Python前端开发使用Python可以对网页进行编写,按照针对浏览器或web服务器访问的标准化协议超文本传输协议(HTTP)运行,接受来自用户的请求并返回页面,并且还可以实现与Web客户端的交互
比如 PC页面,手机页面, 平板页面,屏幕展现出来都是前端内容
后端是指负责处理数据和逻辑的一端,也就是服务器端,它负责处理业务逻辑、安全性和数据存储等工作
常见的后端 : python, Java GO等
对于前端来说的学习:
1. HTML 网页的架子,只是i负责显示一些内容,但是显示出来的内容单调
2.CSS 对网页的架子美化,让网页变得优化美感
3.JavaScript HTML,CSS都是不能动的 ——静态 Js就是让网页能够动起来,变得更加美感
4.bootstrap , jQuery
一些前端配套的框架(库): bootstrap, jQuery, vue ,react, angular, js
当 网址栏中输入地址,enter 到看到页面的返回,整个过程发生了什么事?
1.客户端输入网址向服务端发起请求
2.服务端收到客服端的请求,处理请求
3.服务端要给客户端做出响应
4.把服务端返回的内容 渲染(显示)到浏览器页面中
浏览器(前端代码的执行环境)来翻译前端的代码 ——浏览器就是前端的解释器
浏览器是一个万能的客户端,可以作为很多服务端的客户端,比如 淘宝 ,腾讯视频 等
当自主开发一个服务端时,可让浏览器作为其 客户端
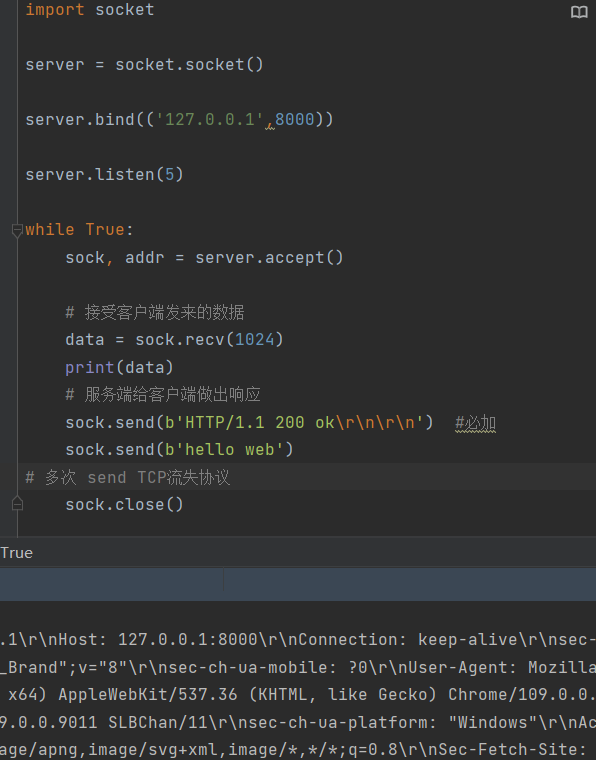
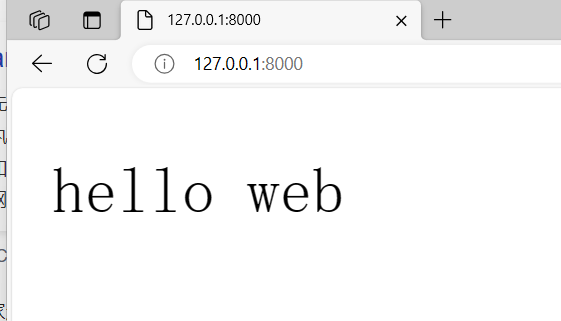
服务端的书写 利用 socket写一个服务端 让浏览器作为其客户端
————————————————————————————————————————
当浏览器称为很多服务器的客户端时 是如何识别的?
必须遵循浏览器的规则 :
(HTTP协议)
HTTP协议属于应用层协议为了实现某一类具体应用的协议,并由某一运行在用户空间的应用程序来实现其功能
HTTP协议的四大特性:
1. 基于请求和响应的(有请求,有响应)
2.它是基于TCP协议之上的应用层协议
3.无状态
这个协议不能够再浏览器中保存数据,现在使用的淘宝,支付宝,京东等网站都需要登录 cookie,session,token,jwt等保存的,这才是真正保存用户数据的。
4. 短链接 :发完消息后立刻断开连接
长链接:不会立刻的断开连接
响应数据
响应首行(响应状态码)
响应头(K:V键值对形式代码)
请求数据
请求首行(请求方式,协议和版本号)
请求头(多数K:V 键值对的形式代码)
空
换行符 \n 也可以是 \r\n
请求方式:
多种方式;目前掌握两种
get:
当朝服务端索要数据的时候,一般使用 get请求方式
——————————————
https://pro.jd.com/mall/active/2X4KPzLccZdVRKe8AiCGVuEKvgDt/index.html?unionActId=31165&d=0bchb5I&s=&cu=true&utm_source=browser.lenovo.com.cn&utm_medium=tuiguang&utm_campaign=t_330412191_&utm_term=0de203c61ca64d44b8ca13f89abec41a
https://pro.jd.com/index
https://pro.jd.com/func/v1/?k=v&k1=v1&k2=v2
?之后是参数
def index()
def func()
——————————————
post
当前服务端提交数据的时候,一般采用post请求方式
post请求,参数在哪里传递?
题:
get 与post的区别
1)post请求更安全(不会作为url的一部分,不会被缓存、保存在服务器日志、以及浏览器浏览记录中,get请求的是静态资源,则会缓存,如果是数据,则不会缓存)
(2)post请求发送的数据更大(get请求有url长度限制,http协议本身不限制,请求长度限制是由浏览器和web服务器决定和设置)
(3)post请求能发送更多的数据类型(get请求只能发送ASCII字符)
(4)传参方式不同(get请求参数通过url传递,post请求放在request body中传递)
(5)get请求产生一个TCP数据包;post请求产生两个TCP数据包(get请求,浏览器会把http header和data一并发送出去,服务器响应200返回数据;post请求,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 返回数据)
注意:在发送 POST 的时候都没有带 Expect 头,server 也自然不会发 100 continue。
响应状态码
使用一个特殊的数字代表一串复杂的描述性信息
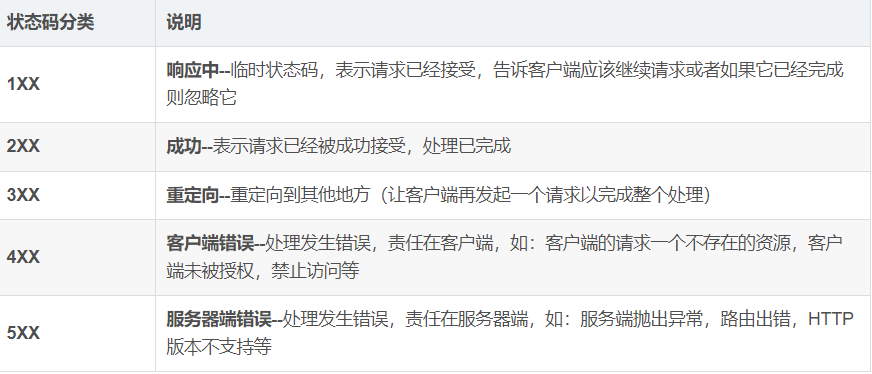
常见状态码:

题: 请说出常见的状态码
————————————————————————————————————————————————————————





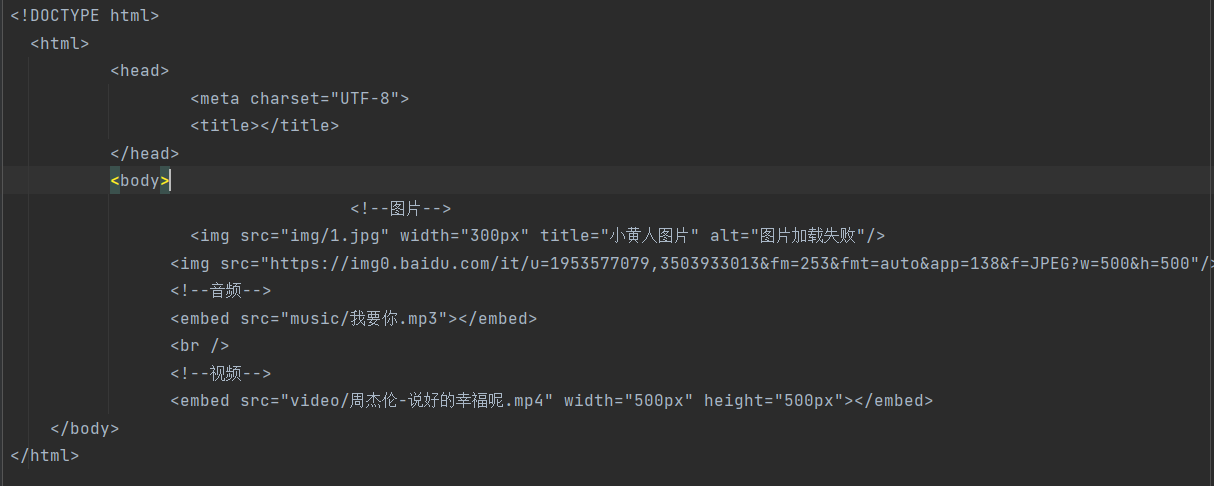
传图片的话 也是相同步骤。 <img src=' '>
复制 图片地址
HTML介绍
在网页中所能看到的 都是HTML标签
例如上方链接所展示的标签;而网站的背后由许多标签组成
html文档介绍
当新建 heml后缀文件时 会自动添加
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
</body>
</html>
<head> 标签里面写的内容一般不是让用户看的,给程序员看的
<body> 标签才是用户看的,在body里面写什么,浏览器就显示什么,
head里面写的代码是对body中的代码做控制

也可通过这里 删除
1. 直接点击pycahrm右上角的浏览器图标
2. 直接找到文档所在的位置,右键选择使用浏览器打开即可
浏览器就是前端的解释器,所有的前端代码都是有浏览器来翻译的
# 基本标签:
<b>加粗</b>
<i>斜体</i>
<u>下划线</u>
<s>删除</s>
<p>段落标签</p>


<h1>标题1</h1>
<h2>标题2</h2>
<h3>标题3</h3>
<h4>标题4</h4>
<h5>标题5</h5>
<h6>标题6</h6>


<!--换行-->
<br>
<!--水平线--><hr>
# 特殊字符
内容 对应代码
空格
> >
< <
& &
¥ ¥
版权 ©
注册 ®