前言
本文主要整理总结face landmark有关的数据集。
https://github.com/open-mmlab/mmpose/blob/main/docs/en/dataset_zoo/2d_face_keypoint.md
关键特征点个数有5/15/68/98/106...
数据集
300W dataset
68个点,Indoor和Outdoor目录各300个人脸及其68个点的标注文件;
数据集下载
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.001
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.002
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.003
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.004
其他数据集下载链接
xm2vts: 只有2360个68点的标注文件
frgc:只有4950个68点的标注文件
https://ibug.doc.ic.ac.uk/download/annotations/frgc.zip
lfpw:
测试和训练集共有2070/2=1035张图像及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/lfpw.zip
helen:
测试和训练集共有4660/2=2330个人脸及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/helen.zip
AFW:
674/2=337个人脸及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/afw.zip
ibug:
270/2=135个人脸及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/ibug.zip
WFLW dataset
这是由商汤提供的,98个关键点,还包括occlusion, position, make-up, lighting, blur, and expression等人脸属性;训练集7500images(list_98pt_rect_attr_train.txt),测试集2500images(list_98pt_rect_attr_test.txt);
标签格式:196+4+6+1=207;
coordinates of 98 landmarks (196) + coordinates of upper left corner and lower right corner of detection rectangle (4) + attributes annotations (6) + image name (1) x0 y0 ... x97 y97 x_min_rect y_min_rect x_max_rect y_max_rect pose expression illumination make-up occlusion blur image_name
标注图像

为什么出现两个wflw_annotations.tar文件呢?
Lapa dataset
JD-landmark
https://sites.google.com/view/hailin-shi
106个关键特征点;
需要注意的是每个图仅仅标注了一张人脸关键点。需要注意的坑是其中#75和#105重合,#84和#106重合。
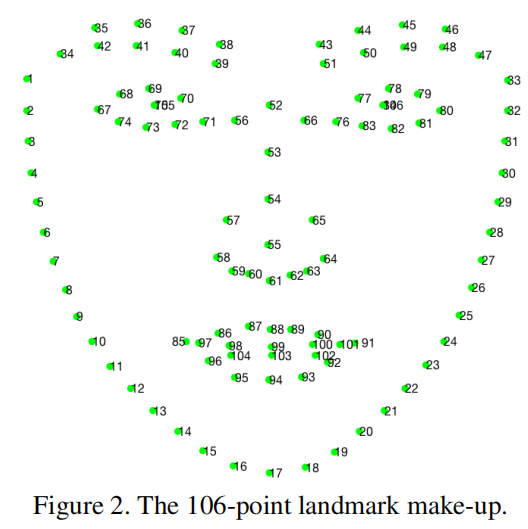
合并后数据集链接: https://pan.baidu.com/s/179crM6svNbK3w28Z0ycBHg 提取码: 7guh
Kaggle dataset
Facial Keypoints Detection 4+15points;
分析总结
68个关键点的数据集:
300w(600) / lfpw(1035) / helen(2330) / AFW(337) / ibug(135);
600+1035+2330+337+135=4437;
300w_name,包含indoor和outdoor;
lfpw_train/test_name,训练集和测试集的名字重名,需要区分开,直接使用train/test或者0/1指定;
helen,train/test数据集,应该没有重名的,可以直接使用,需要验证注意,因为名字没有规律;
afw,与helen相似,不知道二者有没有重复的;
ibug,有规律,但是不知道会不会和lfpw重复;
故,最好都加上原数据集的名称,然后组成新的数据集,再分割train/valid;
gen68kp.sh


#!/bin/sh ''' generate 68 keypoints face landmark dataset from 300w/lfpw/helen/afw/ibug dataset. 300w 01_Indoor/02_Outdoor 300w_name lfpw trainset/testset lfpw0/1_name helen trainset/testset helen_name afw afw_name ibug ibug_name ''' script_path="$(pwd)" kp68path="$script_path/68kp" # 300w for file in $script_path/300w/300w/01_Indoor/*; do echo $file base=$(basename $file) newfile=$kp68path/"300w_"$base cp $file $newfile done for file in $script_path/300w/300w/02_Outdoor/*; do echo $file base=$(basename $file) newfile=$kp68path/"300w_"$base cp $file $newfile done # lfpw for file in $script_path/lfpw/trainset/*; do echo $file base=$(basename $file) newfile=$kp68path/"lfpw0_"$base cp $file $newfile done for file in $script_path/lfpw/testset/*; do echo $file base=$(basename $file) newfile=$kp68path/"lfpw1_"$base cp $file $newfile done # helen/afw/ibug # jpg ---> png for file in $kp68path/*.jpg; do # for file in $script_path/aaa/*jpg; do pngname=${file%.jpg}.png # convert "$file" "${file%.jpg}.png" ffmpeg -pix_fmt rgb24 -i $file -pix_fmt rgb24 $pngname rm $file done # split dataset to train/valid with png/pts. ''' .dataset68 ├── train │ ├── png │ └── pts └── valid ├── png └── pts ''' dataset_path="$script_path/dataset68" cd $script_path find $script_path/68kp/ -name "*.png" > $script_path/image.txt rm -r $dataset_path mkdir $dataset_path cd $dataset_path mkdir train valid cd train mkdir png pts cd ../valid mkdir png pts cd $script_path python genpath.py # 分割数据集
98个关键点的数据集:
wflw(10000) / JD-landmarks-98(unavaiable?)
106个关键点的数据集:
JD-landmark(?) / Lapa(22000)
可以先使用68个点的进行训练,后续再训练98/106的,需要预处理数据集;
参考
- Face 2D Keypoint ‒ MMPose 1.1.0 documentation;
- mmlab_2d_face_keypoint;
- Look at Boundary: A Boundary-Aware Face Alignment Algorithm;
- GitHub - lucia123/lapa-dataset: A large-scale dataset for face parsing (AAAI2020);
- GitHub - JDAI-CV/lapa-dataset: A large-scale dataset for face parsing (AAAI2020) ;
- Grand Challenge of 106-p Facial Landmark Localization;
- Facial Keypoints Detection;