前面介绍了单目标关键点检测网络 Stacked Hourglass Networks,如下图所示,一次只能检测出一个目标的关键点信息,但实际情况下一个场景出现多个目标的概率更大,所以原作者在Stacked Hourglass Networks的基础上提出了Associative Embedding,用于处理多目标关键点的配对问题。

Paper: https://arxiv.org/abs/1611.05424v2
Code: https://github.com/princeton-vl/pose-ae-train
一、Associative Embedding介绍
1.1 大体思想

在单目标关键点检测中提到每一个类型的关键点输出都是一张特征图,然后通过查找这个特征图中最大值所在位置作为关键点坐标,如果有多个目标那相应的一张特征图里面就有多个同类型的关键点,那就要实现一张图中多个关键点的分组,进而确定出关键点属于哪个目标,也就是要找到关键点和目标之间要有个对应关系,这个关系满足属于目标的关键点其相关度较高,不属于的相关度较低这个条件。作者采用的办法是对每一个输出的特征图都输出相同维度大小的编码值,通过训练使得这个编码值满足前面提到的条件,那就可以进行配对了。
1.2 网络结构
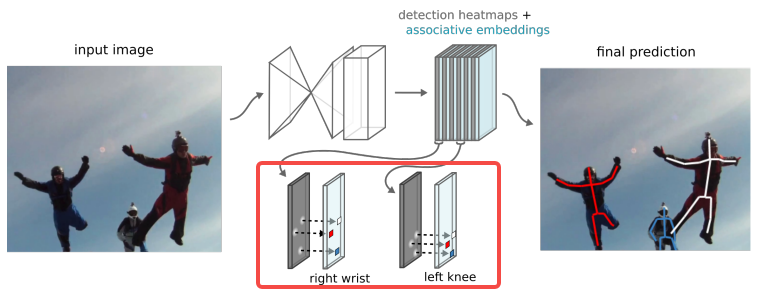
从上图可以看出Associative Embedding在Stacked Hourglass Networks的基础上改变了输出值,每一个类型的关键点对应一个特征图的同时还有一个和特征图相同维度大小的编码信息。
1.3 损失函数
现在问题变成了如何训练可以使得这个编码值满足属于目标的关键点其相关度较高,不属于的相关度较低这个条件呢,论文中给出的损失函数如下:

要使得损失函数变小,那就是尽可能得减少同目标间关键点差异(红色),同时尽可能的增大不同目标间的关键点的差异(黄色),这样训练分组损失就满足最小化类内距离和最大化类间距离,也就满足了编码值所需要的条件。
二、配对细节
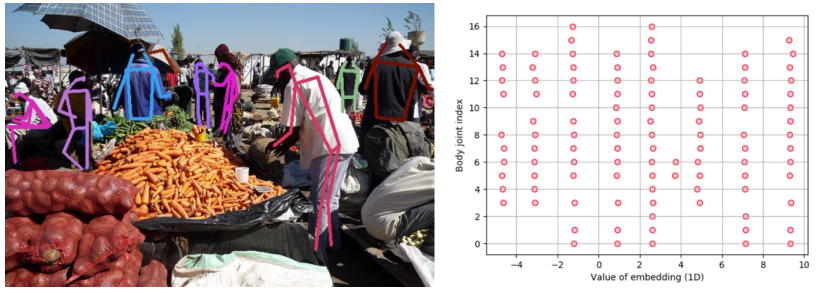
实现可以参考https://github.com/princeton-vl/pose-ae-train/blob/master/utils/group.py,里面主要涉及到一个加速配对的过程、匹配优先级以及二分图匹配Munkres算法。
2.1 加速配对
正常是对每个关键点都与其他关键点进行配对,为了节省计算时间,配对时每个人的所有关键点的编码值通过取平均得到一个参考编码值,避免了每一对关键点之间都进行计算。不同人之间只需要计算参考值之间的距离即可。
2.2 优先级
后续匹配采用优先级规则,从头部==>向四周延伸
- 头部采用非极大值抑制后满足阈值条件的情况下筛选出初始人员
- 后续关节依据头部采用匹配的规则进行分配,直到所有节点都分配到了某个人(匹配参考标签距离以及预测分数)
2.3 Munkres配对
Munkres算法(前面一篇文章已经详细介绍了,感兴趣的可以跳过去看一下)。这里将编码值之间的差异作为Munkres算法里面提到的系数矩阵。
2.4 具体步骤
这里以17个关键点为例,
- 得到B *17 * H * W的特征图和B * 17 * H * W的tag,每张特征图可能有不同人的关节点
- 采用最大池化(3*3,pad=1, stride=1)对特征图进行NMS操作
- 依据外部给定最多的个数(人数)挑选出某一特征图前k个最大值,得到其值及对应的索引值
- 依据索引值,找到相应位置的tag值
- 特征值作为预测分数,按照给定特征图处理顺序,先处理排在第一位的特征图,经过阈值处理后得到一定数量的特征点,计算出位置x,y在结合特征值val和tag,存入字典(key为tag值,value为一个Num_people * Num_Joint的数组)
- 对后续特征图进行同样处理,不同的是先计算字典中每组tag值的平均值(减少计算量),然后借助Munkres算法进行最小匹配(匹配依据当前特征图tag值和平均值的差值),匹配后得到对应的索引进行匹配
- 如果diff值超出给定阈值,则字典添加新的值,否则依据索引在相应位置修改为最新的(x,y, val, tag)
- 处理完后得到最终的字典即为结果