概念简介
外部表:删除表时,外部表只删除元数据,不删除数据。适用于数据源被多处使用的场景,便于数据共享。
内部表:删除表时,内部表的元数据和数据会被一起删除。适用于不需要共享的原始数据或中间数据。
分区表:数据较多,为提高计算速度时使用。
内部表&外部表写入流程图
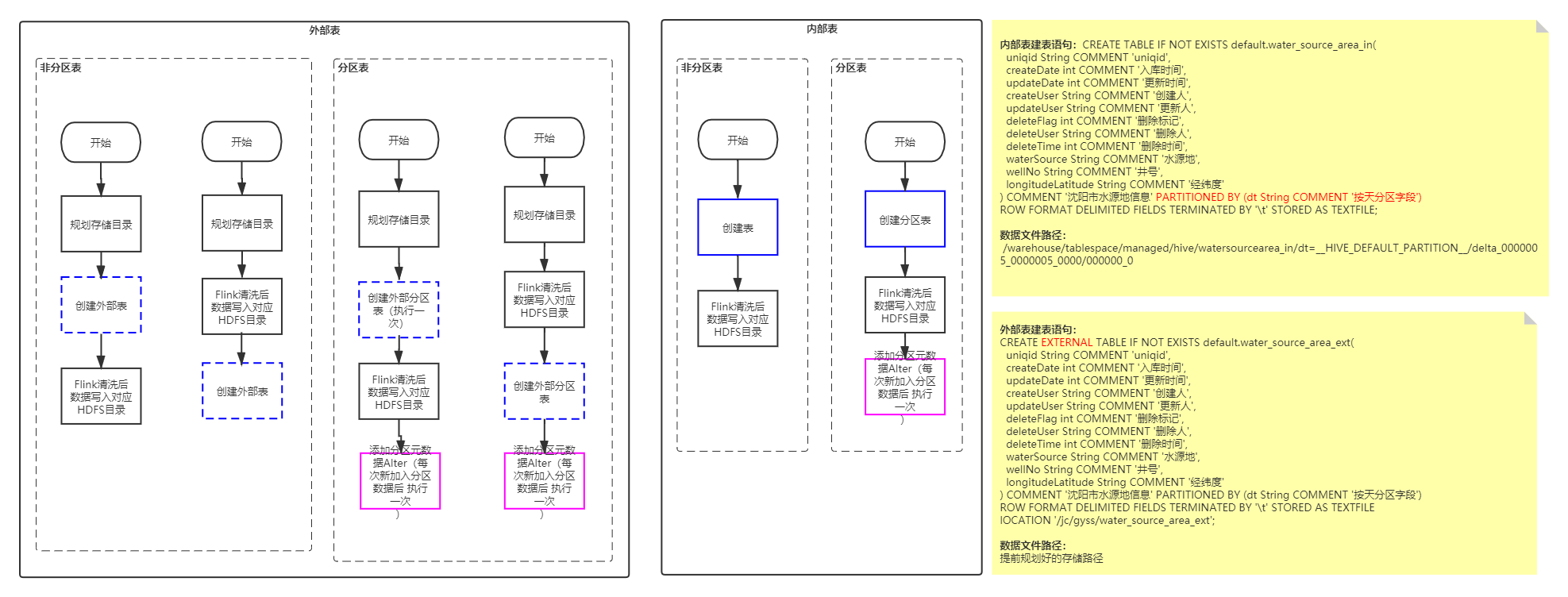
具体流程Demo
以外部表为例:
1.规划存储目录:
源数据存储数据目录:
|--/jc |----/gyss |------/water_source_area_in |--------/dt=20200525
2.创建根目录:
hadoop fs -mkdir /jc/gyss/water_source_area_ext/
3.创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS default.water_source_area_ext( uniqid String COMMENT 'uniqid', createDate int COMMENT '入库时间', updateDate int COMMENT '更新时间', createUser String COMMENT '创建人', updateUser String COMMENT '更新人', deleteFlag int COMMENT '删除标记', deleteUser String COMMENT '删除人', deleteTime int COMMENT '删除时间', waterSource String COMMENT '水源地', wellNo String COMMENT '井号', longitudeLatitude String COMMENT '经纬度' ) COMMENT '沈阳市水源地信息' PARTITIONED BY (dt String COMMENT '按天分区字段') ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE lOCATION '/jc/gyss/water_source_area_ext';
4.数据通过Flink写入Hdfs
用命令模拟Flink写入
hadoop fs -mkdir /jc/gyss/water_source_area_ext/dt=20200525 hadoop fs -put test01.txt /jc/gyss/water_source_area_ext/dt=20200525 hadoop fs -mkdir /jc/gyss/water_source_area_ext/dt=20200526 hadoop fs -put test02.txt /jc/gyss/water_source_area_ext/dt=20200526
测试数据目录:/home/hdfs/jc
5.更新元数据
逐一加入分区元数据
alter table water_source_area_ext add partition (dt='20200525') location '/jc/gyss/water_source_area_ext/dt=20200525'; alter table water_source_area_ext add partition (dt='20200526') location '/jc/gyss/water_source_area_ext/dt=20200526';
批量将未加入的分区元数据全部加入
msck repair table water_source_area_ext;
6.查询数据,此时数据已全部可查。
select * from water_source_area_ext;
任务提交方式:
1.将整体操作流程写入统一任务脚本,后续可以搭建任务管理工具xxlJob或Oozie等任务调度工具,负责任务的依赖和定时触发。
2.整个建表,更新元数据,数据写入过程都写入Flink清洗程序,Flink可以用Jdbc方式执行Hive的DDL操作。
注意:
不建议使用insert into方式写Hive数据,此种方式会生成临时表,数量较大时效率较低。
如果使用外部表,想要彻底删除数据,需要同步删除Hdfs数据。