If you get gains,please give a like
Bioinformatics Computational Biology biostats
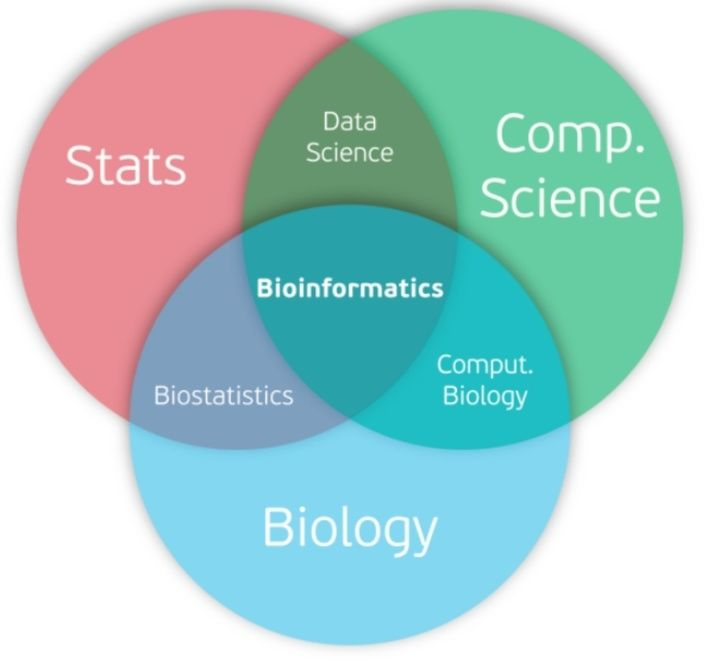
对于这两个专业,我们可以从应用领域来区分:
●Biostatistics生物统计学的研究方向可分为两类:统计遗传学和临床统计学;课程中与生物相关的内容很少,更重视学生的量化能力。
●而Bioinformatics生物信息学与数据挖掘类似,生物信息学是利用数学工具从大量数据中提取有用的生物学信息,比如要处理的典型问题有:从蛋白质的氨基酸序列预测蛋白质结构。
如果这样还分不清,请大家这样理解:
●Biostatistics – bio = Statistics
●Bioinformatics – bio = Informatics(CS的分支)
● 因此生物统计更侧重统计分析,是统计学在医学相关领域的应用,主要处理可转化为矩阵的生物数据,多使用R、SAS、Matlab,侧重Statistics。
生物信息学偏重信息计算,主要做基因测序、图像建模。主要是做算法,处理序列数据,多使用python、C++,侧重Computer Science。
bioinformatics更专注于大数据,特别是各种组学—基因组学,蛋白质组学,代谢组学,转录组学;以及处理各种高通量实验产生的数据,如RNA-seq,CHIp-seq, GWAS, 高通量质谱仪数据等。强调高效计算能力和算法,计算平台包括R(特别是bioconductor包),python等。
bistat 经常处理小数据,但是这种小数据是极其关键的。因为药厂极其昂贵的临床试验往往遭遇各种各样的数据缺失,比如病人不按时服药,病人不来了,以及各种模型的假设不成立等等,强调数理统计,严谨的实验设计,非参数方法,生存分析等等。常用软件包括SAS,R等。
现代医学信息和高通量分子生物技术的巨大变革引导着疾病诊疗和药物应用方式的巨大变革,
医疗实践逐渐将循证医学作为出发点,从基因,蛋白质等大分子水平研究疾病的发病机理,对疾病进行预防,诊断和治疗,整体朝向特异性诊断,个体化治疗方向发展。
细胞生物学 分子生物学 Lewin 基因XII
在不远的未来,可以设想遗传信息在临床环境下的集成应用必将导致个性化医疗等新的临床实践的巨大变革,未来的预防性 基因检测将会变得普遍。
还是什么感兴趣搞什么吧~挣钱没错肯定偏IT好挣钱啊~
不过要搞学术的话。。纯IT除了做软件做web service就有点辅助的感觉了,混学术圈还是要加强生物知识的学习,最好本科和研究生阶段做做实验,加深对生物学问题的理解(不然纯跑流程搞不清跑出来的的结果是对是错自己不会分析是很鸡肋的。。最好是自己能分析生物学问题,自己主动找一些方法/模型来分析得到问题答案)
。。生统夹在中间。。也很赚钱. 如果是做算法和基于新算法的生信工具软件开发,统计学知识也很重要。
坡县挺好,唯一的劣势就是太小了。。过小日子还行,想施展拳脚的话还是要找中美这样的大市场。以后可以去别的地方继续深造.
生物统计是搞统计的,统计方面的基础是核心 statics
计算生物学是搞生物的,生物方面的基础是核心 CS Computer Science 偏理论
主理论 比算法
生物信息学是搞信息的,信息方面的基础是核心 IT Information 工程 偏应用
主应用 跑流程
但其实,从就业市场而言,并不是这么搞的。想要高薪,一定要提升计算机方面的操作和理论水平,过去十多年看来,这是不二法门啊。其次是统计学,有助于树立起数理基础的门槛,秒杀培训班出来的码农。生物嘛~~~~看兴趣了,想在你提及的这三个领域发展,还是需要点基础的,跳到其他领域去就没太多用了。
其实日本东京大学的生物信息学和生物统计学也很强大,分别专门成立的相应的专攻。生物信息学在理学研究科,生物统计学在情报学环研究科。主要面向医药学领域。生物信息学研究的更加具象,比如研究:序列比对(Alignment),比较两个或两个以上蛋白质分子空间结构的相似性或不相似性,蛋白质结构预测,计算机辅助基因识别,非编码区分析和DNA语言研究。对计算机和数学方面专业知识要求比较高。生物方面反而次之。
生物情报学的发展日新月异在全球都面临严重的人才不足。尤其在美国也是大热专业领域。日本该专业的毕业生一般会选择继续进学读完博士课程。就职的学生中很多去了医药企业,或者大数据公司,也有去银行或政府部门的。总之通过对生物信息学的学习毕业生具备了对复杂原生态信息的高度处理能力,因此在数据化的当今社会各行业都是有很高需求的,如果本专业就职还是建议取得博士号后在大学或研究机关从事研究职位或在制药企业从事研究职位或顾问职位。
其实基础生物最后每天都是在做一些重复实验,只有极其少数的精英分子能接触技术开发试验和高级实验技术。一般情况下,你的日常都是qpcr,wb,养细胞,处理模式生物和插枪头等,你觉得有意思就有意思。当你觉得没意思的时候,对不起!爬不出去了!
生信其实依赖数学方法和计算机来处理一些生物高通量数据,其实就是应运高通量测序的发展衍生出来的东西,在此之前其实是计算生物学,就和现在DL盖过机器学习一个概念!抛开生物的限制,你实际还是在处理数据,而且生信的分析方法和工具基本来自于应用数学和计算机领域!连我们图书馆计算机小哥都能自学生物跟着大团队发一区的文章,可见非实验的生物门槛有多低。同时,也引发一系列的连锁反应,比如,很大一部分生信算法文章都是由计算机行业的人提出和未来计算机内卷也会导致大量计算机人员涌入生信领域等问题,未来堪忧!
生物数学本科在读,简单说一下吧。
生物:包括生态学,生理学,遗传学,演化论,细胞生物学,分子生物学为主,当然这可能和我们教授大多都是遗传学背景有关。
数学:线代,数学分析,各种各样的微积分
统计:贝叶斯,R语言,生存分析,各种统计模型检验
计算机(信息技术):抱歉,真不了解
那么,把以上排列组合一下,
生物信息:生物+计算机(不了解)
生物统计:生物+统计(统计为主)
生物数学(计量生物学):生物+统计+数学(个人觉得数学和生物五五开)
大数据:数学+计算机
生物大数据:数学+计算机+遗传学
生物工程:生物+一大堆花里胡哨的仪器和技术(不了解)
研究生生物信息学的视角里的生物信息学发展方向,欢迎大家到评论区讨论哈
1. 偏数学方向,不管是统计学,还是数据科学,机器学习相关我都归到这一类,一般是数学相关出身的人来做,这个应该算是目前最火的领域吧,不管是经典组学研究还是精准医学研究都在做
2. 偏计算机和软件工程化方向,生物信息领域的高性能计算,分布式存储等等,还有为了配合终端用户而完成的各种知识库和微服务式软件,一般是计算机出身的人在搞,目前随着组学数据的爆炸,研究规模的扩大,信息安全的需求,这个方向的需求显然是会与日俱增
3. 偏算法方向,这个主要是伴随着组学研究工具的升级迭代而出现的,从测序数据的比对,注释,进化,变异检测,到多组学数据解析,到结构解析等等,旨在解决由具体组学研究策略和工具引入的数学问题,这块数学背景,计算机背景和生物背景的都有,一般和组学研究工具深度绑定,比如将来出现了一种全方位取代当前测序技术的测序策略,可能就不会有比对的研究了,会引入新的算法问题
生物信息学并不是一门被准确定义的学科,更像一个箩筐,涉及的领域和方向很多,什么都往里装。希望我的分析能给你一些帮助,更具体的建议可以参考其他答主
生物信息学最重要的是生物学问题和大量数据,以及软件算法能力。
所以重要的是选择一个能够产生大量数据的子领域逐步深入下去。
没有好的数据,搞不了好的生物信息学。
确实,问了一些导师,发现国外很多生信实验室都背靠大医院,有着丰富的临床数据库可以挖掘,数据资源很重要
很多前沿热门其实还是都涉及医学,像靶向药,抗体药,细胞免疫,代谢,干细胞等等
Bioinformatics Computational biostats Biologybioinformatics computational biostats biology biology biostats computational computational mechanical response uniaxial bioinformatics 2014 computational international proceedings computational information constraints theory computational complexity笔记 bioinformatics girke http edu