探索浏览器内部
本章看点
1. 浏览器如何解析网址;
2. 浏览器请求消息内容;
3. 向 DNS 服务器查询 Web 服务器的 IP 地址;
4. DNS 服务器接力查询;
5. 浏览器委托操作系统将消息发送给 Web 服务器的过程;
1 生成 HTTP 请求消息
1.1 URL 的种类
虽然我们通常是使用浏览器来访问 Web 服务器,但实际上浏览器并不是只有这一个功能,它还可以用来在 FTP 服务器上上传和下载文件、发送电子邮件、浏览 PDF 文档等等功能。 而到底是使用哪种功能来访问响应的数据,就需要各种不同的 URL 来告诉浏览器。下图列举了现在互联网中常见的几种 URL,根据访问目标的不同,URL 的写法也会不同。 
尽管 URL 有各种不同的写法,但它们有一个共同点,那就是 URL 开头的文字,即“http:”“ftp:”“file:”“mailto:”这部分文字都表示浏览器应当使用的访问方法。 本书主要讲解的是访问 Web 服务器的情况,所以主要将的是以 HTTP 协议的URL。
1.2 URL解析
当我们在浏览器中输入 URL 后,浏览器要做的第一步工作就是对此 URL 进行解析。 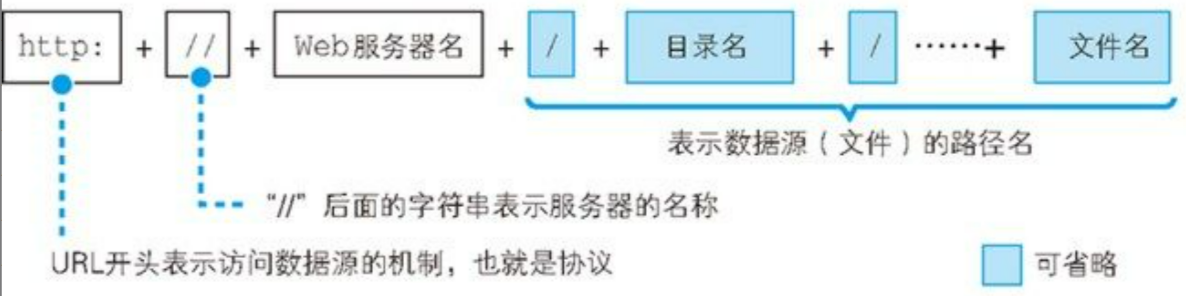 如上图所示,根据 HTTP 的规则,URL 中主要由 URL 头、Web 服务器名称和访问数据源路径这三部分构成。 其中 URL 头与 Web 服务器名称为必须的,其间以
如上图所示,根据 HTTP 的规则,URL 中主要由 URL 头、Web 服务器名称和访问数据源路径这三部分构成。 其中 URL 头与 Web 服务器名称为必须的,其间以 // 分割;访问数据源路径不是必须的,可以省略,路径的不同层级目录之间以 / 分割。
下图是 http://www.lab.glasscom.com/dir1/file1.html 的解析情况。

除了上面介绍的是常规的 URL 写法外,我们也会遇到一些不一样 URL,详见 [[URL 的几种省略写法]]。
1.3 HTTP 的基本思路
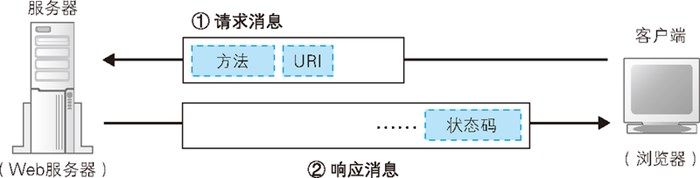
HTTP 协议定义了客户端与服务器之间的交互消息内容和步骤,其基本思想如上图所示非常简单。 首先,客户端会向服务器发送请求消息。其中包含 ==对什么对象== 和 ==执行怎样的操作== 两部分内容。 “对什么对象”部分将由 URI 解决,这里就是指上面讲到的以 http: 开头的 URL。 “执行怎样的操作”部分是我们接下来的重点介绍的内容——HTTP 方法。
收到请求消息之后,Web 服务器会对其中的内容进行解析,通过 URI 和方法来判断“对什么对象”“执行怎样的操作”,并根据这些要求来完成自己的工作,然后将结果存放在响应消息中。 响应消息会被发送回客户端,客户端收到之后,浏览器会从消息中读出所需的数据并显示在屏幕上。
以上就是 HTTP 工作的基本思路了。
1.4 HTTP 请求消息
对 URL 进行解析之后,浏览器确定了 Web 服务器和文件名,接下来就是根据这些信息来生成 HTTP 请求消息了。 浏览器会按照 HTTP 协议规定的格式来生成请求消息,消息格式如下: 
- 请求行。请求消息的第一行称为请求行,包含如下内容:
- 方法:首先就是请求方法了,[[HTTP 的主要请求方法]] 中介绍了 HTTP 有很多种方法,到底是选择用哪一种方法呢(GET、POST或其它),就是由方法决定的。
- URI:方法后面是 URI,中间用空格与方法分隔。URI 一般是文件和程序的路径名,格式为 “<目录名>…/<文件名>”,例如“/sample1.html”。
- HTTP 版本号:URI 后面是 HTTP 版本号,中间同样用空格与方法分隔。这是为了告诉服务器该消息是基于哪个版本的 HTTP 规格编写的。
- 消息头。从第二行开始,直到一个完全没有内容的空行,这中间的内容称为消息头。
- 消息头中定义了很多项目,如日期、客户端支持的数据类型、语言、压缩格式、客户端和服务器的软件名称和版本、数据有效期和最后更新时间等。
- 消息头中的内容随着浏览器类型、版本号、设置等的不同而不同,大多数情况下消息头的长度为几行到十几行不等。在 [[HTTP 的主要头字段]] 中列举了主要的头字段以为参考。
- 消息体。写完消息头之后,还需要写上需要发送的数据,这一部分称为消息体,也就是消息的主体。
1.5 HTTP 响应
HTTP 响应消息 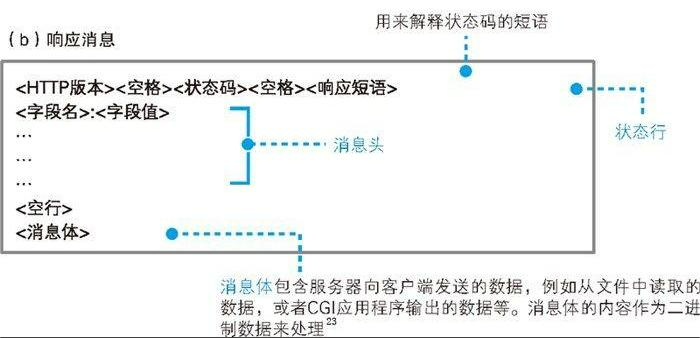
响应消息的格式以及基本思路和请求消息是相同的,差别只在第一行上。在响应消息中,第一行的内容为状态码和响应短语,用来表示请求的执行结果是成功还是出错。 状态码和响应短语表示的内容一致,但它们的用途不同。状态码是一个数字,它主要用来向程序告知执行的结果(详见 [[HTTP 响应消息状态码]]);相对地,响应短语则是一段文字,用来向人们告知执行的结果。
HTTP 响应机制 返回响应消息之后,浏览器会将数据提取出来并显示在屏幕上。但是,当网页中包含图片时,会在网页中的相应位置嵌入表示图片文件的标签的控制信息。 浏览器会在显示文字时搜索相应的标签,当遇到图片相关的标签时,会在屏幕上留出用来显示图片的空间,然后再次访问 Web 服务器,按照标签中指定的文件名向 Web 服务器请求获取相应的图片并显示在预留的空间中。 这个步骤和获取网页文件时一样,只要在 URI 部分写上图片的文件名并生成和发送请求消息就可以了。
由于每条请求消息中只能写 1 个 URI,所以每次只能获取 1 个文件,如果需要获取多个文件,必须对每个文件单独发送 1 条请求。 比如 1 个网页中包含 3 张图片,那么获取网页加上获取图片,一共需要向 Web 服务器发送 4 条请求。
2 向 DNS 查询 Web 服务器的 IP 地址
浏览器解析网址并生成 HTTP 消息后,但它不会将消息直接发送到网络中去(它并不具备将消息发送到网络中的能力),而是通过操作系统来实现这一能力。 但是操作系统发送消息时,需要提供通信对象的 IP 地址,而浏览器知道的是域名,所以在通知操作系统发送消息之前,浏览器还需要根据域名来查询 IP 地址。
IP地址概念及其域名的关系见:[[IP 地址与域名的基本介绍]]
2.1 域名解析基本流程
查询 IP 地址的方法非常简单,只需要向最近的 DNS 服务器发起查询请求即可,DNS 服务器将返回该域名对应的 IP 地址。 向 DNS 服务器发起查询请求,这就要求我们计算机上具有相应的客户端,因为通过 DNS 查询 IP 地址的操作称为域名解析,所以这个客户端就叫做 DNS 解析器(或者简称解析器)。
DNS 解析器是操作系统 Socket 库中的标准组件,浏览器等应用程序只需要进行调用。如下图所示,调用解析器时,只需要写上解析器的程序名称 gethostbynam 以及 Web 服务器的域名 www.lab.glasscom.com 即可。 
### 2.2 DNS 解析器内部原理 虽然浏览器调用解析器很简单,但是解析器内部还涉及到一系列的调用流程,具体流程和原理如下: 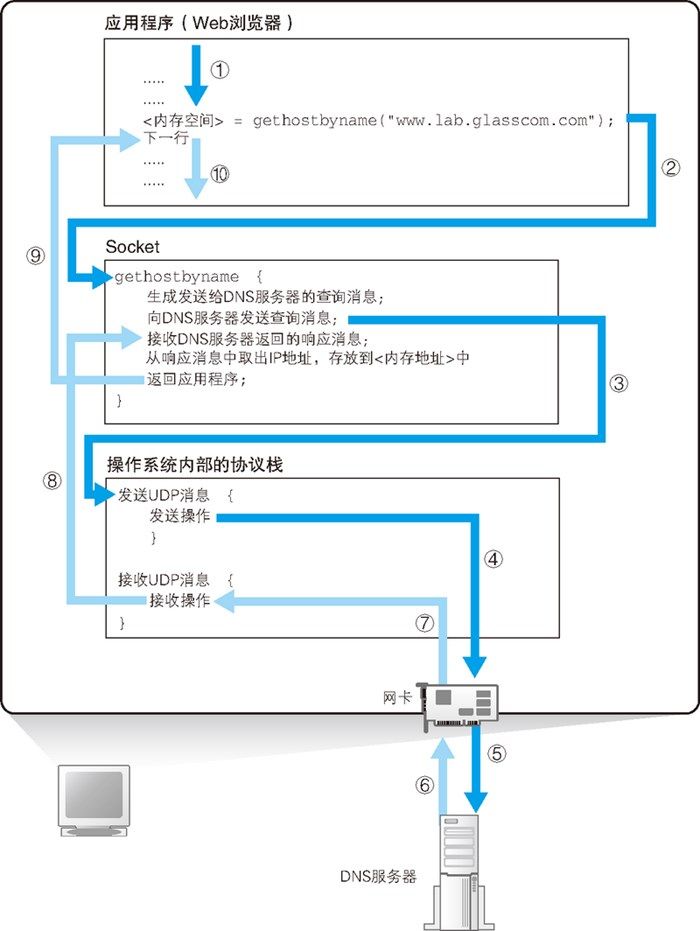
-
IP 地址查询流程 当控制流程转移到解析器后,解析器会生成要发送给 DNS 服务器的查询消息。这个过程与浏览器生成要发送给 Web 服务器的 HTTP 请求消息的过程类似,解析器会根据 DNS 的规格,生成一条表示“请告诉我
www.lab.glasscom.com的 IP 地址”的数据,并将它发送给 DNS 服务器(如上图中的 ③ 所示)。 发送消息这个操作并不是由解析器自身来执行,而是要委托给操作系统内部的协议栈来执行。这是因为和浏览器一样,解析器本身也不具备使用网络收发数据的功能。 解析器调用协议栈后,控制流程会再次转移,协议栈会执行发送消息的操作,然后通过网卡将消息发送给 DNS 服务器(如上图中的 ④⑤ 所示)。 -
IP 地址查询结果接收流程 DNS 服务器收到查询请求并查询到对应域名的 IP 地址后,其 IP 地址会被写入响应消息并返回给客户端(如上图中的 ⑥ 所示)。 接下来,消息经过网络到达客户端,再经过协议栈被传递给解析器(如上图中的 ⑦⑧所示),然后解析器读取出消息取出 IP 地址,并将 IP 地址传递给应用程序(如上图中的 ⑨所示)。 实际上,解析器会将取出的 IP 地址写入应用程序指定的内存地址中,应用程序再从内存中取出 IP 地址来进行后续操作。到这里,解析器的工作就完成了。
-
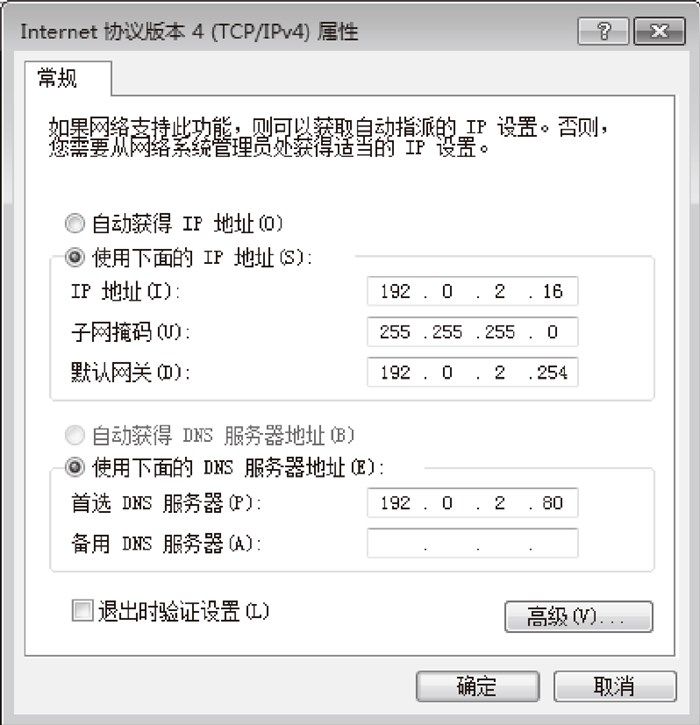
DNS 服务器地址设置 向 DNS 服务器发送消息时,也需要知道 DNS 服务器的 IP 地址,不过这个 IP 地址是作为 TCP/IP 的一个设置项目事先设置好的,不需要再去查询了。 不同的操作系统中 TCP/IP 的设置方法也有差异,Windows 中的设置如下图所示,解析器会根据这里设置的 DNS 服务器 IP 地址来发送消息。
3 DNS 服务器接力查询
3.1 DNS 服务器的基本工作
DNS 服务器的基本工作就是接收来自客户端的查询消息,然后根据消息的内容返回响应。客户端的查询消息一般包含如下三种信息: 1. 域名: 服务器、邮件服务器(邮件地址中 @ 后面的部分)的名称。 2. Class: 在最早设计 DNS 方案时,DNS 在互联网以外的其他网络中的应用也被考虑到了,而 Class 就是用来识别网络的信息。不过,如今除了互联网并没有其他的网络了,因此 Class 的值永远是代表互联网的 IN。 3. 记录类型: 表示域名对应何种类型的记录。例如,当类型为 A 时,表示域名对应的是 IP 地址;当类型为 MX 时,表示域名对应的是邮件服务器。对于不同的记录类型,服务器向客户端返回的信息也会不同。
| 域名 | Class | 记录类型 | 响应数据 |
|---|---|---|---|
| www.lab.glasscom.com | IN | A | 192.0.2.226 |
| glasscom.com | IN | MX | 10 mail.glasscom.com |
| mail.glasscom.com | IN | A | 192.0.2.227 |
| … | … | … | … |
如上表所示,DNS 服务器上会事先保存包含域名、Class、记录类型的记录,然后根据请求内容查询符合条件的记录,返回给客户端。 PS:这里只是为了方便查询,以表格的形式展示,实际上这些信息是保存在配置文件中的,表中的一行信息被称为一条资源记录。
如果要查询 www.lab.glasscom.com 对应的 IP 地址,客户端会向 DNS 服务器发送包含以下信息的查询消息: 1. 域名 = www.lab.glasscom.com 2. Class = IN 3. 记录类型 = A DNS 服务器收到客户端的查询请求后,DNS 服务器会从已有记录中查找域名、Class、记录类型完全匹配的记录,返回给客户端。以上表为例,第一行记录与此查询消息完全匹配,那么 DNS服务器会将 192.0.2.226 返回给客户端。
这里只介绍了记录类型为【A】(即域名)的查询过程,实际上还有 MX(查询邮件服务器)、PTR(根据 IP 地址反查域名)、 CHAME(查询域名相关别名)、NS(查询 DNS 服务器 IP 地址)、SOA(查询域名属性信息)等查询类型。
3.2 域名的层次结构
在前面的讲解中,我们假设要查询的信息都保存在一台 DNS 服务器中,然而,互联网中存在着不计其数的服务器,将这些服务器的信息全部保存在一台 DNS 服务器中是不可能的。所以在实际运行时,是基于域名的层次结构,将服务器信息保存在不同的 DNS 服务器上。
像 www.lab.glasscom.com 中句点代表了不同层次之间的界限,就相当于公司里面的组织结构不用部、科之类的名称来划分,只是用句点来分隔而已。 在域名中,越靠右的位置表示其层级越高,比如 www.lab.glasscom.com 这个域名如果按照公司里的组织结构来说,大概就是“com 事业集团 glasscom 部 lab 科的 www”这样。 其中,相当于一个层级的部分称为域。因此,com 域的下一层是 glasscom 域,再下一层是 lab 域,再下面才是 www 这个名字。
这种具有层次结构的域名信息会作为一个整体注册到 DNS 服务器中。值得说明的是,虽然一个域不能拆开存放到多台 DNS 服务器,但是一台 DNS 服务器中可以存放多个域的信息。 PS:为了避免把事情搞得太复杂,后面的讲解先假设一台 DNS 服务器中只存放一个域的信息。
由于域是不可分割的,所以在互联网中,会通过创建下级的域来分配给不同的国家、公司和组织使用。比如 www.nikkeibp.co.jp 这个域名,最上层的 jp 代表分配给日本这个国家的域;下一层的 co 是日本国内进行分类的域,代表公司;再下层的 nikkeibp 就是分配给某个公司的域;最下层的 www 就是服务器的名称。
根域: 像 com、jp 这些域并不是最顶层的,他们上面还有一级域,称为根域,只是根域的书写一般会被省略。根域的 DNS 服务器中保管着 com、jp 等的 DNS 服务器的信息。
3.3 DNS 服务器接力查询
3.3.1 层次结构 DNS 服务器信息保存方式
上面我们了解 DNS 服务其是如何保存服务器信息的,接下来我们再看看一看如何找到 DNS 服务器上保存的信息。这里的关键在于如何找到我们要访问的 Web 服务器的信息归哪一台 DNS 服务器管。
互联网中有数万台 DNS 服务器,肯定不能一台一台挨个去找。实际过程中会如下办法:首先,将负责管理下级域的 DNS 服务器的 IP 地址注册到它们的上级 DNS 服务器中,然后上级 DNS 服务器的 IP 地址再注册到更上一级的 DNS 服务器中,以此类推。 也就是说,负责管理 lab.glasscom.com 这个域的 DNS 服务器的 IP 地址需要注册到 glasscom.com 域的 DNS 服务器中,而 glasscom.com 域的 DNS 服务器的 IP 地址又需要注册到 com 域的 DNS 服务器中,com 域的 DNS 服务器的 IP 地址保存在根域的 DNS 服务器中。 这样,我们就可以通过上级 DNS 服务器查询出下级 DNS 服务器的 IP 地址,也就可以向下级 DNS 服务器发送查询请求了。
此外,根域的 DNS 服务器信息将保存在互联网中所有的 DNS 服务器中,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器,客户端只要能够找到任意一台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再一路顺藤摸瓜找到位于下层的某台目标 DNS 服务器(如下图所示)。 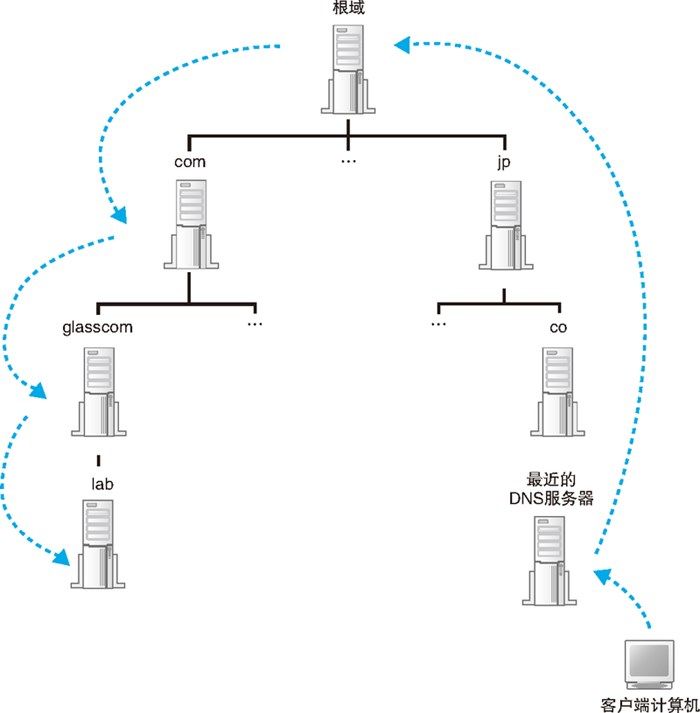
3.3.2 查询目标 DNS 服务器
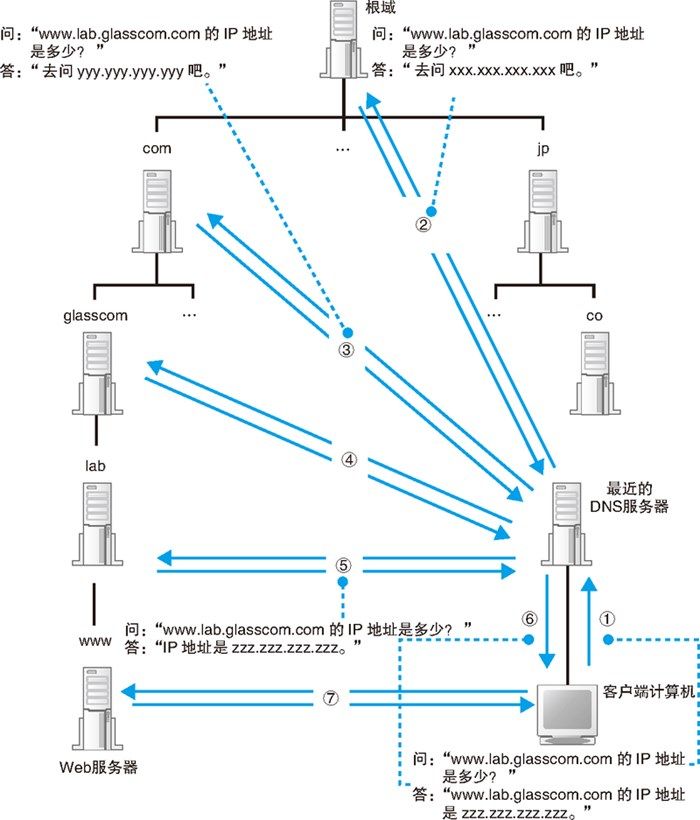
如上图所示,客户端向 DNS 服务器查询域名(www.lab.glasscom.com) IP 地址的完整流程如下: 1. 客户端访问最近的 DNS 服务器(也就是客户端的 TCP/IP 中填写的 DNS 服务器地址)。 2. 最近的 DNS 服务器搜索本地的资源记录,发现没有 www.lab.glasscom.com 的记录,所以最近的 DNS 服务器会将此查询消息转发给根域 DNS 服务器。 3. 根域的 DNS 服务器也没有 www.lab.glasscom.com 这个域名的记录,但是根据域名结构可以判断这个域名属于 com 域,因此根域 DNS 服务器会返回它所管理的 com 域中的 DNS 服务器的 IP 地址,意思是“虽然我不知道你要查的那个域名的地址,但你可以去 com 域问问看”。 4. 接下来,最近的 DNS 服务器又会向 com 域的 DNS 服务器发送查询消息。com 域中也没有 www.lab.glasscom.com 这个域名的信息,和刚才一样,com 域服务器会返回它下面的 glasscom.com 域的 DNS 服务器的 IP 地址。 5. 以此类推,只要重复前面的步骤,就可以顺藤摸瓜找到目标 DNS 服务器。 6. 然后,最近的 DNS 服务器向目标 DNS 服务器发送查询消息,就能够得到 www.lab.glasscom.com 的 IP 地址了。 7. 找到 www.lab.glasscom.com 的 IP 地址后,最近的 DNS 服务器在将此 IP 地址作为结果返回给客户端。 8. 客户端拿到 Web 服务器的 IP 地址后,就可以对其进行访问了。
3.3.3 DNS 服务器缓存
从上面的例子中可以看到,客户端查询 www.lab.glasscom.com 将经过 5 次 查询请求(客户端向最近的 DNS 服务器发起 1 次,DNS 服务器之间接力查询 4 次),这个查询效率未免也太低了。 在真实的互联网中,有时候并不需要从最上级的根域开始查找,DNS 服务器可以通过缓存功能记住查询过的域名。如果要查询的域名和相关信息已经在缓存中,那么就可以直接返回响应,接下来的查询可以从缓存的位置开始向下进行。相比每次都从根域找起来说,缓存可以减少查询所需的时间。
另外,上面我们是为了举例方便,每个域都对应的一台 DNS 服务器,但现实中上级域和下级域有可能共享同一台 DNS 服务器。在这种情况下,访问上级 DNS 服务器时就可以向下跳过一级 DNS 服务器,直接返回再下一级 DNS 服务器的相关信息。
4 委托协议栈发送消息
通过 DNS 服务器查询到目标 Web 服务器的 IP 地址后,接下来就是要向 Web 服务器发送消息了。浏览器本身并不会发送数据,而是将其委托给操作系统中的网络控制软件——协议栈。
整个收发数据的完整过程会稍微复杂一些,因此,我们先来介绍一下收发数据操作的整体思路。
4.1 数据收发的整体思路
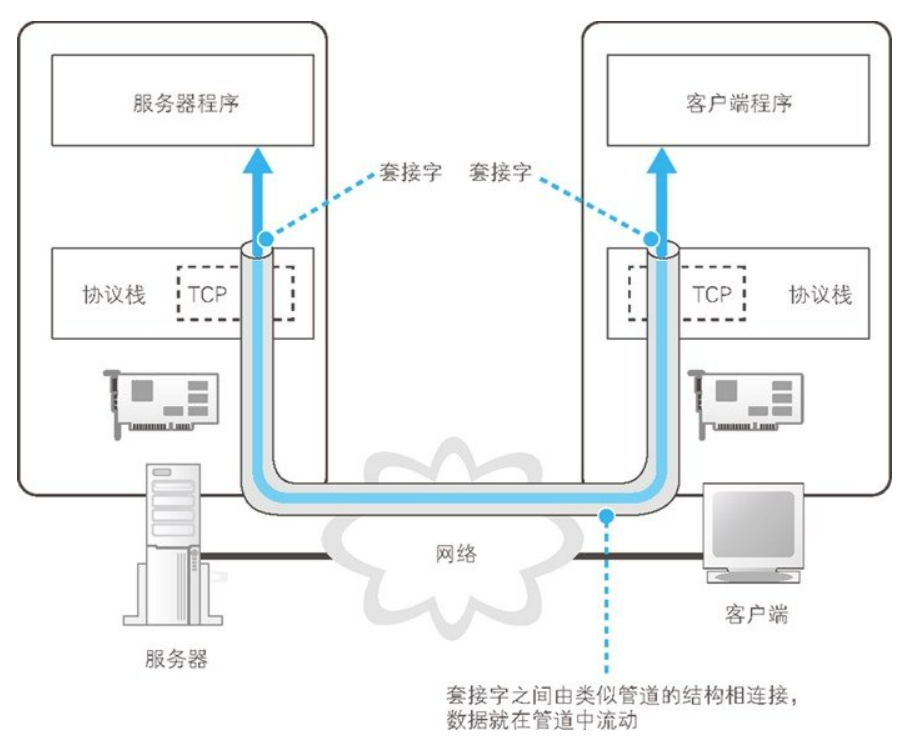
如上图所示,简单来说,手法数据的过程就是在两台计算机之间建立一条数据通道,然后数据就可以沿着这条通道流动,最终达到目的地。而建立这个通道的关键在于通道两端的套接字,实际的过程是下面这样的。 首先,服务器一方先创建套接字,然后等待客户端向该套接字连接管道。当服务器进入等待状态时,客户端也会创建一个套接字,然后从该套接字延伸出管道,最后管道连接到服务器端的套接字上。 接下来,客户端和服务端只需要将数据送入套接字就可以收发数据了。当数据全部发送完毕之后,连接的管道将会被断开。管道在连接时是由客户端发起的,但在断开时可以由客户端或服务器任意一方发起。其中一方断开后,另一方也会随之断开,当管道断开后,套接字也会被删除。
综上所述,收发数据的操作可以分为如下 4 个阶段: 1. 创建套接字阶段:创建套接字; 2. 连接阶段:将管道连接到服务器端的套接字上; 3. 通信阶段:收发数据; 4. 断开阶段:断开管道并删除套接字。
和向 DNS 服务器查询 IP 地址的操作一样,这里也需要使用 Socket 库中的程序组件。不过,查询 IP 地址只需要调用一个程序组件就可以了,而这里需要按照指定的顺序调用多个程序组件,其过程如下图所示。 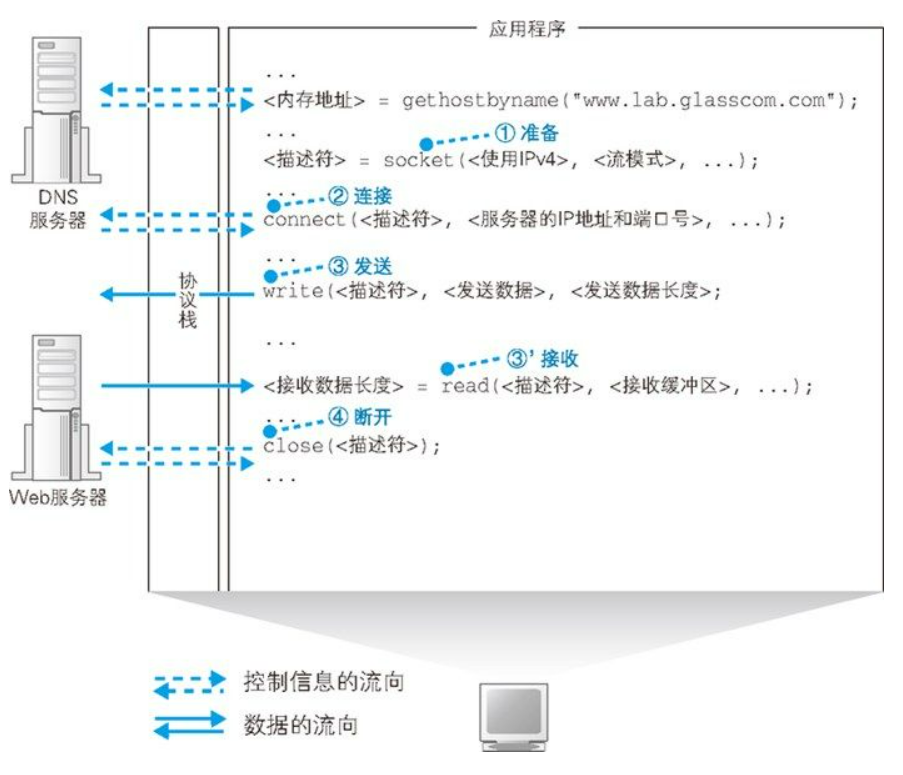
4.2 创建套接字阶段
客户端创建套接字的操作非常简单,只要调用 Socket 库中的 socket 程序组件就可以了。调用 socket 之后,控制流程会转移到 socket 内部并执行创建套接字的操作,完成之后控制流程又会被移交回应用程序。
套接字创建完成后,协议栈会返回一个描述符,应用程序会将收到的描述符存放在内存中。描述符是用来识别不同的套接字的,后续只要通过此描述符,协议栈就能够判断出用哪一个套接字来连接或者收发数据了。
4.3 连接阶段
套接字创建完成后,接下来可以通过调用 Socket 库中的 connect 的组件来将客户端上创建的套接字与服务器上的套接字连接起来。当调用 connect 时,需要指定描述符、服务器 IP 地址和端口号这 3 个参数。 1. 描述符。就是创建套接字时返回的描述符。用于告诉协议栈使用客户端的哪个套接字进行连接。 2. 服务器 IP 地址。就是通过 DNS 服务器查询得到的我们要访问的服务器的 IP 地址。用于标识要和哪台服务器建立连接。 3. 端口号。端口号网址中并没有,也不能像 IP 地址一样去问 DNS 服务器,而是根据应用的种类事先规定好的。用来识别与服务端的哪个套接字进行连接。用于标识要和服务器上的哪个套接字进行连接。 一般 Web 是 80 号端口,电子邮件是 25 号端口。关于端口号的详细信息将在第 6 章探索服务器内部工作的时候进行介绍。
上面通过服务器 IP 地址和端口号,确定了服务器和服务器上的套接字。那么服务器怎么知道客户端的套接字信息呢?事情是这样的,首先,客户端在创建套接字时,协议栈会为这个套接字随便分配一个端口号。接下来,当协议栈执行连接操作时,会将这个随便分配的端口号通知给服务器。
4.4 通信阶段
发送消息 套接字连接起来之后,应用程序将通过 Socket 库中的 write 组件来发送数据。当调用 write 时,需要指定描述符和发送数据,然后协议栈就会将数据发送到服务器。 由于套接字中已经保存了已连接的通信对象的相关信息,所以只要通过描述符指定套接字,就可以识别出通信对象,并向其发送数据。接着,发送数据会通过网络到达我们要访问的服务器。
接受消息 接下来,服务器执行接收操作,解析收到的数据内容并执行相应的操作,向客户端返回响应消息。 当消息返回后,应用程序可以通过 Socket 库中的 read 组件来完成接受消息的操作。调用 read 时需要指定用于存放接收到的响应消息的内存地址,这一内存地址称为接收缓冲区。 当服务器返回响应消息时,read 就会负责将接收到的响应消息存放到接收缓冲区中。由于接收缓冲区是一块位于应用程序内部的内存空间,因此当消息被存放到接收缓冲区中时,就相当于已经转交给了应用程序。
4.5 断开阶段
当浏览器收到数据之后,将调用 Socket 库的 close 程序组件进入断开阶段。最终,连接在套接字之间的管道会被断开,套接字本身也会被删除。
断开的过程如下。Web 使用的 HTTP 协议规定,当 Web 服务器发送完响应消息之后,应该主动执行断开操作,因此 Web 服务器会首先调用 close 来断开连接。 断开操作传达到客户端之后,客户端的套接字也会进入断开阶段。接下来,当浏览器调用 read 执行接收数据操作时,read 会告知浏览器收发数据操作已结束,连接已经断开。浏览器得知后,也会调用 close 进入断开阶段。