1项目目的与意义
1.1项目背景说明
在当今影视行业中,电影和演员信息是非常重要的资源,根据这些信息可以分析电影票房、电影市场趋势和演员影响力等相关信息。为了更好地利用这些信息,于是我开发一个电影和演员数据分析系统,以便能够检索并收集网络上的电影和演员数据。
本系统的主要受众为研究人员、学生、投资人以及对电影和演员关注度高的人群。本系统能够全面而准确地获取电影和演员信息,有利于分析市场数据和预测趋势。与市场上的其他同类系统相比,本系统的优势在于自动化程度高、数据采集速度快和数据质量高等方面。达到检索收集并分析网络上的电影数据和演员数据。
1.2项目目的与意义
获取分析网站上相关电影数据与演员数据。可以用于帮助研究人士、分析师、学生等更好地学习、研究电影产业和演员行业。通过爬取电影和演员数据,可以提供大量的数据支持,这些数据可以被用于制作分析报告、预测模型或其他相关研究
互联网成为了人们获取信息的主要来源,电影和演员数据的爬取与可视化分析使得这些信息更加容易地被用户查询和获取。比如,人们可以根据电影类别、演员名称或电影评分等特定条件查询相关信息。通过对电影票房、电影评分等数据的分析,可以评估电影在市场上的竞争力,并为电影制片人、导演、演员等提供有价值的参考信息,以便他们调整自己的市场策略。通过对电影和演员的数据进行分析,可以了解电影之间的关联性和演员之间的合作关系,进而支持电影推荐或演员推荐功能的实现。
2 软件开发环境与技术说明
2.1软件开发环境
项目开发使用PyCharm 2023.1.1软件编写,使用Python语言编写,依赖于Python3.8环境。
本次项目所需要的库文件模块:request和BeautifulSoup–网页数据爬取,openpyxl–保存数据至Excel,pandas–读取表格数据,pyechars–数据可视化。另需要os,re,time,bs4,fake_useragent,UserAgent,Workbook, load_workbook相关库。
2.2软件开发技术描述
说明软件项目开发需要的技术说明,包括界面设计、数据库连接、网络连接、正则字符串处理等。
1. 网络爬虫:
使用python多种第三方库来实现网络爬虫。Request,BeautifulSoup库实现访问豆瓣网Top250页的相关数据信息。
2. 界面可视化与数据分析:
使用第三方库pyechars进行数据可视化,使用第三方库pandas进行数据分析,并将结果用Excel表格和html界面可视化展示。
3. 数据的保存与管理:
使用第三方库openpyxl保存电影数据与演员数据至Excel表格,便于用户查看。
4. 网络请求:
从网络上获取数据需要进行网络请求。调用本机浏览器的cookie可以实现HTTP请求。
3系统分析与设计
3.1项目需求分析说明
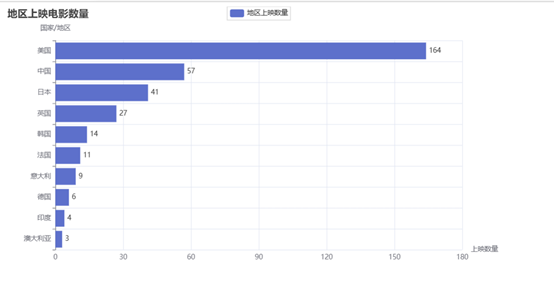
1.可视化得到豆瓣网Top250的各个国家的电影上映数量前十排名,分析各个国家对于电影的接受度和上映数量。
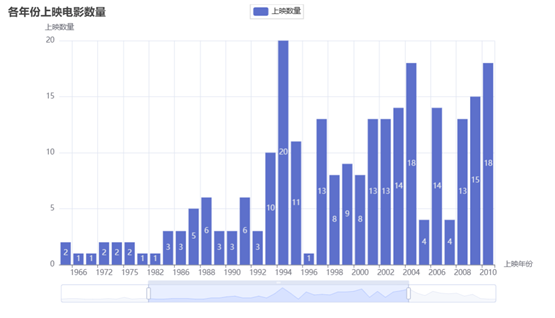
2.可视化得到各年份上映电影数量,得到电影工作人员对电影的拍摄情况。
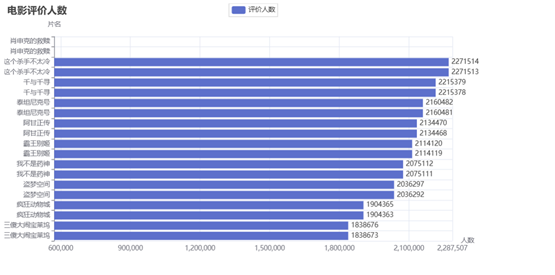
3.可视化得到电影评价人数,分析电影受欢迎程度
4.Excel得到电影片名,导演,主演演员等信息
3.2系统设计方案
1.系统功能架构:数据采集模块:采集电影数据和演员数据,并将采集到的数据保存到Excel表格中。数据清洗模块:负责对采集到的数据进行清洗和去重处理,删除无用数据,并将处理过的数据存入Excel表格中。数据处理分析模块:负责对采集到的电影数据和演员数据进行处理与分析,以便挖掘出电影的潜在需求和演员的市场价值。数据可视化模块:使用数据可视化工具,对数据进行可视化展示,提供数据查询和分析报告功能。
2.系统流程以及云架构。整个系统的流程如下:系统通过电影关键字、演员关键字自动调用网络爬虫工具自动从电影演员数据网站获取相关数据。获取相关数据后,进行数据清洗和预处理,将数据存储到数据库中。进行数据分析和可视化,对电影和演员的数据进行分析挖掘。根据用户请求,查询相关电影或演员数据,并以图表等形式展示给用户,帮助用户更好的了解电影行业动态。
4 系统源代码
4.1系统源代码文件说明
豆瓣电影Top250爬虫.py
爬取豆瓣电影网Top250的所有电影数据和演员数据,并将其存入到TOP250.xlsx表格内
豆瓣电影Top250数据可视化.py
将爬取的Top250的电影。进行数据分析,并且生成三个html界面进行界面可视化处理。
电影评价人数前二十.html
豆瓣电影Top250数据可视化.py生成的界面
各年份上映电影数量.html
豆瓣电影Top250数据可视化.py生成的界面
各地区上映电影数量前十.html
豆瓣电影Top250数据可视化.py生成的界面
TOP250.xlsx
豆瓣电影Top250爬虫.py 生成的Excel表格
5系统使用说明书
第一步,运行这两个程序

第二步,打开三个可视化界面,展示分析
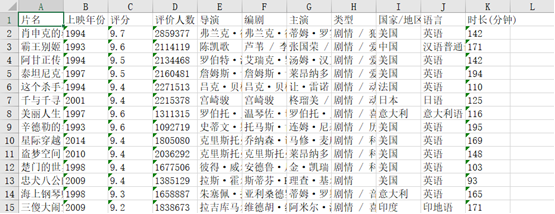
第三步,打开存储的表格
6参考资料
蓝鲸社区python爬取电影数据信息
htps://www.heywhale.com/mw/notebook/6433a8c65d2eb8613c362cac
电影演员合作关系可视化(二)数据分析与可视化
https://blog.csdn.net/u013042248/article/details/52260464?ops_request_misc=%257B%2522request%255Fid%2522%253A%25221685332615168001
(2条消息) 电影分析案例-分析导演、演员拍电影盈利和票房(2021/07/25)_andakiwukawa的博客-CSDN博客
等资料参考
7附件说明
附件一:两个源代码文件:豆瓣电影Top250爬虫.py和豆瓣电影Top250数据可视化.py
附件二:生成的三个html文件:电影评价人数前二十.html、各年份上映电影数量.html和各地区上映电影数量前十.html
附件三:存储爬取的数据的Excel表格:TOP250.xlsx