一. 红黑树的要点:
在介绍HashMap与ConcurrentHashmap底层原理之前我们首先介绍红黑树的知识点,他是我们JDK1.8后为HashMap与ConcurrentHashMap引入的优化的数据结构。
1.1 红黑树的特点:
1.每一个结点不是红色就是黑色
2.不可能有连接在一起的红色结点,也即是如果有一个结点是红色,则他的两个孩子结点必定是黑色
3.根节点都是黑色的
4.任意一个结点到每一个叶子节点的路径上都包含数量相同的黑色结点
5.每一个空指针域都是黑色的
1.2 红黑树的形成过程:
1.红黑树为空树的结构时候:
把插入的结点当成根节点并且把结点的值设置成为黑色,使其满足特点3
2.插入的结点的key已经存在:
把插入结点设置为当前结点的颜色,同时更新当前结点的值为插入结点的值
3.插入结点的父结点为黑色:
无需任何操作直接插入即可
4.当插入结点的父节点为红色时候:
(1)叔叔结点存在并且为红色结点:
1)将父亲结点与叔叔结点先设置成黑色
2)祖父结点设置成为红色
(2) 叔叔结点不存在或者为黑色结点,并且插入结点父节点为祖父结点的左结点:
1)插入结点是父亲结点的左结点:
将父亲结点设置成黑色,祖父结点设置成红色,对祖父节点进行右旋
2)插入结点时父亲结点的右结点:
先对父亲结点进行一次左旋,其余的情况与1)的步骤一样
(3) 叔叔结点不存在或者为黑色结点,并且插入结点父节点为祖父结点的右结点:
1)插入结点是父亲结点的右结点:
将父亲结点设置成黑色,祖父结点设置成红色,对祖父节点进行左旋
2)先对父亲结点进行一次右旋,其余的情况与1)的步骤一样
1.3 红黑树的Java代码:
package BasicKnowledge.CollectionAndMap;
/*
* 手写一下红黑树:
* 红黑树的性质:
* (1) 每一个节点不是红色就是黑色
* (2) 不可能有连在一起的红色节点,也即是如果有一个节点是红色,则它的两个孩子节点必定是黑色
* (3) 根节点都是黑色的
* (4) 任意一节点到每个叶子节点的路径都包含数量相同的黑结点
* (5) 每一个空指针域都是黑色
* 变换的规则如下:
* 每插入一个节点默认是红色:
* 1.变色规则:当前节点的父节点是红色,并且它的祖父节点的另一个子节点也是红色(叔叔节点):
* (1) 父节点变成黑色
* (2) 叔叔节点也设置成为黑色
* (3) 把父亲的父亲也就是祖父节点设置成为红色
* (4) 把指针定义到祖父节点设置为当前要操作的节点
* 2.旋转的规则:
* (1) 左旋:当前父节点是红色,叔叔节点是黑色,并且当前节点是右子树时候,以父节点进行左旋转
* (2) 右旋:当前父节点是红色,叔叔节点是黑色,并且当前节点是左子树时候:
* 1) 把父节点变成为黑色
* 2) 把祖父节点变成红色
* 3) 以祖父节点进行旋转
*
*/
public class RBTree<K extends Comparable<K>,V> {
//定义节点信息:内部类:完全按照hash表中存放的值进行设计:HashMap中存放的是key-value键值对的形式:
static class RBNode<K extends Comparable<K>,V>{
private RBNode Parent; //节点的父节点
private RBNode left; //节点的左节点
private RBNode right; //节点的右节点
private boolean color; //节点的颜色
private K key; //节点的Key值 在HashMap中所对应的应该就是HashCode值
private V value; //节点所对应的value值
public RBNode(){}//无参构造函数
public RBNode(RBNode parent, RBNode left, RBNode right, boolean color, K key, V value) {
Parent = parent;
this.left = left;
this.right = right;
this.color = color;
this.key = key;
this.value = value;
}
public RBNode getParent() {
return Parent;
}
public void setParent(RBNode parent) {
Parent = parent;
}
public RBNode getLeft() {
return left;
}
public void setLeft(RBNode left) {
this.left = left;
}
public RBNode getRight() {
return right;
}
public void setRight(RBNode right) {
this.right = right;
}
public boolean isColor() {
return color;
}
public void setColor(boolean color) {
this.color = color;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
}
//RBTree的属性信息:
private static final boolean RED=true;
private static final boolean BLACK=false;
//树根的引用
private RBNode root;
public RBNode getRoot() {
return root;
}
//获取当前结点的父节点
private RBNode parentof(RBNode node){
if(node!=null){
return node.Parent;
}
return null;
}
//结点是否为红色
private boolean IsRed(RBNode node){
if(node!=null){
return node.color==RED;
}
return false;
}
//结点是否为黑色
private boolean IsBlack(RBNode node){
if(node!=null){
return node.color==BLACK;
}
return false;
}
//设置结点为红色
private void SetRed(RBNode node){
if(node!=null){
node.color=RED;
}
}
//设置结点为黑色
private void SetBlack(RBNode node) {
if (node != null) {
node.color = BLACK;
}
}
/*
* 插入新节点的方法:
*/
public void insert(K key,V value){
//创建一个RBNode:
RBNode node = new RBNode();
node.setKey(key); //设置key值
node.setValue(value); //设置value值
//新节点默认均为红色:
node.setColor(RED);
insert(node);
}
private void insert(RBNode node) {
//初始化节点值:
RBNode parent = null;
RBNode x = this.root;
while( x != null){ //当前节点不为null时进行循环
parent = x;
//因为我们实现了Comparable接口,我们直接使用Comparable接口的比较方法:
int cmp = node.key.compareTo(x.key);
if ( cmp > 0){ //cmp大于零是说明当前的值比parent要大:
x = x.right;
}else if( cmp == 0 ){ //相等直接做替换操作:
x.setValue(node.getValue());
}else if( cmp <0 ){
x = x.left;
}
}
node.Parent = parent;
if(parent != null){
//判断node和parent谁的key更加的大:
int cmp = node.key.compareTo(parent.key);
if(cmp > 0)
{
parent.right = node;
}else {
parent.left = node;
}
}else{//当红黑树是空树的时候的初始化的操作:将根节点设置为当前的节点:
this.root = node;
}
//需要对于红黑树进行修复平衡:
insertfixUp(node);
}
/*
* 变色加上修复旋转:
* 修复方法:
* 情况一:红黑树是空树,则将根节点染色成为黑色:
* 情况二:插入的节点已经存在,上面已经处理完成,不用再进行处理
* 情况三:插入的节点父节点为黑色则依旧平衡,不用进行处理
* 情况四:参考博客
* (1)https://weishihuai.blog.csdn.net/article/details/109729364
* (2)https://blog.csdn.net/a1362619536/article/details/123082313
*/
private void insertfixUp(RBNode node) {
this.root.setColor(BLACK);
RBNode parent = parentof(node);//获取插入的节点的父节点
RBNode gparent = parentof(parent);//获取插入节点的父节点的父节点,祖父节点
//情形四:需要进行修复:
if( parent != null && IsRed(parent)){
RBNode uncle = null;
if( parent == gparent.left)
{
uncle = gparent.right;
//情况4.1:父亲与叔叔节点都存在,而且父亲与叔叔节点都为红色:做法将父亲与叔叔变黑,祖父节点变红:
if( uncle != null && IsRed(uncle)){
SetBlack(parent);
SetBlack(uncle);
SetRed(gparent);
//注意插入的节点祖父节点目前已经变成了红色节点,如果祖父节点的父节点是黑色那么满足我们又得从祖父节点触发进行平衡,因此是递归操作:
insertfixUp(gparent);
return;//都完成之后应当是满足红黑树性质然后进行返回
}
//情况4.2 叔叔节点不存在或者是为黑色,父亲节点为爷爷节点的左子树:
if( uncle == null || IsBlack(uncle)){
//4.2.1插入节点是父节点的左子节点,将爸爸染成黑色,爷爷变成红色,然后以爷爷进行右旋
if( node == parent.left){
SetBlack(parent);
SetRed(gparent);
rightRotate(gparent);
return;
}
//4.2.2插入节点是父节点的右子节点,将爸爸进行左旋,然后递归再进行判断:
if(node == parent.right){
leftRotate(parent);//对于父节点进行一次左旋的操作就会变成4.2.1的情形
insertfixUp(parent);
return;
}
}
}else {//父亲节点是祖父节点的右子树:
uncle = gparent.left;
//情况4.1 叔叔节点存在 ,且与父节点为双红:
if(uncle != null && IsRed(uncle))
{
SetBlack(parent);
SetBlack(uncle);
SetRed(gparent);
insertfixUp(gparent);
return;
}
//情景4.3:叔叔结点不存在,或者为黑色,父节点为爷爷结点的右子树:
if( uncle == null || IsBlack(uncle)){
//情景4.3.1:插入结点为其父节点的右子节点(RR情况)-----将爸爸染色为黑色,将爷爷染色为红色,然后以爷爷结点为当前结点,
if(node==parent.right){
SetBlack(parent);
SetRed(gparent);
leftRotate(gparent);
return;
}
//情景4.2.2:插入结点为去父节点的左子节点(RL情况)-----以爸爸结点进行一次右旋,得到RR双红的情景,然后指定爸爸结点为当前结点
if(node==parent.left){
rightRotate(parent);
insertfixUp(parent);
return;
}
}
}
}
}
/*
* 进行左旋:
* @param x
* /***
*
* p p
* | |
* x ------> y
* / \ / \
* lx y x ry
* / \ / \
* ly ry lx ly
*
* 左旋x
* 1.并将x的右子节点指向y的左子节点(ly),将y的左子节点的父亲结点更新为x,
* 2.当x的父节点(不为空时),更新y的父结点为x的父节点,并将x的父节点指定子树(当前x的子树位置)指定为y
* 3.将x的父子节点更新为y,将y的左子节点更新为x
*
*/
private void leftRotate(RBNode x) {
RBNode y = x.right;
//将 x 的右子节点指向y的左子节点,将y的左子节点的父亲节点更新为x:
x.right=y.left;
if(y.left != null){
y.left.Parent = x;
}
//2.当x的父节点(不为空时),更新y的父结点为x的父节点,并将x的父节点指定子树(当前x的子树位置)指定为y
if(x.Parent != null){
y.Parent=x.Parent;
if(x == x.Parent.left){
x.Parent.left = y;
}else {
x.Parent.right=y;
}
}else {//x为根节点,需要更新y为根节点:
this.root = y;
this.root.Parent = null;
}
//3.将x的父子节点更新为y,将y的左子节点更新为x
x.Parent = y;
y.left = x;
}
/* 进行右旋:
*
* p p
* | |
* y ------> x
* / \ / \
* x ry lx y
* / \ / \
* lx ly ly ry
*
* 右旋x
* 1.并将y的左子节点指向x的右子节点(ly),将x的右子节点的父亲结点更新为y,
* 2.当y的父节点(不为空时),更新x的父结点为y的父节点,并将y的父节点指定子树(当前y的子树位置)指定为x
* 3.将y的父子节点更新为x,将x的右子节点更新为y
*/
private void rightRotate(RBNode y) {
RBNode x = y.left;
//1.并将y的左子节点指向x的右子节点(ly),将x的右子节点的父亲结点更新为y:
y.left = x.right;
if(x.right != null){
x.right.Parent=y;
}
//2.当y的父节点(不为空时),更新x的父结点为y的父节点,并将y的父节点指定子树(当前y的子树位置)指定为x
if(y.Parent!=null){
x.Parent=y.Parent;
if(y==y.Parent.left){
y.Parent.left=x;
}else{
y.Parent.right=x;
}
}else {
this.root=x;
this.root.Parent=null;
}
//3.将y的父子节点更新为x,将x的右子节点更新为y
y.Parent=x;
x.right=y;
}
}
二. HashMap底层源码分析:
1.首先介绍HashMap的用法:
package BasicKnowledge.CollectionAndMap;
import java.util.HashMap;
public class HashMapTest {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("x","1");
}
}
2.深入底层源码分析:
2.1 put操作:
1.首先HashMap<String,String> map = new HashMap<>()做了如下的事情:

注意这里是初始的HashMap的负载因子的赋值操作,我们可以找到对应的负载因子的值为0.75f。这个负载因子是为了后期的HashMap做扩容操作所准备的。
2.然后就是put操作:

(1)首先我们发现会先调用hash(key)的函数算出hash值:

(2)调用putVal方法:
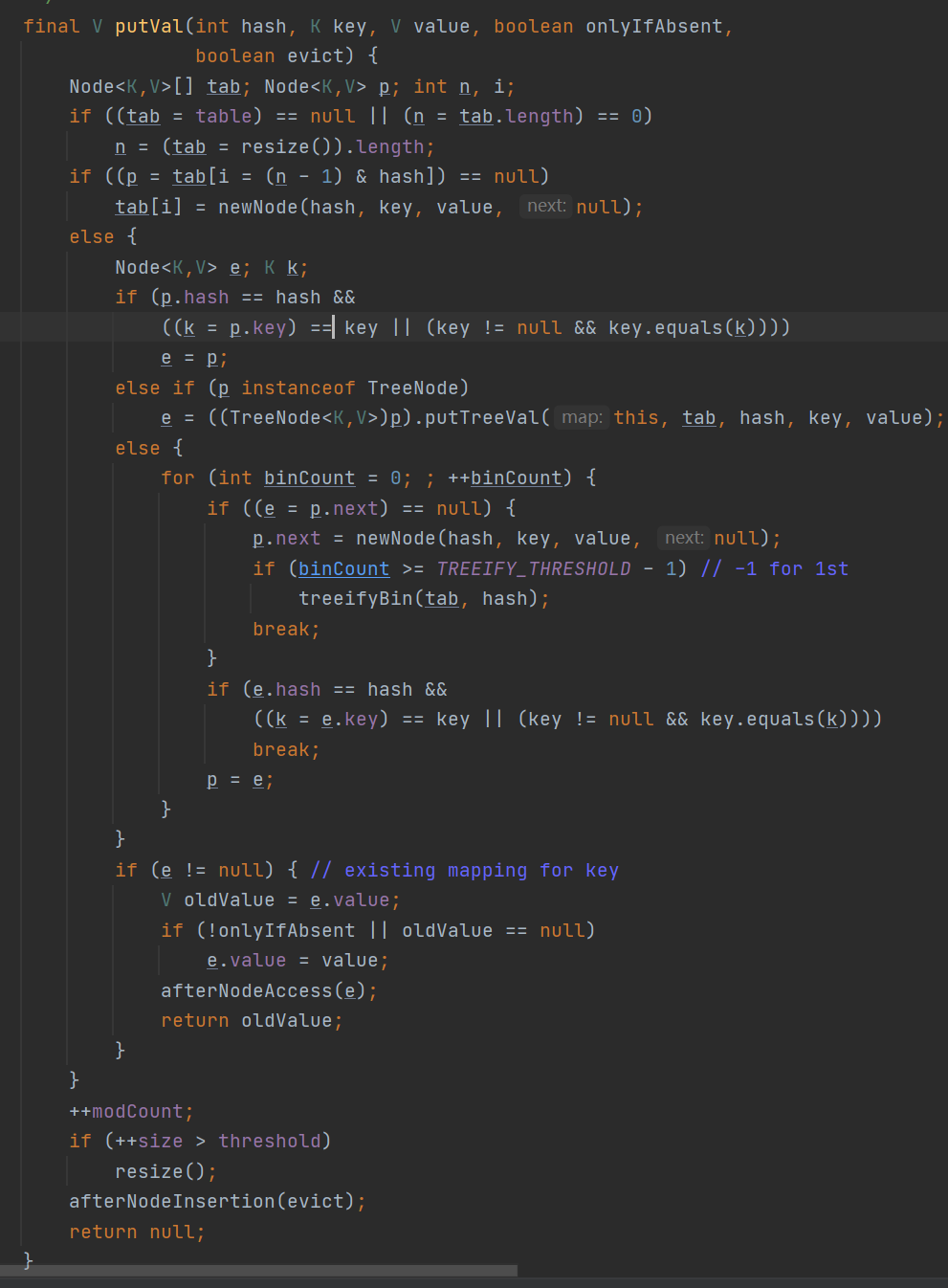
JDK1.8后的源码可读性下降,我们先自己想一下大致的插入k-v键值对的流程,然后再来看源码:
自己想的流程
(1)首先想一下HashMap底层的数据结构是数组+链表+红黑树(JDK1.8后),那么向HashMap中存放数据时候一定会初始化一个null的数组。而HashMap中在执行第一步时候不仅会赋值负载因子的值,而且会有其他属性,例如:
(2)会先生成一个Node对象,包括hash值,key值与value值
(3)会将Node结点存放在数组当中,注意需要根据hash值,key或者value其中一个值算出一个index,然后将其防在对应的数组下标位置。
查看源码流程:
1.步骤一:初始化一些局部变量:

Node结点的数据结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
2.步骤二:初始化数组:

resize()方法:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
对于resize方法涉及到table的初始化与扩容操作,我们看来看初始化操作:
(1)先会有赋值,将hashMap中table变量赋值给oldTab
Node<K,V>[] oldTab = table;
(2)为oldCap赋值,一开始table与oldTab肯定为空,那么oldCap值也就为0了:
int oldCap = (oldTab == null) ? 0 : oldTab.length;
(3)一开始进行if判断会走到:
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
其中DEFAULT_INITIAL_CAPACITY为如下:默认初始化值为16,采用的左移位运算来计算的:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
初始化的扩容的阈值为:16*0.75 = 12:
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
(4)然后就是赋值返回操作:
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
.....
return newTab;
3.步骤三:接下来我们需要存放结点了:

首先会根据(n - 1)& hash计算index,如果下标对应数组值没有值,那么就直接进行赋值。一开始一定都是空的。注意这个位运算需要保证的是算出的结果不能够超过数组的边界同时在数组的下标有效的范围内需要均匀分配可插入的位置,不能基本算出的插入位置都只在几个特定的index上。
这里就会引入一个面试题:为什么HashMap中map长度都是2的幂次方?
答:主要是需要均匀分配node在长度范围可以放置的位置,在HashMap源码当中利用的长度减一的位运算来计算index下标,当是2的幂次方时候可以保证建议后二进制的1会很多从而可以在与运算中获得更多index值,进而可以均匀分配node结点存放的位置。
此外,还会引入一个面试题:为什么HashMap中的计算hash值不是直接拿到hash值而是需要再右移16位做异或运算
答:其实这种方式可以尽可能保证所得到的hash值得低16位与高16位尽可能参与运算,因为我们1知道hashcode值对应是int类型,int类型占的是4个字节,4字节就是32位。这种方式也是为了尽可能均匀分配node结点在数组中的位置,进而减少hash冲突。如果不进行右移16位,会白百浪费高16位的数据。
上面解释完毕后,接下里就需要看当出现hash冲突时候,就是算出的index下标有数据后的解决逻辑:
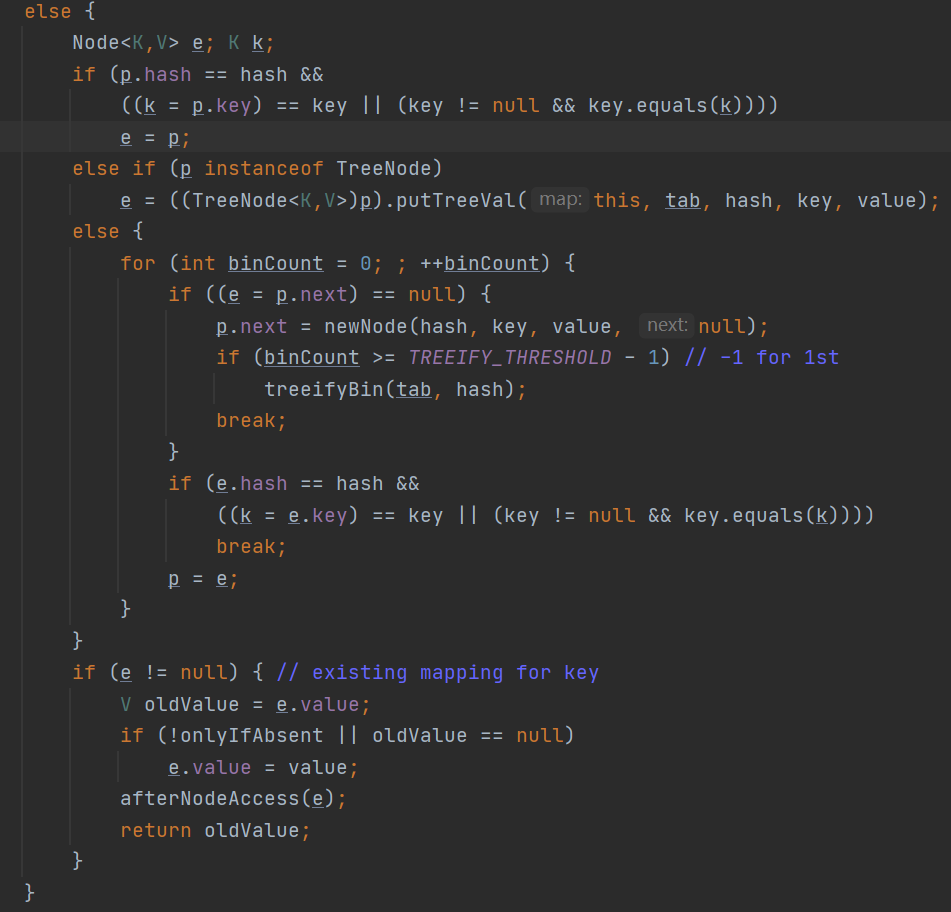
(1)第一个if分支:
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
{
e = p;
}
如果key相等的话,会将已经存在的结点value用新的value进行更新,然后返回oldValue值。
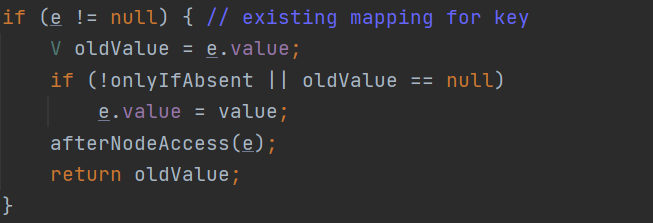
注意此时会受到onlyIfAbscent参数的影响。如果当onlyIfAbscent为true时候会在putIfAbsent判断如果其为true当key存在不会使用新值覆盖旧值,如果不存在才会将新的key与value放到hashMap中。
(2)第二个if分支:
else if (p instanceof TreeNode)
{
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
}
这里很明显与红黑树产生了关系。注意TreeNode是Node子类。也就是说对应的table中存放结点可能是Node类型也有可能是TreeNode类型。而且TreeNode中继承了Node结点属性的next属性,同时还含有ledt,right,prev属性,因此可以看成是一个双向链表。
(3)第三个if分支:
else {
for (int binCount = 0; ; ++binCount) {
//使用尾插法
if ((e = p.next) == null) {
//生成一个新的结点:
p.next = newNode(hash, key, value, null);
//链表变成红黑树,使用binCount来记录链表结点数量大于 TREEIFY_THRESHOLD
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//将链表转成红黑树:
treeifyBin(tab, hash);
break;
}
//这里还会比较这里是否相等,这里的相等指的是链表中间有相等的结点:
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
在treeifyBin中还有判断:与MIN_TREEIFY_CAPACITY有关。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//注意这里还有判断就是当数组的长度小于MIN_TREEIFY_CAPACITY(64)时还是会扩容不转换成为树
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
//只有当大于MIN_TREEIFY_CAPACITY时才会转换成红黑树:
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
注意replacementTreeNode方法:会将链表上的结点全部改成为TreeNode结点。
2.2 扩容resize()方法:
1.在之前一开始时候我们需要初始化数组的时候调用了resize()方法这里就省略不讲了
2.其他情形:
一个是在treeifyBin函数当中,当链表的长度是8个,但是数组长度小于64时候会调用resize()方法:
二是会判断整个数组中结点数量是否大于数组长度乘以0.75,如果大于也会进行扩容:
首先看resize()中比较简单的代码:
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//会重新设置新数组的大小并同时更改阈值:
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
接下来就是最重点的代码:
注意扩容会涉及到原始老数组的四种情况:
1.扩容的该索引下标位置没有数据,就是null
2.扩容时候该索引下标位置只有一个数据
3.扩容时候该索引下标位置是一个链表
4.扩容时候该索引下标位置是一个红黑树
1.扩容的该索引下标位置没有数据,就是null什么也不做
2.扩容时候该索引下标位置只有一个数据:
//老数组该位置对应的下标只有一个结点;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
3.扩容时候该索引下标位置是一个链表:
if (oldTab != null) {
//遍历老数组的下标:
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//只有原始老数组有东西才会修改,如果原来就是null就不需要修改了:
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//老数组该位置对应的下标只有一个结点;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//老数组该位置的对应的下标是红黑树:
else if (e instanceof TreeNode)
//是就会进行拆分:
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//老数组该位置的对应的下标是链表:
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
注意对于链表来,我们其实不用重新rehash,因为扩容之前与扩容之后是有规律的,可以来看举一个例子:
(1)情形一:
原始老的:
数组长度:16 ,然后key对应的hash值为:01100101
进行hash求值:
16-1(15) 0000 1111
hash: 0110 0101
&
-------------------
0000 0101
扩容后:
数组长度:32,然后key对应的hash值为:01100101
进行hash求值:
32-1(31) 0001 1111
hash: 0110 0101
&
-------------------
0000 0101(与原始的老值相同)
(2)情形一:
原始老的:
数组长度:16 ,然后key对应的hash值为:01110101
进行hash求值:
16-1(15) 0000 1111
hash: 0111 0101
&
-------------------
0000 0101
扩容后:
数组长度:32,然后key对应的hash值为:01110101
进行hash求值:
32-1(31) 0001 1111
hash: 0111 0101
&
-------------------
0001 0101(为原始的老值加上原始老的数组长度)
综上所述:所得新的结点值要么还是老值,要么是原始老值加上老数组的长度
画个图来解释:
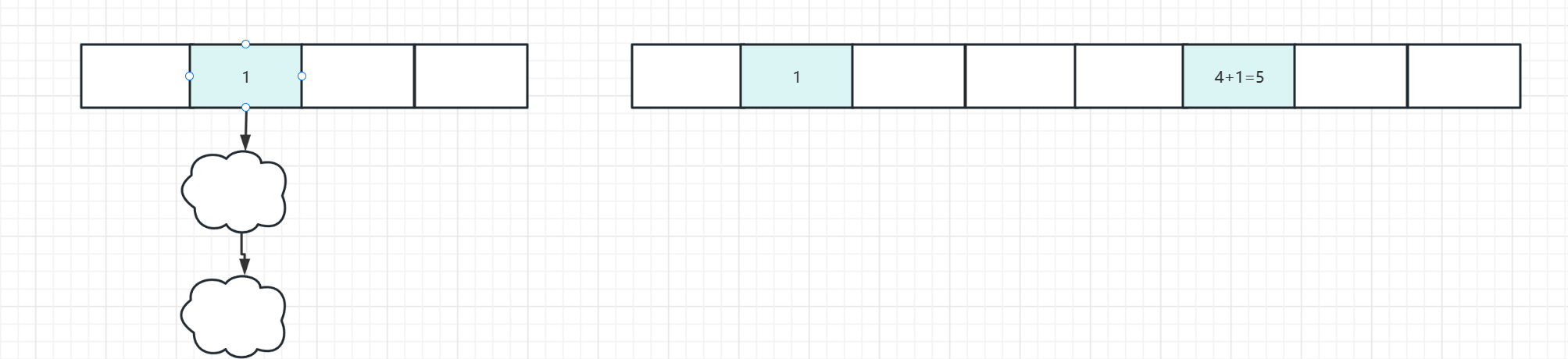
要么挂在新数组的1位置,要么挂在新数组5位置,所以用低位与高位来表示,分别有低位头指针与低位尾指针,高位头指针,高位尾指针:
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
在do-while当中会生成低位与高位两个链表:
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
然后就会判断是否有低位或者高位链表吗?有则赋值:
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
4.扩容时候该索引下标位置是一个红黑树:
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
对于红黑树与索引一样会出现高位与低位链表,在拆分后原始的红黑树可能会变成链表。也有可能一个是链表,一个是红黑树。
因此我们在split中会进行统计低位与高位的元素个数:
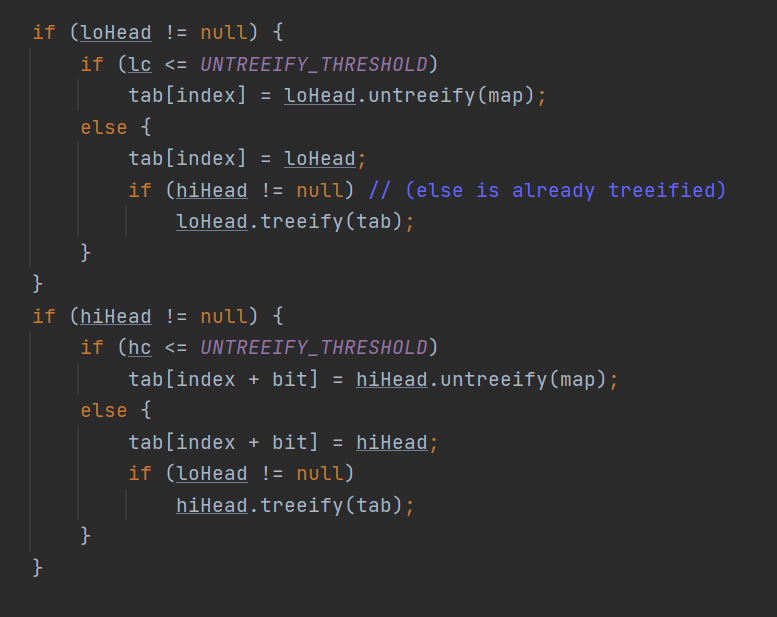
这个过程中涉及到红黑树退化成链表:
UNTREEIFY_THRESHOLD = 6:
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
三.ConcurrentHashMap底层源码分析:
注意对于HashMap来说对于线程并发过程当中是存在不安全的情况的。
我们可以很容易的想到是在ConcurrentHashmap中的put或者get方法加入sychronizd,注意HashTable是这么做的,但是synchronized却不是,因为会损失性能。因为有可能多线程中put的key对应的hashMap不是同一个位置,那么对于方法加入synchronized,锁的粒度就会非常的大。造成性能的影响。
3.1 JDK1.7 中原理:
其实看ConcurrentHashMap原理就是在看并发下ConcurrenthashMap是如何加锁的:

注意在ConcurrentHashMap中会有Segment数组还会有每一个Segment所对应的HashMap,加锁的时候是对于每一个Segment[i]进行加锁。
1.首先来看构造方法:
initialCapacity:初始的容量:j将每一个Segment所对应的Entry数组的数量加起来一共是16。
loadFactor:装载因子,扩容时候会用到。
concurrencyLevel:并发级别。一个concurrentHashMap同一时刻能有多少个线程执行,默认根Segement数量来的,即Segement[0-7]:就会可以实现8个线程同时执行。默认是16.也就是Segment数组默认初始化是16
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
//注意这里ssize是大于concurrencyLevel的第一个2的次幂的结果:
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
UNSAFE。putOrderedObject就是在Segment数组生成完毕后在数组的第一个位置存放了一个Segment对象:将Segment对象s0放入Segment数组第一个位置。
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
//注意这里ssize是大于concurrencyLevel的第一个2的次幂的结果:
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;

注意Segment继承了ReentrantLock.同时在JDK1.7中Segment还包含Entry数组:
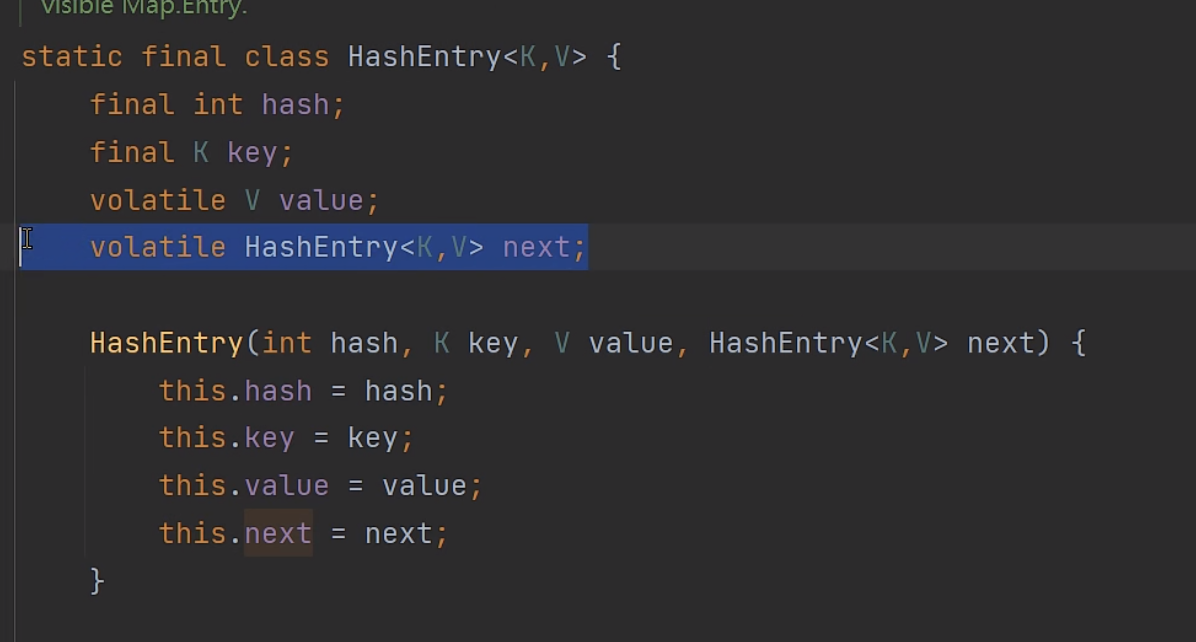
还有再来看一下生成Segment对象的三个参数:
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
注意其中会先生成一个HashEntry,会给这个数组默认的大小为cap,按照我们想法,我们在进行构造函数的时候会有一个initialCapacity代表所有Segment[i]中的Entry个数加起来等于16,而且concurrencyLevel默认也是16,也就是很容易得到每一个Segment[i]中默认的Entry数量应该是16/16=1,但事实真的如此吗?
int c = initialCapacity / ssize;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
{
cap <<= 1;
}
注意我们还是要保证数组的长度是2的次幂, MIN_SEGMENT_TABLE_CAPACITY长度是2,就是我们首先算出来c =1,此时cap = 2,而2不小于1,则初始化HashEntry的大小为2。
注意这里还有向上取整的过程,假设此时给出initialCapacity,而concurrencyLevel给的是4,那么会走下面的代码:
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
{
++c;
}
如果没有这一步话最后的cap就等于2,而此时concurrencyLevel等于4也就是最大的容量只能到2*4=8。而我们给出的最大容量是initialCapacity就会使程序产生错误。因此向上取整这一步尤其重要。使得在经过while(cap<c)后拿到的cap为大于c的最小的2次幂就是4。
接下来就是put方法:
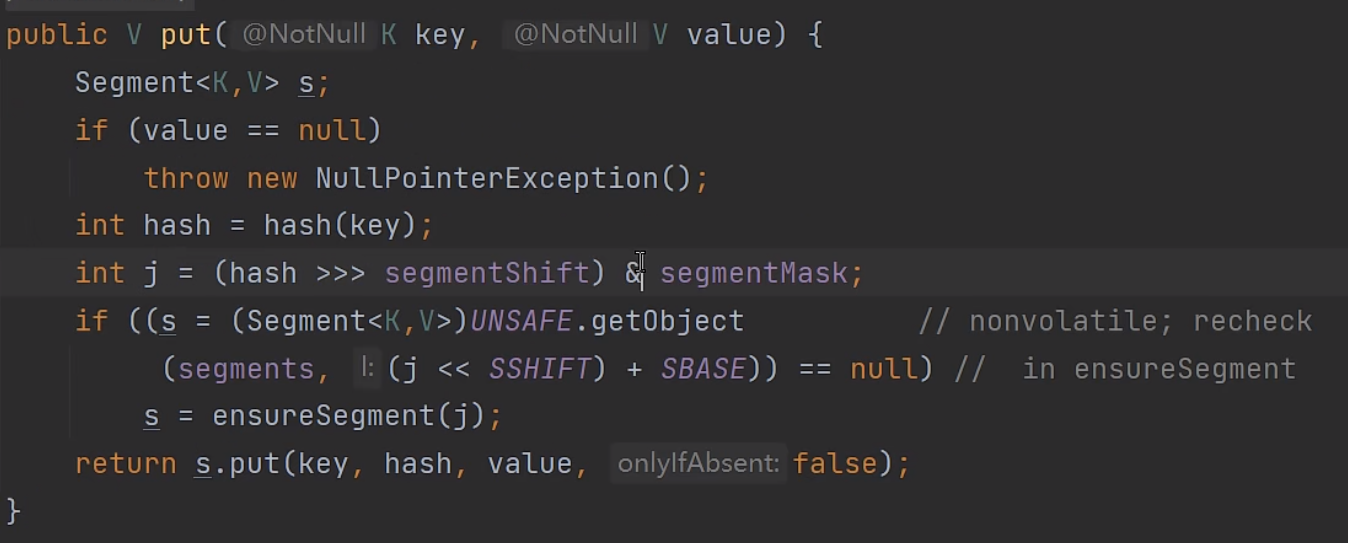
int j = (hash >>> segmentShift) & segmentMask
这一个步骤其实根HashMap类似就是算出key所对应的存放在哪一个Segment数组下标当中。

然后会去查看当前Segment是否有无对象,有就会调用Segment的put方法,如果没有就会去创建。
ensureSegment方法:
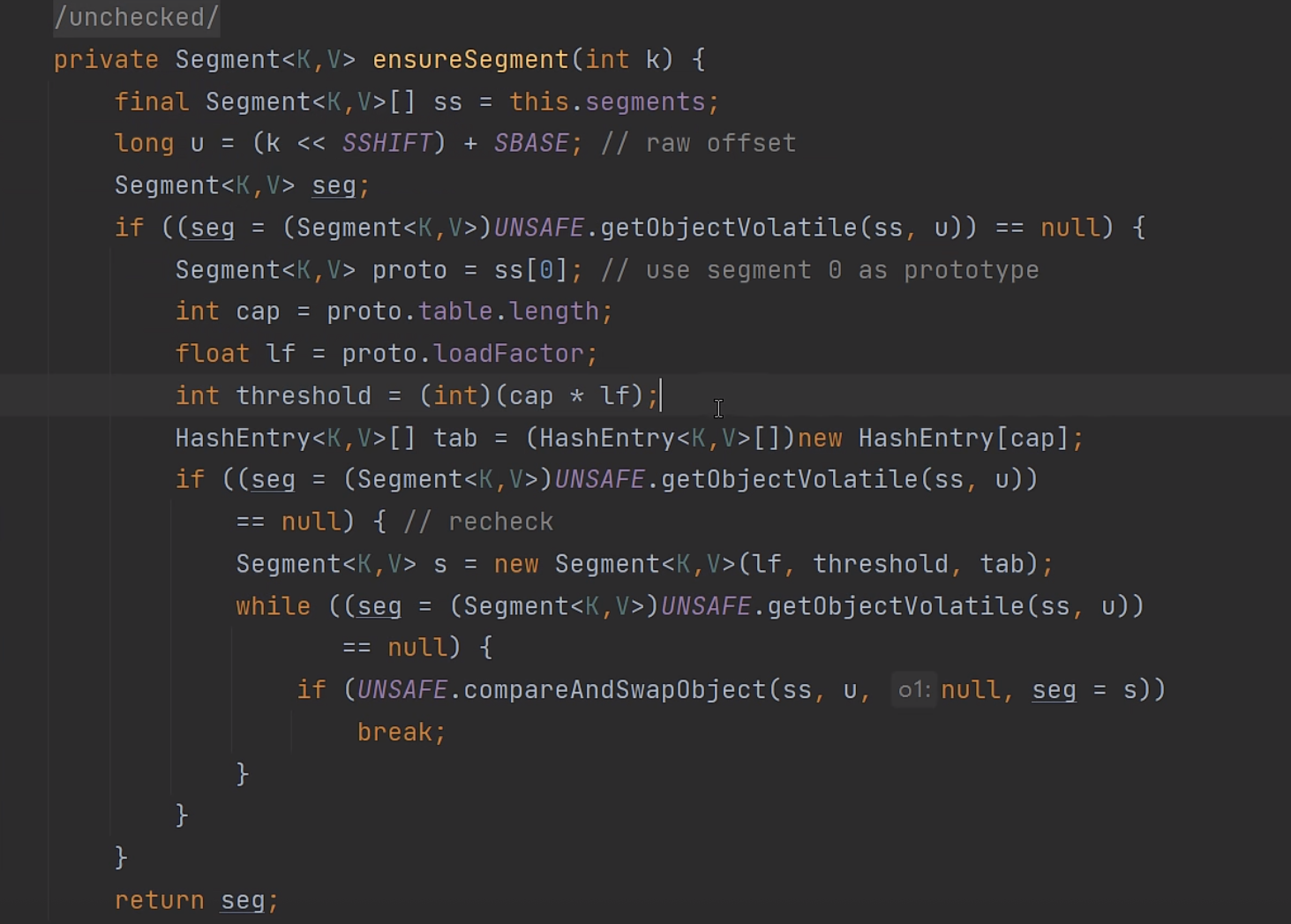
注意因为在多线程并发时候我们发现在ensureSegment前后并没有保证线程安全的锁机制等等。注意以下的if逻辑:,此时的if判断根外层的判断一样,也就是判断第j个位置是否为空,此时为什么又要判断以下呐?
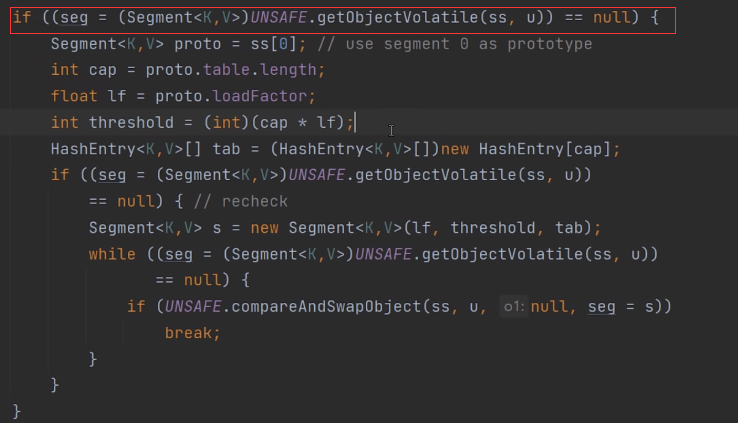
其实就是双重判断。
那么接下来就是当多个线程都判断此时为null时候,则进入该if判断,那么就是自己想办法创建Segment对象:
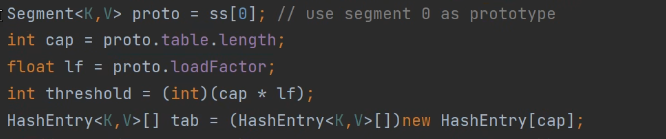
注意在构造ConcurrentHashMap时候第一个位置我们已经看到了它是自动初始化构造一个Segment对象,因此我们拿到然后从其中获取相应的Segment信息,注意在做完上面5步以后又会重新判断if条件:
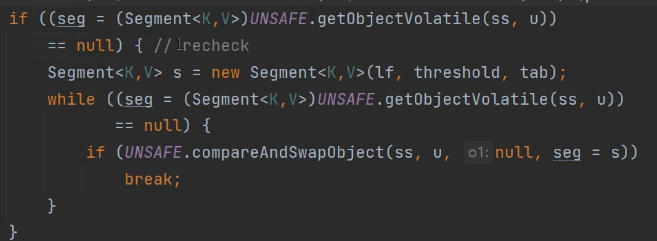
注意在此时if判断还为空的时候才会生成一个Segment对象。此时就会涉及到并发编程里比较重要的点了就是CAS:
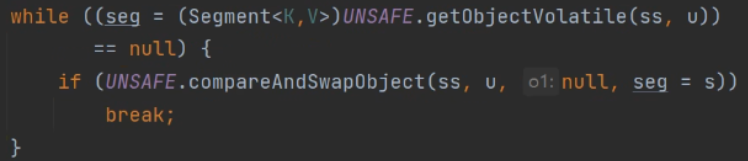
采用CAS其中五个参数就是在整个ss的Segment数组当中,将s赋值为seg然后如果第u个位置为null就进行赋值,如果判断不成功就break。
此后直接return 返回seg结果就可以了。
在Segement创建成功后,就会进入put方法:
注意put方法当中比较重要的就是加锁的方法,其他的方法与HashMap方法类似。
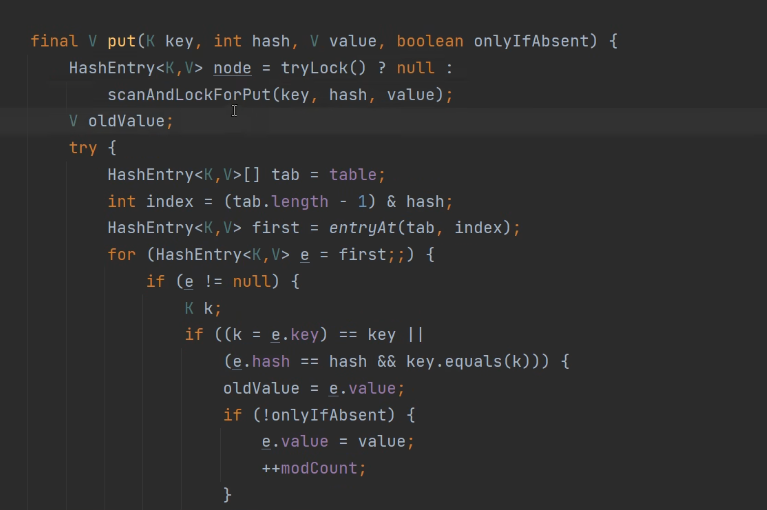
tryLock方法:
tryLock与lock最大的区别就是在阻塞,当tryLock方法调用后会直接判断能否加到锁,能加成就执行 锁中的代码,加不到也不会阻塞。没有加到锁就会去执行scanAndLockForPut方法:
对于该方法含义就是在等待锁的时候就是自旋时候可以求得对于key应该放在Entry数组的什么位置。注意此时有可能不需要创建Entry对象,因为可能存在多个key相同,只需要替换val就可以。所以在等待锁时候还会遍历链表看是否与key相同的Entry,有则不需要创建Entry。
while循环就是自旋锁,注意此时的while中的代码可做可不做。
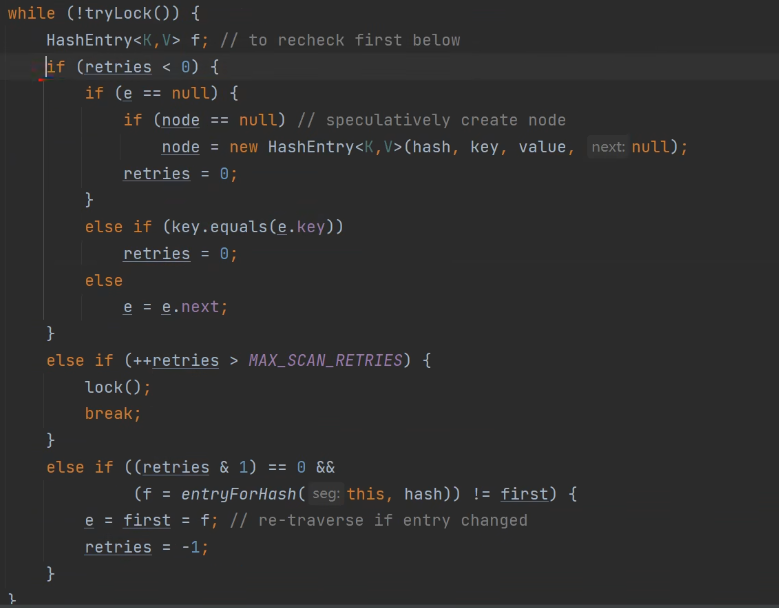
(1)第一个if判断:
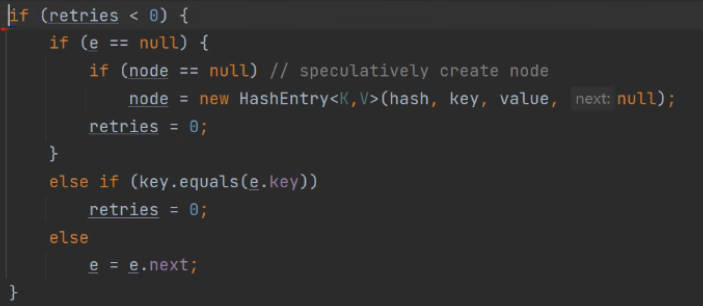
注意在上面还有对于first的赋值,这个时候first赋值其实就是在HashEntry中拿到看是否有与当前插入Entry相同的key对应的链表的第一个结点,此时first可能等于null也有可能不等于null,first会赋值给e。所以在第一个if判断当中有e是否等于null判断 。e为空代表遍历到链表的尾部。同时会判断链表中是否会有结点的key与插入的Entry的key是否相等。如果链表中都不存在与Entry的key相同的结点,等到遍历到e == null就会生成对应的Entry结点。
(2)第二个与第三个if判断:
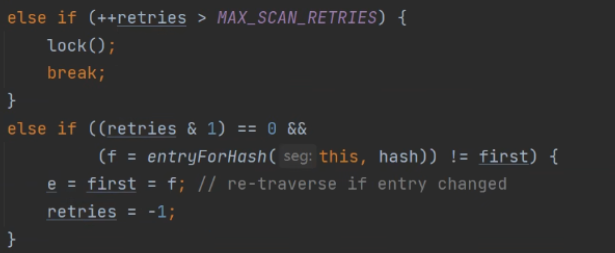
当发现链表中没有Entry的key与插入的Entry的key相同时就会进入到第二个if判断当中,此时因为该做的事情都做完了,因此此时会空转CPU,但也不会一直空转,这里的MAX_SCAN_RETRIES就是获取CPU的核心位数,当时64位时候,会空转64次,进而将该线程阻塞住。第三个if判断就是当在retries是偶数的时候会与1做与操作后得0,然后会判断之前那拿到得头节点与当前得头节点是否相等,如果不相等说明该链表可能被修改过,此时可能在HashEntry中由别的线程插入了与Key相等的结点,因此会将retries置为-1然后进入第一个if判断进行审查,审查的前提条件是还未获取到锁。
3.2 JDK1.8中的原理:
数组+链表+红黑树,并且是并发安全的。注意在JDK1.8中不再有Segment这个概念了。
1.首先来看put方法:


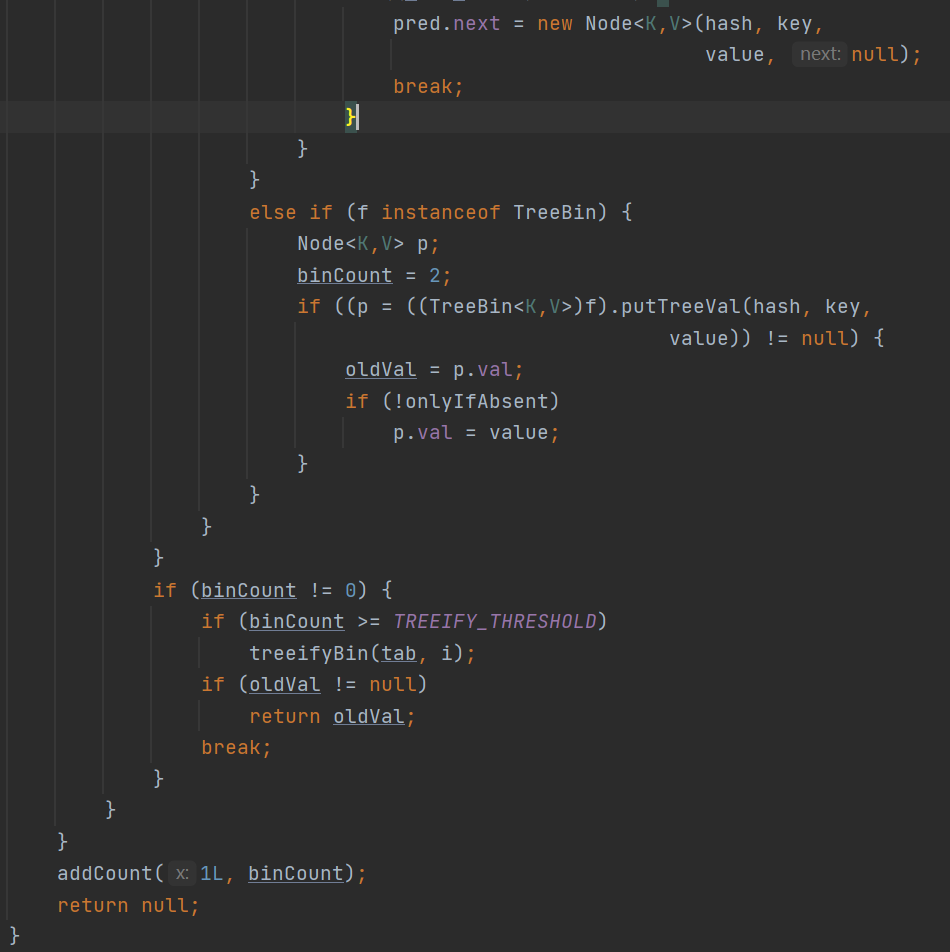
(1) 初始化一个Node类型的Table:iniTable()

一开始sc肯定是等于0的,采用CAS方式将sc减一。然后赋值n等于16。然后初始化一个Node数组,然后会直接赋值触发扩容的阈值sc=16-4=12。注意这里涉及到线程礼让性问题。就是为了放置一个线程并未获取到初始化的锁而导致不断进行while循环。
(2)如果Tab已经初始化过,但是所插入的tab[i]等于null,那么就会使用casTabAt方法进行对于tab[i]的赋值,这里的赋值是生成一个Node结点。

(3)如果上面两个if都走完后,那么走到下面这if时候对应的tab[i]一定是有值的,此时会判断以下是否等于MOVED,这个地方是在判断是否有别的线程对当前的ConcurrentHashMap进行扩容,如果在进行扩容的话就协助进行扩容。

(4)当上面扩容判断不成立后就需要插入元素了,但是需要注意这里要考虑并发安全性的问题。
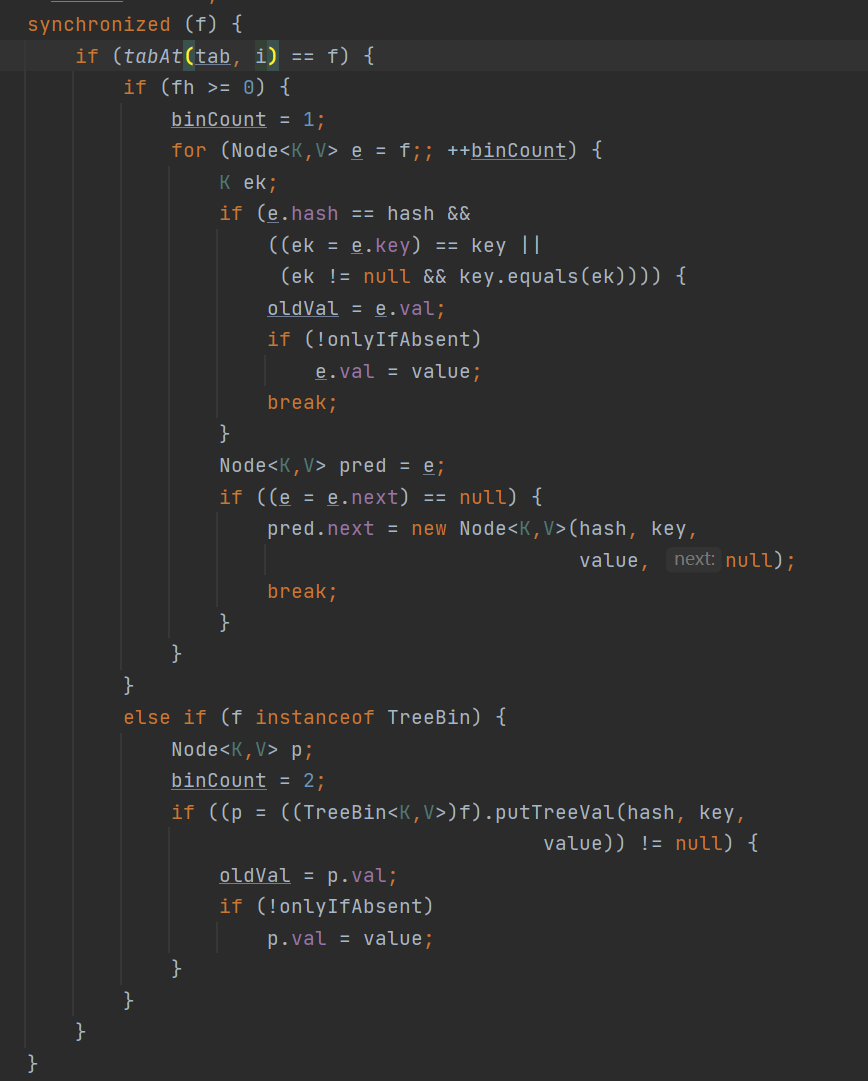
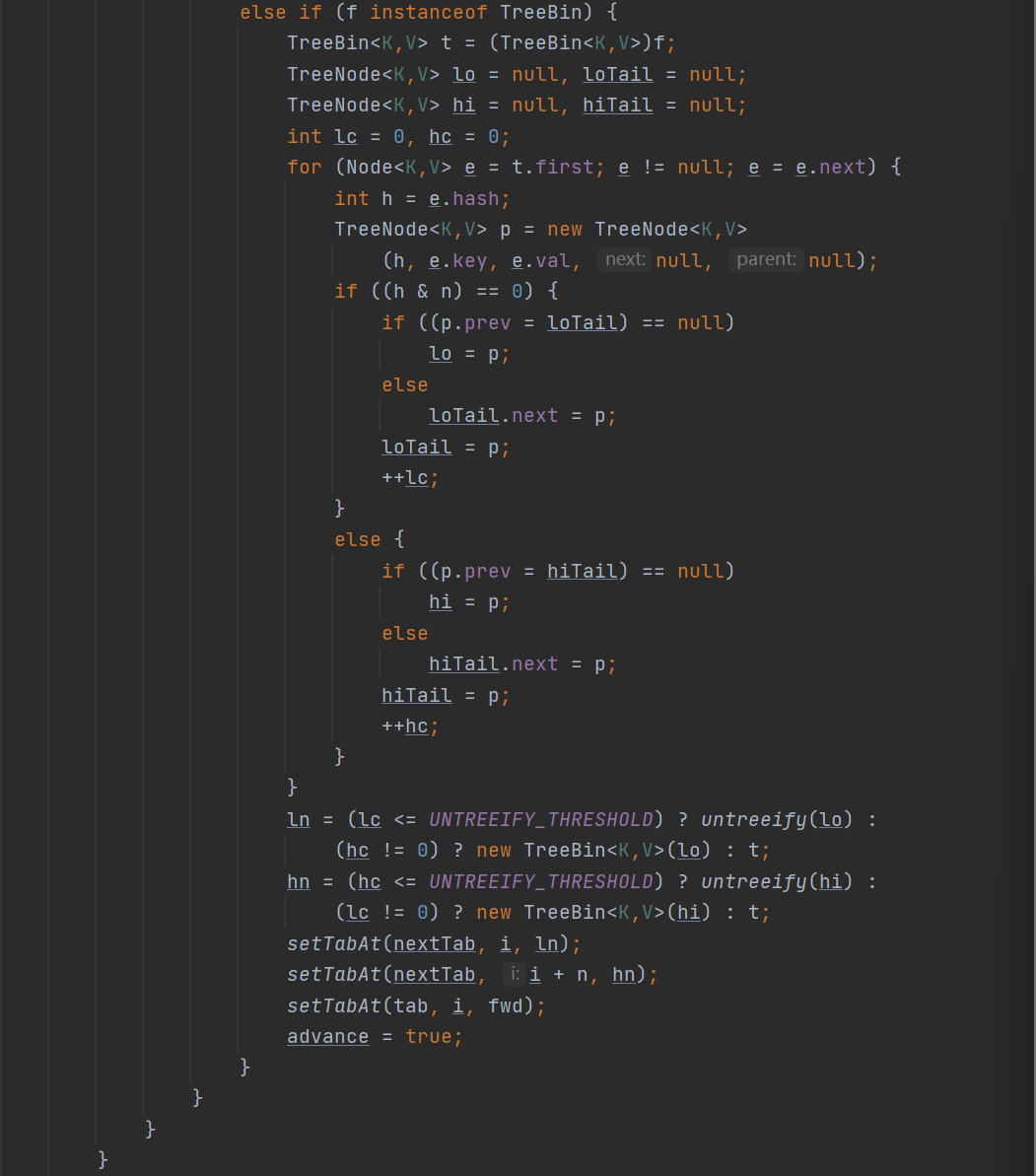
在拿到锁的时候,需要来判断一下当前的tab[i] 是否是原来的f,如果不是则需要拿到最新的头结点,因为在加锁过程当中很有可能有别的线程更改了头结点的值。如果判断相等后,就会区分是链表的插入还是红黑树的插入流程。 注意此时的红黑树的结点的类型是TreeBin。
首先先来看树化操作:treeifyBin:
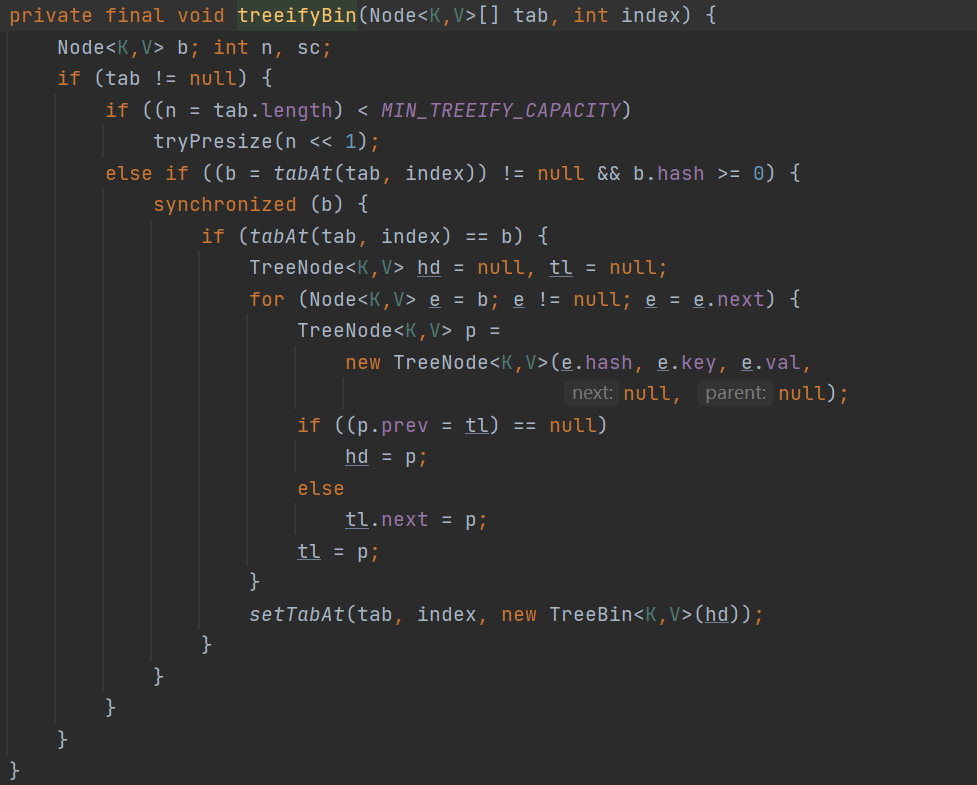
这里在树化的操作当中同样需要保证线程的安全性的问题,采用了synchronized。中间的逻辑其实跟HashMap差不多是将其先改成双向链表。
注意此时为什么采用TreeBin,TreeBin其实代表的是整个红黑树,因为我们知道我们在拿锁的时候拿到的是根结点作为锁的对象,但是在整个编程红黑树过程当中很有可能根节点不再是根结点,而是变成其他结点,此时锁的锁粒度就会出现很大得问题。因此采用将整个红黑树表示成为TreeBin。
接下来我们来看整个putVal最后的一个方法:addCount:

整个方法首先是将size进行+1,然后再判断是否进行扩容,扩容时候如果有其他线程到来,发现此时正在进行扩容,那么就会进行协助扩容。
注意在JDK1.8中的ConcurretHashMap中并没有size这个属性,取而代之的是baseCount属性。此外在ConcurrentHashMap中引入一个CounterCell是用来协助baseCount进行计数的。类似于ForkJoin的思想。
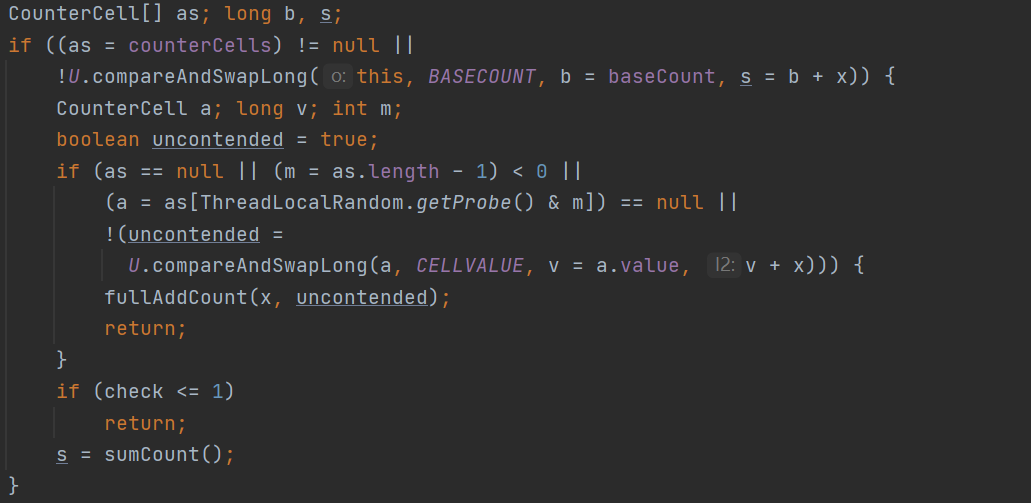
(1)首先对于baseCount进行CAS进行计数+1:
U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x))
(2)当CAS失败后,也就是这种情况,两个线程同时竞争将baseCount+1,但是其中有一个线程竞争失败,那么此时便会启用CounterCell:
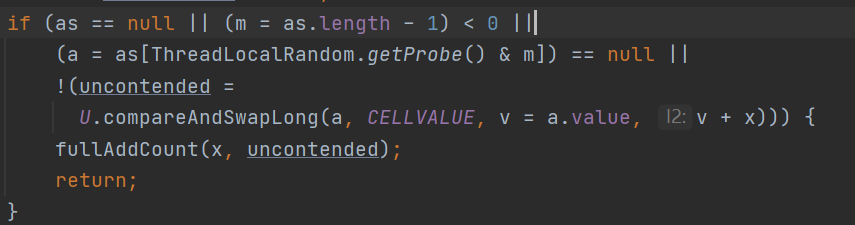
a = as[ThreadLocalRandom.getProbe() & m])
注意当CounterCell不是等于null的时候,会首先获取到CounterCell的长度然后减一赋值给m。然后对于每一个线程会使用ThreadLocalRandom与m进行与运算求得到CounterCell的一个位置。此时解释下if判断的逻辑:
1.当发现如果as==null,那么就说明CounterCell还未初始化,那么fullAddCount就会完成初始化操作
2.如果不等于null,此时如果拿到的进行与运算后的位置等于null,也会直接进到fullAddCount当中。
3.如果拿到位置不等于null,会首先进行CAS操作,CAS操作成功就不会进入到fullAddCount当中也就是说在CAS中已经完成对于CounterCell的val进行加一操作了,如果CAS不成功的化还会进入到fullAddCount中。
那么接下来就来看fullAddCount逻辑:整个这个方法的逻辑是在一个for循环当中:
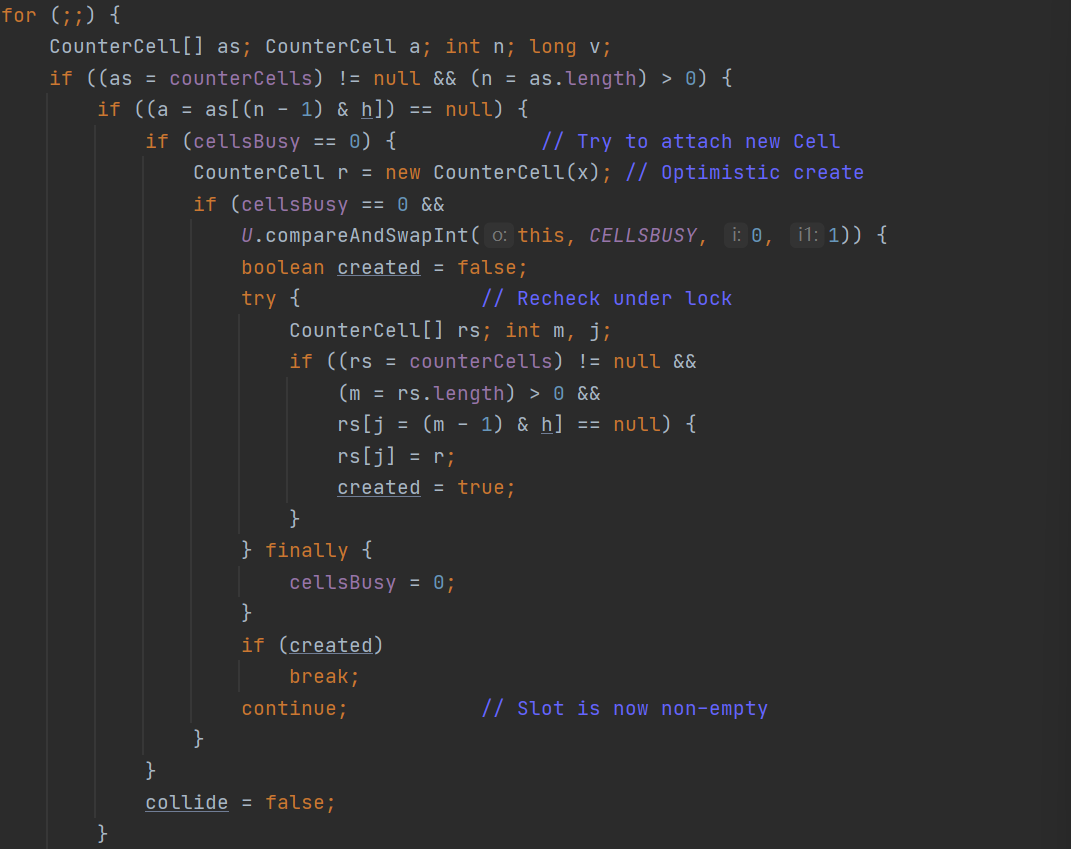
这段代码的逻辑就是会首先拿到应该存放在CounterCell什么位置就是对应的a值,此时来判断cellsBusy是否等于零,如果是零会初始化一个CounterCell,然后会进行CAS判断将当前对于CounterCell的操作改为CELLSBUSY。接下来的逻辑就是要将生成的CounterCell的r对象放到CounterCell数组当中。然后再将cellsBusy改为0。
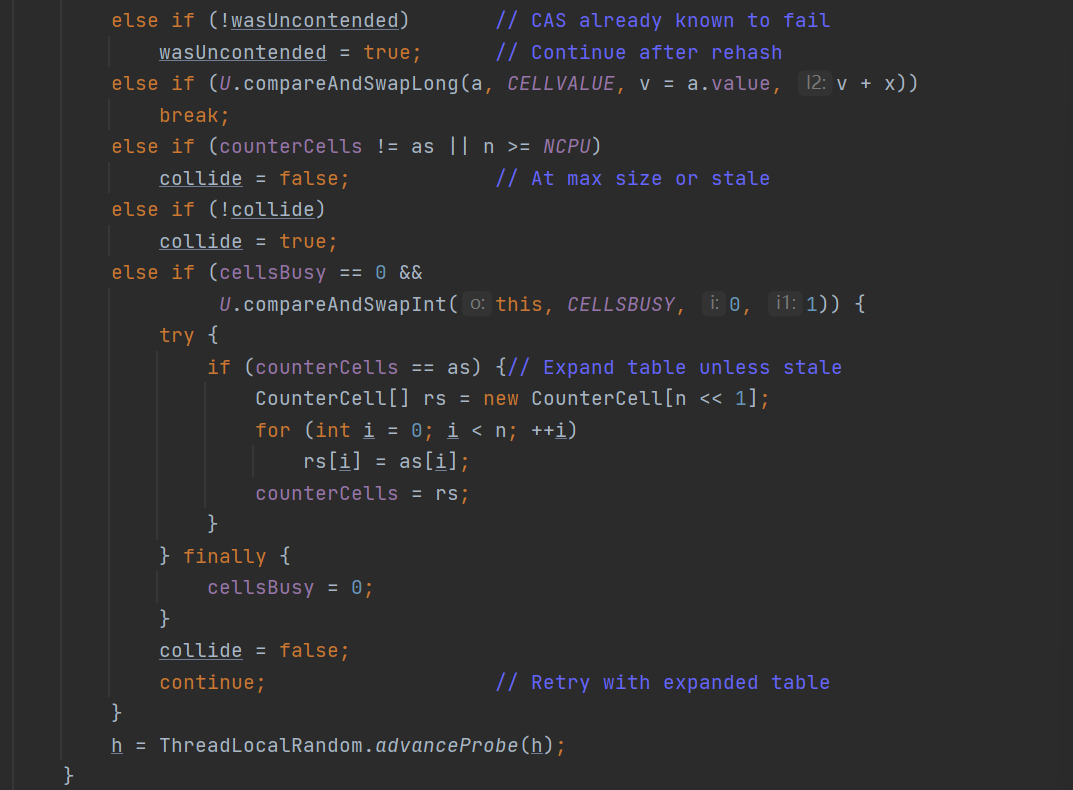
线程会进到以上的if判断的条件是,当前判断插入的位置是存在counterCell对象的。也就是(a = as[(n - 1) & h]) != null成立。对于wasUncountended传递过来的是false值,因此if判断会成立,因此此时wasUnconteded就会被赋值成为true。此时便会进入到h = ThreadLocal.advanceProbe(h)方法重新生成一个hash值,因为此时最外层的循环是一个for循环,因此会再次进入到第一个if分支当中进行判断,如果此时判断成功就会进行赋值,如果不成功就会进入都第二个if判断,此时我们知道wasUncontened已经成为了true,那么很显然第二个if判断也不会成功。则进入到了第三个if判断。此时的就会CAS对于当前的CELLVALUE进行+1判断。如果加成功就会break。如果没有加入成功便会进入到第四个if判断当中。此时第四个if判断很难理解,包括第五个判断,所以我们先来看第六个判断,此时第六个判断当中会涉及到对于原始的counterCells进行扩容的操作,将容量扩充到原始的两倍。那么反推一下我们可以知道只有第四个与第五个if判断不成立才会走第六个判断,那么第四个判断与第五个判断做的事情应该是将控制可以进入第六个判断从而使得CounterCell进行扩容操作。那么就是当collide等于true时候会进入。我们纵观整个fullAddCount代码只有第五个if将collide改成了true,因此我们理顺一下逻辑:
也就是对应的两次for循环所查找的对应的CounterCell位置都不为空(注意此时可能两次查找Hash值是同一位置,也有可能是不同位置,但不管怎么样只要是两次都是不为空就会进行扩容)。那么便会进入到了第四个与第五个判断。使得此时的collide等于true。再次进行
h = ThreadLocalRandom.advanceProbe(h);后进入到for循环当中后就会直接走第6个if判断进行扩容。但是扩容是有限制的,不是无限次进行扩容的,这这判断条件就是第四个if判断的条件,当counterCells !=as 同时 n>=NCPU时候。就是当发现counterCells不等于as时或者n就是数组大小大于CPU核心数也就不会进行扩容了。
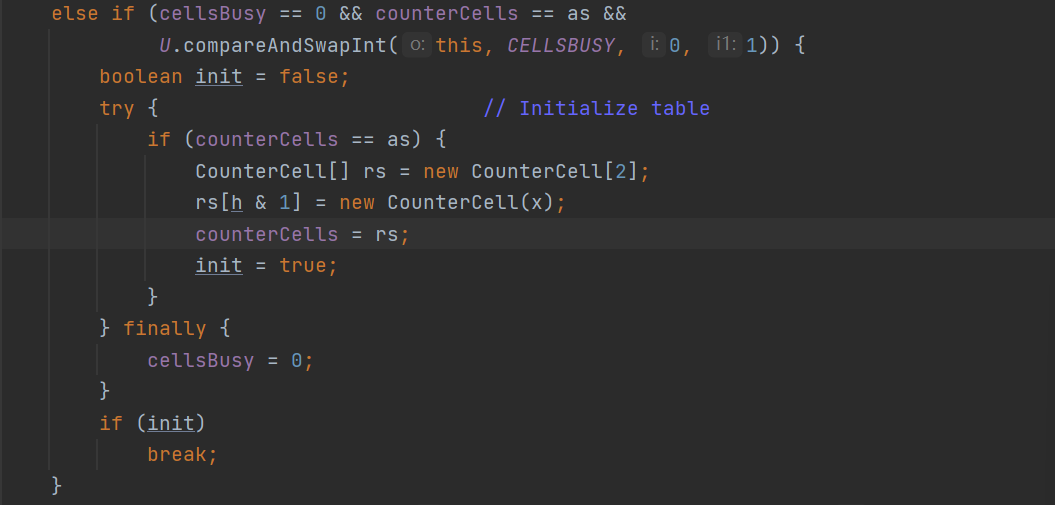
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
...
}
如果CounterCell等于空,会首先判断cell数组是不是在用,如果没人用就是cellsBusy等于0。然后利用CAS操作将CELLBUSY属性由0改成1,表示有线程在使用CounterCell进行初始化的操作。接下来就会初始化一个长度为2的CounterCell数组。
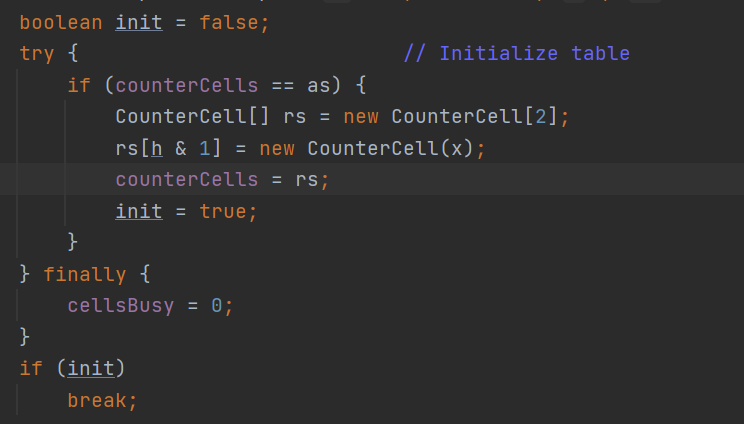
如果上面的if判断没有走,也就是如果两个线程并发进行对于CounterCell进行初始化,必定其中有一个是不成功的,所以便会走到下面的if操作当中,也就是失败的线程会对于baseCount进行CAS操作。

接下来就是要将ConcurrentHashMap的扩容的逻辑了:
还是在addCount方法当中:
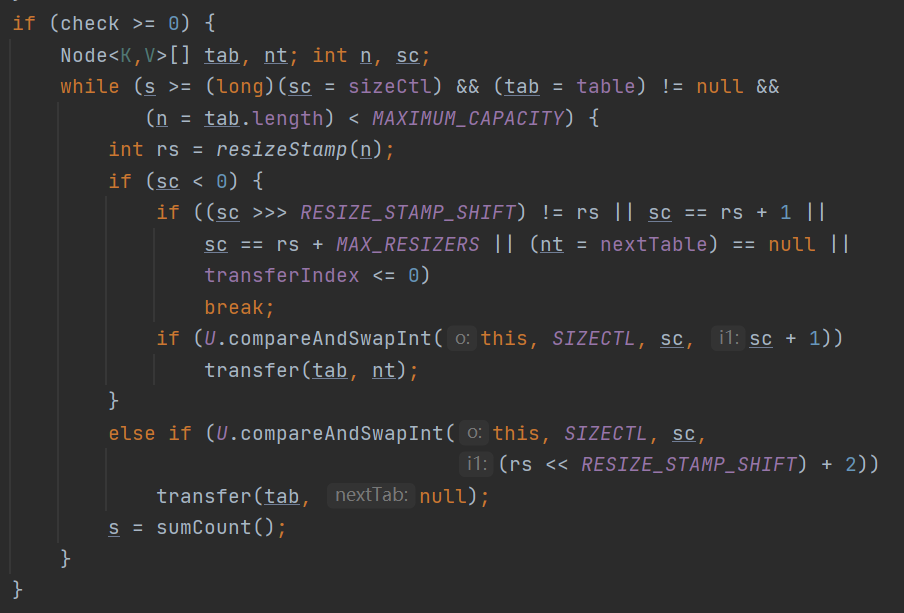
concurrentHashMap扩容的原理:
1.新建一个数组,并且数组大小是原来的两倍,oldTable与newTable同时
存在,然后进行迁移数据
2.会首先设置一个步长:假设是步长等于2
单线程:从后向前进行数据的迁移步长是2
多线程:A与B两个线程,相互协作找寻未在转移的数组部分进行转移
3.此时还会有一种情形是,当线程将老数组都转移到新数组上面来了后,
因为在转移过程当中可能新数组也有不断再插入的过程,当老数组全部
转移完毕后导致新数组又要触发扩容机制。
接下来是源码流程:
当进入到check>0的流程当中后,我们因为在initTable方法当中设置过了sc的值默认阈值是12,那么进入到while循环后会直接走else if逻辑:
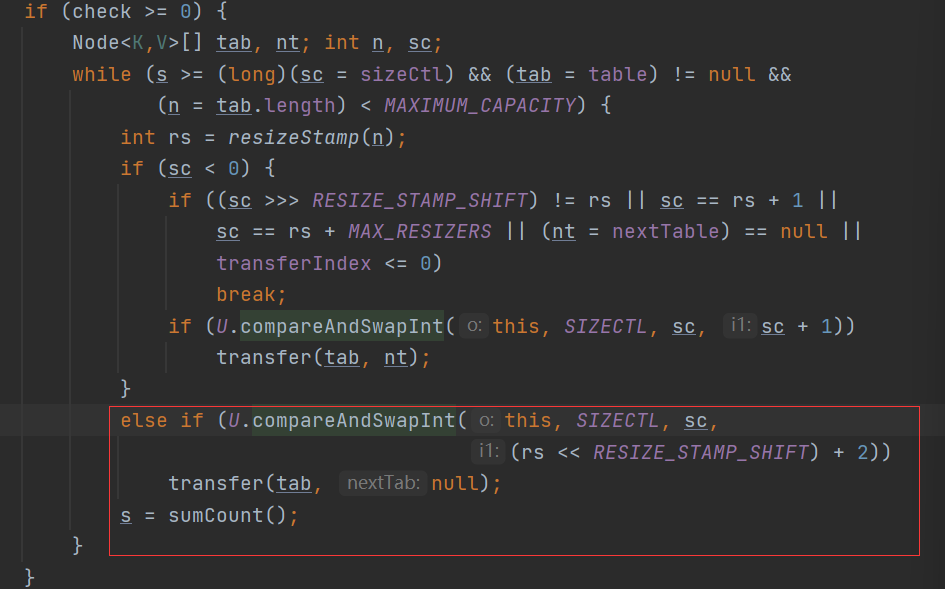
此时注意有个算数:rs << RESIZE_STAMP_SHIFT,此时这个算数我们只要知道算出的结果是一个很小的负数。那么加2以后所得结果也是一个很小的负数。对于else if 判断逻辑就是通过CAS,只有一个线程会将sc改成一个很小的负数。那么此时有一个线程进入到transfer方法后:这个方法中的逻辑相当的复杂:
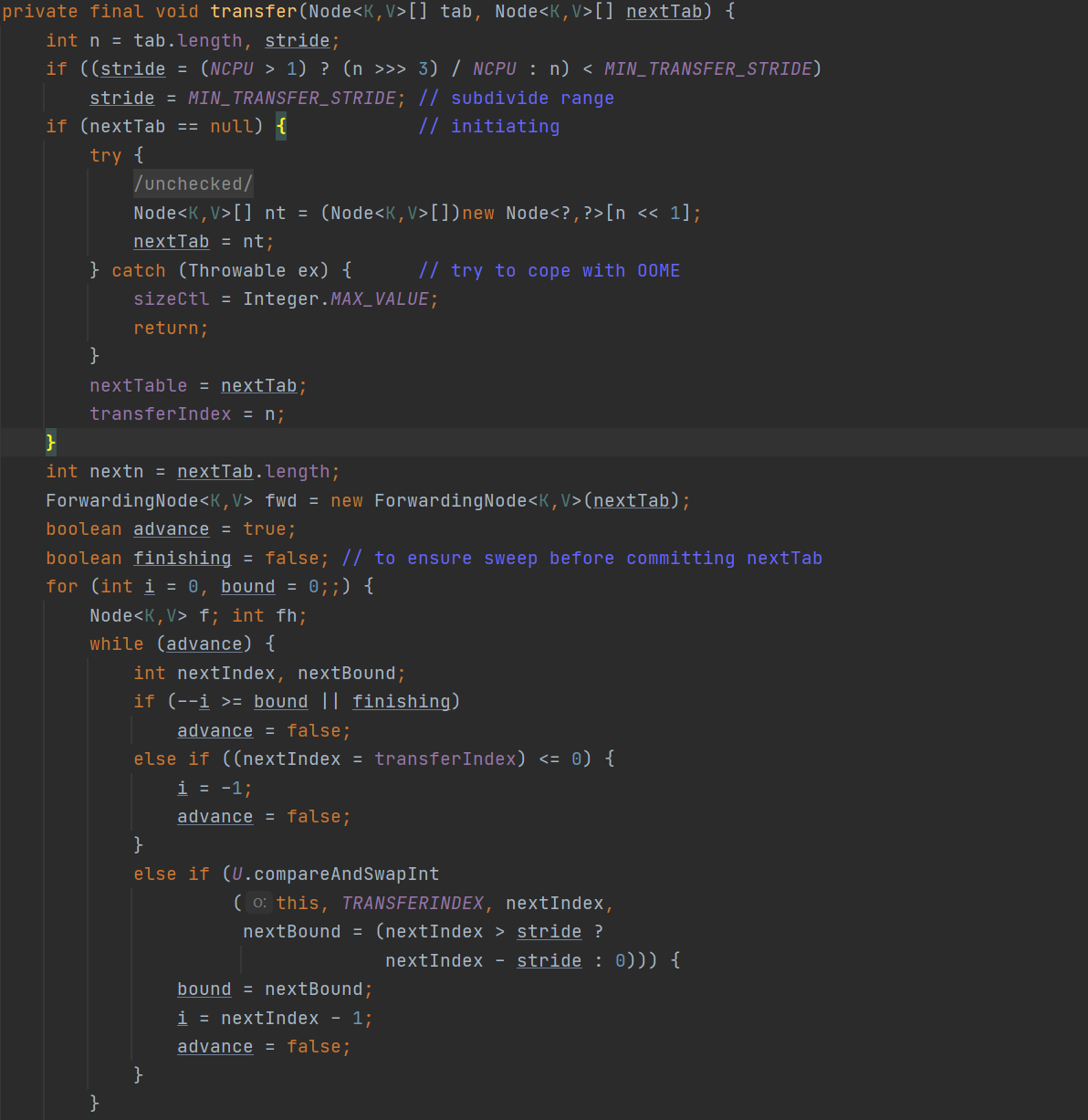
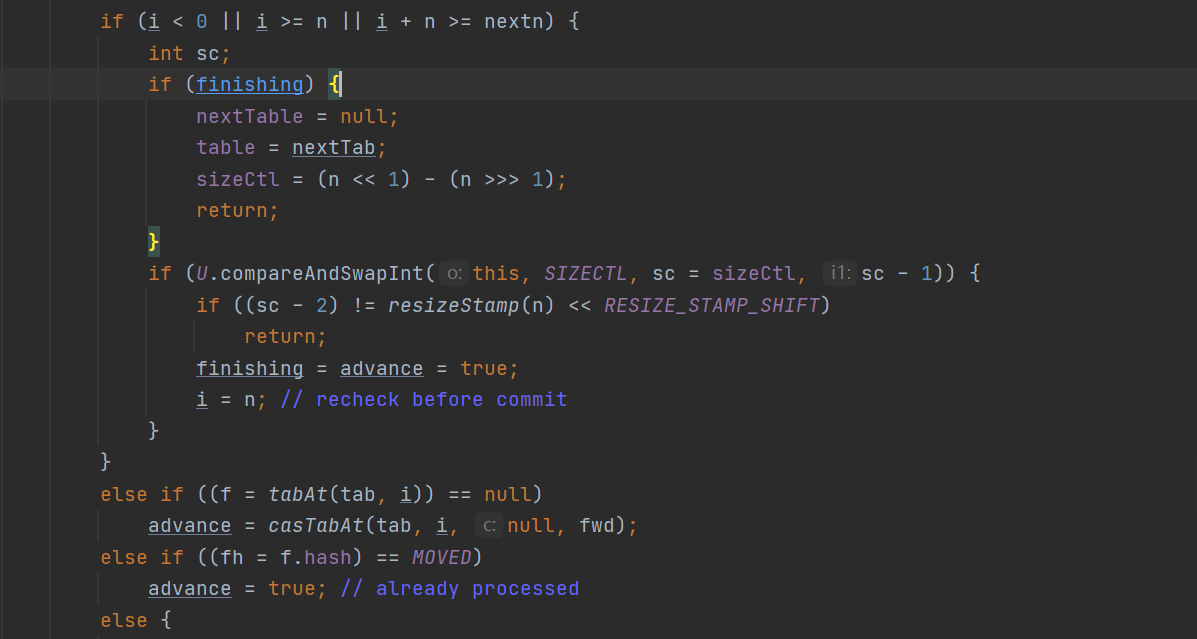
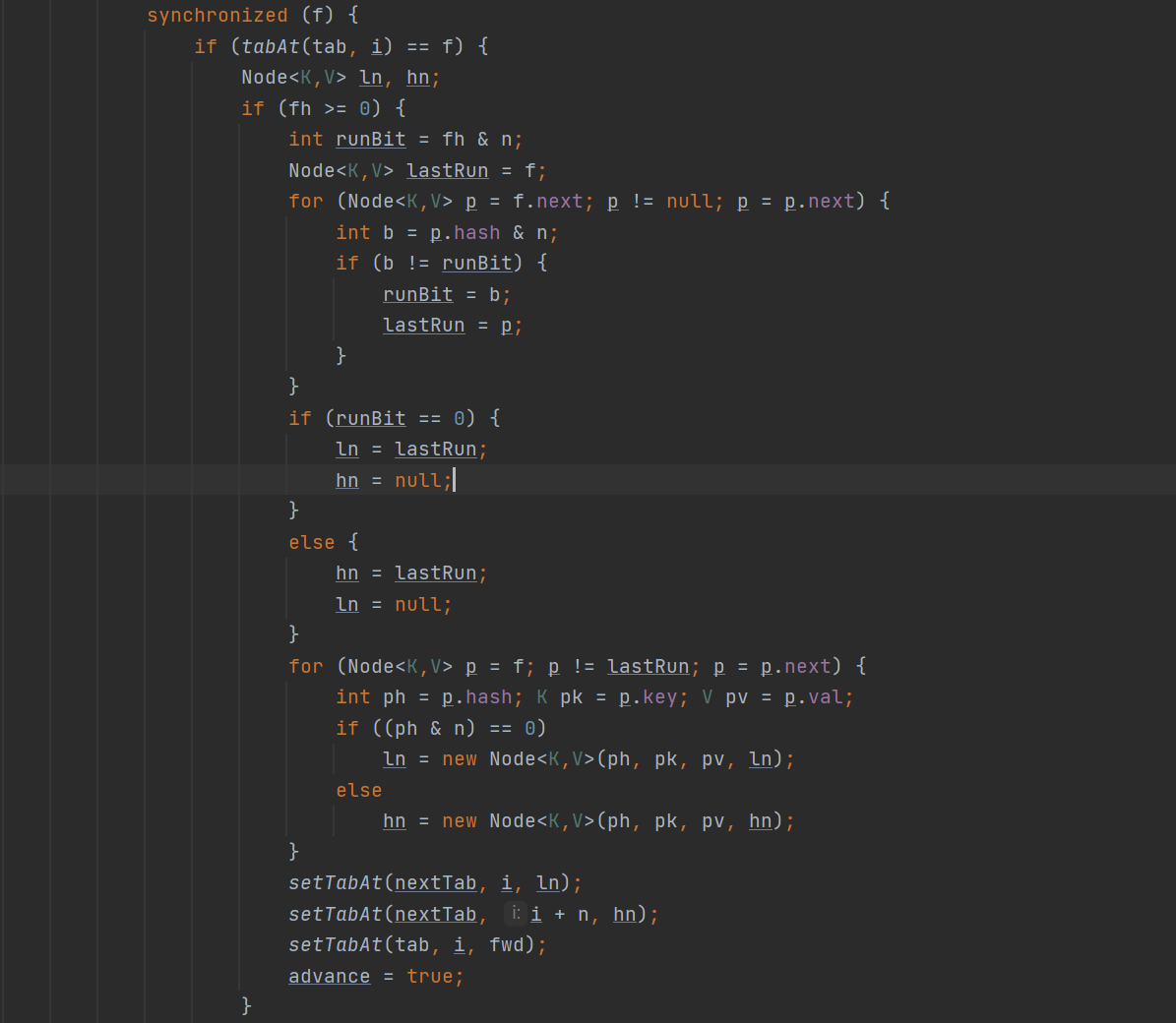
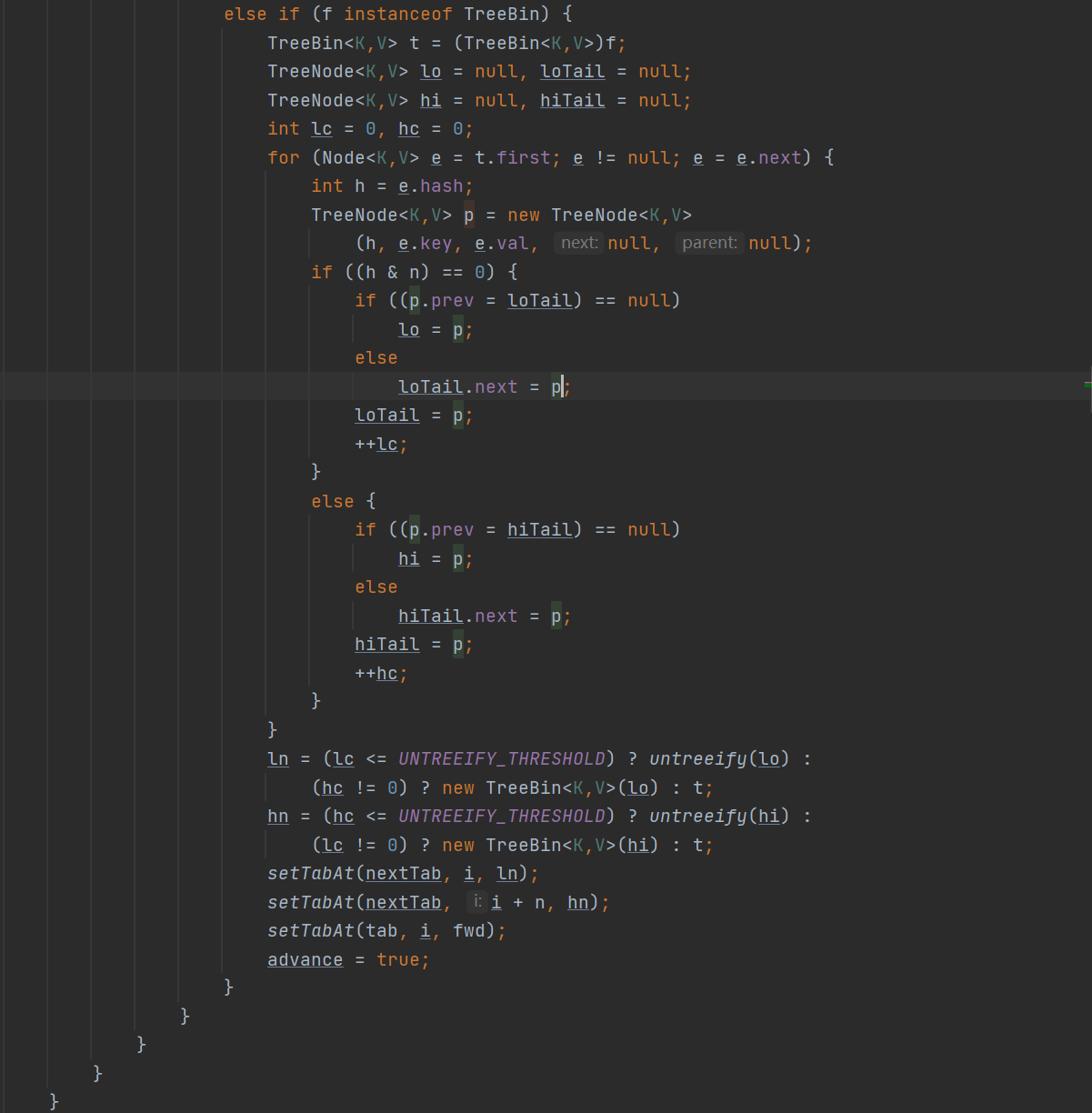
1.首先会算出步长:

2.然后创建新的Node数组:
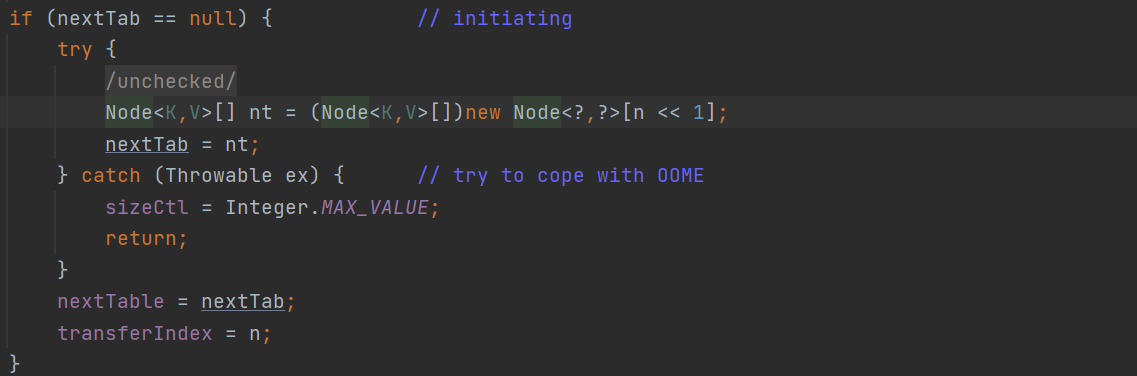
在创建首期,transferIndex会赋值为原始的tab的长度。
3.接下来就会进行扩容的逻辑,在扩容的时候会有一个ForwardingNode类型的对象生成,这个对象的生成的作用是,当数组在进行扩容的时候,生成的ForwardingNode会占据原始数组的Node位置,当有另外的线程来进行put时候发现数组正在进行扩容发现这个ForwardingNode就会进行协助扩容。

4.接下来会有两个变量:advance与finishing:

advance就是用来判断例如线程A将元素的某一位置元素已经转移成功了,那么原始老数组中在数组从后往前中还需不需要线程A再对某一位进行转移。这个变量会在协助扩容时候用到。finishing用来判断对于当前线城是不是所有的扩容工作都完成了。
5.接下来就进入一个for循环,初始化一个 i 一个bound。
(1)首先会进入一个while循环:
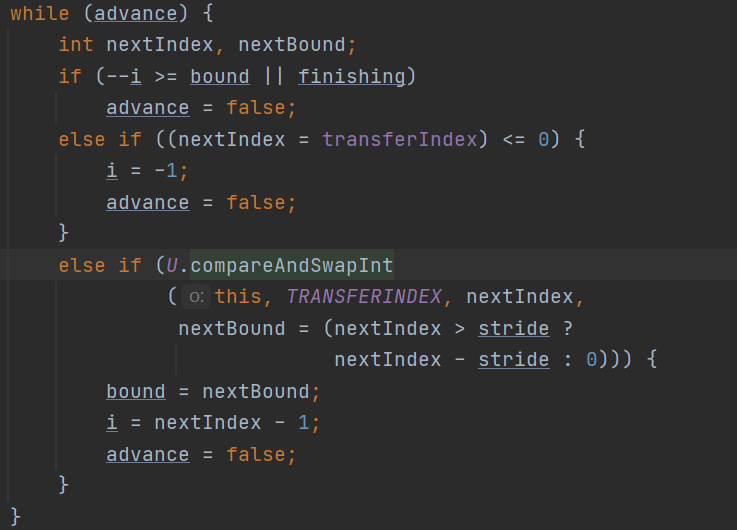
一开始进入while循环:
一开始第一个if,第二个if都不会执行,因为一开始i等于0,i--等于-1小于bound同时finishing设置为false,而nextIndex一开始赋值为transferIndex等于原始的table的长度,也不小于零,那么便会进入第三个if,这个时候如果一个CAS成功会修改TRANSFERINDEX的值,并且如果nextIndex = transferIndex,那么便将其修改成为nextBound,而nextBound是使用老数组Table的长度减去步长得出的结果,然后bound会等于nextBound。
给出一个原始的Table长度等于4的例子,然后经过第一次while循环并且CAS成功后的结果:
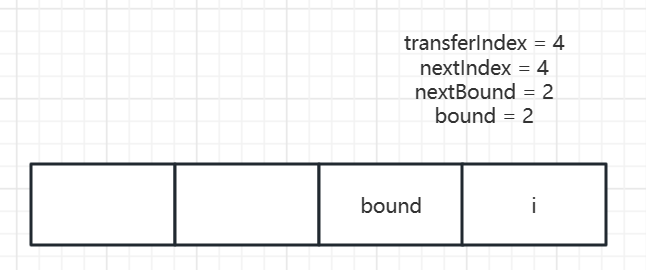
此时会赋值i = nextIndex - 1 = 4 -1 = 3,advance会赋值为false并跳出while循环。
6.当跳出while循环以后:
首先一开始第一个if不会成立,也就是下面的if判断:
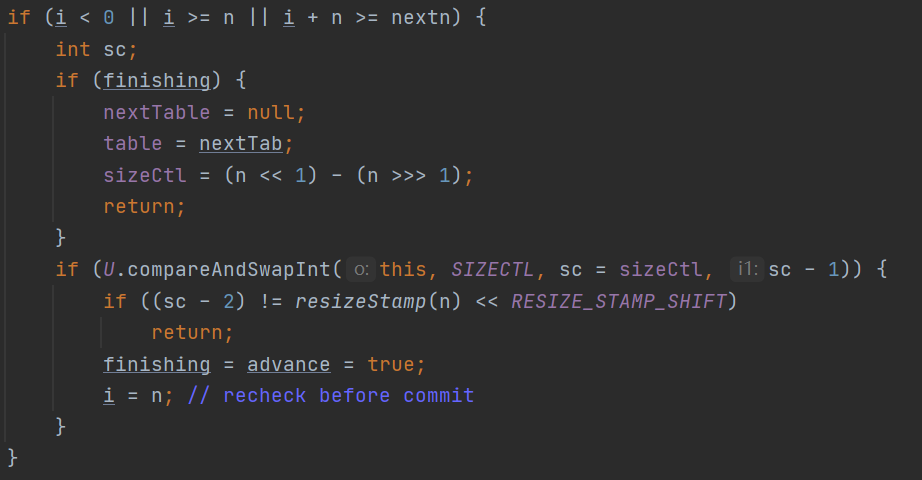
会首先进入接下来的几个if分支:

这一个步骤就是使用cas将i位置原始的结点赋值给f,同时如果判断对应的table[i]是等于null的将其赋值成fwd结点,赋值成功以后advance等于true。

上面这个if判断就是严谨的一个if判断,就是会判断在转移过程当中的结点是否在进行转移,如果在转移也将advance等于true。注意在这个advance被赋值成为true后,又会走到上面的while循环当中,此时也只有CAS的if逻辑会成立。说白了,逻辑其实就是这样,每一个线程冠自己步长内部的原始老结点的扩容转移操纵,操作完毕后进入while循环又会再次寻找可以转移的部分一次类推。
接着当当前的结点不等于null,也不存在转移的时候就会走走下面的if逻辑判断:
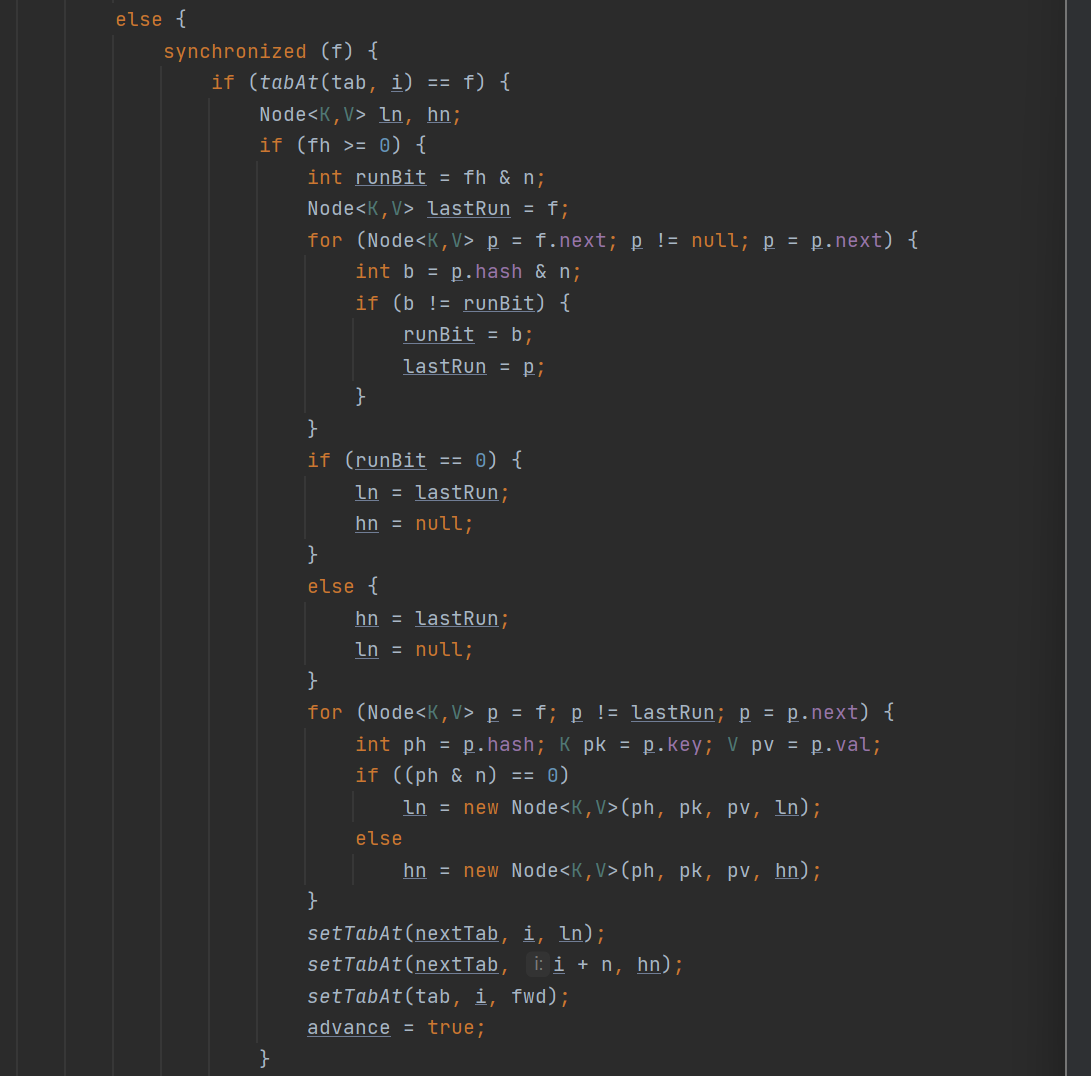
正常的就开始进行扩容转移的操作了,此时是不能够进行put的,而且全部转移的过程当中新table也是不够使用的,因为还未出现赋值的情形。整个转移的过程分为链表的转移以及红黑树的转移的过程与JDK1.8的HashMap相同。在转移完后将转移的老结点位置改为fwd,与advance改成true。
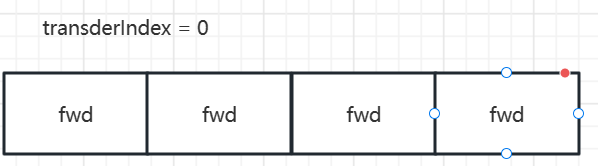
下面介绍边界的情形:transferIndex永远是比 i 大1 的:考虑下面的情形:
(1)当时单线程的时候,此时transferIndex等于0是什么情形,就是线程已经将所有的元素扩容迁移到了新的table上了:
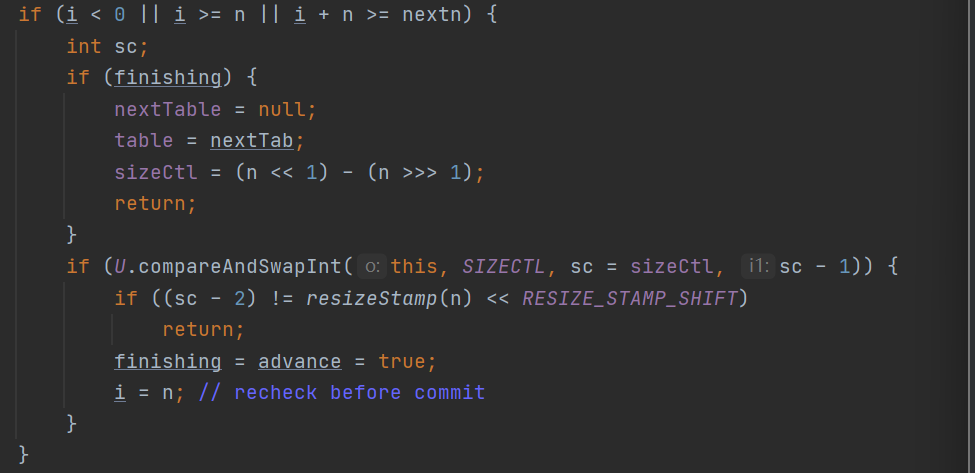
此时再进入while循环会触发第二个if的判断:

此时会将i设置成为-1,advance等于false。此时当while循环跳出以后会触发我们之前都没有触发的if逻辑:
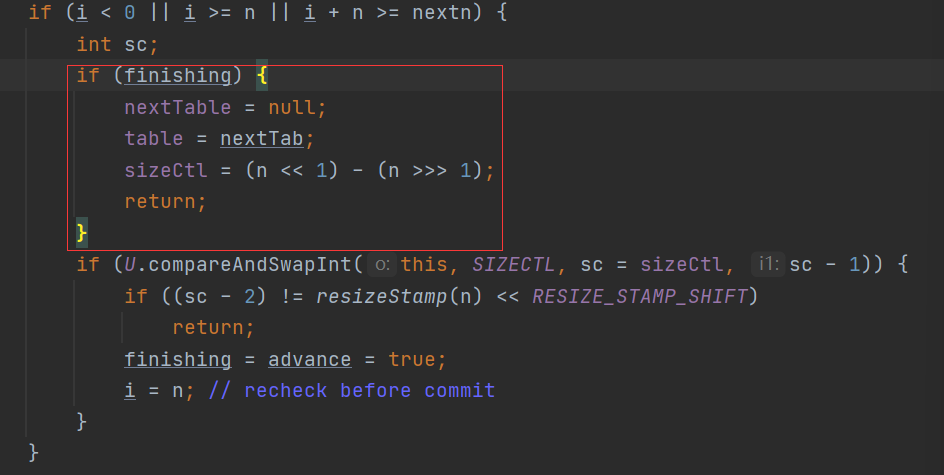
第一次进来以后会发现fininshing等于0,此时便会进入第二个if判断的逻辑:
这个if判断会很绕,其实大概的意思就是,每当一个线程来协助进行扩容的时候sc都会加1,有三个线程协助扩容,那么sc = sc+3,而当一个线程扩容完毕后,会对sc进行减1,这个其实就是判断当一个线程扩容完毕后是否还有其他的线程在协助进行扩容,如果有则(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT是成立的,那么就会返回return。如果没有那么就会赋值finishing = true。此时又会进入到上面的while循环当中此时第一个if判断成立使得advance = false.接下来又会进入到下面这个if判断当中,同时会触发第一个if逻辑,并且将新的Table扩容后的Table进行赋值,然后返回。
- ConcurrentHashMap 底层 HashMapconcurrenthashmap底层hashmap concurrenthashmap hashmap null concurrenthashmap原理hashmap concurrenthashmap hashmap concurrenthashmap amp hashmap concurrenthashmap arraylist hashmap 数据结构concurrenthashmap原理hashmap hashmap concurrenthashmap线程hashtable concurrenthashmap hashtable之间hashmap concurrenthashmap null hashtable hashmap