〇、目标检测
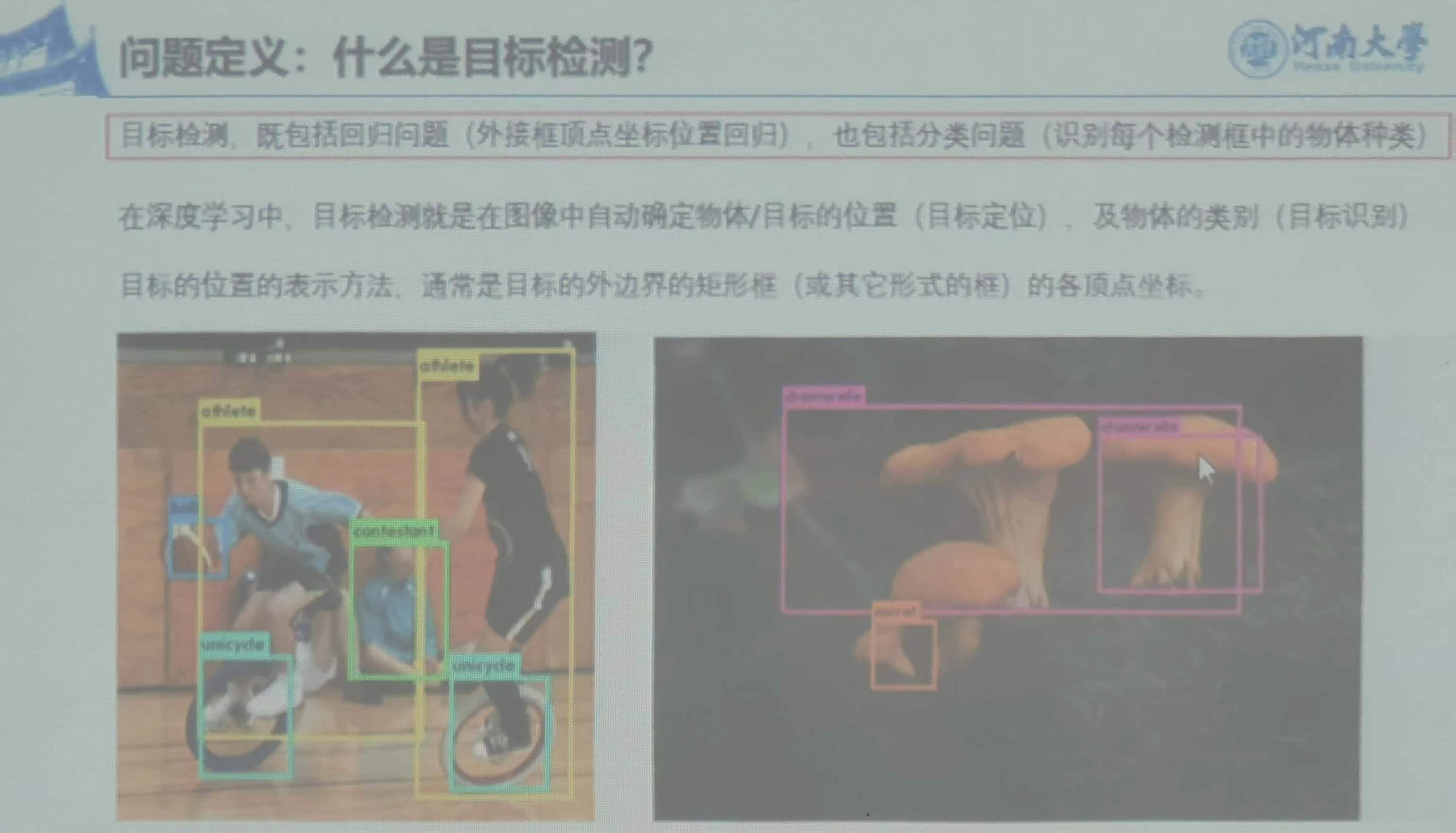
1、定义:既包括回归问题(外接框顶点坐标回归也包括分类问题(识别每个检测框中的物体种类)
在深度学习中,目标检测就是在图像中自动生成确定物体/目标位置(定位目标),
及物体类别(目标识别)目标的位置的表示方法,
通常是目标的外边界的矩形框(或其他形式的框)的各项顶点。
2、基于深度学习的目标检测算法归类
1)第一类:两阶段方法
Ⅰ:先想办法产生候选区域建议框
Ⅱ:在对建议框进行判别遴选&分类
举例:R-CNN系列,含R-CNN、Faster R-CNN、Mask R-CNN、Cascade R-CNN等方法;
2)第二类:单阶段方法
典型代表是YOLO系列算法、SSD算法、Anchor-free等方法。

一、R-CNN算法
1、主要思想
1)区域建议框:由传统方法离线生成(SS),这是输入数据的来源
2)目标分类:检测框(区域建议框)内的物体识别问题,使用VGG、ResNet等卷积神经网络分类,
将每个建议框中物体图像及类别(含背景类),resize到统一尺寸,送入CNN中训练分类模型

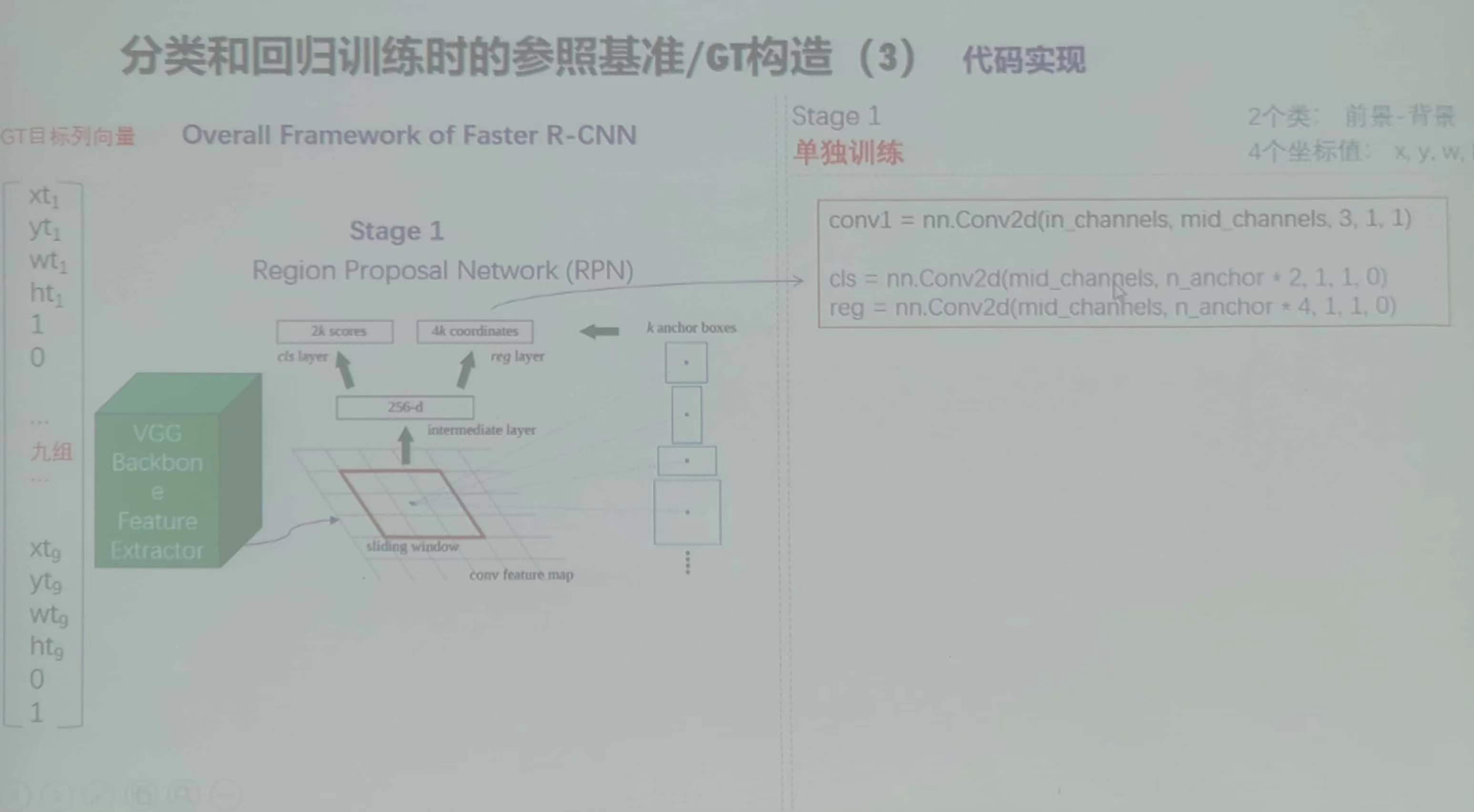
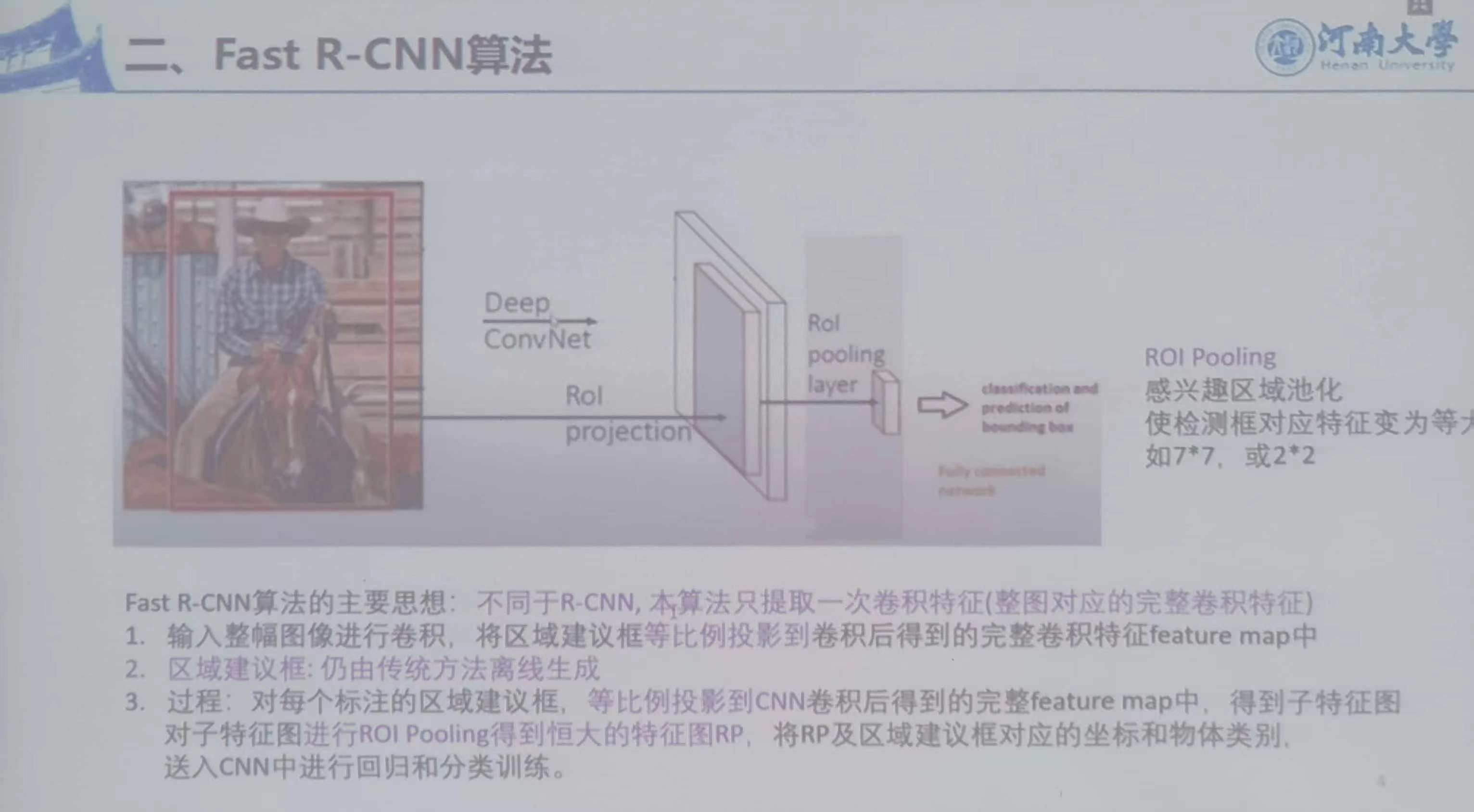
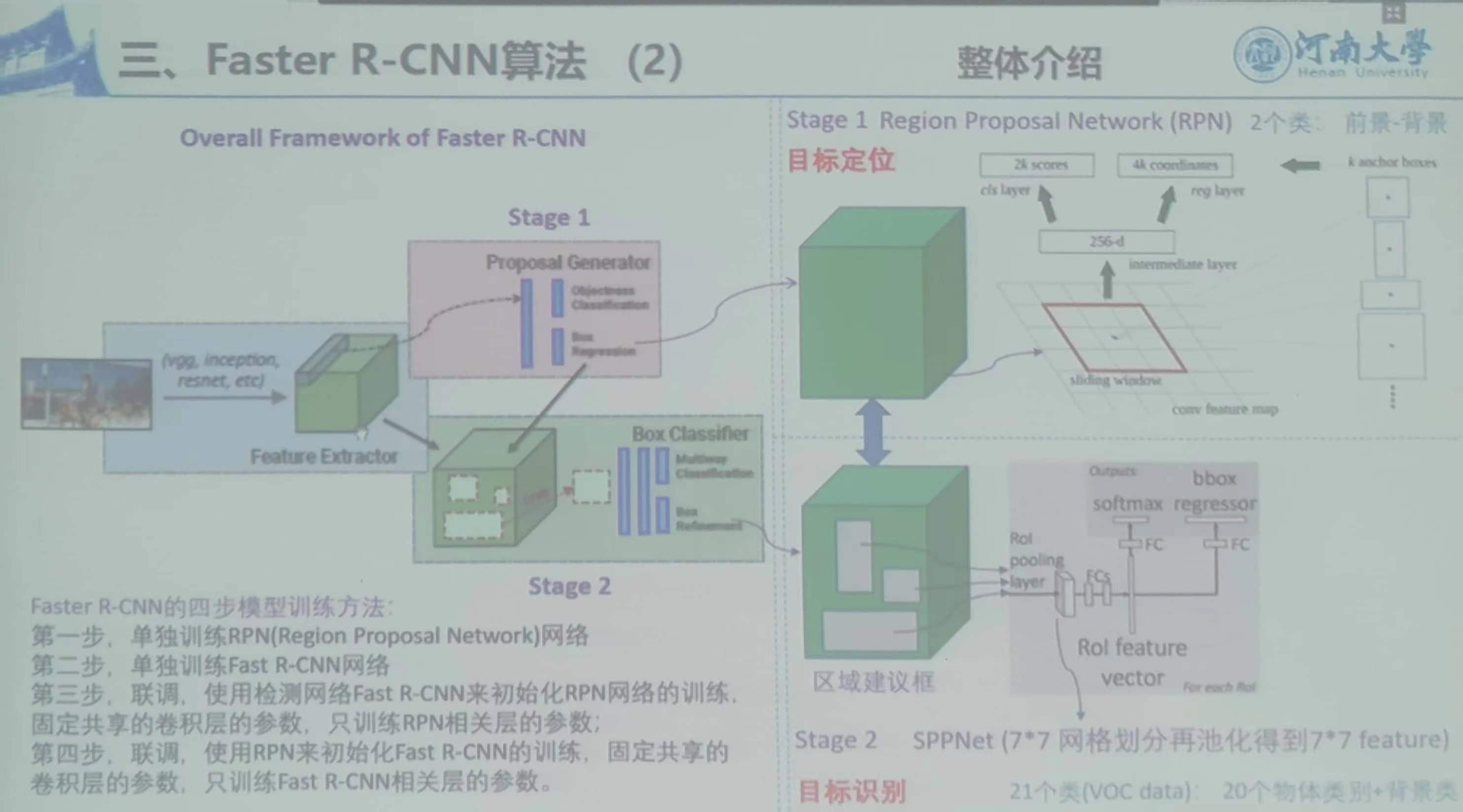
二、Faster R-CNN算法
1、主要思想
不同于R-CNN,本算法只提取一次卷积特征(整图对应的完整卷积特征)
2、简述
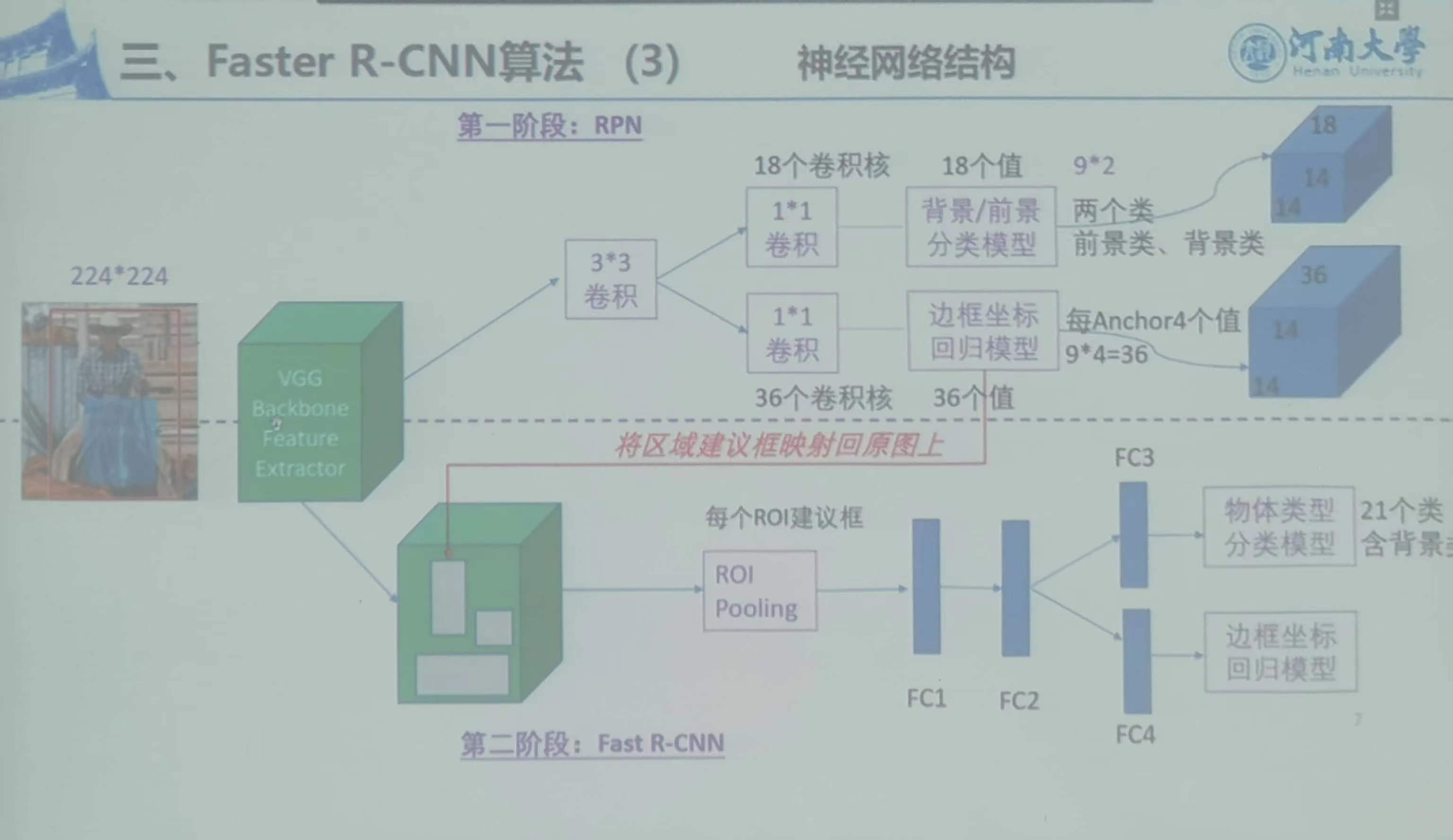
1)输入整幅图进行卷积,将区域建议框等比例投影到卷积后得到完整卷积特征feature map中
2)区域建议框:仍由传统方法离线生成
3)过程:对于每个标注的区域建议框,等比例投影到CNN卷积后得到的完整feature map中,得到子特征图,
对子特征图进行ROI Pooling得到恒大的特征图RP,将RP及区域建议框对应的坐标和物体类别送入CNN中进行回归和分类训练。
4)整体介绍
5)神经网络结构
6)数据准备

7)锚框设置

8)偏移量学习设置

9)主要损失函数

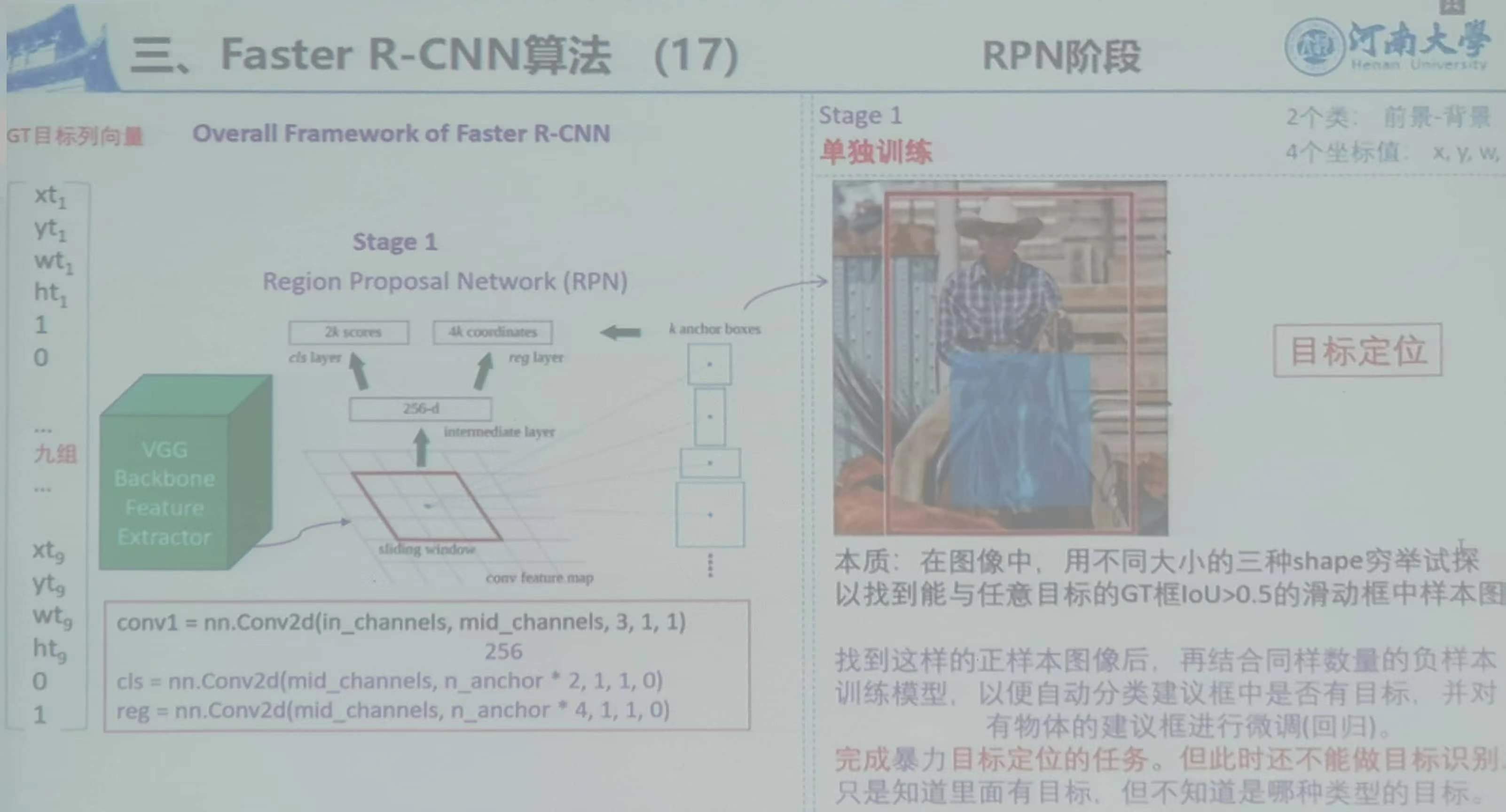
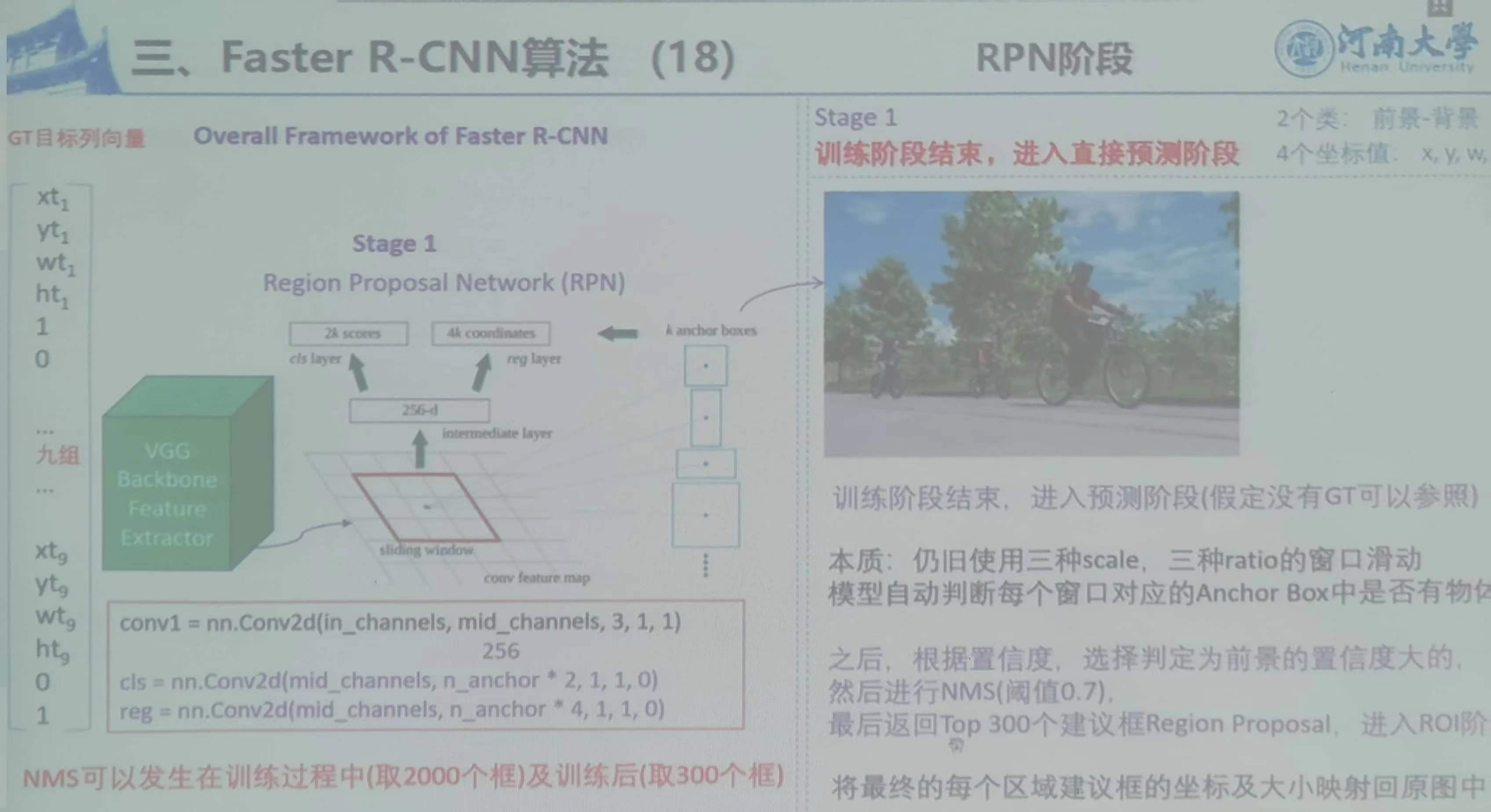
10)RPN阶段


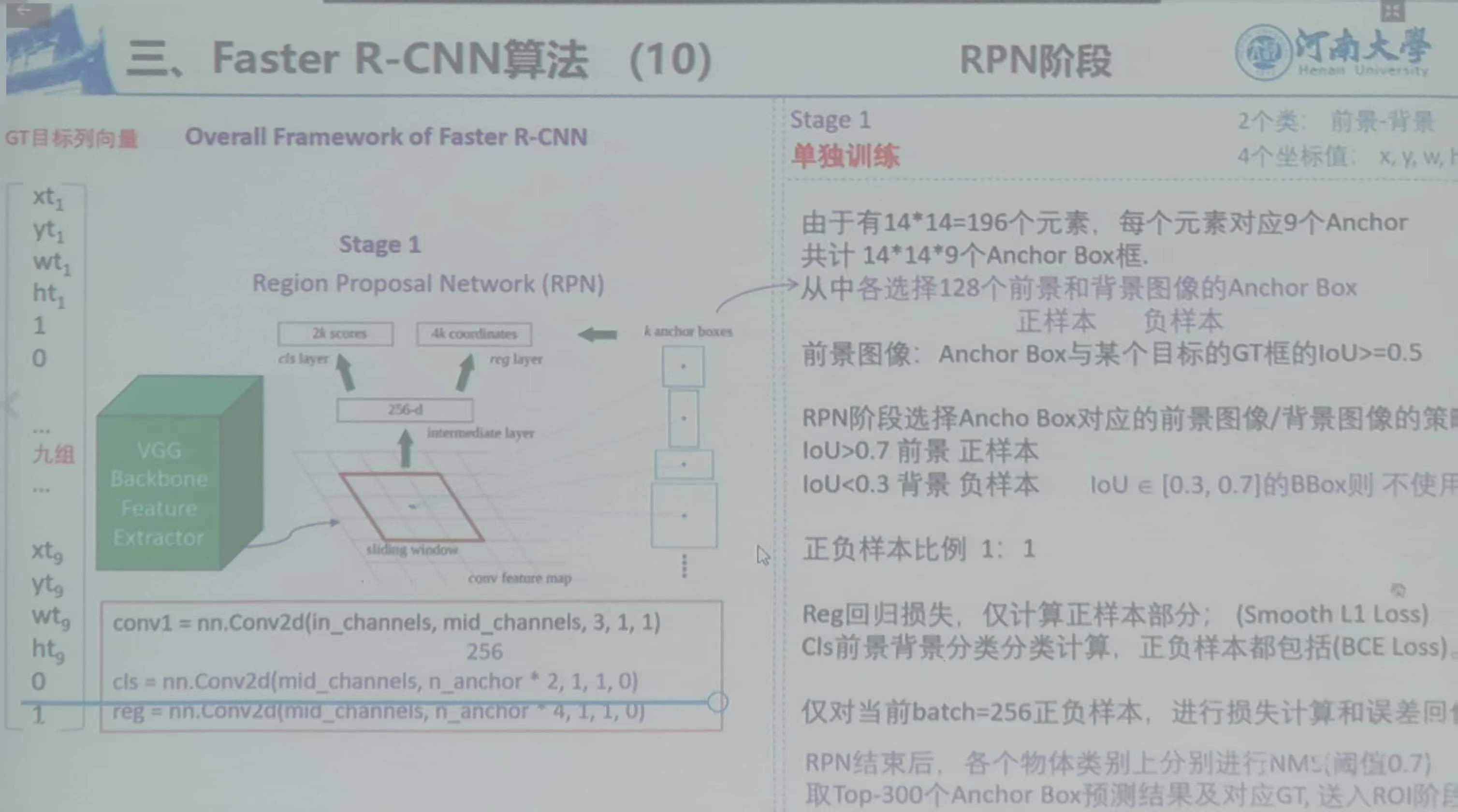


3、GT目标列向量
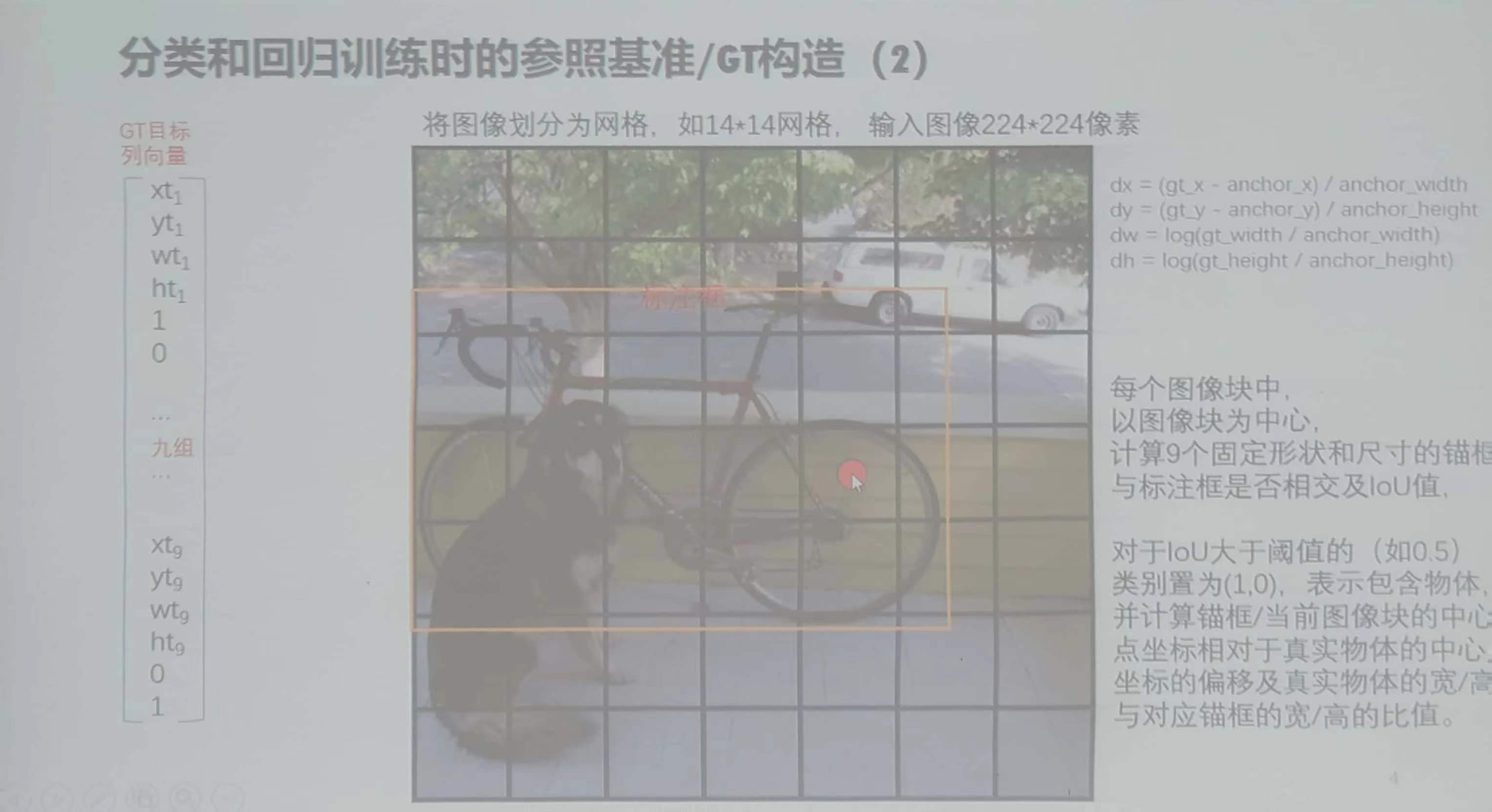
GT目标列向量(提前算出):有真实的标注,将原图卷积池化后,将原先的标注等比例缩放映射到操作后的图(或原图,此时不用等比缩放),得到标注框。
之后划分块,在每一个块的中心发散出来9种锚框,锚框与标注框是有差别的,故可以算出具体的差异,或是否有交集,一般用比例。
eg:14*14个图像块,每一个块的中心,由此中心衍生出来的九种锚框与标注框进行交集,算比例,大于时为10,无交集的直接置为01,其他数值随即设置。