第一章、Python概述
1.1 扩展库安装方法
使用pip命令安装扩展库。
在cmd命令行中输入pip,回车后可以看到pip命令的使用说明。
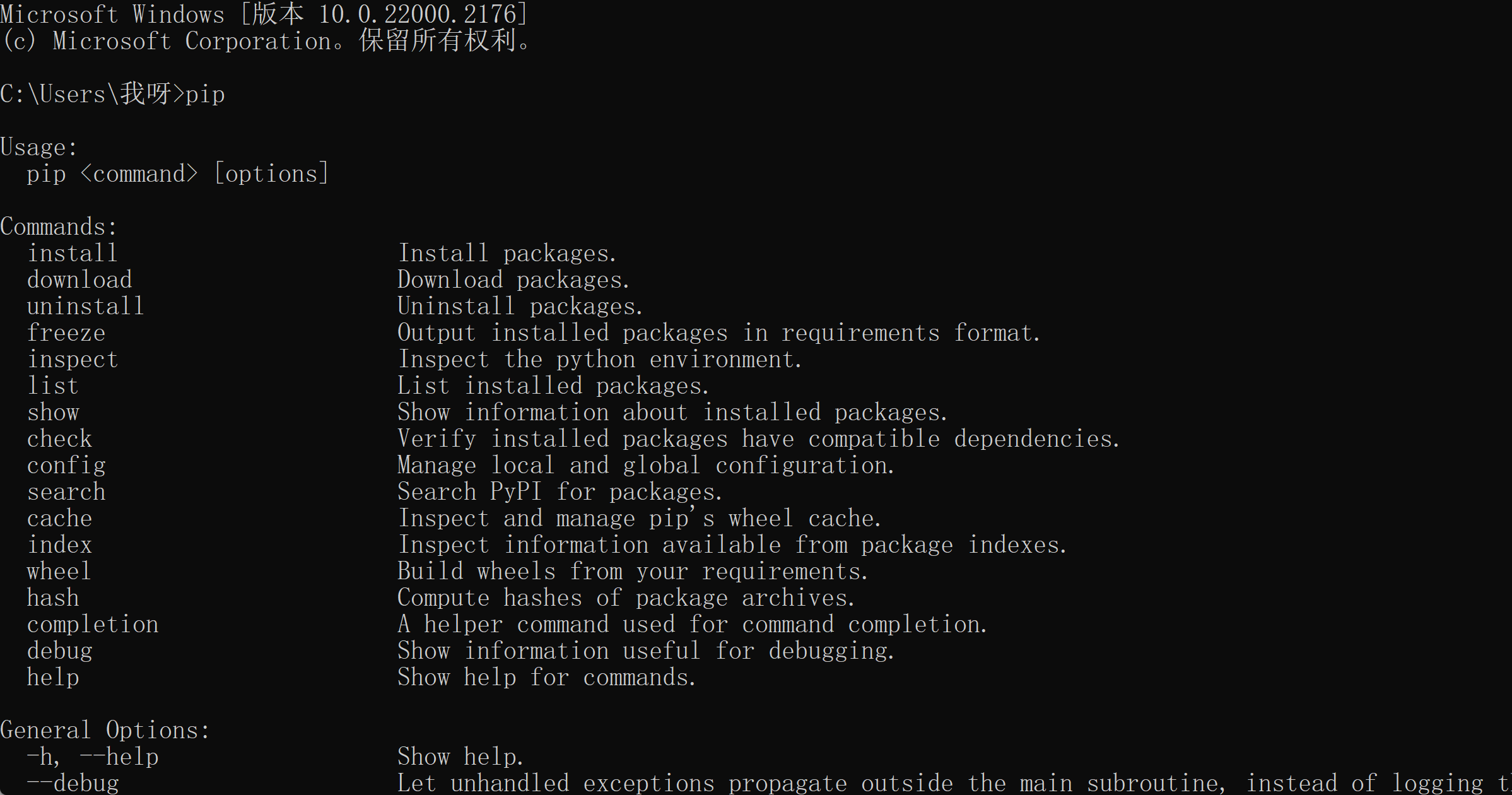
1.2 常用的pip命令
| pip命令示例 | 说 明 | |
|---|---|---|
| pip freeze[>requirements.txt] | 列出已安装扩展库及其版本号(不知道怎么用。。?) | |
| pip install SomePackage[=version] | 在线安装SomePackage扩展库的指定版本 | |
| pip install SomePackage.whl | 通过whl文件离线安装扩展库 | |
| pip install packagel package2 .. | 依次(在线)安装packagel、package2等扩展库 | |
| pip install -r requirements.txt | 安装requirements.xt文件中指定的扩展库 | |
| pip install -upgrade SomePackage | 升级SomePackage扩展库 | |
| pip uninstall SomePackage[=version] | 卸载SomePackage扩展库 | |
| python.exe -m pip install --upgrade pip | 升级pip |
使用示例
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # 指定国内镜像源下载
pip install PyPDF2 # 安装PyPDF2模块
pip install PyPDF2==3.0.1 # 安装3.0.1版本
pip install -upgrade PyPDF2 # 升级PyPDF2
pip uninstall PyPDF2 # 卸载PyPDF2
1.3 导入包/模块的方法
直接导入(常用) import 模块名
import math # 导入math
math.sqrt(10) # 通过math.调用math模块下的功能
起别名 import 模块名 as 别名
import math as ma
ma.sqrt(20) # 使用别名
math.sqrt(20) # 也可使用原名
导入模块下的某个功能 form 模块名 import 功能名 (as 功能别名)
form math import sqrt
sqrt(30) # 不需要加前缀,直接使用
form math import sqrt as sq # 起别名
sq(40)
导入模块下的全部功能 form 模块名 import *
form math import * # 将math模块中的所有都导入,容易产生名称冲突
sqrt(50)
sin(1)
3、dir()和help()
dir(模块名) # 查看模块中的功能
help(模块功能名) # 查看功能的使用方法
第二章、内置对象,运算符,表达式,关键字
2.1 Python常用内置对象
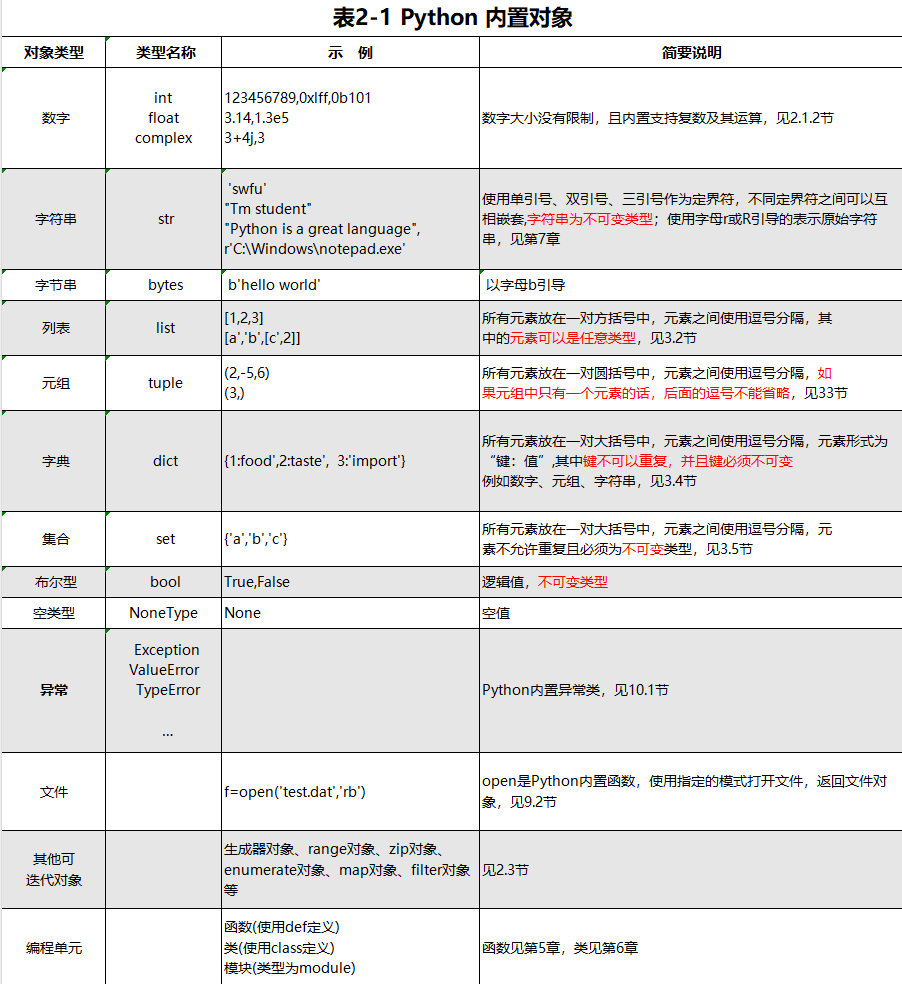
注意bool类型的值:
print(True==1) # True
print(False==0) # True
print(True==2) # False
2.1.1 常量与变量
常量:指不能改变的字面值。数字,字符串,元组都是常量。(???有疑问,不是所python中没有常量吗?)
变量:一般是指值可以变化的量。
在Python中,不需要先声明变量名及其类型,赋值语句可以直接创建任意类型的变量。
赋值语句的执行过程是:首先把等号右侧表达式的值计算出来,然后在内存中寻找一个位置把值存储进去,最后创建变量并引用这个内存地址。也就是说,Python 变量并不直接存储值,而是存储了值的内存地址或者引用,所以,不仅变量的值可以改变,变量的类型也可以随时发生改变。
变量名的密码规范:
- 以字母、汉字、或下划线开头。
- 变量名中不能有空格或标点符号。
- 不能使用关键字作为变量名,如if、else、for、等都是非法的。
- 变量名区分大小写,如abc与Abc是不同的变量。
- 不建议使用系统内置的模块名,类型名、或函数名,以及导入的模块名及其成员名。
2.1.2 整数、实数、复数
二进制:以0b开头
八进制:以0o开头
十六进制:以0x开头
Python支持任意大的数字。但是由于精度问题,Python对于实数运算可能存在一些误差,应尽量避免在实数之间直接进行相等性测试。例如
>>>0.4-0.3
0.10000000000000003
Python内置支持复数运算,形式与数学上一致。
为了提高可读性,Python3.6X及以上版本支持在数字中间插入单个下划线对数字进行分组,但下划线不能出现在数字开头或结尾。例如1000000可以写成1_000_000。
>>>1_000_000
1000000
2.1.3 字符串
Python 使用单引号、双引号、三单引号、三双引号作为定界符来表示字符串,并且不同的定界符之间可以互相嵌套。另外,Python 3.x 全面支持中文,使用内置函数 len()统计长度时中文和英文字母都作为一个字符对待,甚至可以使用中文作为变量名。
(1)字符串的定义
s1='apple'
s2="banana"
s3='''ege'''
(2)字符串索引
# 在字符串变量名后更[n],获取n号索引
s='abcdef'
s[0] # 获取字符串s中的第0号索引的值 a
s[-1] # 先后索引,获取倒数第一个值 f
(3)字符串切片
# 切片 [开始:结束:步长(默认为1)] 顾头不顾尾,从后往前也是不取最后取的那一个
# 无论是行前往后索引,还是从后往前索引,都是不取后面的那个索引的值,也就是第二个参数的值。
# 例如从1取到3,那么不包含3,从3取到1,那么不包含1
s='abcdef'
s[0:3] # 获取第0号索引到第3号索引(不包含3号)的片段 abc
s[2:5] # cde
s[3:] # 省略第二个参数,表示截取到字符串末尾(包含最后一个字符) ef
S[:] # 第一、二个参数都省略,获取整个字符串 abcdef
s[0:5:2] # 从0号索引到5号索引(不包含5号)之间,每隔一个字符取一个值 ace
s[3:-1] # 获取3号索引到-1号索引(不包含-1号)的片段 de
# 反向切片(步长为负数)
s[4:1:-1] # edc
s[-1:2:-1] # 从倒数第一个到2号索引(不包含2号),从后往前获取它们之间的片段 fed
s[::-1] # 反转整个字符串 fedcba
2.1.4 列表、元组、字典、集合
列表、元组、字典、集合都是Python内置的容器对象,可以包含和持有多个元素。
(1)列表
# 使用[]和赋值语句就可以创建列表
l=[123,'abc',[111,'lll'],(123,666,'fjdksla'),{1,2,3,'fdsa'},{1:'one'}]
列表是可变类型,
(2)元组
# 使用()和赋值语句就可以创建元组
tup = ('sjsjsjskk', 455665, (1, 2), [3, 4], {5, 6}, [7, {8, 9, (10, 11)}])
元组是不可变类型
(3)字典
# 使用{}和赋值语句就可以创建字典,但{}中的元素要是“key:vallue"这样的键值对
d = {'one': '1', 'two': 2, 'dictionary': '字典', 'name': '我呀'}
字典是可变类型,但字典的键(key)必须为不可变类型
(4)集合
# 使用{}和赋值语句就可以创建集合
s = {'fnshbhbhb', 1, (2, 3), (4), (5, 6), 1, 4}
集合中的元素因该被不可变类型
集合与数学中的集合一样,具有去重的现在,集合中相同的元素只会保存一个
2.2 Python运算符运算符与表达式
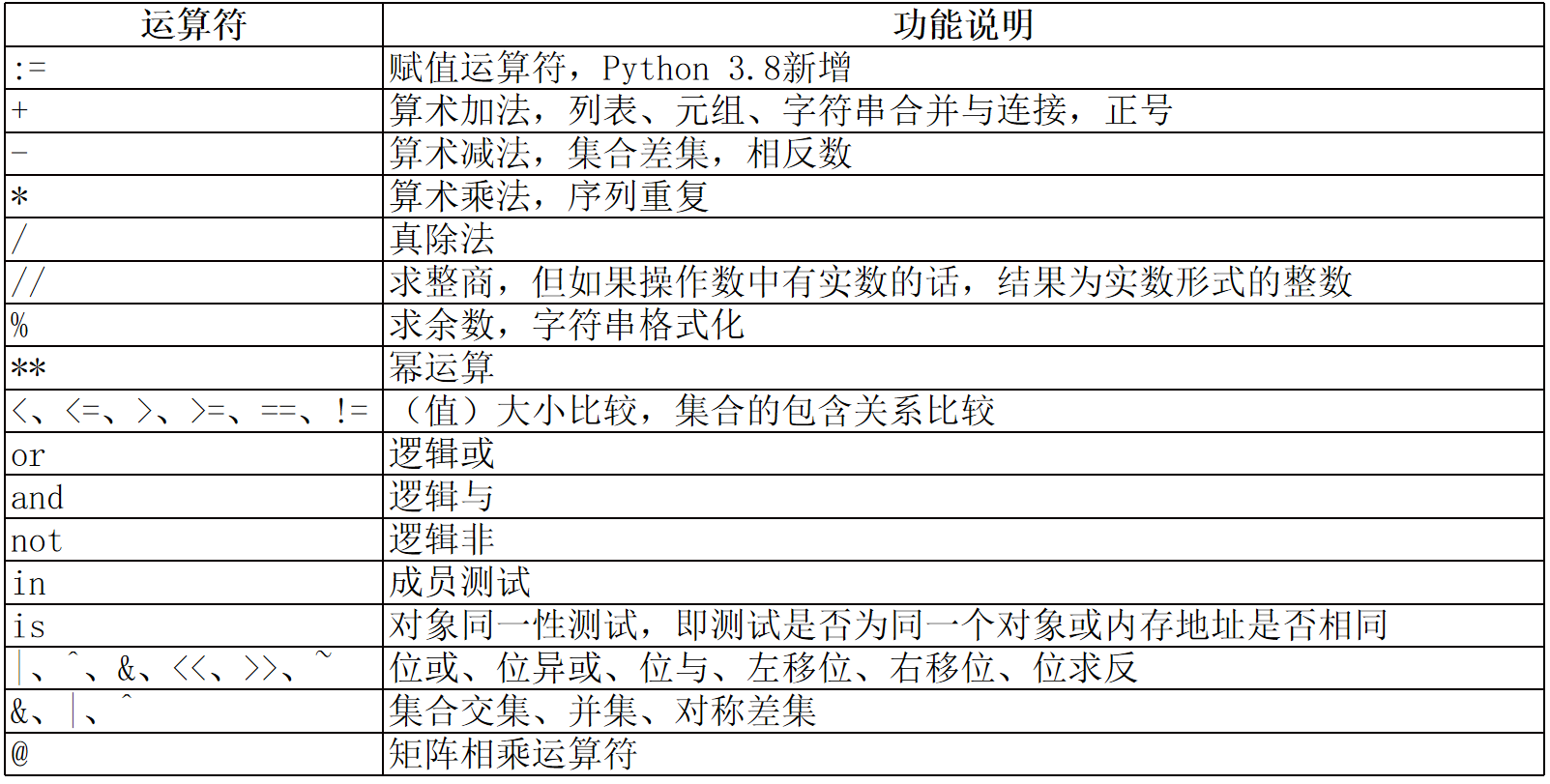
# ------------------------------ +
print('{0:-^30}'.format(' + '))
# 算数加法
my_sum = 1 + 2 + 3
print(my_sum)
# 列表合并
ls1 = ['a', 'b', 'c']
ls2 = [1, 2, 3]
ls3 = ls1 + ls2
print(ls3)
# 元组合并
tup = (1, 2, 3) + (4, 5, 6,)
print(tup)
# 字符串拼接
s = 'abc' + 'def'
print(s)
# ------------------------------ -
print('{0:-^30}'.format(' - '))
# 算数减法
a = 1 - 2 - 3
print(a)
# 集合差集
set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
set2 = {1, 2, 3, 4, 5, 6}
set3 = set1 - set2
print(set3)
print(set2 - set1) # 空集
# ------------------------------ *
print('{0:-^30}'.format(' * '))
# 算数乘法
b = 1 * 2 * 3 * 4 * 5
print(b)
# 序列重复
# 字典与集合不可进行乘法,应为集合中不存在重复元素,字典的key不可重复
l = [1, 2, 3]
s = 'abc'
tup = (7, 8, 9)
set4 = {1, 2, 3}
dic = {1: 'one', 2: 'two', 3: 'three'}
print(l * 3)
print(s * 3)
print(tup * 3)
# ------------------------------ /
print('{0:-^30}'.format(' / '))
# 真除法,结果为实数
print(3 / 2)
print(3 / 2.0) # 结果都为1.5
# ------------------------------ //
print('{0:-^30}'.format(' // '))
# 求整商,结果为整数,但如果操作数中有实数,那么结果为实数形式的整数。
print(5 // 2, type(5 // 2)) # 2 int
print(5 // 2.0, type(5 // 2.0)) # 2.0 float
# ------------------------------ %
print('{0:-^30}'.format(' % '))
# 求余数
print(5 % 2)
print(6 % 3)
print(3 % 5) # 商0,余3
# 字符串格式化
height = 178.0 # float
weight = 76 # int
b = '娃哈哈' # str
print('这就是传说中的%s,太酷啦!' % b)
print('保留3位小数:%.3f') # 字符串后面没有%和对应的变量的话就是常规输出
print('保留3位小数:%.3f' % height) # 与c语言的%类似
print('我的身高为%.2f,我的体重为%d' % (height, weight)) # 多个值要放在元组中,按前后顺序
tup = (height, weight)
print('我的身高为%.2f,我的体重为%d' % tup) # 直接放一个元组变量也是可以的
print('我的身高为%(身高).3f,我的体重为%(体重)d' % {'体重': weight, '身高': height}) # 使用字典,按key传值
# ------------------------------ **
print('{0:-^30}'.format(' ** '))
# 幂运算,具有右结合性
print(3 ** 3)
print(2 * 3 ** 3)
# ------------------------------ < <= > >= == !=
print('{0:-^30}'.format(' < <= > >= == != '))
# 值的比较
print(3 < 2)
print('abc' < 'abd', 'abc' >= 'aaa', 'abc' < 'abca') # 对应字符比较(ASCII码值),只要其中一对比出结果了,就不再进行后面的比较(都相等的话,长的大)
print('abcdef' == 'abcde') # 每一个字符都要相等
print(['a', 2, 5] >= ['a', 2, 5]) # 列表之间的比较也是一个元素一个元素的比,但对应元素必须是同类型的。
print((1, 2, 3) > (3, 2, 1), (1, 2, 3) <= (1, 2, 6))
print({1: 'one', 2: 'two'} != {3: 'one', 4: 'two'}) # 字典之间只能支持==和!
# 集合的包含关系比较
print('{0:-^30}'.format('集合包含关系'))
set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 <= set2)
print(set1 == set2)
print(set1 > set2)
print(set1 >= set2)
print(set1 != set2)
# < 真子集 <= 子集(两个集合可以相等)
# == 相等 != 不相等
# ------------------------------ and or not
print('{0:-^30}'.format(' and or not '))
if True and False:
print('与')
if True or False:
print('或')
if not False:
print('非')
# ------------------------------ in
print('{0:-^30}'.format(' in '))
# 成员运算符
print('{0:-^20}'.format('in'))
print('a' in 'abc')
print('a' in ['a', 'b', 'c'])
print('a' in {1: 'a', 2: 'b'}) # 字典中找的是key
print('a' in ('a', 1, 'c'))
print('a' in {'a', 'b', 'c'})
# ------------------------------ is
print('{0:-^30}'.format(' is '))
# 对象同一性测试,即测试是否为同一对象或内存地址是否相同
a = ['abc']
b = a
print(type(a))
print(type(b))
print(a is b)
def func():
pass
f = func
print(func, f)
print(f is func)
# ------------------------------ | ^ & << >> ~
# 位或,位异或,位与,左移位,右移位,位求反
print('{0:-^30}'.format(' | ^ & << >> ~ '))
print(6 ^ 7) # 0b110与0b111进行异或运算
print(0b11 & 0b110) # 0b011与0b110进行与运算
print(0 | 1)
print(0b110 << 1) # 左移一位,变为0b1100
print(6 << 1) # 转为二进制后,左移一位
print(0b1100 >> 2) # 右移2位,变为0b11
print(~0b111) # 位求反 结果为-8 ???和预期结果不同 -0b111-0b1得到-0b1000,就是-8
# ------------------------------ & | ^
# 集合的交集,并集,对称差集
print('{0:-^30}'.format(' & | ^ '))
set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 & set2) # 交集
print(set1 | set2) # 并集
print(set2 - set1) # 对称差集(只在A中出现和只在B中出现的元素,即A并B-AB)
print(set1 - set2)
# 其他
# Python不支持自增和自减运算符(++、--)
i = 3
print(++i) # 解释为两个正号
print(+(+i)) # 与++i等价
# print(i++) # 语法不支持
# --i也与++i类似,表示两个负号,负负得正
# 另外的一些运算符
# 下标运算符:[]
# 属性访问运算符:.
# 复合赋值运算符:+=、-=、*=、/=、//=、**=、|=、^= (|=和^=还不知道是什么意思)
2.3 Python常用内置函数
内置函数不需要额外导入任何模块,就可以直接使用,具有非常快的运行速度,推荐优先使用。
使用下面这个命令可以查看所有内置函数和内置对象
dir(__builtins__)

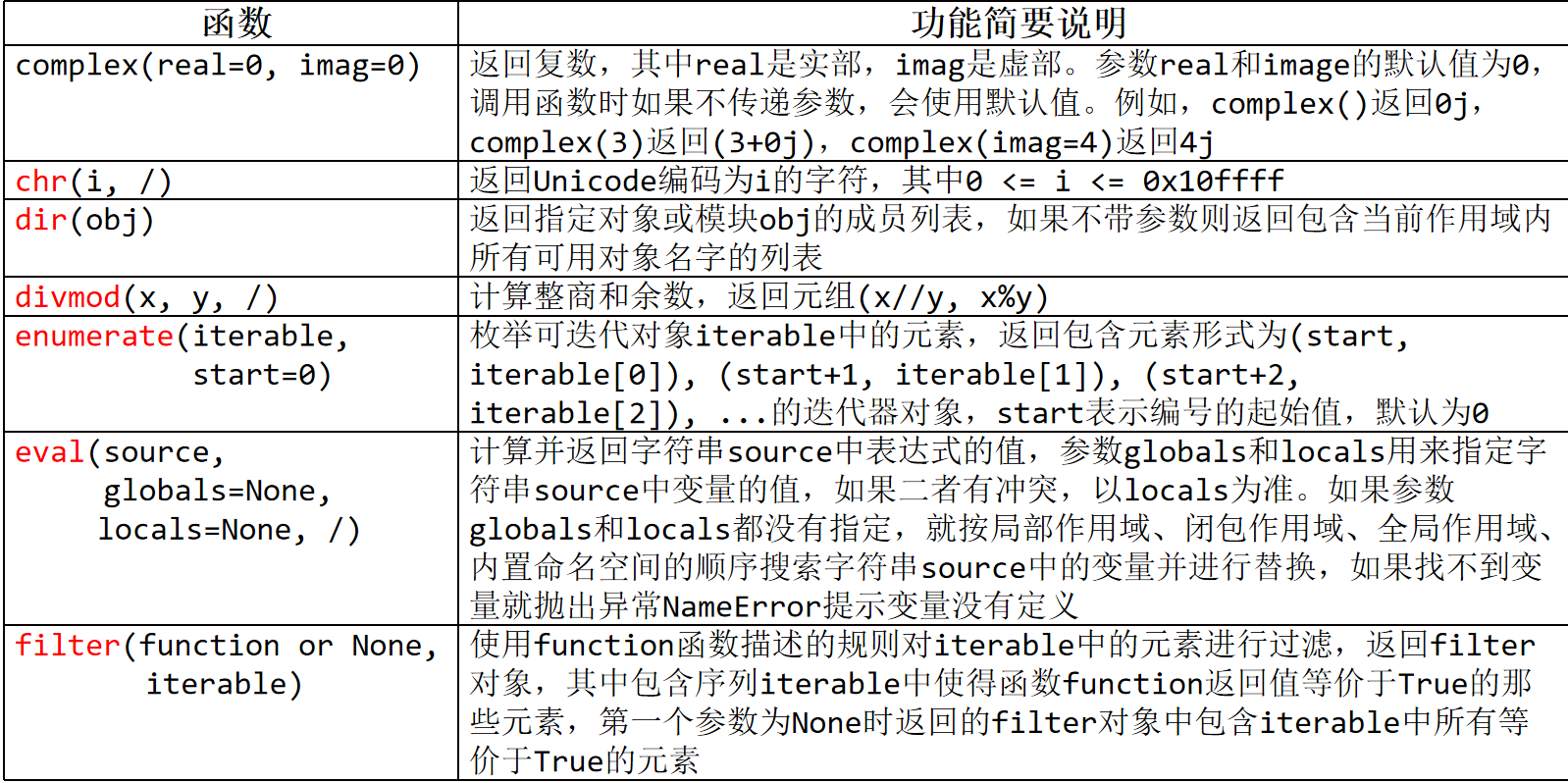
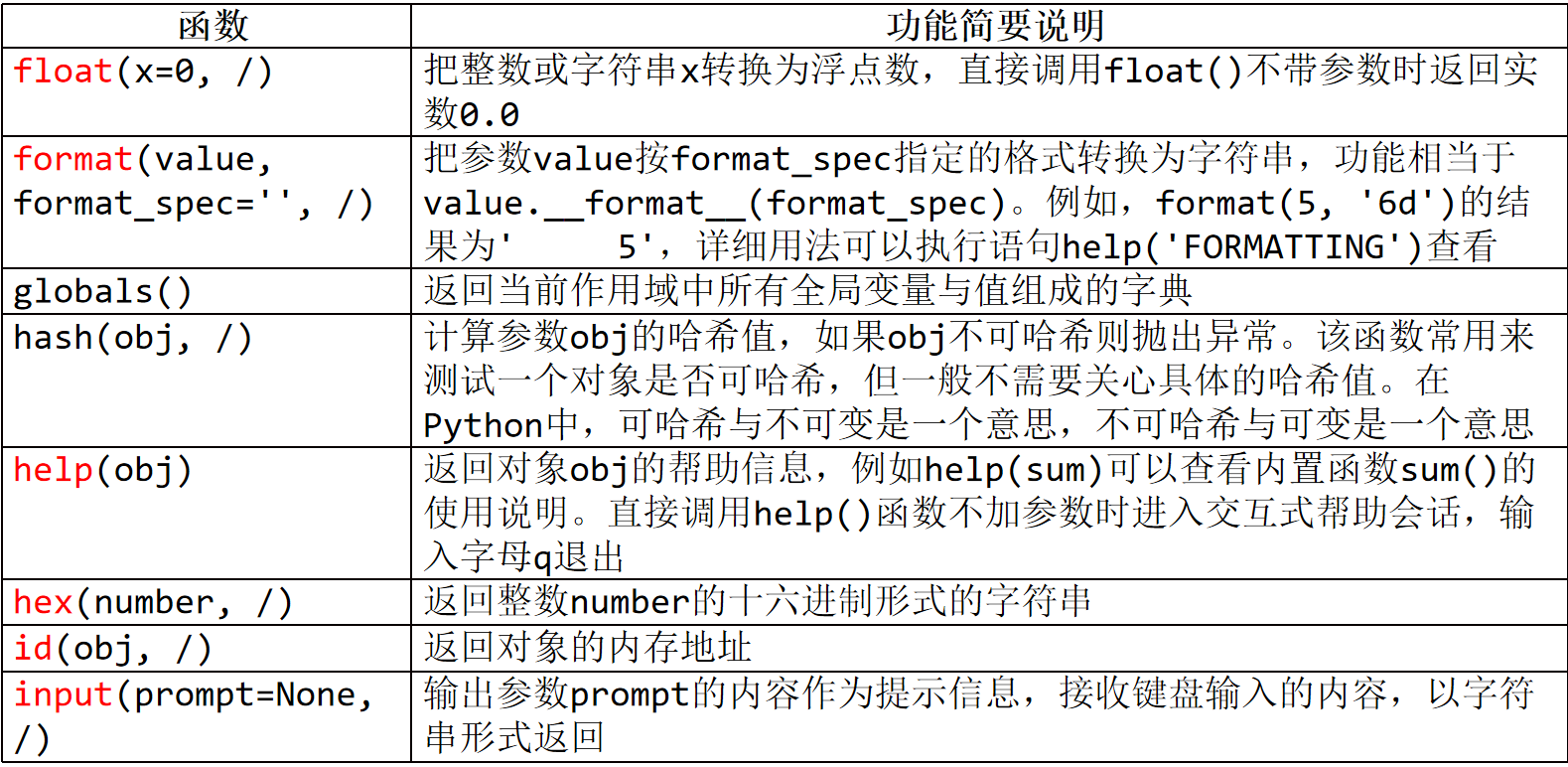
一、判断
1、all(iterable,/)
如果可迭代对象中所有元素都等价于True则返回True,否则返回False
print(all([1, 2, 3])) # Ture
print(all([0,0,1])) # False
print(all([])) # Ture 为什么是T?
2、any(iterable,/)
只要可迭代对象iterable中存在等价于True的元素就返回True,否则返回False
print(any([1, 2, 3])) # Ture
print(any([0,0,1])) # Ture
print(any([0,0,0])) # False
print(any('abc')) # Ture
print(any([])) # False 为什么是F?
3、bool(x)
如果参数x的值等价于True就返回True,否则返回False
print(bool([])) # F
print(bool(0)) # F
print(bool([1])) # T
print(bool('0')) # T
4、callable(obj,/)
如果obj为可调用对象就返回True,否则返回False。
Python中的可调用对象包括内置函数、标准库函数、扩展库函数、自定义函数、lambda表达式、
类、类方法、静态方法、实例方法、包含特殊方法__call__的类的对象
print(callable(int)) # Ture
print(callable('abc')) # False
5、isinstance(obj,class or tuple,/)
测试对象obj是否属于指定类型的实例(如果有多个类型的话需要放到元组中),返回值为bool类型
print(isinstance([1, 2, 3], list)) # True
print(isinstance((2), tuple)) # False
print(isinstance((2,), tuple)) # True
多种类型的话需要放在元组中,只要满足任意一种类型,就返回True
print(isinstance('abc',(list,tuple,str,))) # True
二、转换
1、bytes()
(0)字节对象(不可变类型,与字符串相似)
print(type('abc'),type(b'abc')) # 'abc'时str对象,b'abc'是bytes对象
(1)bytes() or bytes(int)
参数为空或整形(2、8、10、16进制都可以),创建指定长度的0填充的字节对象
print(bytes()) # 创建一个空的字节对象
print(type(bytes())) # <class 'bytes'>
print(bytes(10)) # 创建10个字节的以0填充的字节对象 b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
print(bytes(0b11)) # 创建三个字节的以0填充的字节对象 b'\x00\x00\x00'
print(bytes(0xA)) # 创建10个字节的以0填充的字节对象 b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
(2)bytes(iterable of ints)
参数为可迭代对象,将可迭代对象中的每个元素x(x为int且0<=x<=255),按照x的数值对应的ASCII码表的字符来显示
例如,x值为65(或0x41,或0b01000001),65对应的ASCII表中的字符为'A',那么转换为字节对象后,它表示为b'A'
但是,如果x的值对应的ASCII字符不可显示(如响铃,退格),那么就用16进制来表示它,如响铃(值为7)那么结果为b'\x07'
如果是换行符\n、制表符\t、回车符\r、退格符\b、换页符\f、反斜杠\、单引号'、双引号"这些容易产生混淆的特殊字符,
那么也可能是用16进制来表示,但是用print输出时,会自动解码这些字节,并用其对应的字符表示。
print(bytes(range(10))) # 十进制值为0到9的ASCII字符(不可显示的用16进制表示)
print(bytes([0,1,2,3,4,5,6,7,8,32])) # 32对应的字符为Space空格
print(bytes(range(65,71))) # 65到70的ASCII字符
print(bytes([10, 9, 13, 8, 12, 92, 39, 34])) # 对应的特殊字符:换行符\n、制表符\t、回车符\r、退格符\b、换页符\f、反斜杠\、单引号'、双引号"
print(bytes([65,0b01000001,0x41])) # 字符A对应的三种进制的值
print(bytes([65]),bytes((66,))) # 也可以通过这样的方式转换单个字符,只要是可迭代对象都可以
输出结果:
b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t'
b'\x00\x01\x02\x03\x04\x05\x06\x07\x08 '
b'ABCDEF'
b'\n\t\r\x08\x0c\\\'"'
b'AAA'
b'A' b'B'
(3)bytes(string,encoding[,errors])
将给定字符串转换为字节序列,encoding表示指定的字符编码方式
print(bytes('abc',encoding='UTF-8')) # b'abc'
print(bytes('字节序列',encoding='utf-8')) # b'\xe5\xad\x97\xe8\x8a\x82\xe5\xba\x8f\xe5\x88\x97'
在 Python 3.x 版本中,如果字符串中只包含 ASCII 码对应的字符,则 print 函数会直接输出这些字符而不会转换为 UTF-8 编码值。
(4)bytes(bytes or buffer)
通过缓冲区协议复制现有二进制数据(还没学过,略)
print(bytes(b'hello world')) # 使用一个 bytes 对象来创建一个新的 bytes 对象
2、进制转换
(1)bin(number,/)
返回整数number的二进制形式的字符串,例如表达式bin(5)的值是'0b101'
print(bin(520)) # 0b1000001000
print(bin(10)) # 0b1010
(2)hex(number,/)
返回整数number的16进制形式的字符串
print(hex(15)) # 0xf
print(hex(8)) # 0x8
print(hex(32)) # 0x20
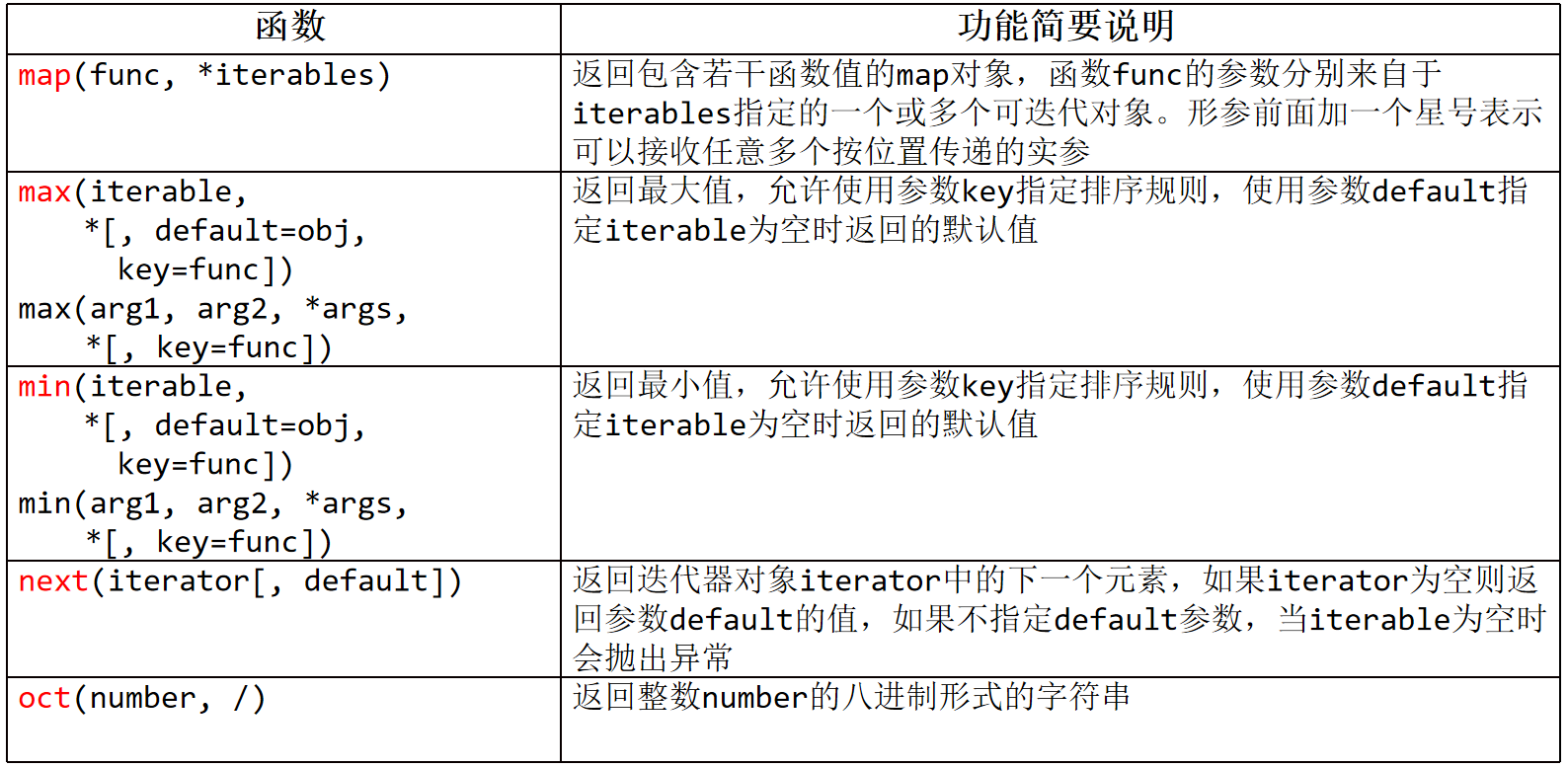
(3)oct(number,/)
返回整数number的8进制形式的字符串
print(oct(8)) # 0o10
print(oct(16)) # 0o20
print(oct(2)) # 0o2
3、字符编码转换
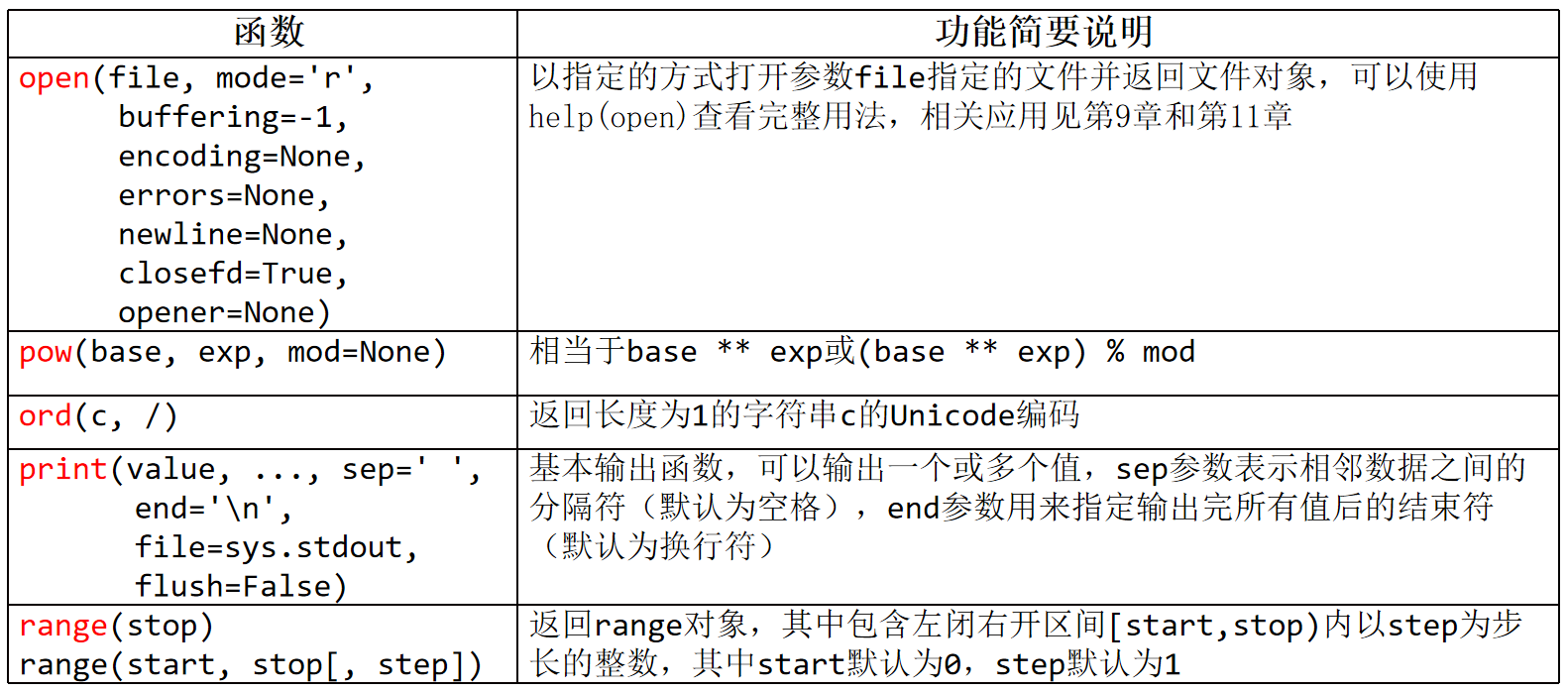
(1)ord(c,/)
返回字符串c的Unicode编码,c的长度为1,也就是一个字符
print(ord('刘')) # 21016
print(ord('a')) # 97
(2)chr(i,/)
返回Unicode编码为i的字符,(0<=0<-0x10ffff)(十进制1114111)
print(chr(21016))
print(chr(97))
print(chr(65))
print(chr(0x41))
print(chr(10)) # 换行符
输出结果:
刘
a
A
A
4、数据类型转换
(1)float(x=0,/)
把整数或字符串x转换为浮点数,不带参数时返回指数0.0
字符串x必须长得像浮点数或整数,比如像'数字'或'数字.数字'这样的字符串
print(float(10)) # 整数转为浮点数 10.0
print(float(1.23)) # 浮点数 1.23
print(float('1.23')) # 字符串转浮点数 1.23
print(float('123')) # 字符串转浮点数 123.0
print(float('10c')) # 报错 ValueError: could not convert string to float: '10c'
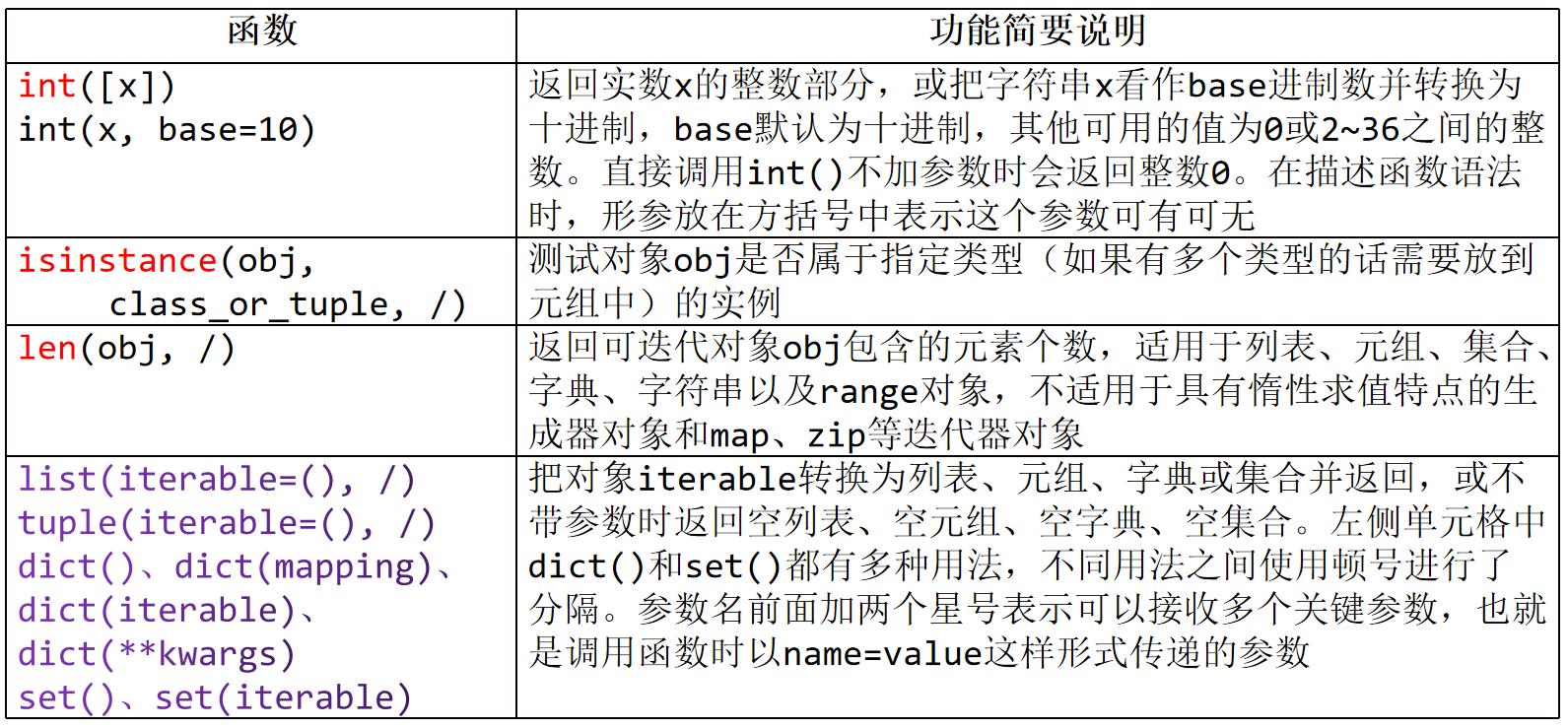
(2)int([x]) or int(x,base=10)
a、将数字或字符串转换为整数,字符串必须长得像整数,比如'数字'这种形式
print(int()) # 不带参数时返回整数0
print(int(10.123)) # 返回整数部分
print(int('123')) # 将字符串转换为整数
print(int('10.123')) # 报错 ValueError: invalid literal for int() with base 10: '10.123'
b、将x转换为十进制,用base指明x是几进制的数,
此时x的类型应为str | bytes | bytearray,base的值为0或2~36之间的整数
print(int('0xF',16)) # 将16进制转换为10进制
print(int('11',2)) # 将2进制转换为10进制
print(int('11',8)) # 将8进制转换为10进制
print(int('11',3)) # 将3进制转换为10进制
print(int(b'F',16)) # 将bytes的16进制转换位10进制
print(int(b'111',2)) # 将bytes的2进制转换位10进制
当base=0时,更具字符串的的前缀来判断字符串的进制,不是0b、0o、0x开头的就默认为10进制
print(int('0b111',base=0)) # 识别为2进制
print(int('0o10',base=0)) # 识别为8进制
print(int('0xA',base=0)) # 识别为16进制
print(int('123',base=0)) # 识别为10进制
print(int(b'0xA',base=0)) # 识别为16进制
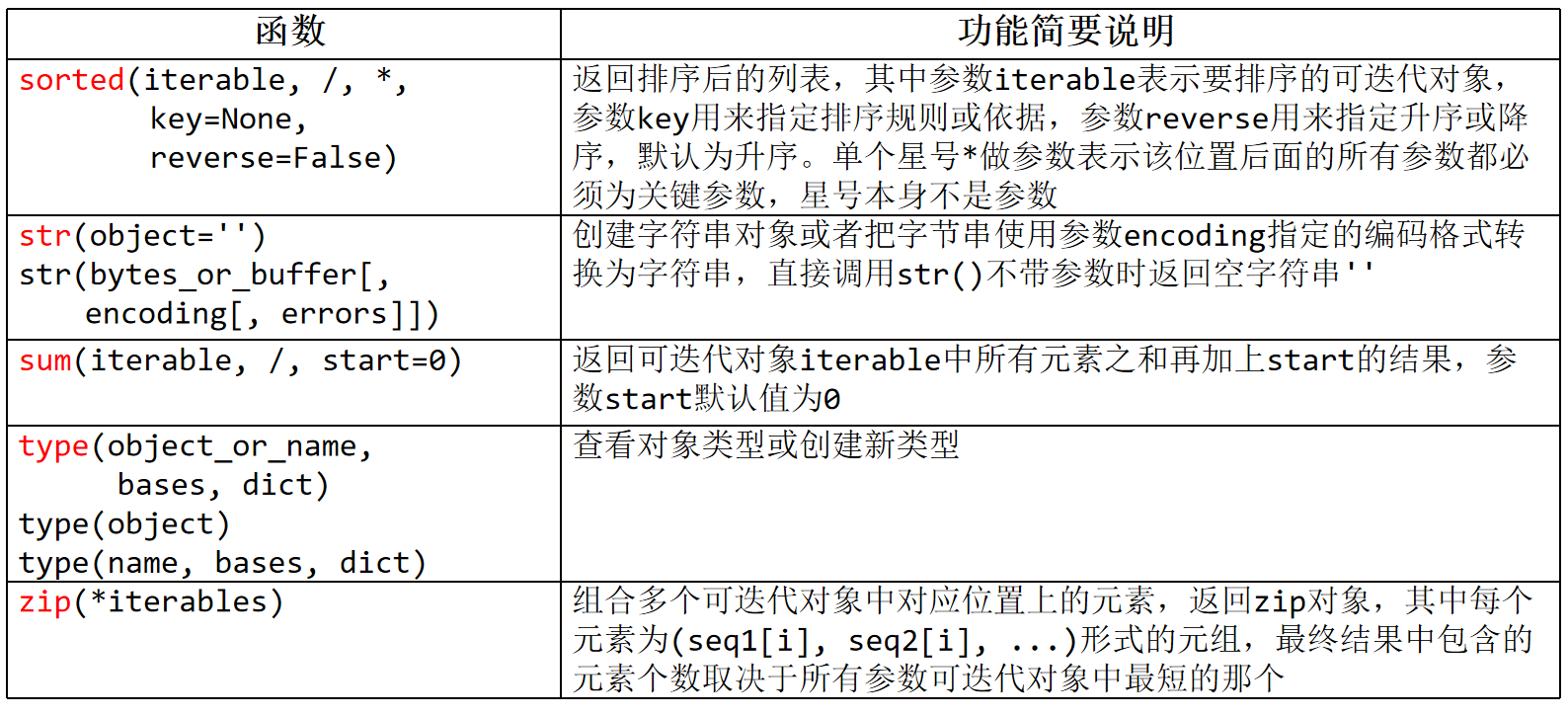
(3)str(object='') or str(bytes or buffer[,encoding[,errors]])
创建字符串对象或者把字节串使用参数encoding指定的编码格式转换为字符串,
直接调用str()不带参数时返回空字符串''
s1 = str() # 不带参数时返回空字符串
liu = bytes('刘','utf-8') # 将字符串用指定编码转换成字节串
print(liu) # b'\xe5\x88\x98'
s2 = str(liu,'utf-8') # 用指定编码将字节串转换为字符串
将其他类型转换为str
list_str = str([1,2,3]) # 将列表转换为字符串
tuple_str = str((1,2,3)) # 将元组转换为字符串
set_str = str({1,2,3,}) # 将集合转换为字符串
dict_str = str({1:[1,2]}) # 将字典转换为字符串
print(s1,type(s1)) # s1是空字符,打印时看不出来
print(s2,type(s2))
print(list_str,type(list_str))
print(tuple_str,type(tuple_str))
print(set_str,type(set_str))
print(dict_str,type(dict_str))
打印结果:
<class 'str'>
刘 <class 'str'>
[1, 2, 3] <class 'str'>
(1, 2, 3) <class 'str'>
{1, 2, 3} <class 'str'>
{1: [1, 2]} <class 'str'>
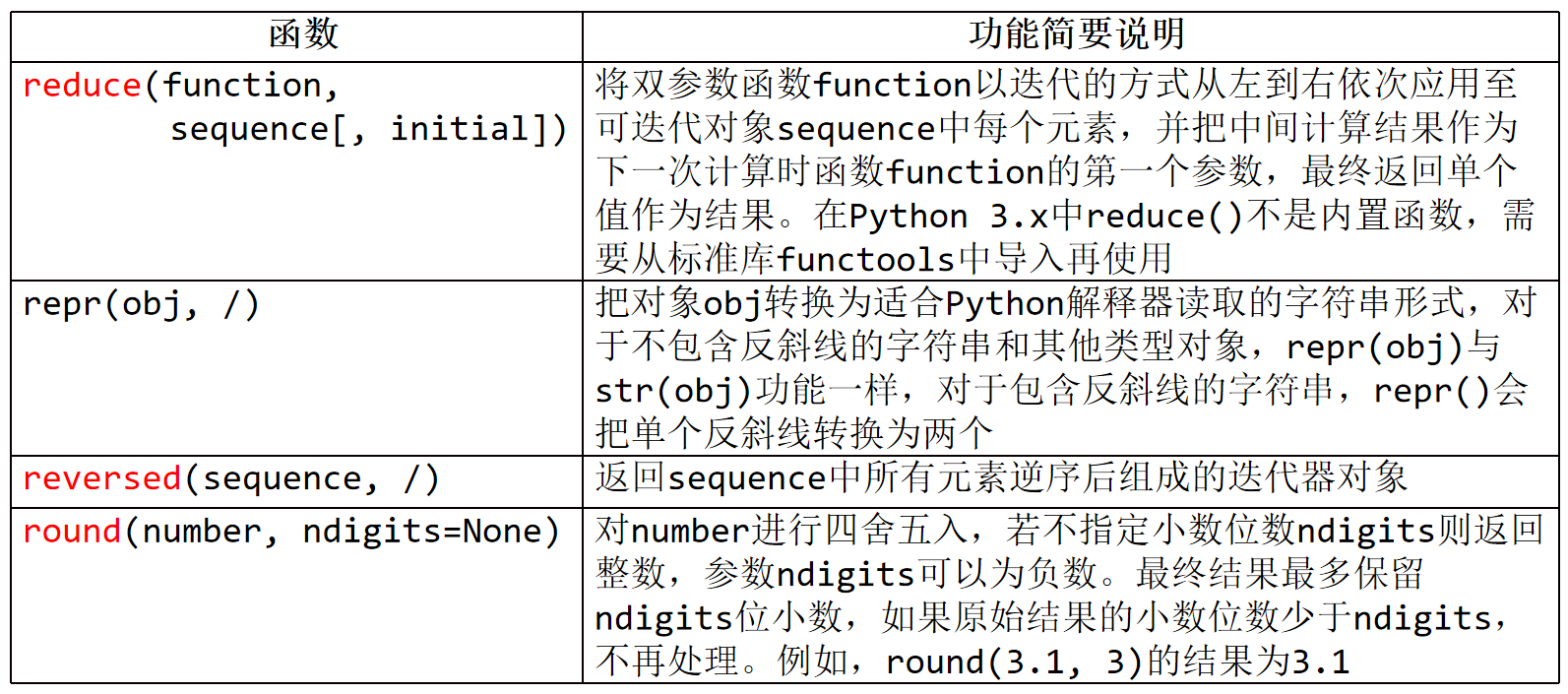
(4)repr(obj,/)
把对象obj转换为适合Python解释器读取的字符串形式,
对于不包含反斜线的字符串和其他类型对象,repr(obj)与str(obj)功能一样,
对于包含反斜线的字符串,repr()会把单个反斜线转换为两个
print(repr('Python实验\实验2-Python内置函数\实验2 Python内置函数.txt'))
print(str('Python实验\实验2-Python内置函数\实验2 Python内置函数.txt'))
输出结果:
'Python实验\\实验2-Python内置函数\\实验2 Python内置函数.txt'
Python实验\实验2-Python内置函数\实验2 Python内置函数.txt
(5)创建/转换为列表、元组、字典或集合
list(iterable=(),/)
tuple(iterable=())
dict()、dict(mapping)、dict(iterable)、dict(**kwargs)
set()、set(iterable)
把可迭代对象iterable转换为列表、元组、字典或集合并返回,
或不带参数时返回空列表、空元组、空字典、空集合。
参数名前面加两个星号表示可以接收多个关键参数,也就是调用函数时以name=value.这样形式传递的参数
print(list(range(5))) # 把可迭代对象转换成列表、元组、集合并返回
print(tuple(range(5)))
print(set(range(5)))
print(set([1,2,3]))
print(dict([(1,'noe'),(2,'two'),(3,'three')])) # 通过可迭代对象创建字典
print(dict(((1,'noe'),(2,'two')))) # 通过可迭代对象创建字典
print(dict(a=1,b=2,c=3)) # 通过关键字参数创建字典
print(dict({'a': 1, 'b': 2, 'c': 3})) # 通过映射创建字典
print(list(),tuple(),set(),dict()) # 不带参数时返回空列表、空元组、空集合、空字典。
输出结果:
[0, 1, 2, 3, 4]
(0, 1, 2, 3, 4)
{0, 1, 2, 3, 4}
{1, 2, 3}
{1: 'noe', 2: 'two', 3: 'three'}
{1: 'noe', 2: 'two'}
{'a': 1, 'b': 2, 'c': 3}
{'a': 1, 'b': 2, 'c': 3}
[] () set() {}
三、计算
1、abs(x,/)
返回数字x的绝对值或复数x的模
print(abs(-6)) # 6
print(abs(3 + 4j)) # 5
2、complex(real=0,imag=0)
返回复数,其中real是实部,imag是虚部。参数real和image的默认值为0
调用函数时如果不传递参数,会使用默认值。例如,complex()返回j,
comp1e×(3)返回(3+0j),complex(imag=4)返回4j
a=complex()
b=complex(3.4)
c=complex(3,4)
print(a,b,c) # 0j (3.4+0j) (3+4j)
3、divmod(x,y,/)
计算整商和余数,返回元组(x//y,x%y)
print(divmod(5,2)) # (2, 1)
print(divmod(5,9)) # (0, 5)
4、pow(base,exp,mod=None)
幂运算,相当于baseexp或(baseexp)%mod
print(pow(2,3)) # 2**3==8
print(pow(2,3,3)) # (2**3)%3
5、round(number,ndigits=None)
对number进行四舍五入,若不指定小数位数ndigits则返回整数,参数ndigits可以为负数。
最终结果最多保留ndigits位小数,如果原始结果的小数位数少于ndigits,不再处理。
print(round(3.96,)) # 不指定ndigits参数时返回整数(也是四舍五入)
print(round(3.14,1)) # 保留一位小数
print(round(1.78,1)) # 四舍五入
print(round(3.14,3)) # 原始结果的小数位数少于ndigits,不再处理
print(round(183.14,-1)) # 用负数进行舍入
print(round(183.14,-2)) # 用负数进行舍入
输出结果:
4
3.1
1.8
3.14
180.0
200.0
6、sum(iterable,/start=0)
返回可迭代对象iterable中所有元素之和再加上start的结果,参数start默认值为0
print(sum([1, 2, 3, 4, 5])) # 15
print(sum((1, 2, 3, 4, 5),start=100)) # 115
7、eval(source,globals=None,locals=None,/)
计算并返回字符串source中表达式的值,参数globals和loca1s用来指定字符串source中变量的值(,
如果二者有冲突,以1oca1s为准。如果参数globals和1 ocals都没有指定,
就按局部作用域、闭包作用域、全局作用域、内置命名空间的顺序搜索字符串source中的变量并进行替换,
如果找不到变量就抛出异常NameError提示变量没有定义
(1)字符串表达式求值
a = eval('1+2+3+4')
b = eval('3**3')
c = eval('5/2')
d = eval('6%3')
print(a,b,c,d) # 10 27 2.5 0
e = eval('666') # 效果类似于将字符串转换为数字,但它可以判断字符串是int还是float类型,然后返回对应类型的值
f = eval('6.66')
print(e,f,type(e),type(f)) # 666 6.66 <class 'int'> <class 'float'>
(2)字符串表达式中使用变量名
位置参数globals和locals需要是映射类型(比如字典),globals必须是字典。globals和locals默认为当前全局变量和局部变量
这两个参数一般不指定,使用如果参数形式是字典时,key必须是str,value可以是任何东西
x,y,z = 1,2,3
g = eval('x+y+z') # 不指定
h = eval('x+y+z',{'x':10,'y':20,'z':30}) # 这里的修改并不会更改局部或全局变量的值
i = eval('x+y+z',globals()) # globals()返回的是一个字典,key为全局变量名,value为对应变量的值
j = eval('i-j',{'i':x,'j':y,'z':66}) # 可以把globals和locals参数当做是将字符串中的字符替换的作用
k = eval('i+j',{'i':'abc','j':'def'})
l = eval('x+y',{'x':x,'y':y},{'x':100}) # 两参数冲突时,以locals为准
print(f'g={g},h={h},i={i},j={j},k={k},l={l}') # g=6,h=60,i=6,j=-1,k=abcdef,l=102
8、hash(obj)
返回给定对象的哈希值。两个比较相等的对象也必须具有相同的哈希值,但反过来则不一定正确。
如果对象不可哈希,则会报错,一般用于判断对象是否可哈希。
print(hash(123))
print(hash(True)) # True==1,所以哈希值相同
print(hash(1))
print(hash(4567823484))
print(hash((4567823484,7854612))) # 计算元组的哈希值
print(hash([1,2,3])) # 报错,列表不可哈希
可变与不可变
不可变类型(可哈希):int整型、float浮点型、bool布尔型、str字符串、tuple元组
不可变类型的特点是一旦创建,就无法再次修改,只能通过重新创建对象来改变其值。
可变类型(不可哈希):list列表、dict字典、set集合
可变类型的特点是可以对其进行增删改操作,即可以修改已经存在的对象。
注意:所有不可变类型在被修改时都会创建一个新的对象,并将变量名指向新对象。而原先的那个变量仍然还在内存中。
例如:
不可变类型
s1 = 'abc'
s2 = s1 # 相当于让s2也指向'abc'
print(id(s1),id(s2)) # 两者id(内存地址)相同
s1 = 'def' # 创建一个新对象,并让s1指向它
print(s1,s2) # 原来的对象'abc'并没有被修改。 def abc
print(id(s1),id(s2)) # id不同了
可变类型
l1 = [1,2,3]
l2 =l1 # l1和l2同时指向[1,2,3]
del l2[0] # 删除l2中的第0个元素
print(l1,l2) # l1和l2中的第0个元素都被删除了
print(id(l1),id(l2)) # 两者id仍然相同
9、len(obj,/)
返回可迭代对象obj包含的元素个数,适用于列表、元组、集合、字典、字符串以及range对象,
不适用于具有惰性求值特点的生成器对象和map、zip等迭代器对象
print(len([1, 2, [3, 4]])) # 3
print(len(range(10))) # 10
print(len({1,2,3,4,5,5,5})) # 5
10、reduce(function,sequence[,initial])
将双参数函数function以迭代的方式从左到右衣次应用至可迭代对象sequence中每个元素,
并把中间计算结果作为下一次计算时函数Function的第一个参数,最终返回单个值作为结果。
在Python3.x中reduce()不是内置函数,需要从标准库functools中导入再使用.
reduce()的参数:
function:用于累积操作的二元函数,它接受两个参数,其中第一个参数是上一次累积操作的结果,第二个参数是当前迭代的元素值。
iterable:一个可迭代对象,用于提供要累积的元素。
initializer(可选):用于初始化累积结果的可选参数。
reduce() 函数的工作过程如下所示:
1、reduce() 函数将可迭代对象中的第一个和第二个元素作为参数传递给指定的二元函数,并计算它们的结果。
2、reduce() 函数将上一步计算出的结果和可迭代对象中的第三个元素作为参数传递给指定的二元函数,并计算它们的结果。
3、重复上述过程,直到迭代完所有元素。最终的结果即为所有元素的累积结果。
from functools import reduce
计算1+2+3+4+5+6+7+8的值
print(reduce(lambda x, y: x + y, [1, 2, 3, 4, 5])) # 15
四、处理
1、enumerate(iterable,start=0)
枚举可迭代对象iterable中的元素,返回包含元素形式为(start,iterable[]),
(start+1,iterable[1]),(start+2,iterable[21)...的迭代器对象,start表示编号的起始值,默认为0
abc = enumerate(['a', 'b', 'c'], 1) # 返回enumerate的迭代器对象
print(list(abc),type(abc)) # [(1, 'a'), (2, 'b'), (3, 'c')] <class 'enumerate'>
2、filter(function or None,iterable)
使用function函数描述的规则对iterable中的元素进行过滤,返回filter对象,
其中包含序列iterable中使得函数Function返回值等价于True的那些元素,
第一个参数为None时返回的filter对象中包含iterable中所有等价于True的元素
fil1 = filter(None, [0, 1, 3, True, False, [], (1,)]) # 第一个参数为None
print(fil1, list(fil1)) # 返回迭代器中值等价于True的元素
fil2 = filter(lambda item: type(item) is int, [0, 1, 3, True, False, [], (1,)]) # 返回int类型的元素
fil3 = filter(lambda item: item>2, [0, 1, 3, True, False,]) # 返回大于2的元素
print(list(fil2),list(fil3)) # [0, 1, 3] [3]
注意:False0,True1
3、format(args)
string.format(args) 其中,string 是待格式化的字符串,args 是一个或多个待填充到字符串中的值
a='my name is {},my age is {}.'.format('我呀',18) # 按位置传
print(a)
b='my name is {0}{0}{0},my age is {1}{1}{1}{0}{0}.'.format('我呀',18) # 按位置索引
print(b)
c='my name is {}{name}{name},my age is {age}{age}.'.format(123,name='我呀',age=18) # key=value
print(c)
d='{}{}{name}{age}'.format(123,456,name='我呀',age=18) # 混用
print(d)
e='10/3={:.1f},5/2={num},5/2={num:.2f}'.format(3.3333,num=2.5) # 指定精度
print(e)
打印结果:
my name is 我呀,my age is 18.
my name is 我呀我呀我呀,my age is 181818我呀我呀.
my name is 123我呀我呀,my age is 1818.
123456我呀18
10/3=3.3,5/2=2.5,5/2=2.50
格式化填充 {索引/key : 填充符号^><长度} # 长度不足时才采用填充符号填充
g='{0:*^8},,,{2:!>9}{1:#<7},{3:#<2}'.format('one','two','three','four') # ^两边,>左填,<右填
print(g)
h = '{name:=^10}'.format(name='我呀') # key=value
print(h)
打印结果:
**one***,,,!!!!threetwo####,four
====我呀====
4、map(func,*iterables)
返回包含若干函数值的map对象,函数func的参数分别来自于iterables指定的一个或多个可迭代对象。
形参前面加一个星号表示可以接收任意多个按位置传递的实参,可迭代对象有多个时,以长度最短的为准
a = map(lambda item: item + '娃哈哈', ['noe', 'two', 'three'])
print(list(a)) # ['noe娃哈哈', 'two娃哈哈', 'three娃哈哈']
b = map(lambda x,y:x+y,range(10),range(5)) # func接收多个参数,以长度短的为准(range(5))
print(list(b)) # [0, 2, 4, 6, 8]
上面的匿名函数lambda x,y:x+y等价于
def func(x,y):
return x+y
5、max() and min()
max(),返回最大值,允许使用参数key指定排序规则,使用参数default指定iterable为空时返回的默认值
max(iterable,*[default=obj,key=func])
max(arg1,arg2,*args,*[key=func])
min(),返回最小值,与max()类似
min(iterable,*[default=obj,key=func])
min(arg1,arg2,*args,*[key=func])
print(max([1, 2, 3, 4, 5]))
print(max([],default='对象为空'))
print(max(['apple','banana','orange',])) # 用字符串的比较规则进行比较
print(max(['apple','bananas','orange'],key=len)) # 以长度作为比较的依据,比较出最长的元素。
print(max(1,2,3,4,5.5,5,6,6.6))
print(max([1,2,3],[4,5])) # 比较的是列表中的对应的元素
print(max((1,2,3),(0,5,6),(-1,66)))
输出结果:
5
对象为空
orange
bananas
6.6
[4, 5]
(1, 2, 3)
6、next(iterator[,default])
返回迭代器对象iterator中的下一个元素,如果iterator为空则返回参数default的值,
如果不指定default参数,当iterable为空时会抛出异常
l = [1,2,3,4,5,6,[7,8]]
iterator1 = l.__iter__() # __iter__()方法将可迭代对象生成迭代器,__ietr__()与iter()是等价的
print(next(iterator1))
print(iterator1.__next__()) # __next__()与next()是等价的
print(next(iterator1))
while True:
try:
print(iterator1.__next__())
except StopIteration: # 捕捉到StopIteration异常后执行下面缩进的代码
print('停止迭代StopIteration')
break
输出结果:
1
2
3
4
5
6
[7, 8]
停止迭代StopIteration
7、reversed(sequence,/)
返回sequence中所有元素逆序后组成的迭代器对象
a = reversed([1,2,3,4,5,6])
b = reversed((1,2,3,4,5,6))
print(list(a),list(b))
输出:[6, 5, 4, 3, 2, 1] [6, 5, 4, 3, 2, 1]
8、sorted(iterable, *, key=None, reverse=False)
返回一个新的排序后的列表,不会修改原始的可迭代对象。
参数:
iterable 表示要排序的可迭代对象,
key 是一个用于指定排序规则的函数,
reverse 是一个布尔值,表示是否要对结果进行反向排序,默认为 False。
fruits = ['banana', 'apple', 'orange', 'pear']
sorted_fruits = sorted(fruits) # 默认为从正向(从小到大)排序
print(sorted_fruits) # 输出:['apple', 'banana', 'orange', 'pear']
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_numbers = sorted(numbers, reverse=True) # 反向排序
print(sorted_numbers) # 输出:[9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
words = ['cat', 'dog', 'elephant', 'giraffe', 'ant']
sorted_words = sorted(words, key=len) # 以长度来排序
print(sorted_words) # 输出:['cat', 'dog', 'ant', 'giraffe', 'elephant']
9、zip(*iterables)
组合多个可迭代对象中对应位置上的元素,返回zip对象,
其中每个元素为(seq1[i],seq2[i],...)形式的元组,
最终结果中包含的元素个数取决于所有可迭代对象参数中最短的那个
a = zip(range(1,6), ['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight'])
print(list(a)) # 结果取决于最短的那个
结果:[(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four'), (5, 'five')]
b = zip(range(1,6), ['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight'],('一','二','三'))
print(list(b))
# 结果:[(1, 'one', '一'), (2, 'two', '二'), (3, 'three', '三')]
五、其他
1、globals()
返回当前作用域中所有全局变量与其值所组成的字典,只包含在globals()执行前就已经存在的变量
print(globals()) # 例如{'__name__':'__main__'}
globals()['a']=123 # 改变globals()字典时,会影响到全局名称空间的名称查找
print(globals()) # 字典中增加了'a':123
print(a) # 因为在globals()字典中添加了名称a,所以能够找到a这个变量。
2、locals()
返回当前作用域中所有局部变量与其值所组成的字典(与globals类似)
print(locals()) # 因为当前作用于就是全局,所以结果与globals()一样
def func():
a=666
print(globals()) # 返回的是全局的变量,与外面的globals()一样
print(locals()) # 局部作用域(func函数内)只有变量a。结果为{'a': 666}
func()
3、help(obj)
查看对象的帮助信息
print(help(input))
不加入参数时进入交互式回话,按q退出(输入q,然后回车),
交互式会话大概就是在help>提示符后输入对象名称,就会输出其帮助信息
help()
4、id(obj,/)
返回对象的内存地址
a = 123
print(id(a)) # print是以十进制输出的 1338396053552
5、input(prompt=None,/)
输出prompt的内容作为提示信息,接受键盘输入的内容,并以字符串的形式返回。
password = input('请输入你的密码:')
print(password,type(password)) # 123 <class 'str'>
6、print(value1,value2,...,sep=' ',end='\n')
基本输出函数,可以输出一个或多个值,
sep参数表示相邻数据之间的分隔符(默认为空格),end参数用来指定输出完所有值后的结束符(默认为换行符)
sep和end的类型都只能是str或None
print([1,2,3],'abc',sep='娃哈哈',end='结束') # [1, 2, 3]娃哈哈abc结束
7、open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
其中,各参数的含义如下:
file:要打开的文件名(包括路径)。可以是一个字符串或一个 bytes 对象(Python 3.x)。
mode:打开文件时的模式,常用的为 'r'(只读,默认值)、'w'(写入)、'a'(追加)、'x'(排它,创建一个新文件并写入)等。另外,还可以通过添加 'b'、't' 或 '+' 来指定文件是否以二进制模式打开、是否以文本模式打开以及是否同时支持读写等操作。
buffering:缓存大小,用于控制文件 I/O 的缓冲行为。当 buffering 等于 0(默认值)时,表示不缓冲;当为 1 时,表示使用默认缓冲方式(通常为全缓冲);当为正整数时,表示缓冲区大小(单位为字节);当为负数时,表示按照系统缓冲方式处理(通常为行缓冲)。
encoding:用于解码或编码文件内容的字符集。文件以文本模式打开时,该参数默认为 None,表示使用系统默认编码;文件以二进制模式打开时,该参数不起作用。
errors:指定编解码时的错误处理方式,常用的有 'strict'(默认值,表示遇到非法字符时抛出异常)、'ignore'(忽略非法字符)、'replace'(用 ? 取代非法字符)等。
newline:表示写入文件时的换行符,常用的有 '\n'(Unix/Linux)、'\r\n'(Windows)等。
closefd:当 open() 函数的 file 参数为一个整数类型的文件描述符(即通过 os.open() 等函数获得的)时,该参数确定是否在调用 close() 时同时关闭该文件。
opener:一个 Python 函数,用于打开文件时使用自定义的方法(一般很少用到,可以忽略)。
open()函数的返回值是一个文件对象,可以通过该对象进行文件的读写操作。
open()函数长与with语句一同使用,with用于自动关闭文件
with open(r'实验2 Python内置函数.txt',mode='rt',encoding='utf-8')as f: # as的作用是将open()的返回值赋值给f
res = f.read() # 一次性读取文件的所有内容并赋值给res
print(res)
8、range(start,stop[,step])
用于生成一系列连续的整数,返回range对象
star,stop,step分别为开始,结束,步长
左闭右开区间,顾头不顾尾,stop的值取不到。
print(list(range(10))) # 0到9的整数
print(list(range(0,10))) # 与range(10)等价
print(list(range(0,11,2))) # 0到11之间的偶数(不包含11)
print(list(range(10,0,-1))) # 10到0的整数(不包含0)
输出结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 2, 4, 6, 8, 10]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
9、type(obj)
(1)返回obj对象的类型
print(type([1, 2, 3])) # <class 'list'>
print(type({1:'one'})) # <class 'dict'>
(2)创建新的类型
使用 type() 函数定义了一个名为 MyClass 的新类。
第一个参数指定了类名,第二个参数是一个元组,包含基类的类型对象,第三个参数是一个字典,包含类的成员变量和方法。
在这个例子中,我们定义了一个名为 x 的成员变量,其值为 42。
MyClass = type("MyClass", (object,), {"x": 42})
上面的代码等价于:
class MyClass(object): # 用这种方式更好一些
x = 42