OFDMA是802.11ax为了适配室内多用户场景而运用的物理层技术,其原理是将原本的OFDM信道划分为更小的单位(即RU),这样就能让一个信道同时为多个站点提供数据传输的服务。不过在这种传输方式中,这些RU并不能被自由的使用,他们必须同步传输,即在同一个channel的RU在同一时刻必须是同一个数据传输方向;这和802.11be中MLO的nSTR还是有相当大的不同。
在ns-3中使用OFDMA一共有两类:上行OFDMA和下行OFDMA。开启OFDMA机制必须要在mac层中配置多用户管理器RrMultiUserScheduler。
以下使用的官方文档和仿真代码的版本为ns-3.40,当前ns-3的gitlab开发版对于802.11ax和802.11be的pcap的输出依然存在一些bug,详见 https://gitlab.com/nsnam/ns-3-dev/-/issues/983。
该仿真使用40MHz宽度的信道,因为此信道比20MHz拥有更多的ru,能更好的展现仿真结果。
在这篇论文中也是使用的40MHz的信道去仿真OFDMA的,同时解答了采用OFDMA后带来的性能损耗问题:https://ieeexplore.ieee.org/document/9447964
@ARTICLE{9447964,
author={Avallone, Stefano and Imputato, Pasquale and Redieteab, Getachew and Ghosh, Chittabrata and Roy, Sumit},
journal={IEEE Wireless Communications},
title={Will OFDMA Improve the Performance of 802.11 Wifi Networks?},
year={2021},
volume={28},
number={3},
pages={100-107},
doi={10.1109/MWC.001.2000332}}
OFDMA
对OFDM来说,在时间片段内用户占用全部的子载波(整个信道),并发送数据。对OFDMA来说,在一个时间片段内,整个信道被切分为了更小的资源块,多个用户各自占用不同的资源块,在这个时间片段内他们一起发送数据。
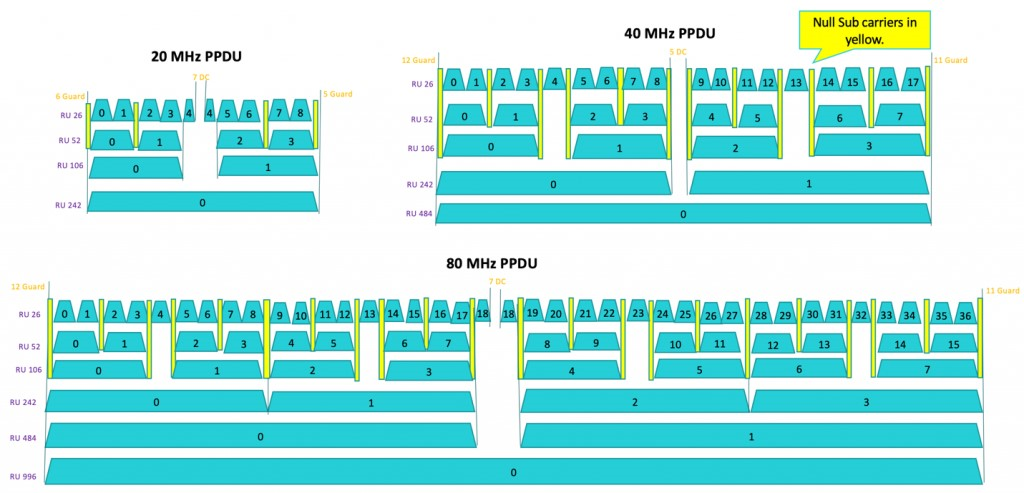
下图解释了如何划分某个宽度的信道的资源块,图片来源:思科,https://blogs.cisco.com/networking/wi-fi-6-ofdma-resource-unit-ru-allocations-and-mappings 。需要注意的是AP对各个STA的RU的分配未必是一致的,比如在有5个sta使用同一个40MHz的信道,那么可以出现4个sta占用4个106的RU,第五个sta占用中央的两个26的ru之一。
ns-3文档原文,34.1.3.2.8. Round-robin Multi-User Scheduler( https://www.nsnam.org/docs/models/html/wifi-design.html#round-robin-multi-user-scheduler )
For instance, if the channel bandwidth is 40 MHz and the determined number of stations is 5, the first 4 stations (in order of priority) are allocated a 106-tone RU each (if 52-tone RUs were allocated, we would have three 52-tone RUs unused). If central 26-tone RUs can be allocated (as determined by the UseCentral26TonesRus attribute), possible stations that have not been allocated an RU are assigned one of such 26-tone RU. In the previous example, the fifth station would have been allocated one of the two available central 26-tone RUs.
性能问题
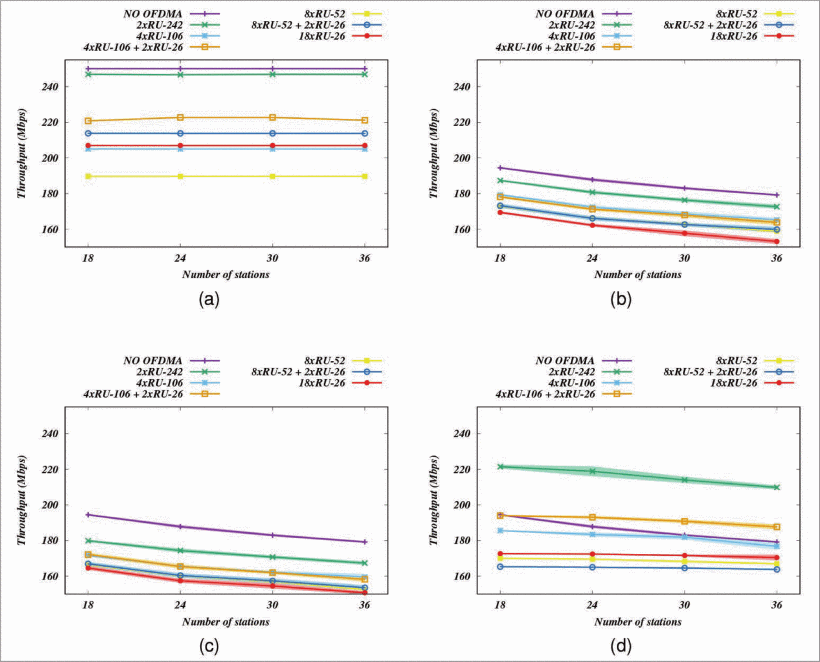
一般来说我们做仿真都是在饱和的数据收发的条件下去测试网络的性能。考虑仅DL流量的情况,AP为每一个STA生成一个UDP流,所有的流都有一个极大的产生速率,而站点不产生流量,因此不存在信道访问冲突;在这种情况下的吞吐量的损失就仅在于信道的接入方案、包头的长度以及ACK所带来的开销,这样不使用OFDMA一定会比使用OFDMA带来更高的总吞吐量(请求ACK所带来的开销,为OFDMA而设置的mac帧头),而且sta越多,总吞吐量会越低(sta接入,ARP报文带来的开销),如下图所示,图片来开头提到的论文。
RrMultiUserScheduler
在ns-3的官方文档(34.1.3.2.7. Multi-User Scheduler https://www.nsnam.org/docs/models/html/wifi-design.html#multi-user-scheduler )中称,这是唯一的被实现的多用户管理器Multi-User Scheduler,默认情况下是不启动这个多用户调度管理器的,需要使用下述代码去配置:
WifiMacHelper mac;
mac.SetMultiUserScheduler("ns3::RrMultiUserScheduler",
"EnableUlOfdma",
BooleanValue(enableUlOfdma),
"EnableBsrp",
BooleanValue(enableBsrp),
"AccessReqInterval",
TimeValue(accessReqInterval));
可以在上述代码中直接配置UL时OFDMA的参数,在ns-3的UL OFDMA系统中,各个STA是否采用OFDMA传输数据由AP进行协调控制。
对于UL OFDMA,ns-3支持BSRP触发帧和基本触发帧。BSRP触发帧由AP发送,以请求站点发送包含缓冲区状态报告的QoS Null帧;基本触发帧由AP发送,以请求站点在TB PPDUs中发送数据帧,这些帧由AP通过Multi-STA BlockAck帧进行确认。这些帧的发送过程如下所示:
/*
* |-------------NAV----------->| |-----------------NAV------------------->|
* |---------NAV------>| |--------------NAV------------->|
* |---NAV-->| |--------NAV-------->|
* ┌───┐ ┌───┐ ┌────┐ ┌────┐ ┌───┐ ┌───┐ ┌─────┐ ┌────┐ ┌─────┐
* │ │ │ │ │ │ │QoS │ │ │ │ │ │ │ │QoS │ │ │
* │ │ │ │ │ │ │Null│ │ │ │ │ │ │ │Data│ │ │
* │ │ │ │ │ │ ├────┤ │ │ │ │ │ │ ├────┤ │ │
* │ │ │ │ │ │ │QoS │ │ │ │ │ │ │ │QoS │ │Multi│
* │MU-│ │CTS│ │BSRP│ │Null│ │MU-│ │CTS│ │Basic│ │Data│ │-STA │
* │RTS│SIFS│ │SIFS│ TF │SIFS├────┤<IFS>│RTS│SIFS│ │SIFS│ TF │SIFS├────┤SIFS│Block│
* │TF │ │x4 │ │ │ │QoS │ │TF │ │x4 │ │ │ │QoS │ │ Ack │
* │ │ │ │ │ │ │Null│ │ │ │ │ │ │ │Data│ │ │
* │ │ │ │ │ │ ├────┤ │ │ │ │ │ │ ├────┤ │ │
* │ │ │ │ │ │ │QoS │ │ │ │ │ │ │ │QoS │ │ │
* │ │ │ │ │ │ │Null│ │ │ │ │ │ │ │Data│ │ │
* ───┴───┴────┴───┴────┴────┴────┴────┴─────┴───┴────┴───┴────┴─────┴────┴────┴────┴─────┴──
* From: AP all AP all AP all AP all AP
* To: all AP all AP all AP all AP all
*/
为了保证ap能够协调控制sta,就需要给ap设置一个即使自己的缓冲区没有数据,也要请求txop的时间间隔,以便于发送brsp和基本触发帧,该参数为AccessReqInterval。
dlAckSeqType下行数据时STAs的ack格式
在AP向STAs发送数据时,STA发送ack帧的方式,ns-3中规定了三种确认方式,本来想要截图的,发现ns-3的src/wifi/test/wifi-mac-ofdma-test.cc文件中有画的很好的ASCII艺术图:
-
DL_MU_TF_MU_BAR
一个基于请求重传的ack机制
/* * |---------------------NAV------------------------>| * |-------------------NAV----------------->| * |---------------NAV--------->| * |------NAV----->| * ┌───┐ ┌───┐ ┌──────┐ ┌───────┐ ┌──────────┐ * │ │ │ │ │PSDU 1│ │ │ │BlockAck 1│ * │ │ │ │ ├──────┤ │MU-BAR │ ├──────────┤ * │MU-│ │CTS│ │PSDU 2│ │Trigger│ │BlockAck 2│ * │RTS│SIFS│ │SIFS├──────┤SIFS│ Frame │SIFS├──────────┤ * │TF │ │x4 │ │PSDU 3│ │ │ │BlockAck 3│ * │ │ │ │ ├──────┤ │ │ ├──────────┤ * │ │ │ │ │PSDU 4│ │ │ │BlockAck 4│ * -----┴───┴────┴───┴────┴──────┴────┴───────┴────┴──────────┴─── * From: AP all AP AP all * To: all AP all all AP */如上图所示,AP在同一时刻向多个sta发送多个帧,经过sifs时间后发送触发帧请求ack,然后各个站点在同一时刻发送ack帧回报。
在仿真文件中可以通过如下方式启用这种ack功能
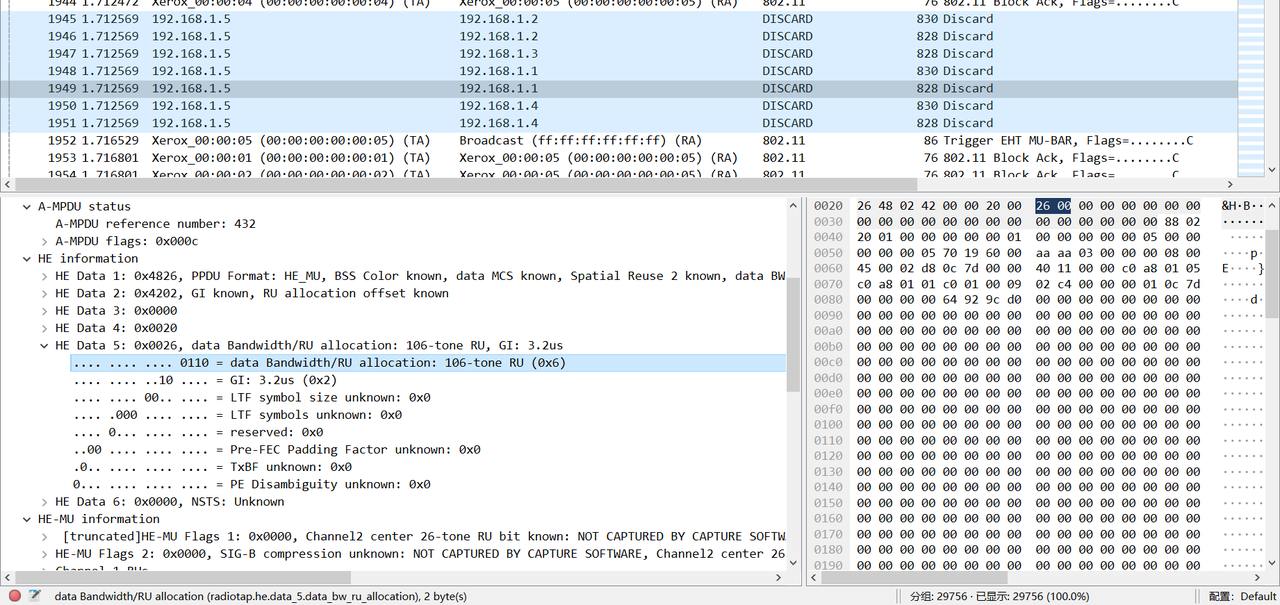
Config::SetDefault("ns3::WifiDefaultAckManager::DlMuAckSequenceType", EnumValue(WifiAcknowledgment::DL_MU_TF_MU_BAR));启用后在pcap文件中可以看到如下的输出,可以看到AP在同一时间内向多个ip地址发送UDP数据包,这些接收到数据的STA也在收到触发帧后在同一时间内回复的ACK报文。不知道又有什么bug,这些UDP数据包的包头报了一个解析错误,不知道是wireshark还是ns-3的问题,嘛,不影响我们读取想要的信息就是了。

选取一个UDP数据报文,可以在头部的信息中读取到他所占用的RU宽度,这里占用了一个106-tone的RU,符合OFDMA的设计规范:将40MHz的信道划分为4个106-tone的RU。
-
DL_MU_BAR_BA_SEQUENCE
一个和未开启OFDMA的传输很像的ack回报格式:
/* * |-----------------------------------------NAV-------------------------------->| * |----------------------------------NAV------------------------------>| * |-----------------------------NAV------------------------->| * |-------------------------NAV--------------------->| * |--NAV->| |--NAV->| |--NAV->| * ┌───┐ ┌───┐ ┌────┐ ┌──┐ ┌───┐ ┌──┐ ┌───┐ ┌──┐ ┌───┐ ┌──┐ * │ │ │ │ │PSDU│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ │ 1 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ ├────┤ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ │PSDU│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │MU-│ │CTS│ │ 2 │ │BA│ │BAR│ │BA│ │BAR│ │BA│ │BAR│ │BA│ * │RTS│SIFS│ │SIFS├────┤SIFS│ │SIFS│ │SIFS│ │SIFS│ │SIFS│ │SIFS│ │SIFS│ │ * │TF │ │x4 │ │PSDU│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ │ 3 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ ├────┤ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ │PSDU│ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * │ │ │ │ │ 4 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ * ───┴───┴────┴───┴────┴────┴────┴──┴────┴───┴────┴──┴────┴───┴────┴──┴────┴───┴────┴──┴── * From: AP all AP STA 1 AP STA 2 AP STA 3 AP STA 4 * To: all AP all AP STA 2 AP STA 3 AP STA 4 AP */可以看到,在启用这种ack回报格式后,对于STA来说并没有什么变动,只有AP会将多个PSDU聚合在一起,通过OFDMA的形式下发给不同的STA
-
DL_MU_AGGREGATE_TF
一个在数据帧中整合了ACK请求消息的ACK格式
/* * |---------------------NAV----------------------->| * |-------------------NAV---------------->| * |------NAV----->| * ┌───┐ ┌───┐ ┌──────┬───────────┐ ┌──────────┐ * │ │ │ │ │PSDU 1│MU-BAR TF 1│ │BlockAck 1│ * │ │ │ │ ├──────┼───────────┤ ├──────────┤ * │MU-│ │CTS│ │PSDU 2│MU-BAR TF 2│ │BlockAck 2│ * │RTS│SIFS│ │SIFS├──────┼───────────┤SIFS├──────────┤ * │TF │ │x4 │ │PSDU 3│MU-BAR TF 3│ │BlockAck 3│ * │ │ │ │ ├──────┼───────────┤ ├──────────┤ * │ │ │ │ │PSDU 4│MU-BAR TF 4│ │BlockAck 4│ * -----┴───┴────┴───┴────┴──────┴───────────┴────┴──────────┴─── * From: AP all AP all * To: all AP all AP */和第一种ACK方式差别在于将触发ACK请求帧整合到了发送的数据帧之中,应该能缩短数据的延迟,增加带宽。