python爬虫实战-小说爬取
基于requests模块与lxml模块编写的爬虫,目标小说网站为 https://www.hongxiu.com/category/
基本思路
- 主要内容分为三个部分
- 使用requests模块获取网页内容
- 使用lxml模块进行网页解析
- 将解析出来的数据存储进MySQL数据库中
-
获取网页内容
-
网站分析
获取各个分类的href标签
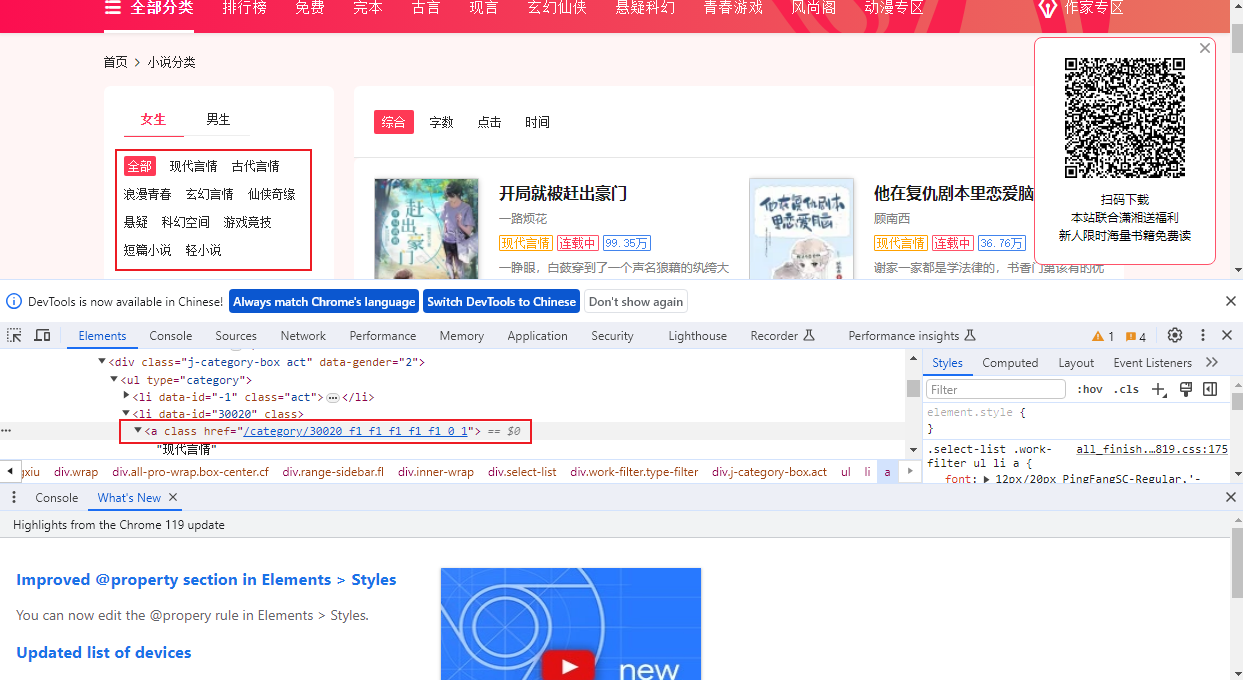
-
代码如下
def novel_sort_link(self): novel_website = requests.get(self.url).text # print(novel_website) novel_classification_link = etree.HTML(novel_website) novel_classification = novel_classification_link.xpath( '/html/body/div[1]/div[2]/div[2]/div/div/div[1]/div/ul/li/a') classification_href_list = list() for classification in set(novel_classification): href = self.url + classification.xpath('./@href')[0].replace('/category/', '') classification_href_list.append(href) return classification_href_list
-
-
解析数据
-
获取书名、作者、状态、热度、简介等数据
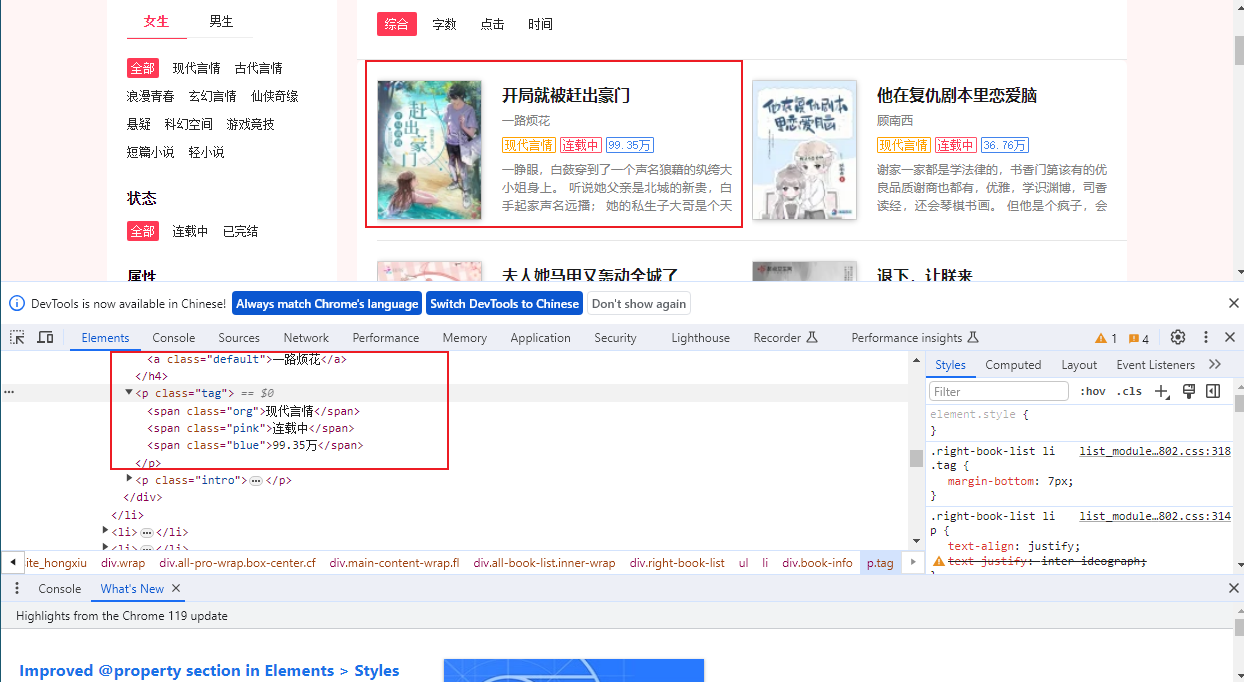
-
代码如下:
def analysis(self, classification_url_link): for classification_url in classification_url_link: # print(classification_url) for num in range(1, 51): url = classification_url.replace(classification_url[-1], str(num)) novel_response_text = requests.get(url).text # print(novel_response_text) novel_response_html = etree.HTML(novel_response_text) novel_response = novel_response_html.xpath('/html/body/div[1]/div[2]/div[3]/div[2]/div[1]/ul/li') for novel in novel_response: novel_dict = dict() novel_dict['novel_name'] = novel.xpath('./div[2]/h3/a/@title')[0] novel_dict['author'] = novel.xpath('./div[2]/h4/a/text()')[0] novel_dict['classify'] = novel.xpath('./div[2]/p[1]/span[1]/text()')[0] novel_dict['state'] = novel.xpath('./div[2]/p[1]/span[2]/text()')[0] novel_dict['number'] = novel.xpath('./div[2]/p[1]/span[3]/text()')[0] novel_dict['synopsis'] = novel.xpath('./div[2]/p[2]/text()')[0].replace('\r\n', '').replace(' ', '') # print(novel_dict)
-
-
将数据存储进数据库中
-
调用将数据存储进mysql数据库的类
MySQL().main(table_name='hongxiu_novel', data=novel_dict) -
连接数据库
def connect_to_database(self): """连接到MySQL数据库""" self.connection = pymysql.connect( host='localhost', user='root', password='password', database='reptile_text', port=3306 ) def disconnect_from_database(self): """断开与MySQL数据库的连接""" if self.connection: self.connection.close() -
判断数据表是否存在
def table_exists(self, table_name): """检查数据表是否存在""" self.connect_to_database() cursor = self.connection.cursor() cursor.execute("SHOW TABLES LIKE '{}'".format(table_name)) result = cursor.fetchone() cursor.close() self.disconnect_from_database() if result: return True else: return False -
数据表不存在则根据提供的数据字典键来进行创建新数据表
def create_table(self, table_name, data): """创建包含文本列的数据表""" self.connect_to_database() cursor = self.connection.cursor() columns = [] for key, value in data.items(): column_type = 'TEXT' columns.append(f'{key} {column_type}') create_table_sql = f"CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(set(columns))})" cursor.execute(create_table_sql) print('数据表创建成功') cursor.close() self.disconnect_from_database() -
将数据插入进数据库中
def insert_data(self, table_name, data): """在表中插入数据""" self.connect_to_database() cursor = self.connection.cursor() keys = ', '.join(data.keys()) values = ', '.join([f"'{value}'" for value in data.values()]) one_key = list(data.keys())[0] select_sql = f"SELECT * FROM {table_name} WHERE {one_key} ='{data[one_key]}'" cursor.execute(select_sql) result = cursor.fetchone() if result: print(f"数据已存在: {data}") else: insert_sql = f"INSERT INTO {table_name} ({keys}) VALUES ({values})" cursor.execute(insert_sql) print(f"插入数据: {data}")
-
完整代码
-
hongxiu_novel.py完整代码
# coding:utf-8 import requests from lxml import etree from reptile_text.mysql_data import MySQL class HongXiu(object): def __init__(self): self.url = 'https://www.hongxiu.com/category/' def novel_sort_link(self): novel_website = requests.get(self.url).text # print(novel_website) novel_classification_link = etree.HTML(novel_website) novel_classification = novel_classification_link.xpath( '/html/body/div[1]/div[2]/div[2]/div/div/div[1]/div/ul/li/a') classification_href_list = list() for classification in set(novel_classification): href = self.url + classification.xpath('./@href')[0].replace('/category/', '') classification_href_list.append(href) return classification_href_list def analysis(self, classification_url_link): for classification_url in classification_url_link: # print(classification_url) for num in range(1, 51): url = classification_url.replace(classification_url[-1], str(num)) novel_response_text = requests.get(url).text # print(novel_response_text) novel_response_html = etree.HTML(novel_response_text) novel_response = novel_response_html.xpath('/html/body/div[1]/div[2]/div[3]/div[2]/div[1]/ul/li') for novel in novel_response: novel_dict = dict() novel_dict['novel_name'] = novel.xpath('./div[2]/h3/a/@title')[0] novel_dict['author'] = novel.xpath('./div[2]/h4/a/text()')[0] novel_dict['classify'] = novel.xpath('./div[2]/p[1]/span[1]/text()')[0] novel_dict['state'] = novel.xpath('./div[2]/p[1]/span[2]/text()')[0] novel_dict['number'] = novel.xpath('./div[2]/p[1]/span[3]/text()')[0] novel_dict['synopsis'] = novel.xpath('./div[2]/p[2]/text()')[0].replace('\r\n', '').replace(' ', '') # print(novel_dict) MySQL().main(table_name='hongxiu_novel', data=novel_dict) def main(self): classification_url_link = self.novel_sort_link() self.analysis(classification_url_link) if __name__ == '__main__': HongXiu().main() -
mysql_data.py完整代码
# -*- coding:utf-8 -*- import pymysql class MySQL(object): def __init__(self): self.connection = None def connect_to_database(self): """连接到MySQL数据库""" self.connection = pymysql.connect( host='localhost', user='root', password='password', database='reptile_text', port=3306 ) def disconnect_from_database(self): """断开与MySQL数据库的连接""" if self.connection: self.connection.close() def create_table(self, table_name, data): """创建包含文本列的数据表""" self.connect_to_database() cursor = self.connection.cursor() columns = [] for key, value in data.items(): column_type = 'TEXT' columns.append(f'{key} {column_type}') create_table_sql = f"CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(set(columns))})" cursor.execute(create_table_sql) print('数据表创建成功') cursor.close() self.disconnect_from_database() def table_exists(self, table_name): """检查数据表是否存在""" self.connect_to_database() cursor = self.connection.cursor() cursor.execute("SHOW TABLES LIKE '{}'".format(table_name)) result = cursor.fetchone() cursor.close() self.disconnect_from_database() if result: return True else: return False def insert_data(self, table_name, data): """在表中插入数据""" self.connect_to_database() cursor = self.connection.cursor() keys = ', '.join(data.keys()) values = ', '.join([f"'{value}'" for value in data.values()]) one_key = list(data.keys())[0] select_sql = f"SELECT * FROM {table_name} WHERE {one_key} ='{data[one_key]}'" cursor.execute(select_sql) result = cursor.fetchone() if result: print(f"数据已存在: {data}") else: insert_sql = f"INSERT INTO {table_name} ({keys}) VALUES ({values})" cursor.execute(insert_sql) print(f"插入数据: {data}") self.connection.commit() cursor.close() self.disconnect_from_database() def main(self, table_name, data): if self.table_exists(table_name): print('数据表已存在') self.insert_data(table_name, data) else: print('数据表不存在') self.create_table(table_name, data) self.insert_data(table_name, data)