metric_fn in self.metrics_dict.items()}
return loss.item(), step_metrics
def train_step(self, features, labels):
self.net.train()
return self.step(features, labels)
@torch.no_grad()
def eval_step(self, features, labels):
self.net.eval()
return self.step(features, labels)
def __call__(self, features, labels):
if self.stage == 'train':
return self.train_step(features, labels)
else:
return self.eval_step(features, labels)
class EpochRunner:
def __init__(self, steprunner):
self.steprunner = steprunner
self.stage = steprunner.stage
def __call__(self, dataloader):
total_loss, step = 0, 0
loop = tqdm(enumerate(dataloader), total=len(dataloader), file=sys.stdout)
for i, batch in loop:
loss, step_metrics = self.steprunner(*batch)
step_log = dict({self.stage + '_loss': loss}, **step_metrics)
total_loss += loss
step += 1
if i != len(dataloader) - 1:
loop.set_postfix(**step_log)
else:
epoch_loss = total_loss / step
epoch_metrics = {self.stage + '_' + name: metric_fn.compute().item() for name, metric_fn in self.steprunner.metrics_dict.items()}
epoch_log = dict({self.stage + '_loss': epoch_loss}, **epoch_metrics)
loop.set_postfix(**epoch_log)
for name, metric_fn in self.steprunner.metrics_dict.items():
metric_fn.reset()
return epoch_log
def train_model(net, optimizer, loss_fn, metric_dict, train_data, val_data=None, epochs=10,
ckpt_path='checkpoint.pt', patience=5, monitor='val_loss', mode='min'):
history = {}
for epoch in range(1, epochs + 1):
printlog('Epoch {0} / {1}'.format(epoch, epochs))
# train
train_step_runner = StepRunner(net=net, stage='train', loss_fn=loss_fn, metrics_dict=deepcopy(metric_dict), optimizer=optimizer)
train_epoch_runner = EpochRunner(train_step_runner)
train_metrics = train_epoch_runner(train_data)
for name, metric in train_metrics.items():
history[name] = history.get(name, []) + [metric]
# validate
if val_data:
val_step_runner = StepRunner(net=net, stage='val', loss_fn=loss_fn, metrics_dict=deepcopy(metric_dict))
val_epoch_runner = EpochRunner(val_step_runner)
with torch.no_grad():
val_metrics = val_epoch_runner(val_data)
val_metrics['epoch'] = epoch
for name, metric in val_metrics.items():
history[name] = history.get(name, []) + [metric]
# early-stopping
arr_scores = history[monitor]
best_score_idx = np.argmax(arr_scores) if mode == 'max' else np.argmin(arr_scores)
if best_score_idx == len(arr_scores) - 1:
torch.save(net.state_dict(), ckpt_path)
print('<<<<<< reach best {0} : {1} >>>>>>'.format(monitor, arr_scores[best_score_idx]), file=sys.stderr)
if len(arr_scores) - best_score_idx > patience:
print('<<<<<< {} without imporvement in {} epoch, early stopping >>>>>>'.format(monitor, patience), file=sys.stderr)
break
net.load_state_dict(torch.load(ckpt_path))
return pd.DataFrame(history)
import torchmetrics
class Accuracy(torchmetrics.Accuracy):
def __init__(self, dist_sync_on_step=False):
super().__init__(dist_sync_on_step=dist_sync_on_step)
def update(self, preds: torch.Tensor, targets: torch.Tensor):
super().update(torch.sigmoid(preds), targets.long())
def compute(self):
return super().compute()
loss_fn = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
metric_dict = {'acc': Accuracy(task='binary')}
dfhistory = train_model(net, optimizer, loss_fn, metric_dict, train_data=dl_train, val_data=dl_val, epochs=10,
patience=5, monitor='val_acc', mode='max')
4.评估模型
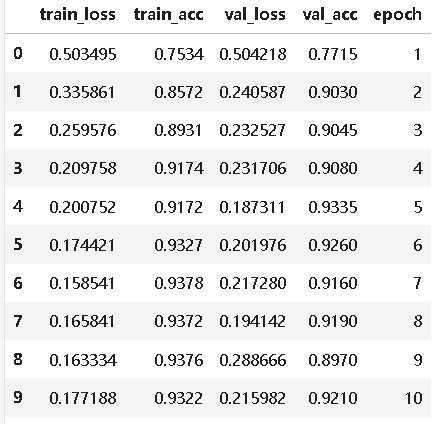
dfhistory
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory['train_' + metric]
val_metrics = dfhistory['val_' + metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation ' + metric)
plt.xlabel('Epochs')
plt.ylabel(metric)
plt.legend(['train_' + metric, 'val_' + metric])
plt.show()
plot_metric(dfhistory, 'loss')

plot_metric(dfhistory, 'acc')

5.使用模型
def predict(net, dl):
net.eval()
with torch.no_grad():
result = torch.nn.Sigmoid()(torch.cat([net.forward(t[0]) for t in dl]))
return result.data
# 预测概率
y_pred_probs = predict(net, dl_val)
y_pred_probs
"""
tensor([[7.5663e-03],
[2.0658e-05],
[1.2745e-04],
...,
[9.9374e-01],
[9.9579e-01],
[8.3239e-02]])
"""
# 预测类别
y_pred = torch.where(y_pred_probs > 0.5, torch.ones_like(y_pred_probs), torch.zeros_like(y_pred_probs))
y_pred
"""
tensor([[0.],
[0.],
[0.],
...,
[1.],
[1.],
[0.]])
"""
6.保存模型
print(net.state_dict().keys())
"""
odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'linear1.weight', 'linear1.bias', 'linear2.weight', 'linear2.bias'])
"""
# 保存模型参数
torch.save(net.state_dict(), './data/net_parameter.pt')
net_clone = Net()
net_clone.load_state_dict(torch.load('./data/net_parameter.pt'))
predict(net_clone, dl_val)
"""
tensor([[7.5663e-03],
[2.0658e-05],
[1.2745e-04],
...,
[9.9374e-01],
[9.9579e-01],
[8.3239e-02]])
"""