day01-XML&tomcat
XML介绍
XML:eXtendsible markup language 可扩展的标记语言
XML有什么用?
1.可以用来保存数据
2.可以用来做配置文件
3.数据传输载体
定义XML
其实就是一个文件,文件的后缀为 .xml
文档声明
简单声明:version:解析这个xml的时候,使用什么版本的解析器解析
<?xml version="1.0" ?>
encoding:解析xml中的文字的时候,使用什么编码来翻译
<?xml version="1.0" encoding="gbk" ?>
standalone:no-该文档会依赖关联其他文档,yes-这是一个独立的文档
<?xml version="1.0" encoding="gbk" standalone="no" ?>
encoding详解
在解析这个xml的时候,使用什么编码去解析。---解码
默认文件保存的时候,使用的是GBK的编码保存。
所以要想让我们的xml能够正常的显示中文,有两种解决办法
1.让encoding也是GBK或者gb2312
2.如果encoding是utf-8,那么保存文件的时候也必须使用utf-8
3.保存的时候见到的ANSI对应的其实就是我们的本地编码GBK
为了通用,建议使用UTF-8编码保存,以及coding都是utf-8
元素定义(标签)
1.其实就是里面的标签,<>括起来的都叫元素。成对出现。如下:
<stu></stu>
2.文档声明下来的第一个元素叫做根元素(根标签)
3.标签里面是可以嵌套标签的
4.空标签:既是开始也是结束,一般配合属性来用(<img src="" />)
5.标签可以自定义(有一套命名规则需遵守)
简单元素&复杂元素
简单元素:元素里面包含了普通的文字
复杂元素:元素里面还可以嵌套其他的元素
属性的定义
定义在元素里面,<元素名称 属性名称="属性的值"></元素名称>
XML注释
与html注释一样:<!-- -->
说明:xml的注释,不允许放置在文档的第一行,必须在文档声明的下面。
CDATA区
非法字符
严格地讲,在xml中仅有字符"<"和"&"是非法的,省略号、引号和大于号是合法的,但是把它们替换为实体引用是个好的习惯。
< <
& &
如果某段字符串里面有过多的字符,并且里面包含了类似标签或者关键字的这种文字,不想让xml的解析器去解析。那么可以使用CDATA来包装。不过这个CDATA一般比较少看到。通常在服务器给客户端返回数据的时候。
<desc><![CDATA[<a href="#">我爱黑马训练营</a>]]></desc>
XML解析
其实就是获取元素里面的字符数据或者属性数据。
XML解析方式(DOM&SAX)
xml解析方式有很多种,但是常用的有两种。
DOM(document object model):把整个xml全部读取到内存当中,形成树状结构。整个文档称之为document对象,属性对应Attribute对象,所有的元素节点对应Element对象,文本也可以称之为Text对象,对上所有对象都可以称之为Node节点。如果xml特别大,那么将会造成内存溢出。可以对文档进行增删操作。
SAX(Simple API for XML):基于事件驱动。读取一行,解析一行。不会造成内存溢出。不可以进行增删,只能查询。
针对这两种解析方式的API
一些组织或者公司,针对以上两种解析方式,给出的解决方案有哪些?
jaxp sun公司,比较繁琐
jdom
dom4j 使用比较广泛
Dom4j基本用法
element.element("stu"): 返回该元素下的第一个stu元素
element.elements():返回该元素下的所有子元素
1.创建SaxReader对象
2.指定解析的xml
3.获取根元素
4.根据根元素获取子元素或者下面的子孙元素
//1.创建sax读取对象
SAXReader reader = new SAXReader();
//2.指定解析的xml源
Document document = reader.read(new File("src/xml/stus/xml"));
//3.得到元素
//得到根元素
Element rootElement = document.getRootElement();
//获取根元素下面的子元素age
//rootElement.element("age");
//获取根元素下面的所有子元素 stu元素
List<Element> elements = rootElement.elements();
//获取根元素下的所有stu元素===待确认此句和上一句的区别
List<Element> list = rootElement.elements("stu");
//遍历所有的stu元素
for(Element element:elements){
//获取stu元素下面的name元素
String name = element.element("name").getText();
}
Dom4j的Xpath使用
dom4j里面支持Xpath的写法。Xpath其实就是xml的路径语言,支持我们在解析xml的时候,能够快速的定位到具体的某一个元素。
1.添加jar包依赖(jaxen-1.1-beta-6.jar)
2.在查找指定节点的时候,根据Xpath语法规则来查找
3.后续的代码与以前的解析代码一样。
//要想使用Xpath,还得添加支持的jar 获取的是第一个 只返回一个
Element nameElement = (Element) rootElement,selectSingleNode("//name");
System.out.println(nameElement.getText());
//获取文档里面的所有name元素
List<Element> list = rootElement.selectNodes("//name");
for(Element element : list){
System.out.println(element.getText());
}
XML约束
怎么规定元素只能出现一次,不能出现多次,甚至是规定里面只能出现具体的元素名字。
DTD
语法自成一派,早期就出现的,可读性比较差。
1.引入网络上的DTD
<!-- 引入dtd来约束这个xml--> <!--文档类型 根标签名字 网络上的dtd dtd的名称 dtd的路径 <!DOCTYPE stus PUBLIC "//UNKNOWN/" "unkonwn.dtd">-->
2.引入本地的DTD
<!--文档类型 根标签名字 引入本地的dtd dtd的位置 <!DOCTYPE stus SYSTEM "stus.dtd">-->
3.直接在XML里面嵌入DTD的约束规则
<!--xml文档里面直接嵌入DTD的约束法则--> <!DOCTYPE stus[
<!ELEMENT stus(stu)> :stus下面有一个元素stu,但是只有一个
<!ELEMENT stu(name,age)> :stu下面有两个元素name,age 顺序必须name-age
<!ELEMENT name(#PCDATA)> //简单元素的写法,PCDATA=parser character data(转译字符数据)
<!ELEMENT age(#PCDATA)>
<!--<!ATTLIST 元素名称 属性名称 属性类型 默认值>--> //默认值有三个选项值:#IMPLIED表示可有可无,#FIXED,#REQUESED
<!ATTLIST stu id CDATA #IMPLIED> :stu有一个属性 文本类型,该属性可有可无
元素的个数:
+ 一个或多个
* 零个或多个
?零个或一个
<!ELEMENT stus(stu)*>
属性的类型定义:
CDATA:属性是普通文字
ID:属性的值必须唯一
<!ELEMENT stu(name,age)> 按照顺序来
<!ELEMENT stu(name|age)> 两个中只能包含一个子元素
]>
<stus>
<stu>
<name>张三</name>
<age>18</age>
</stu>
</stus>
Schema
其实就是一个xml,使用xml的语法规则,xml解析器解析起来比较方便,是为了替代DTD,但是Schema约束文本内容比DTD的内容还要多,所以目前也没有真正意义上的替代。
约束文档:teacher.xsd
<!--xmlns:xml namespace :名称空间/命名空间 targetNamespace:目标名称空间:下面定义的那些元素都与这个名称空间绑定上。 elementFormDefault:元素的格式化情况。-->
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/teacher"
elementFormDefault="qualified">
<element name="teachers">
<complexType>
<sequence maxOccurs="unbounded"> //teachers标签下面的teacher元素可以出现无数个,也可以指定具体的数值,如:maxOccurs="2",表示只能出现2个
<!--这是一个复杂元素-->
<element name="teacher">
<complexType>
<sequence>
<!--以下两个是简单元素-->
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</teachers>
实例文档:
<!--xmlns:xsi:这里必须是这样的写法,也就是这个值已经固定了。 xmlns: 这里是名称空间,也固定了,写的是schema里面的顶部目标名称空间 xsi:schemaLocation:有两段:前半段是名称空间,也是目标空间的值,后面是约束文档的路径。-->
<teachers
xmlns:xsi="http://www.w3.org/2001/CMLSchema-instance"
xmlns="http://www.example.org/teacher"
<!--
xmlns:aa="http://www.itheima.org/teacher"
xmlns:bb="http://www.example.org/teacher" -->
xsi:schemaLocation="http://www.example.org/teacher teacher.xsd">
<teacher>
<name>zhangsan</name>
<!--<aa:name>zhangsan</aa:name>--> //当有多个schema文件,里面同时对name字段进行了约束,一个要求是string,另一个要求是int,那么要指定具体需遵守是哪个命名空间下的schema约束文件
<age>18</age>
</teacher>
</teachers>
名称空间的作用
一个xml如果想指定它的约束规则,假设使用的是DTD,那么这个xml只能指定一个DTD,不能指定多个DTD,但是如果一个xml的约束是定义在schema里面,并且是多个schema,那么是可以的,简单的说: 一个xml可以引用多个schema约束,但是只能引用一个DTD约束。
名称空间的作用就是在写元素的时候,可以指定该元素使用的是哪一套约束规则,默认情况下,如果只有一套规则,那么都可以这么写
<name>zhangsan</name>
服务器
其实服务器就是一台电脑,配置比一般的要好。
web服务器软件
客户端在浏览器的地址栏输入地址,然后web服务器软件,接收请求,然后响应消息。
处理客户端的请求,返回资源|信息。
web应用 需要服务器支撑。 index.html
Tomcat apache
WebLogic BEA
websphere IBM
IIS 微软
tomcat安装
1.直接解压,然后找到bin/startup.bat
2.启动之后,如果能够正常看到黑窗口,表明已经成功安装,为了确保万无一失,最好在浏览器的地址栏上输入:http://localhost:8080,如果有看到内容,就表明成功了。
3.如果双击了startup.bat,看到一闪而过的情形,一般都是JDK的环境变量没有配置(JAVA_HOME)
如何把一个项目发布到tomcat中
需求:如何能让其他的电脑访问我这台电脑上的资源。stu.xml
1.拷贝这个文件到webapps/ROOT底下,在浏览器里面访问:
http://localhost:8080/stu.xml
在webapps下面新建一个文件夹xml,然后拷贝文件放置在这个文件夹中
http://localhost:8080/xml/stu.xml
http://localhost:8080:其实对应的是到webapps/root
http://localhost:8080/xml/:对应的是webapps/xml
2.配置虚拟路径
配置说明的文档查看路径:使用localhost:8080打开tomcat首页,在左侧找到tomcat的文档入口(tomcat document),点击进去后,在左侧接着找到Context入口,点击进入。
http://localhost:8080/docs/config/contect.html
1.在conf/server.xml找到host元素节点。
2.加入以下内容
<!--docBase:项目的路径地址,如:D:\xml02\person.xml
path:对应的虚拟路径一定要以/打头。
对应的访问方式为:http://localhost:8080/a/person.xml-->
<Context docBase="d:\xml02" path="/a"></Context>
3.在浏览器地址栏上输入:http://localhost:8080/a/person.xml
3.配置虚拟路径(文件的名字作为虚拟路径)
1.在tomcat/conf/catalina/localhost/文件夹下新建一个xml文件,名字可以自己定义。如:person.xml
2.在这个文件里面写入以下内容
<?xml version="1.0" enconding="utf-8" ?> <Context docBase="D:\xml02"></Context>
3.在浏览器上面访问
http://localhost:8080/person/xml的名字即可
给Eclipse配置tomcat
1.首先,切换至Java EE视图,然后在server页签里面 右键新建一个服务器,选择到apache分类,找到对应的tomcat版本,接着一步步配置即可。
2.配置完毕后,在server里面,右键刚才的服务器,然后open,找到上面的Server Location,选择中间的Use Tomcat installation...(配置web项目存放路径)
3.创建web工程,在WebContext下定义html文件,右键工程,run as 》Run on Server(发布web项目到tomcat服务器上)
day02-HTTP&Servlet
http协议
什么是协议
双方在交互、通讯的时候,遵守的一种规范、规则。
http协议
针对网络上的客户端与服务器端在执行http请求的时候,遵守的一种规范。其实就是规定了客户端在访问服务器端的时候,要带上哪些东西。服务器端返回数据的时候,也要带上什么东西。
版本
1.0
请求数据,服务器返回后,将会断开连接
1.1
请求数据,服务器返回后,连接还会保持着。除非服务器|客户端关掉,有一定的时间限制。如果都空着这个连接,那么后面会自己端掉。
演示客户端如何与服务器端通讯
在地址栏中键入网络地址,回车或者是平常注册的时候,点击了注册按钮,浏览器都能显示出来一些东西,那么背地里浏览器和服务器是怎么通讯。它们都传输了哪些数据。
1.安装抓包工具HttpWatch(IE插件)
2.打开tomcat,输入localhost:8080 打开首页
3.在首页找到Example字样
4.选择servlet例子--->Request Paramter
接着点击Request Parameters的Execute超链接
执行tomcat的例子,然后查看浏览器和tomcat服务器的对接细节
Http请求数据解释
请求的数据里面包含三个部分的内容:请求行、请求头、请求体
请求行
POST /examples/servlets/servlet/RequestParamExample HTTP/1.1
POST:请求方式,以post去提交数据
/examples/servlets/servlet/RequestParamExample
请求的地址路径,就是要访问哪个地方。
HTTP /1.1 协议版本
请求头
Accept:客户端向服务器端表示,我能支持什么类型的数据。
Referer:真正请求的地址路径,全路径
Accept-Language:支持语言格式
User-Agent:用户代理,向服务器表明,当前来访的客户端信息。如:使用哪种浏览器,IE还是谷歌,使用什么系统,ios,andriod还是windows等。
Content-Type:提交的数据类型,经过urlencoding编码的form表单的数据(application/x-www-form-urlencoding)
Accept-Encoding:gzip,deflate:压缩算法。
Host:主机地址
Content-Length:数据长度
Connection:Keep-Alive 保持连接
Cache-Control:对缓存的操作
请求体
浏览器真正发送给服务器的数据,发送的数据呈现的是key-value,如果存在多个数据,那么使用&
firstname=zhang&lastname=san
Http响应数据解析
响应的数据里面包含三个部分内容:响应行、响应头、响应体
响应行:
HTTP/1.1 200 OK
协议版本
状态码:咱们这次交互到底是什么样结果的一个code
Informational 1xx
Successful 2xx
Redirection 3xx
Client Error 4xx
Server Error 5xx
403 :Forbidden 拒绝
200:成功,正常处理,得到数据
404:Not Found
500:服务器异常
OK:对应前面的状态码
响应头:
server:服务器是哪一种类型,tomcat
Content-Type:服务器返回给客户端的内容类型
Content-Length:返回的数据长度
Date:通讯的日期,响应的时间
GET和POST请求区别
1.请求路径不同,post请求在url后面不跟上任何的数据,get请求在地址后面跟上数据
2.带上的数据不同,post请求会使用流的方式写数据,get请求是在地址栏上跟数据
3.由于post请求使用流的方式写数据,所以一定需要一个Content-Length的头来说明数据的长度是多少
post:
1.数据是以流的方式写过去,不会在地址栏上面显示。现在一般提交数据到服务器使用的都是POST
2.以流的方式写数据,所以数据没有大小限制
get:
1.会在地址栏后面拼接数据,所以有安全隐患。一般从服务器获取数据,并且客户端也不用提交什么数据的时候,可以使用GET
2.能够带的数据有限,1kb大小
web资源
在http协议当中,规定了请求和响应双方,客户端和服务器端,与web相关的资源。
有两种分类:
静态资源:
html,js,css
动态资源:
靠servlet产生动态资源:如:jsp
servlet
servlet是什么?
其实就是一个java程序,运行在我们的web服务器上,用于接收和响应客户端的http请求。
更多的是配合动态资源来做。当然静态资源也需要使用到servlet,只不过是tomcat里面已经定义好了一个DefaultServlet
Hello Servlet(第一个Web项目)
1.得写一个web工程,要有一个服务器。
2.测试运行Web工程
1.新建一个类,实现Servlet接口(需实现接口中的所有方法,主要是service()方法) 2.配置Servlet,用意:告诉服务器,我们的应用有这么些个servlet 在webContent/WEB-INF/web.xml里面写上以下内容: <!--向tomcat报告,我这个应用里面有这个servlet,名字叫做HelloServlet,具体的路径是com.itheima.servlet.HelloServlet--> <servlet> <servlet-name>HelloServlet</servlet-name> <servlet-class>com.itheima.servlet.HelloServlet</servlet-class> </servlet> <!--注册servlet的映射。servletName:找到上面注册的具体servlet,url-pattern:在地址栏上的path,一定要以/打头--> <servlet-mapping> <servlet-name>HelloServlet</servlet-name> <url-pattern>/a</url-pattern> </servlet-mapping> 3.在地址栏上输入 http://localhost:8080/项目名称/a
Servlet执行过程
1.找到tomcat应用
2.找到项目
3.找web.xml,然后在里面找到url-pattern,有没有哪一个pattern的内容是/a
4.找到servlet-mapping中的那个servlet-name【HelloServlet】
5.找到上面定义的servlet元素中的servlet-name中的【HelloServlet】
6.找到下面定义的servlet-class,然后开始创建该类的实例
7.继而执行该servlet中的service方法
Servlet的通用写法
Servlet(接口)
|
GenericServlet
|
HttpServlet(用于处理http的请求)
定义一个类,继承Httpservlet 重写doGet和doPost方法
Servlet的生命周期
生命周期
从创建到销毁的一段时间
生命周期方法
从创建到销毁,所调用的那些方法。
1.init方法
在创建该servlet的实例时,就执行该方法
一个servlet只会初始化一次,init()方法只会执行一次
默认情况下是:初次访问servlet(即在地址栏录入地址后,回车),才会创建实例
2.service方法
只要客户端来了一个请求,那么就执行这个方法了
该方法可以被执行很多次,一次请求对应一次service()方法的调用
3.destroy方法
servlet销毁的时候,就会执行该方法(关闭浏览器--不销毁)
1.该项目从tomcat的里面移除(从服务器中移除托管)。
2.正常关闭tomcat 就会执行 shutdown.bat
让servlet创建实例的时机提前(可提前到服务器启动的时候)
1.默认情况下,只有在初次访问servlet的时候,才会执行init方法。有的时候,我们可能需要在这个方法里面执行一些初始化工作,甚至是做一些比较耗时的逻辑。
2.那么这个时候,初次访问,可能会在init方法中逗留太久的时间,那么有没有方法可以让这个初始化的时机提前一点。
3.在配置的时候,使用load-on-startup元素来指定,给定的数字越小,启动的时机就越早。一般不写负数,从2开始即可。
<servlet> <servlet-name>HelloServlet</servlet-name> <servlet-class>com.itheima.servlet.HelloServlet</servlet-class>
<load-on-startup>2</load-on-startup> </servlet>
ServletConfig
ServletConfig 可以获取servlet在配置servlet的信息
//得到servlet配置对象 专门用于在配置servlet的信息
ServletConfig config = getServletConfig();
//获取到的是配置servlet里面servlet-name的文本内容
String servletName = config.getServletName();
//可以获取具体的某一个参数
String address = config.getInitParameter("address");
//获取所有的参数名称
Enumeration<String> names = config.getInitParameterNames();
//遍历取出所有的参数名称
while(names.hasMoreElements()){
String key =(String)names.nextElement();
String value = config.getInitParameter(key);
}
<!--可以添加初始化参数--> <init-param> <param-name>name</param-name>
<param-value>zhangsan</param-value> </init-param>
<init-param> <param-name>address</param-name>
<param-value>beijing...</param-value> </init-param>
为什么需要有ServletConfig
1.未来我们自己开发的一些应用,使用到了一些技术,或者一些代码,我们不会,但是有人写出来了,它的代码放置在了自己的servlet类里面(把别人的代码导出jar包引用)
2.刚好这个servlet里面需要一个数字或者叫做变量值,但是这个值不能是固定了,所以要求使用到这个servlet的公司,在注册servlet的时候,必须要在web.xml里面声明init-param
day03-HTTPServletRequest和HTTPServletResponse
Servlet配置方式
1.全路径匹配
以/开始 /a /aa/bb
localhost:8080/项目名称/aa/bb
2.路径匹配,前半段匹配
以/开始,但是以*结束。/a/* /**其实是一个通配符,匹配任意文字
3.以扩展名匹配
没有/ 以*开始 *.扩展名 *.aa *.bbServletContext
Servlet上下文每个web工程都只有一个ServletContext对象,说白了也就是不管在那个servlet里面,获取到的这个类的对象都是同一个。
如何得到对象
//获取对象
ServletContext context = getServletContext();
有什么作用
1.可以获取全局配置参数
<!--全局参数:哪个servlet都可以拿,ServletContext--> <context-param> <param-name>address</param-name>
<param-value>深圳宝安</param-value>
</context-param>
获取全局参数
protected void doGet(HttpServletRequest request,HttpServletResponse){
//获取对象
ServletContext context = getServletContext();
String address = context.getInitParameter("address");
}
2.可以获取web应用中的资源
说明:如果想获取web工程下的资源,用普通的FileInputStream写法是不OK的,因为路径不对了。这里相对的路径,其实是根据jre来确定的,但是我们这是一个web工程,jre后面会由tomcat管理,所以这里真正相对的路径是tomcat里面的bin目录。
1.获取资源在tomcat里面的绝对路径(通过ServletContext)
先得到路径,然后自己new InputStream
说明:context.getRealPath("file/config.properties");//这里得到的是项目在tomcat里面的根目录--D:\tomcat\apache-tomcat-7.0.5\apache-tomcat-7.0.52\wtpwebapps\Demo03
//获取ServletContext对象
ServletContext context = getServletContext();
//获取给定的文件在服务器上的绝对路径
String path = context.getRealPath("file/config.properties");
//创建属性对象
Properties properties = new Properties();
InputStream is = new FileInputStream(path);
properties.load(is);
//获取name属性的值
String name = properties.getProperties("name");
2.getResourceAsStream获取资源 流对象(通过ServletContext)
直接给相对的路径,然后获取流对象
//获取ServletContext对象 ServletContext context = getServletContext(); //创建属性对象 Properties properties = new Properties();
//获取web工程下的资源,转化成流对象。前面隐藏当前工程的根目录
InputStream is = context.getResourceAsStream("file/config.properties");
properties.load(is);
//获取name属性的值 String name = properties.getProperties("name");
is.close();
3.通过classloader去获取web工程下的资源
//创建属性对象
Properties properties = new Properties();
//ClassLoader默认的路径是web项目的classer路径,我们必须得回到项目这个目录下,才能进入file目录。如果回到上一级目录呢?../
InputStream is = this.getClass().getClassLoader().getResourceAsStream("../../file/config.properties");
properties.load(is);
//获取name属性的值 String name = properties.getProperties("name");
is.close();
3.使用ServletContext存取数据(存取数据,Servlet间共享数据)
1.定义一个登陆的html页面,定义一个form表单
2.定义一个Servlet,名为LoginServlet
3.针对成功或者失败,进行判断,然后跳转到不一样的网页
protected void doGet(HttpServletRequest request,HttpServletResponse response){
//获取数据
String userName = request.getParameter("username");
String password = request.getParameter("password");
//校验数据
//向客户端输出内容
PrintWriter pw = response.getWriter();
if("admin".equals(userName)&& "123".equals(password)){
//设置状态码,重新定位状态码
response.setStatus(302);
//定位跳转的位置是哪一个页面
response.setHeader("Location","login_success.html");
}else{
pw.write("login failed...");
}
}
ServletContext何时创建,何时销毁?
服务器启动的时候,会为托管的每一个web应用程序,创建一个ServletContext对象
从服务器移除托管,或者是关闭服务器就会销毁
ServletContext的作用范围
只要在这个项目里面,都可以取。只要同一个项目。
A项目存,在B项目取,是取不到的,为什么?
ServletContext对象不同。
HttpServletRequest
这个对象封装了客户端提交过来的一切数据。
1.可以获取客户端请求头信息
//取出请求里面的所有头信息-----得到一个枚举集合
Enumeration<String> headerNames = request.getHeaderNames();
while(headerNames.hasMoreElements()){
String name = (String)headerNames.nextElement();
String value = request.getHeader(name);
}
2.获取客户端提交过来的数据
//获取到的是客户端提交上来的数据
String name = request.getParameter("name");
//获取所有的参数,得到一个枚举集合
Enumeration<String> parameterNames = request.getParameterNames();
Map<String,String[]> map = request.getParameterMap();
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while(iterator.hasNext()){
String key = (String)iterator.next();
String value = map.get(key)[0];
}
3.获取中文数据
客户端提交数据给服务器端,如果数据中带有中文的话,有可能会出现乱码情况,那么可以参照以下方法解决。
如果是GET方式
1.代码转码
String username = request.getParameter("username");
//get请求过来的数据,在url地址栏上就已经经过编码了额,所以我们渠道的就是乱码
//tomcat收到了这批数据,getParameter默认使用ISO-8859-1去解码
//先让文字回到ISO-8859-1对应的字节数组,然后再按照utf-8组拼字符串
username = new String(username.getBytes("ISO-8859-1","UTF-8"));
直接在tomcat里面做配置,以后get请求过来的数据永远都是用UTF-8编码
2.可以在tomcat里面做设置处理 conf/server.xml 加上URIEncoding="utf-8"
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443" URIEncoding="UTF-8"/>
如果是POST方式
这个说的是设置请求体里面的文字编码。get方式用这行没用
request.setCharacterEncoding("UTF-8");
这行设置一定要写在getParameter之前。
HttpServletResponse
负责返回数据给客户端
输出数据到页面上
//以字符流的方式写数据
response.getWriter().write("<h1>hello response...</h1>");
//以字节流的方式写数据
response.getOutputStream().write("hello response...".getBytes());
//设置当前这个请求的处理状态码
response.setStatus("");
//设置一个头
response.setHeader(name,value);
//设置响应的内容类型,以及编码
response.setContextType(type);
响应的数据中有中文,那么有可能出现中文乱码
以字符流输出
//这里写出去的文字,默认使用的是ISO-8859-1,我们可以指定写出去的时候,使用什么编码写
//1.指定输出到客户端的时候,这些文字使用UTF-8编码
response.setCharacterEncoding("UTF-8");
//2.直接规定浏览器看这份数据的时候,使用什么编码来看
response.setHeader("Content-Type","text/html;charset=UTF-8");
response.getWriter().write("我爱黑马训练营...");
以字节流输出
//1.指定浏览器看这份数据使用的码表
response.setHeader("Content-Type","text/html;charset=UTF-8");
//默认情况下getOutputStream输出使用的是UTF-8的码表。如果想指定具体的编码,可以在获取byte数组的时候,指定
//2.指定输出的中文哟给的码表 response.getOutputStream().write("我爱深圳黑马训练营...".getBytes("UTF-8"));
//以上两行的设置方式,可以直接用下面一行代替
//不管是字节流还是字符流,直接使用一行代码就可以了。然后再写数据即可
//设置响应的数据类型是html文本,并且告知浏览器,使用UTF-8来编码
response.setContentType("text/html;charset=UTF-8");
下载文件
1.直接以超链接的方式下载,不写任何代码。也能够下载东西下来
让tomcat默认的servlet去提供下载:<br> <a href="download/aa.jpg">aa.jpg</a><br> <a href="download/bb.txt">bb.txt</a><br> <a href="download/cc.rar">cc.rar</a><br>
原因是tomcat里面有一个默认的Servlet--DefaultServlet。这个DefaultServlet专门用于处理放在tomcat服务器上的静态资源。
//1.获取要下载的文件名字aa.jpg---inputstream
String fileName = request.getParameter("filename");
//2.获取这个文件在tomcat里面的绝对路径地址
String path = getServletContext().getRealPath("download/"+fileName);
//如果文件的名字带有中文,那么需要对这个文件名进行编码处理
//如果是IE或者Chrome,使用URLEncoding编码
//如果是Firefox,使用Base64编码
//获取来访的客户端类型
String clientType = request.getHeader("User-Agent");
if(clientType.contains("Firefox")){
fileName = DownLoadUtil.base64EncodeFileName(fileName);//DownLoadUtil是封装的一个工具类,代码未在此处体现
}else{
fileName = URLEncoder.encode(fileName,"UTF-8");
}
//让浏览器收到这份资源的时候,以下载的方式提醒用户,而不是直接展示
response.setHeader("content-Disposition","attachment;filename="+fileName);
//3.转化成输入流
InputStream is = new FileInputStream(path);
OutputStream os = response.getOutPutStream();
int len=0;
byte[] buffer = new byte[1024];
while((len = is.read(buffer))!=-1){
os.write(buffer,0,len);
}
os.close();
is.close();
手动编码提供下载:<br>
<a href="Demo01?filename=aa.jpg">aa.jpg</a><br> <a href="Demo01?filename=bb.txt">bb.txt</a><br> <a href="Demo01?filename=cc.rar">cc.rar</a><br>
day04-Cookie&Session
请求转发和重定向
重定向
//之前的写法
response.setStatus(302);
response.setHeader("Location",login_success.html"");
//重定向写法:重新定位方向 参数即跳转的位置
response.sendRedirect("login.success.html");
1.地址上显示的是最后的那个资源的路径地址
2.请求次数最少有两次,服务器在第一次请求后,会返回302以及一个地址,浏览器再根据这个地址,执行第二次访问
3.可以跳转到任意路径,不是自己的工程也可以跳
4.效率稍微低一点,执行两次请求
5.后续的请求,没法使用上一次的request存储的数据,或者没法使用上一次的request对象,因为这是两次不同的请求。
请求转发
request.getRequestDispatcher("login_success.html").forward(request,response);
1.地址上显示的是请求servlet的地址 返回200 ok
2.请求次数只有一次,因为是服务器内部帮客户端执行了后续的工作
3.只能跳转自己项目的资源路径
4.效率上稍微高一点,因为只执行一次请求
5.可以使用上一次的request对象
Cookie
饼干,其实是一份小数据,是服务器给客户端,并且存储在客户端上的一份小数据
应用场景
自动登录、浏览记录、购物车
为什么要有这个cookie
http的请求是无状态。客户端与服务器在通讯的时候,是无状态的,其实就是客户端在第二次来访的时候,服务器根本就不知道这个客户端以前有没有来访问过。为了更好的用户体验,更好的交互【自动登录】,其实从公司层面讲,就是为了更好的收集用户习惯【大数据】
Cookie怎么用
简单使用:
添加Cookie给客户端
1.在响应的时候,添加cookie
Cookie cookie = new Cookie("aa","bb");
//给响应,添加一个cookie
response.addCookie(cookie);
2.客户端收到的信息里面,响应头中多了一个字段Set-Cookie
获取客户端带过来的cookie
//获取客户端带过来的cookie
Cookie[] cookies = request.getCookies();
if(cookies != null){
for(Cookie c : cookies){
String cookieName = c.getName();
String cookieValue = c.getValue();
}
}
常用方法
//cookie的有效期
///默认情况下,关闭浏览器后,cookie就没有了---》针对没有设置cookie的有效期
//expiry
//正值:表示在这个数字过后,cookie将会失效
//负值:关闭浏览器,那么cookie就失效,默认值是-1
cookie.setMaxAge(60*60*24*7); //以秒为单位
//赋值新的值
//cookie.setValue(newValue);
//用于指定只有请求了指定的域名,才会带上该cookie
cookie.setDomain(".itheima.com");
//只有访问该域名下的cookieDemo的这个路径地址才会带cookie
cookie.setPath("/CookieDemo");
例子-显示最近访问的时间
Jsp里面使用Java代码
jsp(Java Server Pager--->最终会翻译成一个类,就是一个Servlet)
定义全局变量
<%! int a = 99; %>
定义局部变量
<% int b = 999; %>
在jsp页面上,显示a和b的值
<%=a%>
<%=b%>
清除Cookie
删除cookie是没有什么delete方法的,只有设置MaxAge为0
Cookie总结
1.服务器给客户端发送过来的一小份数据,并且存放在客户端上。
2.获取cookie,添加cookie
request.getCookie();
response.addCookie();
什么时候有cookie?
添加cookie的时候,response.addCookie();
3.Cookie分类
会话Cookie
默认情况下,关闭了浏览器,那么cookie就会消失
持久Cookie
在一定时间内,都有效,并且保存在客户端上。
cookie.setMaxAge(0); //设置立即删除
cookie.setMaxAge(100); //100秒 说明:这句话要写在response.addCookie();方法之前,即先设置再添加才生效
4.Cookie的安全问题。
由于Cookie会保存在客户端上,所以有安全隐患问题。还有一个问题,Cookie的大小与个数有限制。为了解决这个问题,出来了Session
5.服务器返回cookie给客户端,放置在响应头里面
Set-Cookie:aa=bb
Set-Cookie:cc=dd
客户端提交数据的时候,cookie也是在请求头里面
Cookie:aa=bb;cc=dd
6.移除cookie
官方没有提供delete方法,也没有什么remove方法
Cookie cookie = new Cookie("aa","bb");
cookie.setMaxAge(60*60*24); //一天
response.addCookie(cookie);
删除cookie
一:
得到以前的cookie,然后重新设置有效期
Cookie[] cookies = request.getCookies();
Cookie cookie = CookieUtil.findCookie(cookies,"aa"); //CookieUtil是自己写代码封装的一个类,此处未体现
cookie.setMaxAge(0);
response.addCookie(cookie);
二:
创建一个新的cookie
Cookie cookie = new Cookie("aa",""); // 设置原来的key为任意非指定的value即可
cookie.setMaxAge(0);
response.addCookie(cookie);
Session
会话,Session是基于Cookie的一种会话机制。Cookie是服务器返回一小份数据给客户端,并且存放在客户端上。Session是数据存放在服务器端的内存中。
会在cookie里面添加一个字段JSESSIONID,是tomcat服务器生成的。并且把这个session对应的sessionID传递给客户端。是通过Cookie去传递的。下一次客户端来访的时候,带上那个sessionID,就可以去到以前的数据了。
Session常用API
HttpSession session = request.getSession(); //得到会话ID String id = session.getId(); //存储 session.setAttribute(name,value); //取值 session.getAttribute(name); //移除值 session.removeAttribute(name);
//强制干掉会话,里面存放的任何数据就都没有了
session.invalidate();
Session何时创建,何时销毁?
创建
如果有在servlet里面调用了request.getSession()
销毁
session是存放在服务器的内存中的一份数据。当然可以持久化(Redis)。即使关了浏览器,session也不会销毁。
1.关闭服务器
2.session会话时间过期,有效期过了。默认有效期:30分钟
setAttribute存放的值,在浏览器关闭后,也还是有的。
为什么再一次开启浏览器访问的时候,无法取到以前的数据?
因为sessionID是通过cookie来传递的。但是这个cookie并没有设置有效期,所以关闭浏览器之后,cookie就删除了,表明里面的那个sessionID也就没有了,下一次再来访问,如果还想在下一次访问的时候,取到以前的数据。
1.在服务器端手动设置cookie
String id = request.getsession().getId();
Cookie cookie = new Cookie("JSESSIONID",id);
cookie.setMaxAge(60*60*24*7); //7天
response.addCookie(cookie);
day05-JSP&EL&JSTL
jsp
Java Server Page
三大指令集
三个动作标签
九个内置对象
什么是jsp?
从用户角度看待,是一个网页,从程序员角度看待,其实就是一个java类,它继承了servlet,所以可以直接说jsp就是一个Servlet
为什么会有jsp?
html多数情况下用来显示静态内容,一成不变的。但是有时候我们需要在网页上显示一些动态数据,比如:查询所有的学生信息,根据姓名去查询具体某个学生。这些动作都需要去查询数据库,然后在网页上显示,html是不支持写java代码,jsp里面可以写java代码。
怎么用JSP
指令写法
<%@指令名字%>
page指令
language
表明jsp页面中可以写java代码
contentType
其实即使说这个文件是什么类型,告诉浏览器我是什么内容类型,以及使用什么编码
contentType="text/html;charset=UTF-8"
text/html MIMEType 这是一个文本,html网页
pageEncoding: jsp内容编码
extends: 用于指定jsp翻译成java文件后,继承的父类是谁,一般不用改。
import:导包使用的,一般不用手写
session
值可选的有true or false
用于控制在这个jsp页面里面,能够直接使用session对象。
具体的区别是,请看翻译后的java文件(存放在tomcat安装目录下:apache-tomcat-7.0.52\work\Cataline\localhost\项目名称\org\apache\jsp),如果改值是true,那么在代码里面会有getSeesion()方法的调用,如果是false,那么就不会有该方法调用,也就是没有session对象了,在页面上自然也就不能使用session了。
errorPage
指的是错误的页面,值需要给错误的页面路径
isErrorPage
上面的errorPage用于指定错误的时候跑到哪一个页面去。那么这个isErrorPage就是声明某一个页面到底是不是错误的页面。
include
包含另外一个jsp的内容进来。
<%@ include file="other02.jsp"%>
背后细节:把另外一个页面的所有内容拿过来一起输出。所有的标签元素都包含进来。
taglib
<%@ taglib prefix="" uri=""%>
uri:标签的路径
prefix:标签库的别名
JSP动作标签
jsp:include
<jsp:include page="other02.jsp"></jsp:include>
包含指定的页面,这里是动态包含,也就是不把包含的页面所有元素标签全部都拿过来输出,而是把它的运行结果拿过来。
jsp:forward
<jsp:forward page=""></jsp:forward>
前往哪一个页面
<%
//请求转发
request.getRequestDispatcher("other02.jsp").forward(request,response);
%>
jsp:param
意思是:在包含某个页面的时候,或者在跳转某个页面的时候,加入这个参数。
<jsp:forward page="other02.jsp">
<jsp:param value="beijing" name="address"/>
</jsp:forward>
在other02.jsp中获取参数:
<%= request.getParamter("address")%>
JSP内置对象
所谓内置对象,就是我们可以直接在jsp页面中使用这些对象,不用创建。
pageContext
request
session
application
以上4个是作用域对象
作用域:表示这些对象可以存值,它们的取值范围有限定。setAttribute 和 getAttribute
使用作用域来存储数据<br> <%
pageContext.setAttribute("name","page");
request.setAttribute("name","request");
session.setAttribute("name","session");
application.setAttribute("name","application"); %> 取出四个作用域中的值<br> <%=pageContext.getAttribute("name")%> <%=request.getAttribute("name")%> <%=session.getAttribute("name")%> <%=application.getAttribute("name")%>
四个作用域的区别
pageContext【PageContext】
作用域仅限当前的页面。
还可以获取到其他八个内置对象。
request【HttpServletRequest】
作用域仅限于一次请求,只有服务器对该请求做出了响应,这个域中存的值就没有了。
session【HttpSession】
作用域限于一次会话(多次请求与响应)当中
application【ServletContext】
整个工程都可以访问,服务器关闭后就不能访问了。
out 【JspWriter】
response 【HttpServletResponse】
说明:把out对象输出的内容放置到response的缓冲区去,先输出response本身要输出的内容,然后才是out里面的内容(out.write()&response.getWrite().write())
exception 【Throwable】
page 【Object】---就是这个jsp翻译成的java类的实例对象
config 【ServletConfig】
EL表达式
是为了简化咱们的jsp代码,具体一点就是为了简化在jsp里面写的那些java代码。
写法格式
${表达式}
如何使用
1.取出4个作用域中存放的值
<%
pageContext.setAttribute("name","page");
request.setAttribute("name","request");
session.setAttribute("name","session");
application.setAttribute("name","application");
%>
<br>使用EL表达式取出作用域中的值<br>
${ pageScope.name }
${ requestScope.name }
${ sessionScope.name }
${ applicationScope.name }
2.如果域中所存的值是数据
<%
String[] a = {"aa","bb","cc"};
pageContext.setAttribute("array",a);
%> 使用EL表达式取出作用域中数组的值<br>
${array[0]},${array[1]},${array[2]}
<%
List list = new ArrayList();
list.add("11");
list.add("22");
list.add("33");
pageContext.setAttribute("li",list);
%>
使用EL表达式取出作用域中集合的值<br>
${li[0]},${li[1]},${li[2]}
<br>------------Map数据---------<br>
<%
Map map = new HashMap();
map.put("name","zhangsan");
map.put("age",18);
map.put("address.aa","深圳...");
pageContext.setAttribute("map",map);
%>
使用EL表达式取出作用域中Map的值<br>
${map.name},${map.age},${map["address.aa"]}
取值细节
1.
从域中取值,得先存值
<%
pageContext.setAttribute("name","zhangsan");
session.setAttribute("name","lisi");
%>
<br>直接指定说了,到这个作用域里面去找这个name<br>
${ pageScope.name}
<br>先从page里面找,没有去request找,再没有去session找,再没有去aoolication找<br>
${name}
2.取值方式
如果这份值是有下标的,哪直接使用[]
<%
String[] a = {"aa","bb","cc"};
pageContext.setAttribute("array",a);
%>
使用EL表达式取出作用域中数组的值<br>
${array[0]},${array[1]},${array[2]}
如果没有下标,直接使用.的方式去取
<%
User user = new User("zhangsan",18);
session.setAttribute("u",user); %> ${u.name},${u.age}
${empty u} //判断是否为空,返回true或false
一般使用EL表达式,用的比较多的都是从一个对象中取出它的属性值,比如取出某一个学生的姓名。
EL表达式的11个内置对象
pageContext
pageScope
requestScope
sessionScope
applicationScope
header
headerValues
param
paramValues
cookie
initParam
JSTL
全称:JSP Standard Tag Library jsp标准标签库
简化jsp的代码编写,替换<%%>写法,一般与EL表达式配合。
怎么使用
1.导入jar文件到工程的WebContent/Web-Info/lib jstl.jar standard.jar
2.在jsp页面上,使用taglib指令,来引入标签库
3.注意:如果想支持EL表达式,那么引入的标签库必须选择1.1的版本,1.0的版本不支持EL表达式。
<%@ taglib preifx="c" uri="http://java.sun.com/jsp/jstl/core"%>
常用标签
<c:set></c:set>
<c:if test=""></c:if>
<c:forEach></c:forEach>
c:set===存值
<!--声明一个对象name,对象的值zhangsan,存储到了page(默认),指定是session-->
<c:set var="name" value="zhangsan" scope="session"></c:set>
${sessionScope.name}
c:if===判断
判断test里面的表达式是否满足,如果满足,就执行c:if标签中的输出,c:if是没有else的,如果需要再写一个c:if标签即可
<c:set var="age" value="18"></c:set>
定义一个变量名flag,去接收前面表达式的值,然后存在session域中,值为true或false
<c:if test="${age>26}" var="flag" scope="session">
年龄大于26岁
</c:if>
${flag}
c:forEach===遍历
从1开始遍历到10,得到的结果赋值给i,并且会存储到page域中,step表示增幅为2
<c:forEach begin="1" end="10" var="i" step="2">
${i}
</c:forEach>
<%
List list = new ArrayList();
list.add(new User("zhangsan",18));
pageContext.setAttribute("list",list);
%>
items:表示遍历哪一个对象,注意:这里必须写EL表达式
var:遍历出来的每一个元素用user去接收。
<c:forEach var="user" items="${list}">
${user.name}----${user.age}
</c:forEach>
day06-事务&数据库连接池&DBUtiles
事务
Transaction 其实指的是一组操作,里面包含许多个单一的逻辑,只要有一个逻辑没有执行成功,那么都算失败。所有的数据都回归到最初的状态(回滚)
为什么要有事务?
为了确保逻辑的成功。例子:银行的转账。
使用命令行方式演示事物
1.开启事务:start transaction;
2.提交或者回滚事务
commit:提交事务,数据将会写到磁盘上的数据库
rollback:数据回滚,回到最初的状态
3.关闭自动提交功能
查看数据库命令是否自动提交:show variables like '%commit%';
修改数据库为非自动提交:set autocommit=off
使用代码方式演示事务
代码里面的事务,主要是针对连接来的。(事务只是针对连接对象,如果再开一个连接对象,那么那是默认的提交了)
1.通过conn.setAutoCommit(false)来关闭自动提交的设置。
2.提交事务 conn.comit();
3.回滚事务 conn.rollback();
事务的特性
原子性:指的是事务中包含的逻辑,不可分割
一致性:指的是事务执行前后数据的完整性保持一致
隔离性:指的是事务在执行期间不应该受到其他事务的影响
持久性:指的是事务执行成功,那么数据应该持久保存到磁盘上
事务的安全隐患
命令查看数据库事务的隔离级别:select @@tx_isolation;
设置隔离级别为读未提交:set session transaction isolation level read uncommitted;
不考虑隔离级别设置,那么会出现以下问题。
读
脏读:一个事务读到了另外一个事务还未提交的数据(打开两个数据库命令窗口)
不可重复读:一个事务读到了另外一个事务提交的数据,造成了前后两次查询结果不一致。
幻读:一个事务读到了另一个事务已提交的插入的数据,导致多次查询结果不一致。(多个事务并发提交,可能产生)
写
丢失更新
解决丢失更新
悲观锁:可以在查询的时候,加入for update
乐观锁:要求程序员自己控制
隔离级别
Read Uncommitted【读未提交】:引发问题===脏读
Read Committed【读已提交】:这个隔离级别能够屏蔽脏读的现象,但是引发了另一个问题,不可重复读。
Repeatable Read【重复读】:解决脏读和不可重复读,未解决幻读
Serializable【可串行化】:如果有一个连接的隔离级别设置为了串行化,那么谁先打开了事务,谁就有了先执行的权利,谁后打开事务,谁就只能等着,等前面的那个事务,提交或者回滚后才能执行。但是这种隔离级别一般比较少用,容易造成性能上的问题,效率比较低。
mysql:默认的隔离级别是可重复读
oracle:默认的隔离级别,读已提交
按效率划分,从高到低
读未提交>读已提交>可重复读>可串行化
按拦截成程度,从高到低
可串行化>可重复读>读已提交>读未提交
数据库连接池【开源框架】
数据库的连接对象创建工作,比较消耗性能。
一开始先在内存中开辟一块空间(集合),一开始先往池子里面放置多个连接对象,后续需要连接的话,直接从池子里面取,不要去自己创建连接了,使用完毕,要记得归还连接,确保连接对象能循环利用。
DBCP(database connection pool)
C3P0
ComboPooledDataSource dataSource = new ComboPooledSource();
使用配置(必须掌握)===配置文件设置
properties
xml 推荐使用xml
自定义连接池
装饰者模式
DBUtils
简化了我们的CRUD,里面定义了通用的CRUD方法。
ComboPooledDataSource dataSource = new ComboPooledSource();
QueryRunner queryRunner = new QueryRunner(dataSource);
//针对增加、删除、修改
queryRunner.update(sql,params);
//针对查询
queryRunner.query(sql,rsh);
1.直接new接口的匿名实现类
new ResultSetHandler<Account>(){}
2.直接使用框架已经写好的实现类
查询单个对象
new BeanHandler<Account>(Account.class)
查询多个对象
new BeanListHandler<Account>(Account.class)
补充说明:new ScalarHandler()
//用于处理平均值、总的个数
Long result = (Long) queryRunner.query("select count(*) from stu",new ScalarHandler());
return result.intValue(); //Long转换为int类型
元数据
Meta data:描述数据的数据 String sql,描述这份sql字符串的数据叫做元数据
数据库元数据 DatabaseMetaData
参数元数据 ParameterMetaData(应用场景:sql语句中参数问号的个数,占位符)
结果集元数据 ResultSetMetaData
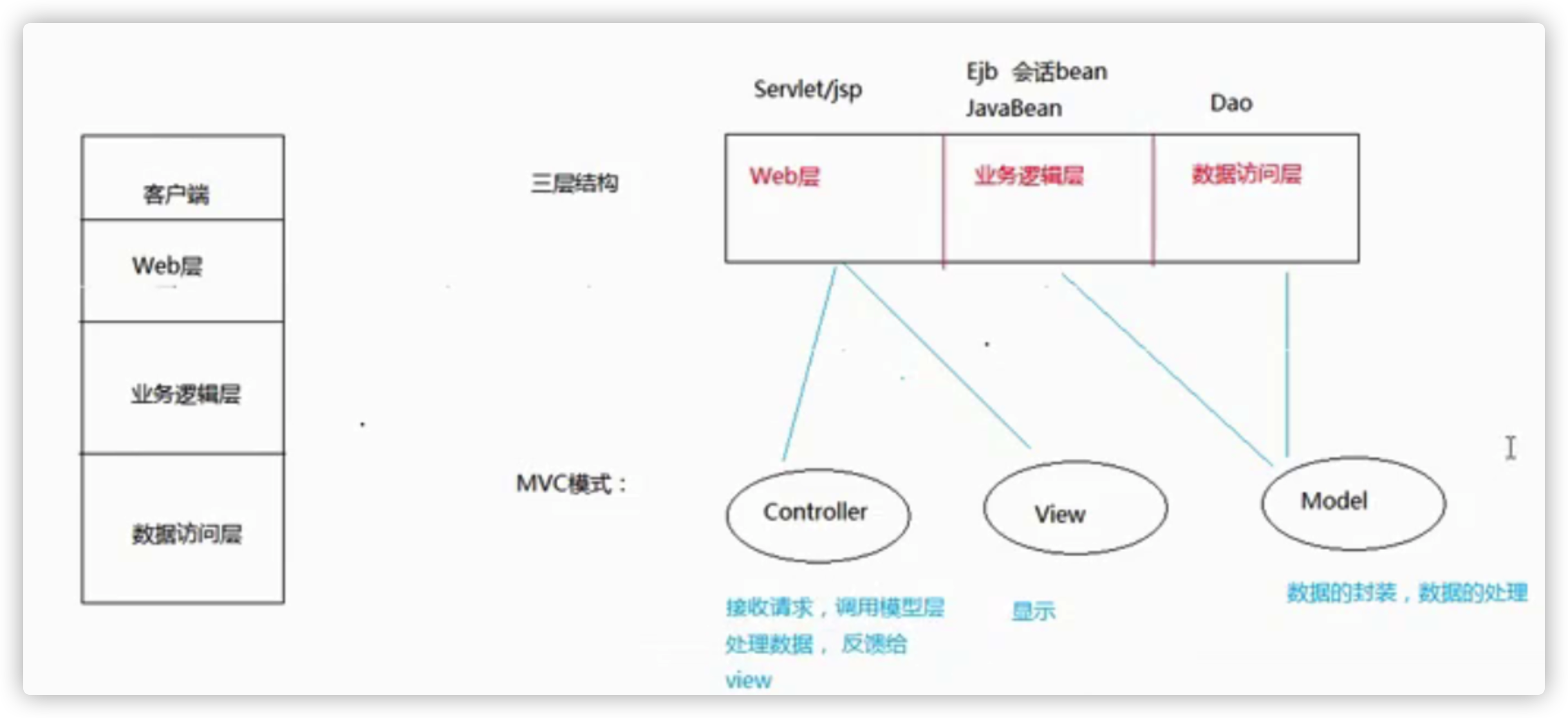
MVC设计模式

三层架构(javaEE)&MVC模式
学生管理系统 增加学生实现
1.先跳转到增加的页面,编写增加的页面
2.点击添加,提交数据到AddServlet处理数据
3.调用service
4.调用dao完成数据持久化
5.完成这些存储工作后,需要跳转到列表页面,这里不能直接跳转到列表页面,否则没有什么内容显示。应该先跳转到查询学生信息的那个Servlet,由那个Servlet再去跳转到列表页面。
6.爱好的value值有多个
request.getParameter("hobby");
String[] hobby = request.getParameterValues("hobby");
String value = Arrays.toString(hobby); //转化数组为字符串,得到:[足球,篮球,写字]
value.subString(1,value.length-1); //去掉中括号,仅显示里面的内容:足球,篮球,写字
学生管理系统 删除学生实现
1.点击超链接,弹出一个询问是否删除的对话框,如果点击了确定,那么就真的删除。
<a href="#" onclick="doDelete(${stu.sid})">删除</a>
<script type="text/javascript">
function doDelete(sid){
var flag = confirm("是否确定删除?");
if(flag){
//表明点了确定,访问servlet,在当前标签页上打开超链接
//window.location.href="DeleteServlet?sid="+sid;
location.href="DeleteServlet?sid="+sid; //写不写window实现效果是一样的
}
}
</script>
2.让超链接执行一个js方法
3.在js访问里面判断点击的选项,然后跳转到Servlet
4.servlet收到了请求,然后去调用service,service去调用dao
学生管理系统 更新学生实现
1.点击列表上的更新,先跳转到一个EditServlet
在这个Servlet里面,先根据ID去查询这个学生的所有信息出来。
2.跳转到更新的页面,然后在页面上显示数据
<tr>
<td>姓名</td>
<td><input type="text" name="sname" value="${stu.sname}"></td>
</tr>
<!--单选框显示-->
<tr>
<td>性别</td>
<td>
<!--如果性别是男的,可以在男的性别input标签里面出现checked,如果性别是女的,可以在女的input标签里面出现checked-->
<input type="radio" name="gender" value="男" <c:if test="${stu.gendet=='男'}">checked</c:if>/>男
<input type="radio" name="gender" value="女" <c:if test="${stu.gendet=='女'}">checked</c:if>/>女
</td>
</tr>
<!--复选框显示-->
<input type="checkbox" name="hobby" value="写字"<c:if test="${fn:contains(stu.hobby,'写字')}">checked</c:if>/>写字
JSTL的fn:contains()函数的语法如下:
<c:if test="${fn:contains(<原始字符串>,<要查找的子字符串>)}">
...
</c:if>
3.修改完毕后,提交数据到UpdateServlet
提交上来的数据是没有带id的,所以我们要手动创建一个隐藏的输入框,在这里面给定id的值,以便提交表单,带上id
说明:若想提交某个参数,但是不想在界面展示,可创建一个隐藏的输入框
<form method="post" action="UpdateServlet">
<inpout type="hidder" name="sid" value="${stu.sid}"> </form>
4.获取数据,调用service,调用dao
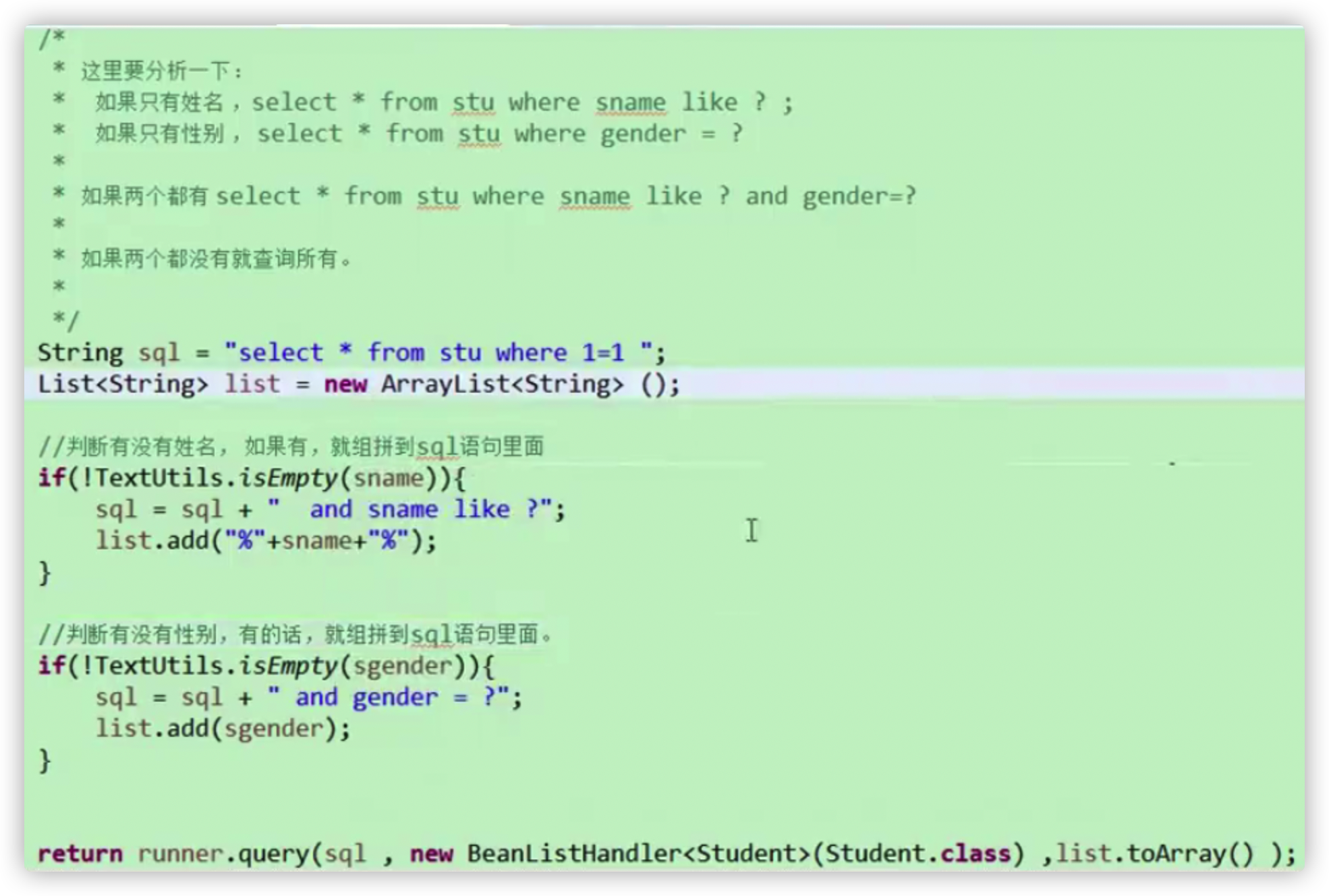
学生管理系统 模糊查询
jsp页面上输出空格:
说明:TextUtils.isEmpty(String s)方法是自己封装的一个字符串判空工具类(s.length==0|s==null)
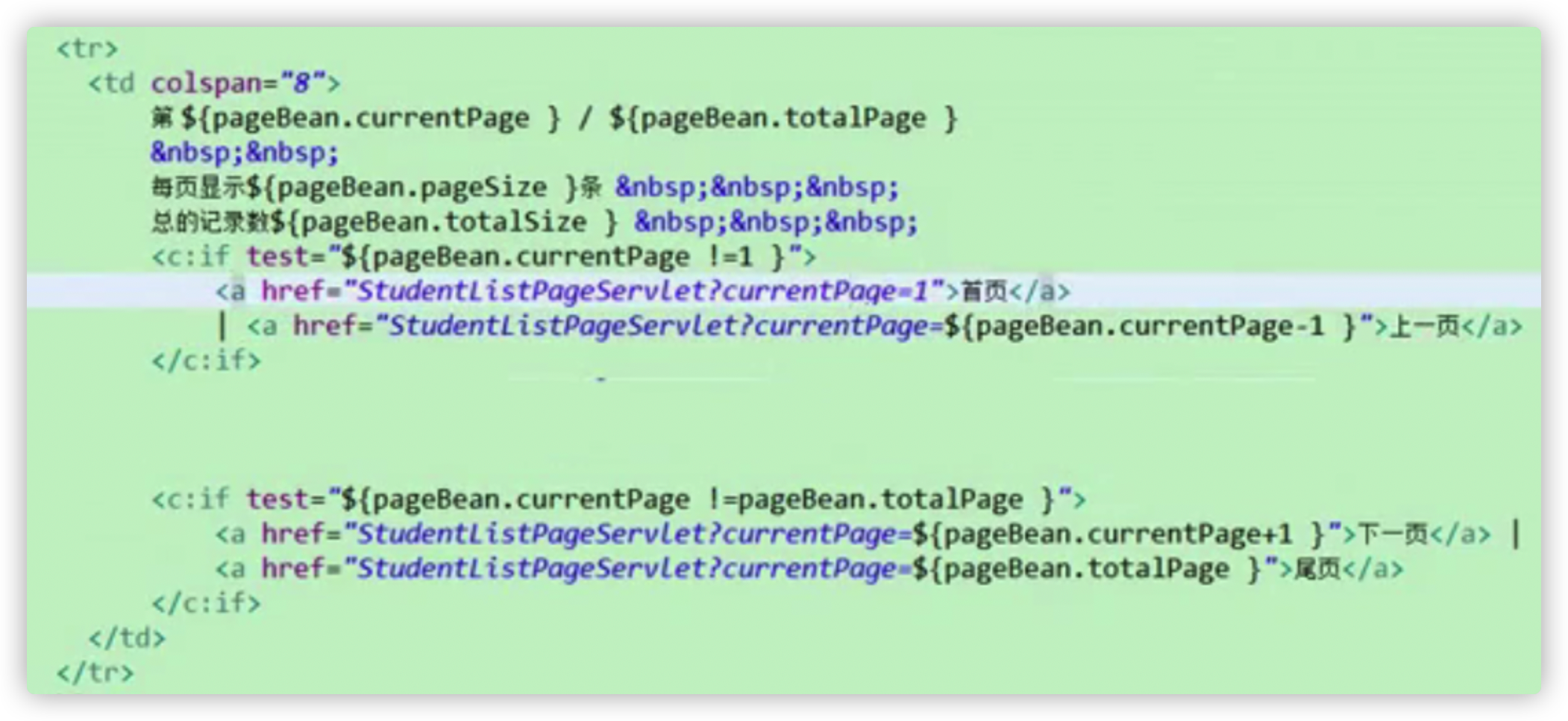
分页功能
物理分页(真分页)
来数据库查询的时候,只查询一页的数据就返回了。
优点:内存中的数据量不会太大
缺点:对数据库的访问频繁了一点
逻辑分页
一口气把所有的数据全部查询出来,然后放置在内存中
优点:访问速度快
缺点:数据库量过大,内存溢出
补充知识点:数据库查询语句limit的用法
用法一:
第一个参数是索引
第二个参数显示的个数
说明:起始索引是0
select * from product limit 0,3;
select * from product limit 3,3;
用法二:
select * from stu where limit 5 offset 2; //表示限制查询出5条数据,但是相对索引为0的那条记录有2个偏移量(即舍去前2条记录不查询,从第3条记录开始查询)
补充:

day08-Ajax&Jquery
Ajax是什么?
Ajax即"Asynchronous Javascript And XML"(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术,它并不是一种新的技术,而是集中原有技术的结合体。
它由下列技术组合而成:
1.使用CSS和XHTML来表示。
2.使用DOM模型来交互和动态显示。
3.使用XMLHttpRequest来和服务器进行异步通信。
4.使用javascript来绑定和调用。
Ajax有什么用?
它可以让我们无需重新加载全部网页内容,即可完成对某个部分的内容执行刷新。
最典型的例子,莫过于大家在注册网站的时候,输入的用户名会自动提示我们该用户已被注册。
Ajax是如何工作的?
ajax方式与前面的方式其实从要做的事情来说,是一样的。ajax也没有牛到不用去访问服务器就知道你的用户名是否已被占用。那么它是如何工作的呢?
1.通过JS获取咱们的输入框文本内容document.getElementById("username").value
2.通过XmlHttpRequest去执行请求。XmlHttpRequest其实就是XML+http+Request的组合
3.请求结束后,收到结果,再使用js去完成提示
4.可以在顺便配合css样式来增加提示效果
数据请求GET
1.创建对象
function ajaxFunction(){
var xmlHttp;
try{
xmlHttp = new XMLHttpRequest();
}
catch(e){
try{
xmlHttp=new ActiveXobject("Msxml2.XMLHTTP"); //表示支持的浏览器类型,火狐等
}
catch(e){
}
}
return xmlHttp;
}
2.发送请求
//执行get请求
function get(){
//1.创建xmlhttprequest对象
var request = ajaxFunction();
//2.发送请求
//参数一:请求类型 GET or POST
//参数二:请求的路径
//参数三:是否异步 true or false
request.open("GET","/day16/DemoServlet01",true);
request.send();
}
如果发送请求的同时,还想获取数据,那么代码如下:
//执行get请求
function get(){
//1.创建xmlhttprequest对象
var request = ajaxFunction();
//2.发送请求
request.open("GET","/day16/DemoServlet01?name=aa&age=18",true);
3.获取响应数据 注册监听的意思。以后准备的状态发生了改变,那么就执行等号右边的方法
request.onreadystatechange = function(){
//前半段表示已经能够正常处理,再判断状态码是否是200
if(request.readyState==4&&request.status==200){
//弹出响应的信息
alert(request.responseText);
}
}
request.send();
}
数据请求POST
function get(){
//1.创建xmlhttprequest对象
var request = ajaxFunction();
//2.发送请求
request.open("POST","/day16/DemoServlet01",true);
//如果不带数据,写这行就可以了
//request.send();
//如果想带数据,就写下面的两行
//如果使用的是post方式带数据,那么这里要添加头,说明提交的数据类型是一个经过url编码的form表单数据
request.setRequestHeader("Content-type","application/x-www-form-urlencoded");
//带数据过去,在send方法里面写表单数据
request.send("name=aobama&age=19");
}
JQuery
说明:使用JQuery之前需要先导入JQuery的支持
//在WebContent文件夹下创建js文件夹 //jquery-1.11.3.min.js是一个外部引用的JQuery文件名称 <script type="text/javascript" src="js/jquery-1.11.3.min.js"></script>
是什么?
javascript的代码框架。
有什么用?
简化代码,提高效率。
write less,do more:写的更少,做的更多
load
//找到这个元素,去执行加载的动作,加载/day16/DemoServlet02得到的数据,赋值显示
$("#text01").load("/day16/DemoServerlet02",function(responseText,statusTXT,xhr){
//找到id为text01的元素,设置它的value属性值为responseText对应的值
$("#text01").val(responseText);
});
Get
$.get("/day16/DemoServlet02",function(data,status){
$("#div01").text(data);
});
赋值显示
val("aa");----只能放那些标签带有value属性
html("aa");---里面可以写html代码,如:<font>等样式标签
text("aa");
其实没有什么区别,如果想针对这份数据做html样式处理,那么只能用html()
load&get&post
load
$("#元素id").load(url地址);
$("#div1").load(servlet);----->使用的get请求回来赋值的时候,使用text();去赋值
get
语法格式:$.get(URL,callback); //callback里面可以写函数
使用案例:
$.get("/day16/DemoServlet02",function(data,status){
$("#div01").text(data);
});
post
语法格式:$.post(URL,data,callback);
使用案例:
function post(){
$.post("/day16/DemoServlet02",{name:"zhangsan",age:18},function(data,status){ //post请求参数s使用json格式,后面跟匿名函数
$("#div01").html(data);
});
}
JQuery去实现校验用户名

XStream使用
前提:先把XStream使用的两个jar包,存放至lib目录下
//XStream转化bean对象成xml XStream xStream = new XStream(); //想把id做成属性 xStream.useAttributeFor(CityBean.class,"id"); //设置别名 xStream.alias("city",CityBean.class); //转化一个对象(List集合)成xml字符串 String xml = xStream.toXML(list); //把xml转成一个javaBean对象 xStream.fromXML(file);
把list转化成json数据
//JSONArray--->变成数组,集合[]
//JSONObject--->变成简单的数据 {name:zhangsan,age:18}
JSONArray jsonArray = JSONArray.fromObject(list);
String json = jsonArray.toString();
Day09-Listener&Filter
Listener
监听器能做什么事?
监听某一个事件的发生。状态的改变。
监听器的内部机制?
其实就是接口的回调。
接口回调
Web监听器
总共有8个,划分成三种类型
1.定义一个类,实现接口
2.注册|配置监听器
<listener> <listener-class>类全名</listener-class> </listener>
监听三个作用域创建和销毁
request ---httpServletRequest
session ---httpSession
application --ServletContext
1.ServletContextListener
servletcontext创建
1.启动服务器的时候
servletContext销毁
2.关闭服务器,从服务器移除项目
2.ServletRequestListener
request创建:
访问服务器上的任意资源都会有请求出现(网页上录入访问请求地址):
访问html
访问jsp
访问servlet
request销毁:
服务器已经对这次请求作出了响应。
3.HttpSessionListener
session的创建:
只要调用getSession
html:不会
jsp:会 (默认调用:getSession())
servlet:会,需要手动调用getSession()
session的销毁:
超时 30分钟
正常关闭服务器(序列化)
非正常关闭 销毁
作用:
ServletContextListener
利用它来在servletContext创建的时候
1.完成自己想要的初始化工作
2.执行自定义任务调度,执行某一个任务
HttpSessionListener
统计在线人数
监听三个作用域属性状态变更
request ---ServletRequestAttributeListener
session ---HttpSessionAttributeListener
servletContext ---ServletContextAttributeListener
可以监听在作用域中值 添加(session.setAttribute("name","aobama");)|替换(session.setAttribute("name","zhangsan");)|移除(session.removeAttribute("name"))的动作。
以上三个监听器都对应三个方法,仅参数不同:
attributeAdded()
attributeReplaced()
attributeRemoved()
监听httpSession里面存值的状态变更
这一类监听器不用注册
HttpSessionBindingListener
监听对象与session绑定和解除绑定的动作
1.让javaBean实现该接口即可
HttpSessionActivationListener
用于监听现在session的值是钝化(序列化)还是活化(反序列化)的动作
钝化(序列化):把内存中的数据存储到硬盘上。
超时失效,session销毁了。
非正常关闭服务器,钝化。正常关闭服务器,销毁。
设置了session,多久时间,context.xml
活化(反序列化):把硬盘中的数据读取到内存中。
session的钝化活化的用意何在?
session中的值可能会很多,并且我们有很长一段时间不使用这个内存中的值,那么可以考虑把session的值可以存储到硬盘上【钝化】,等下一次再使用的时候,再从硬盘上提取出来【活化】
如何让session的值在一定时间内钝化?
做配置即可
1.在tomcat里面conf/context.xml里面配置
对所有的运行在这个服务器的项目生效
2.在conf/Catalina/localhost/context.xml配置(context.xml文件需要自己新建)
对localhost生效。localhost:8080
3.在自己的web工程项目中的META-INF/context.xml
只对当前的工程生效。
maxIdleSwap:1分钟不用就钝化
directory:钝化后的那个文件存放的目录位置(D:\tomcat\apache-tomcat-7.0.52\work\Catalina\localhost\ListernerDemo\itheima)
<Context> <Manager className="org.apache.catalina.session.PersistentManager" maxIdleSwap="1"> <Store className="org.apache.catalina.session.FileStore" directory="itheima"/> </Manager> </Context>
Filter
过滤器,其实就是对客户端发出来的请求进行过滤。浏览器发出,然后服务器派servlet处理。在中间就可以过滤,其实过滤器起到的是拦截的作用。
作用:
1.对一些敏感词汇进行过滤
2.统一设置编码
3.自动登录等
如何使用Filter ?
1.定义一个类,实现接口 Filter
2.注册过滤器
在web.xml里面注册,注册的手法与servlet基本一样。
Filter的生命周期
创建:在服务器启动的时候就创建(服务器加载这个项目的时候创建实例)。
销毁 :在服务器停止的时候销毁(关闭服务器或者从服务器中移除项目的时候)。
Filter执行顺序
1.客户端发出请求,先经过过滤器,如果过滤器放行,那么才能到servlet
2.如果有多个过滤器,那么它们会按照注册的映射顺序来排队,只要有一个过滤器不放行,那么后面排队的过滤器以及咱们的servlet都不会收到请求。
Filter处理细节:
1.init方法的参数FilterConfig,可以用于获取filter在注册的名字以及初始化参数。其实这里的设计的初衷于ServletConfig是一样的。
2.如果想放行,那么在doFilter方法里面操作,使用参数chain
chain.doFilter(request,response); 放行,让请求到达下一个目标。
3.<url-pattern>/*</url-pattern>写法格式与servlet一样。
1.全路径匹配,以/开始
/LoginServlet
2.以目录匹配,以/开始,以*结束
/demo01/*
3.以后缀名匹配,以*开始,以后缀名结束
*.jsp *.html
4.针对dispatcher设置
REQUEST:只要是请求过来都拦截,默认就是REQUEST
FORWARD:只要是转发都拦截。
ERROR:页面出错发生跳转
INCLUDE:包含页面的时候就拦截。
BeanUtils介绍
//注册自己的日期转换器
ConvertUtils.register(new MyDateConverter(),Date.class);//类MyDateConverter是自己编写的,其中代码包括SimpleFormat("yyyy-MM-dd");
//转化数据
Map map = request.getParameterMap();
UserBean bean = new UserBean();
//转化map中的数据,放置到bean对象身上
BeanUtils.populate(bean,map);
day10-基础加强
注解
什么是注解?
注解和接口,类一样,都是属于数据类型。
注解的作用:
1.编译检查:通过代码里标识注解,让编译器能够实现基本的编译检查。例如:@Override
2.代码分析:通过代码里标识注解,对代码进行分析,从而达到取代xml目的。
3.编写文档:通过代码里标识注解,辅助生成帮助文档对应的内容
注解可以在变量、方法、类之上加载
注解可以有属性@Test(timeout=1000),也可以没有属性@Override
@Test(timeout=1000):如果当前方法的执行时间超过1秒,会报错
注解有作用范围(源码、编译期间、运行期间)
源码期间有效:String类之上的@author,@see,@since,作用:使用命令javadoc命令将当前的源码生成帮助文件,可以识别String类上的相关的注解
编译期间有效:@Override @Deprecated @Suppresswarning,作用:告诉编译器部分信息
运行期间有效:@Test,作用:当我们在当前代码上以Junit方式运行时,Junit会运行方法上包含@Test注解的方法
回顾JDK中出现的3种注解
@Override:声明当前的方法是重写父类的方法
@SuppressWarnings("unused"):抑制编译器发生警告信息
@SuppressWarnings({"unused","rawtypes"}) :抑制编译器发生警告信息(如果有变量未使用,未遵循泛型格式错误不报警告)
@Deprecated:声明以下的方法是过时的方法,不建议大家使用
自定义注解
格式:
public @interface 注解名称{
public 属性类型 属性名称1();
public 属性类型 属性名称2() default 默认值;
}
自定义注解的属性支持的类型:
基本数据类型(4类8种)、
String、
Class:public Class c() default java.util.Date.class;
Annotation(注解类型)、
枚举类型、
以及以上类型的一维数组类型:public String[] strs();
注解作用:配置作用
配置:开发的时候部分信息不希望写死在程序中,例如数据库的用户名和密码,可以将用户名和密码存放在.txt,.properties,.xml文件中,利用程序来读取文件中的内容
框架:一大堆工具类组合,目的:加速项目开发
后期的学习中,框架部分hibernate,spring,struts2很多信息需要配置,提供了2种形式配置(xml,注解)
什么时候用注解来做配置?
如果配置信息不会发生的修改,例如servlet路径,建议使用注解的形式
如果配置信息需要发生频繁的修改,例如数据库的用户名和密码信息,建议采用传统方法(.txt,.properties,.xml)说明:xml更适用于有层次结构(学生下面有学号、电话,电话下面有家庭电话、公司电话)的键值对
注解案例
模拟Junit
1.自定义注解@MyTest
通过元注解@Rentention@Target声明当前注解作用域以及目标对象,如果没有声明,在运行期间是无法获取到注解的信息
//自定义注解,相当于JUnit@Test
//定义注解的时候,需要通过元注解Retention说明当前自定义注解的作用域(Class(编译期间),Source(源码期间),Runtime(运行期间))
@Retention(RetentionPolicy.RUNTIME)
//定义注解的时候,需要通过元注解Target说明当前的自定义注解的目标对象,如:类上,方法上,成员变量上
@Target(ElementType.METHOD)
public @interface MyTest{
//在MyTest注解中定义成员属性,默认值为-1
public long timeout() default -1;
}
2.定义UserDao
创建4个方法addUser,delUser,uptUser,getUser,在前三个方法上加上注解
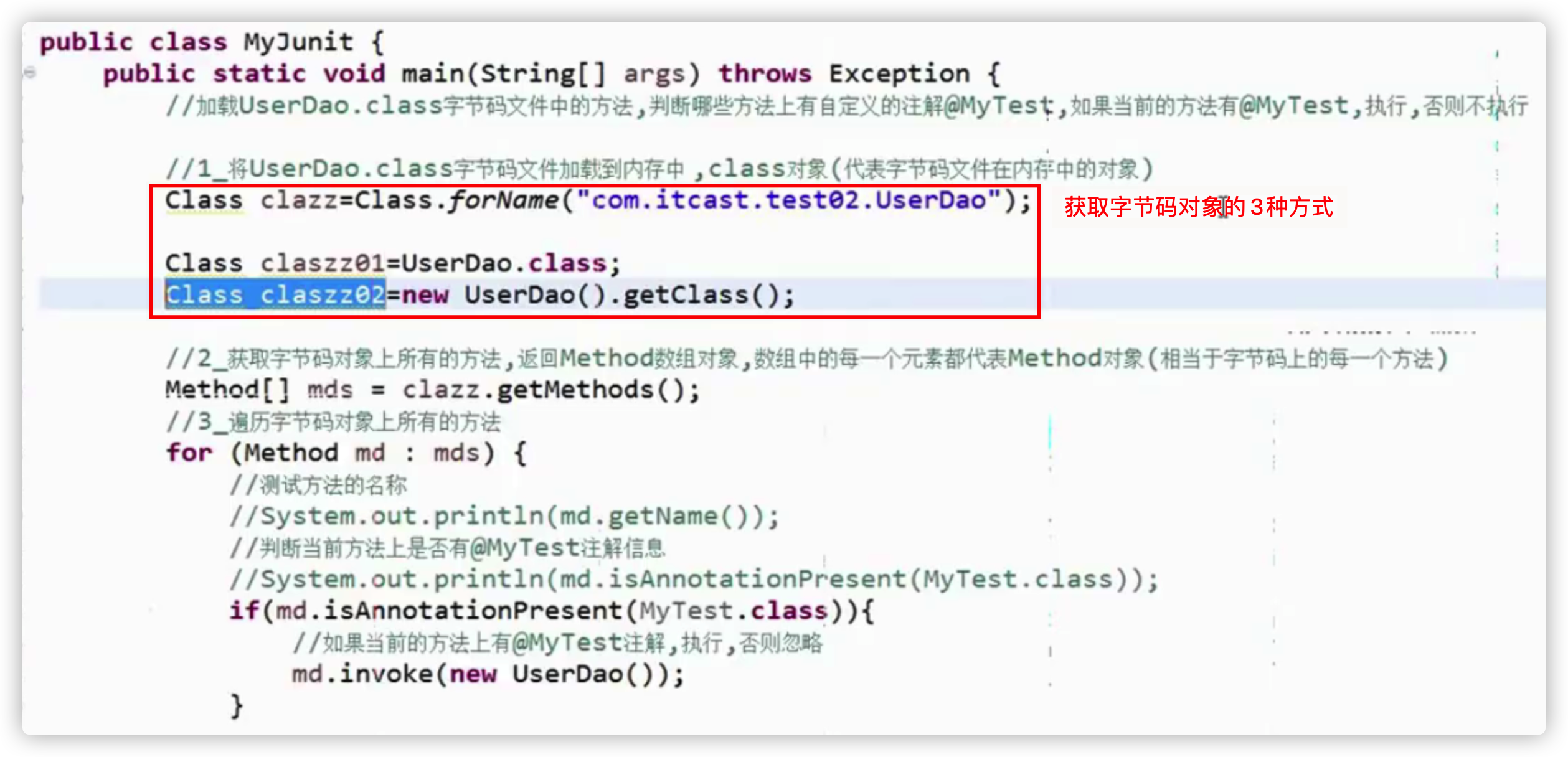
3.定义类MyJunit,模拟JUnit
将UserDao.class文件加载到内存
获取到字节码文件上所有的方法
遍历方法,判断每个方法上是否加载了@MyTest注解
如果当前方法上设置@MyTest,执行当前的方法
自定义注解的地位相当于dom4j解析xml(https://cloud.tencent.com/developer/article/2089146),一般不需要程序员自己编写,由服务器自行解析的,但是要学习和理解。
设计模式简介
设计模式:软件开发过程中,遇到相似问题,将问题的解决方式抽取模型(套路)
单例,工厂,装饰者,适配器,动态代理
单例模式
public class Stu{
private Stu(){} //私有构造方法不能new对象了
private static Stu stu = new Stu(); //静态区域只能加载一次,内存中只有一份,即地址是一样的
public static Stu getInstance(){
return stu;
}
}
谷歌汽车场景
java设计了汽车开发约定
interface ICar{start run stop}
class GoogleCar implements ICar{}
希望在将谷歌Car接入到生态圈平台时,增强汽车启动功能
装饰者模式
场景:二次开发的时候,无法获取到源码,无法使用继承(class类被finally修饰)前提下,要对已经存在对象上的功能进行增强。
前提:可以获取到被装饰的对象GoogleCar实现的所有接口
实现思路:自定义装饰类MyCar实现ICar接口,为自定义装饰类传递被装饰的对象
弊端:如果被实现的接口中的方法过多,装饰类中国的方法过多冗余(因为装饰类必须要实现接口的所有方法)
public class Mycar implements ICar{
ICar car;
public MyCar(ICar car){ //此处调用时传入:new GoogleCar
this.car = car;
}
@Override
public void start(){
System.out.println("检查天气是否良好");
car.start();
}
}
最后调用
public class TestCar{
public static void main(String[] args){
ICar car = new MyCar(new GoogleCar());
car.start();
}
}
动态代理模式
原理:通过虚拟机在内存中创建类似MyCar.class文件
要创建MyCar.class文件告诉虚拟机:
1.被创建的字节码文件上应该有多少方法
2.
字节码加载器:
jdk有一些程序,专门将各种字节码文件加载到内存,这类程序简称为字节码加载器
如何将字节码文件class文件加载到内存?
底层实现过程,利用IO流技术,获取到文件中的数据加载到内存
字节码加载器:3种
a.系统引导加载器:由于String.class,int.class等字节码文件需要频繁的被加载进内存,速度必须要快,底层用其他语言来实现,如:c C++。
b.ExtClassLoader:扩展类加载器:获取ext(extendtion)包下的某个类的字节码加载器 ExtClassLoader:扩展类加载器
c.应用类:程序员实现的所有的类都属于应用类
获取:应用类加载器AppClassLoader
//1param:固定值:告诉虚拟机用哪个字节码加载器加载内存中创建出的字节码文件
//2param:告诉虚拟机内存中正在被创建的字节码文件中应该有哪些方法
//3param:告诉虚拟机正在被创建的字节码上的各个方法如何创建
ICar car = (ICar)Proxy.newProxyInstance(TestCar.class.getClassLoader(),GoogleCar.class.getInterfaces(),new InvocationHandler(){ @Override
//method:代表正在执行的方法
//args:代表正在执行方法中的参数
//Object:代表方法执行之后的返回值
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable{
//代表每个方法执行完毕之后返回对象
Object obj=null;
if(method.getName().equalsIgnoreCase("start")){
System.out.println("检查天气是否良好");//增强方法
}
obj=method.invoke(new GoogleCar().args);//若方法返回是void,则返回null
}
return obj;
});
car.start();
car.run();
car.stop();
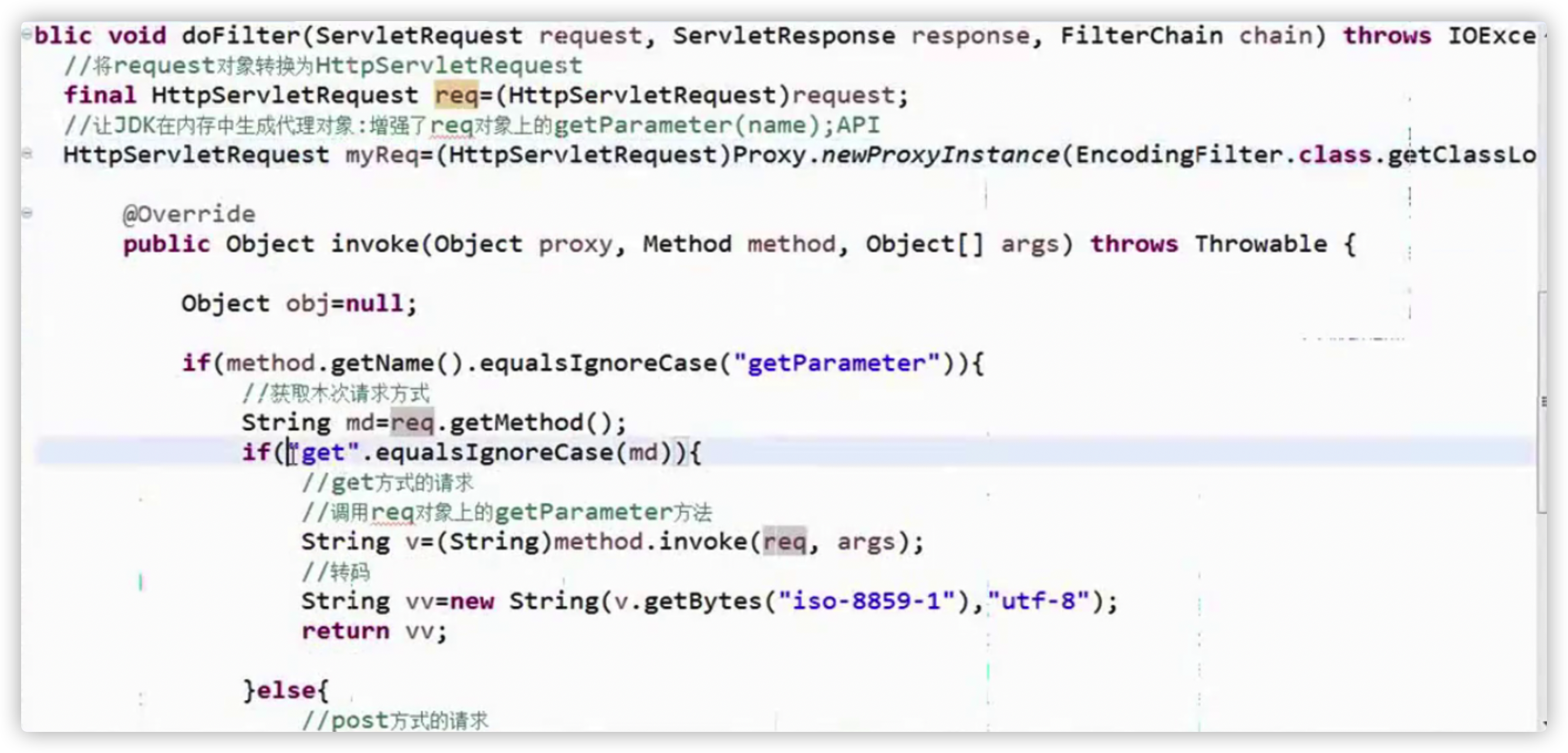
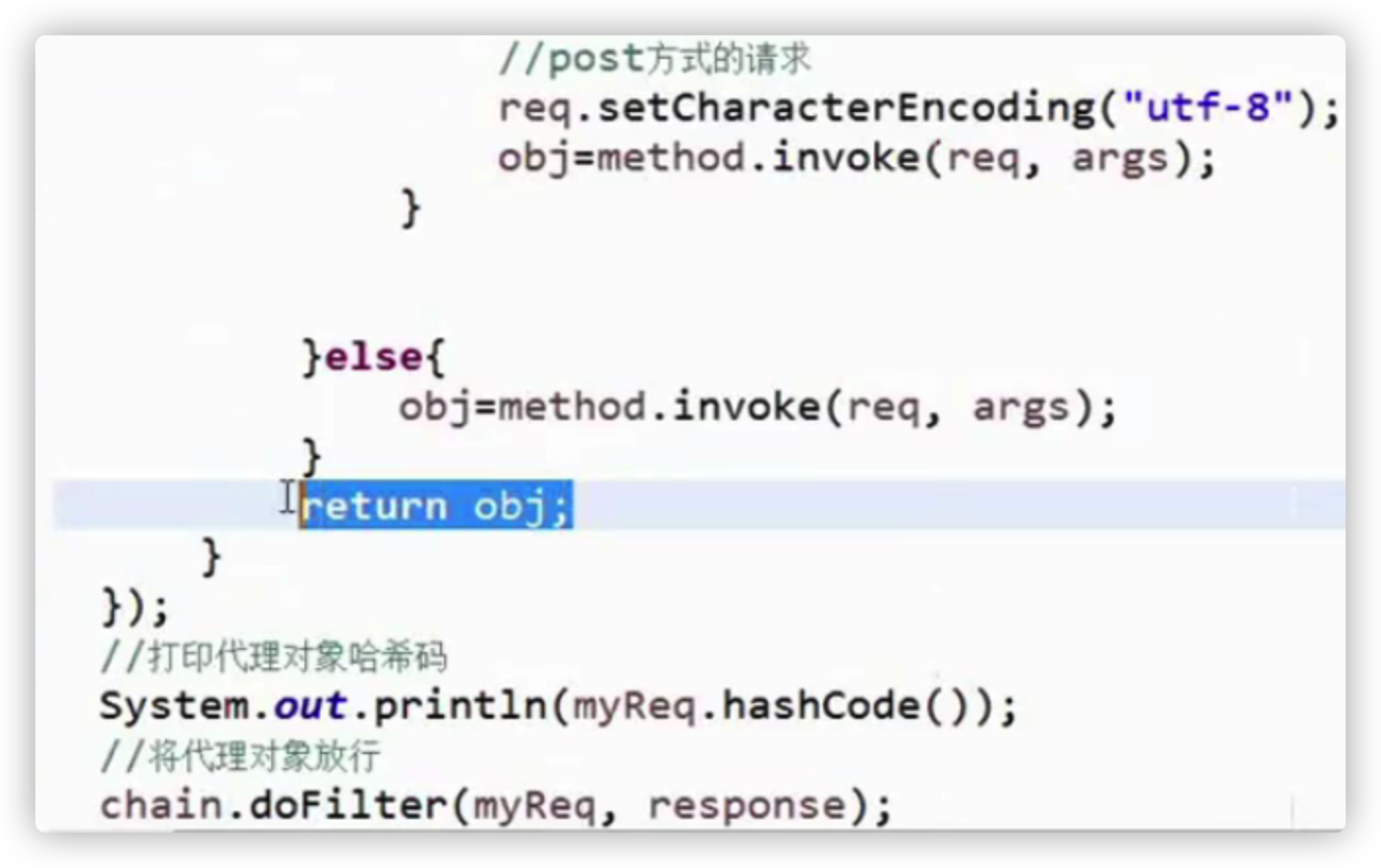
使用动态代理解决网站的字符集编码问题
需求:无论是在post/get方法,执行以下语句不存在中文乱码问题
String um=request.getParameter("username");
System.out.println(um);
过滤器中,为request上的getParameter()功能进行增强
思路:
判断当前的请求是get/post request.getMethod();
如果是post,设置一句话:request.setCharacterEncoding("utf-8"); 放行
如果是get,调用原先的String v = request.getParameter(neme);将v进行转码,放行
//todo:下面的两张图用代码敲出来,搞成一个代码块
day11-Linux(剩余部分待学习)
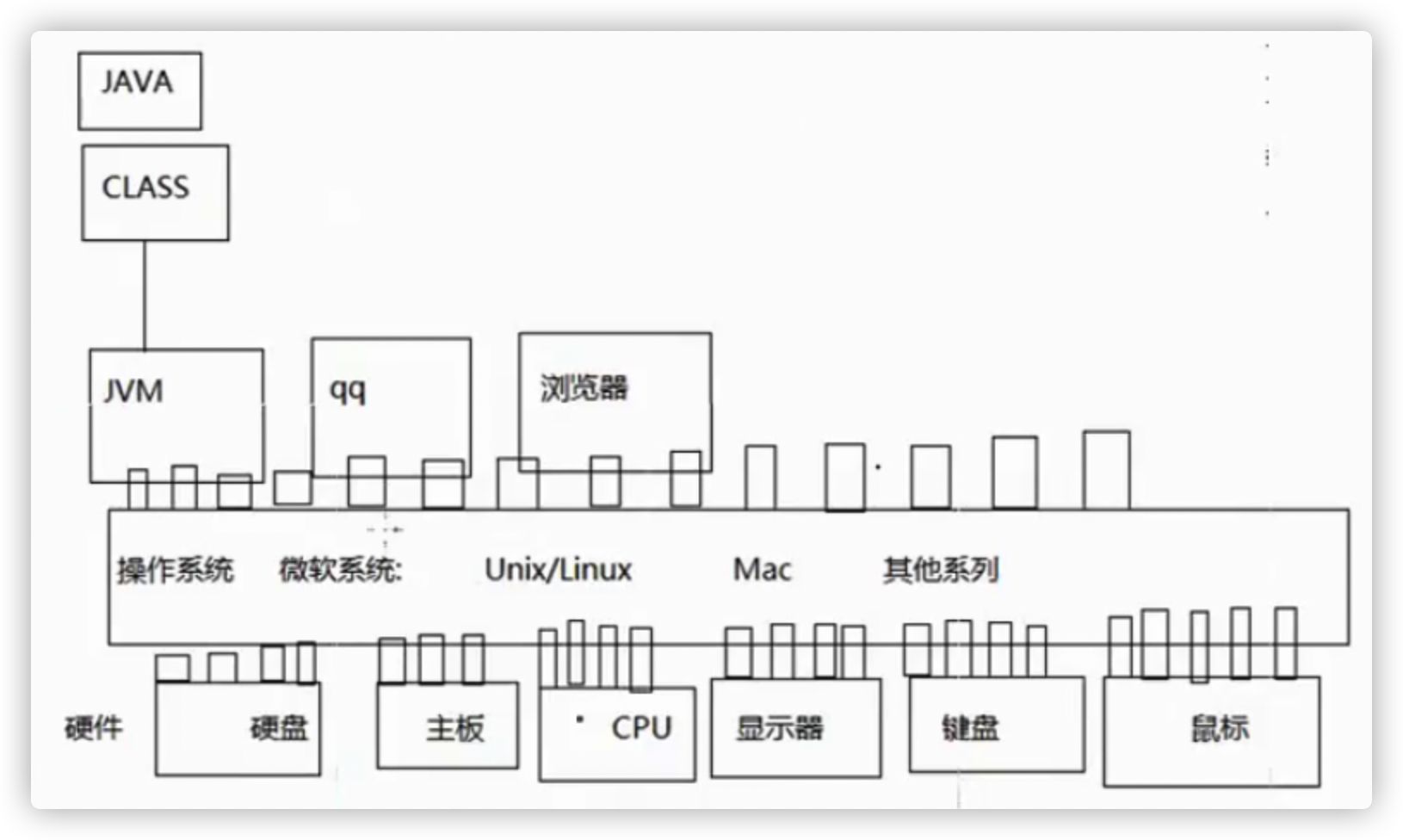
虚拟机(本身是一个软件):通过调用系统接口模拟出一台机器
虚拟机:指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
VMware Workstation是一台虚拟机软件(威睿工作站),还有其他的,如:VirtualBox后更名为Oracle VM VirtualBox
linux版本:redhat(红帽)、CentOS、红旗、ubuntu(乌班图),入门建议使用:CentOS
服务器(硬件/软件):
硬件:网吧一台公共机器,硬件服务器
软件服务器:WebServer(Tomcat),邮件,DNS服务器(域名解析:www.baidu.com)
linux目录结构:只有1个目录,根目录
usr:相当于program files(软件安装目录)
etc:存放系统配置文件
root:系统管理员默认目录
home:存放其他用户的目录
pwd:打印当前目录
cd /:切换到根目录
ll:查看当前目录下的内容
利用CRT连接linux:
在linux获取ip:ifconfig
打开绿色版本的CRT:点击SecureCRT.exe
点击文件》连接〉快速连接,录入ip地址后,点击连接按钮
依次输入用户名,密码,连接到linux机器上
解决CRT编码问题:
关闭CRT,重新打开
选中待连接的IP,右键》属性,选择外观,编码改为utf-8
day12-Linux系统下软件安装&redis入门
扩展知识学习:ssm、 lucuen、 solor
NoSQL:not only sql
为什么有NoSQL?
互联网项目特点:数据库高并发读写,海量数据高效存储,可扩展
NoSQL主流:
键值对(redis),列式存储、文档类型、图形数据库
Redis简介
什么是实时系统:瞬时可以实现某些数据的统计或者是功能的实现
Redis由来:
什么是redis?
由C语言实现的直接操作内存的开源的高性能的数据库软件
redis应用场景:
缓存(数据查询、短连接、新闻内容、商品内容等等)
聊天室的在线好友列表
任务队列(秒杀、抢购、12306等等)
应用排行榜
网站访问统计
数据过期处理(可以精确到毫秒)
分布式集群架构中的session分离
安装redis
原理:
redis安装包:源码形式提供 .c文件
将.c编译为.o文件 需要安装:gcc
将编译后的文件安装在linux系统上
步骤:
1.获取安装包 redis-3.0.7.tar.gz
2.利用filezilla.exe软件将安装包上传到linux系统的/root/目录
3.执行如下linux命令:
cd /root/
tar -zxvf redis-3.0.7.tar.gz
4.编译 将源码翻译为.o文件
cd /root/redis-3.0..7
make
5.创建一个安装目录 /usr/local/redis(通过secureCRT软件,界面右键》创建文件夹redis)
6.安装redis
cd /root/redis-3.0.7
make PREFIX=/usr/local/redis install (出现:It's a good idea to run 'make test'字样,表示安装成功)
7.由于redis启动需要一个配置文件,将配置文件复制到/usr/local/redis/
cp /root/redis-3.0.7/redis.conf /usr/local/redis
8.修改/usr/local/redis/redis.conf(以后端模式启动)
daemonize no 改为 daemonize yes
9.后端方式启动redis服务端:
./bin/redis-server ./redis.conf
查看redis是否启动成功:
Redis默认端口6379,通过当前服务进行查看:ps -ef|grep -i redis
补充知识:
查看机器开放的端口号:/etc/init.d/iptables status
开放6379端口号:/sbin/iptables -I INPUT -p tcp --dport 6379 -j ACCEPT
将打开的端口的访问规则保存在文件中:/etc/sysconfig/iptables
10.连接redis客户端:./bin/redis-cli
11.执行redis命令:
向redis设置数据:set name mary
向redis获取数据:get name
删除指定key的内容:del name
查看当前库中所有的key值:keys *
redis命令学习。。。