| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 作业要求 | 综合设计——多源异构数据采集与融合应用综合实践 |
| 组名 | 汪汪队 |
| 项目主题 | 微博评论情感分析 |
| 项目简介 | 项目需求:1. 情绪监测、2. 品牌声誉管理、3. 市场分析、4. 舆论引导、5. 个性化推荐、6. 社交网络分析 项目目标: 1. 情绪识别、2. 情感分类、3. 观点提取、4. 情绪监测、5. 市场趋势预测、6. 个性化推荐、7. 社交网络分析 项目开展技术路线:1. 数据收集、2. 数据预处理、3. 模型选择与训练、4. 情感分析、5. 结果分析与可视化、6. 搭建网页 |
| 团队成员学号 | 组长:102102130张明康 组员: 102102131张铭玮 102102128汪伟杰 102102129张昊 102102133陈灿铭 |
| 这个项目的目标 | 1. 情绪识别:准确识别评论表达的情绪倾向,如正面情绪、负面情绪或中性情绪。这是情感分析的基础任务,也是其他应用场景的前提。 2. 情感分类:对评论进行细致的情感分类,如愤怒、喜悦、悲伤等,以便更深入地了解用户的情感状态。 3. 观点提取:从评论中提取出用户对某一事件、话题或产品的观点和看法,为舆情分析、市场调查等领域提供有价值的信息。 4. 情绪监测:通过对微博评论的情感分析,实时监测公众情绪的变化趋势,为情绪监测和舆情管理提供数据支持。 5. 市场趋势预测:通过分析用户对产品或服务的情感态度,预测市场趋势和消费者需求,为企业市场策略制定提供参考。 6. 个性化推荐:根据用户的情感倾向,为用户推荐更符合其兴趣和需求的内容,提高用户体验。 7. 社交网络分析:通过分析微博评论的情感倾向,研究社交网络中用户之间的关系和影响力,为社交网络分析提供数据支持。 |
| 参考文献 | 【深度学习】详解TextCNN [NLP] 文本分类之TextCNN模型原理和实现(超详细) Python数据可视化:折线图、柱状图、饼图代码 【干货】Python:wordcloud库绘制词云图 python绘制雷达图(详细) |
几个阶段:
- 数据收集:通过爬虫技术或API接口从微博平台获取评论数据。考虑到数据的多样性和真实性,往往会选取带有用户图片和文本双重信息的评论数据。
- 数据预处理:清洗数据,去除噪声,如HTML标签、特殊字符等;然后进行分词处理,把文本分解为更易分析的单元,如词、短语等。
- 特征工程:从预处理后的文本中提取特征,如词频、词向量、语法结构等,为机器学习模型准备输入。
- 模型训练:使用机器学习算法TestCNN训练模型。深度学习框架常被用于构建复杂的网络模型。
- 情感分析:将训练好的模型应用于新的数据集上,输出情感分析结果,如正面情绪、负面情绪或中性情绪。
- 结果分析与应用:根据模型输出的情感分析结果,进行数据可视化、趋势分析等,为情绪监测、品牌管理、市场分析等领域提供依据。
- 搭建网页:使用streamlit搭建网页,展示爬取的数据以及可视化结果。
微博评论情感分析项目在实施过程中可能会遇到数据量大、语言多样、情感表达复杂等挑战。因此,项目往往需要结合最新的NLP技术,如深度学习、迁移学习等,以及领域专业知识,才能达到较好的分析效果。
项目需求
微博评论情感分析的需求主要来源于以下几个方面:
- 情绪监测:通过分析微博评论的情感倾向,可以了解公众对于某一事件、话题或产品的情绪态度,为情绪监测提供数据支持。
- 品牌声誉管理:企业可以通过微博评论情感分析了解消费者对其产品或服务的满意度和不满意度,以及消费者对品牌形象的评价,从而更好地进行品牌声誉管理。
- 市场分析:通过对微博评论的情感分析,可以了解消费者对某一产品或服务的需求、喜好和期望,为企业市场策略的制定提供参考。
- 舆论引导:政府和媒体可以通过微博评论情感分析了解公众对某一事件或政策的看法和态度,从而进行舆论引导和舆情管理。
- 个性化推荐:微博平台可以根据用户的评论情感倾向,为用户推荐更符合其兴趣和需求的内容,提高用户体验。
- 社交网络分析:通过分析微博评论的情感倾向,可以了解社交网络中用户之间的关系和影响力,为社交网络分析提供数据支持。
个人分工:网页前端
完整代码
主函数
def main():
a = 'mydata'
b = '123'
print("主函数开始")
start_time = dm2.time.time()
dm2.torch.manual_seed(1)
dm2.torch.cuda.manual_seed_all(1)
dm2.torch.backends.cudnn.deterministic = True
config = dm2.Config(a,b)
vocab_path= 'mydata/data/vocab3.pkl'
vocab = dm2.pkl.load(open(vocab_path, 'rb'))
time_dif = dm2.get_time_dif(start_time)
print("Time usage:", time_dif)
config.n_vocab = len(vocab)
global cfggb
cfggb = len(vocab)
model = dm2.Model(config).to('cpu')
model.load_state_dict(dm2.torch.load(config.save_path))#加载模型,定式
side = ["主界面","数据分析结果"]
st.sidebar.title("使用左侧面板")
la = st.sidebar.selectbox("请选择",side)
a = 0
if la == "主界面":
r1,r2,r3 = st.columns([3,6,3])
with r2:
st.title("情绪分析(单句)")
test = st.text_input("请输入文字:", key="请输入内容")
x = st.button("开始分析")
res = ""
if x:
print("x")
res = dm2.predict(model,test,cfggb)
st.write("情感倾向为: "+res)
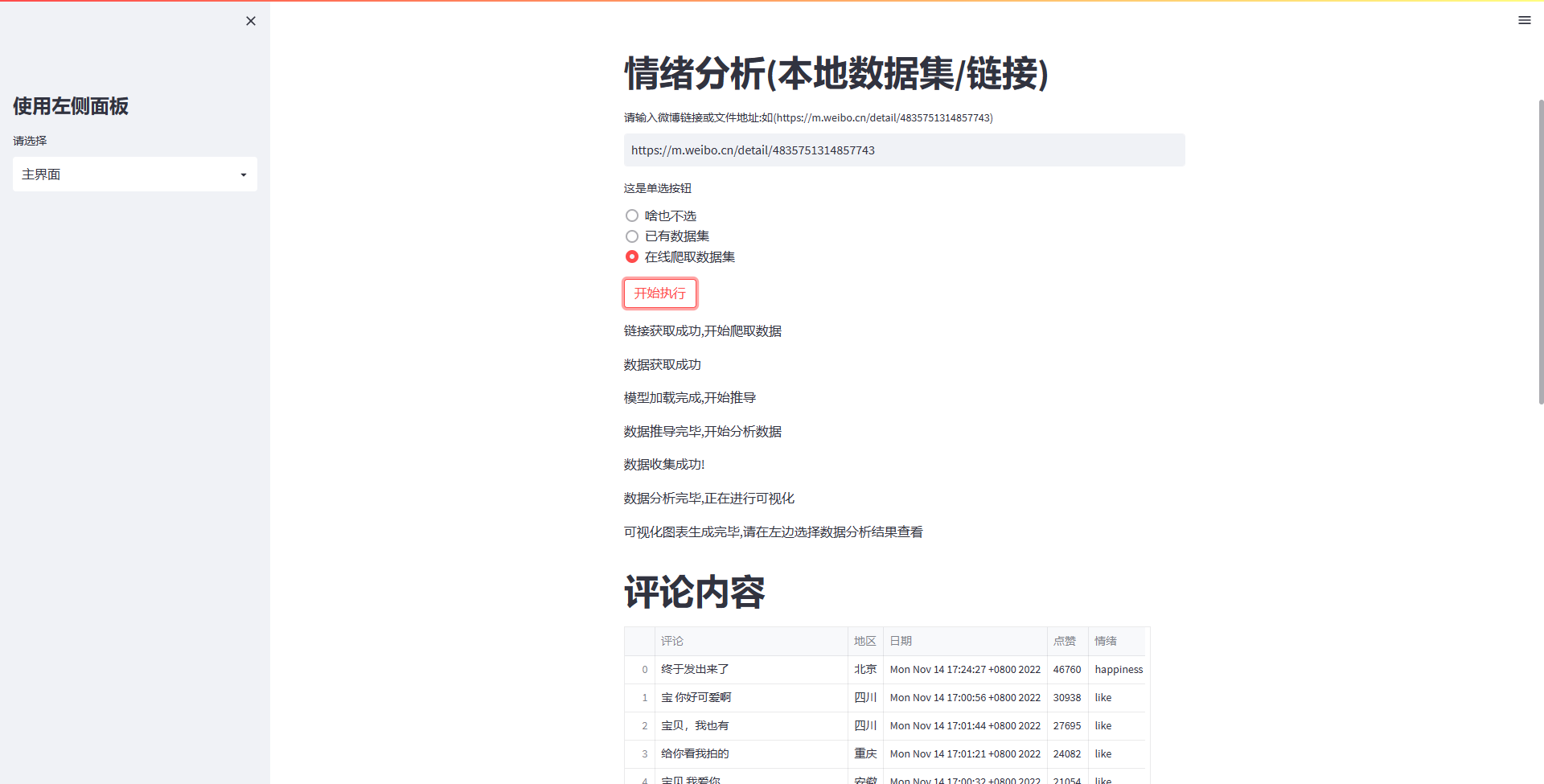
st.title("情绪分析(本地数据集/链接)")
text = st.text_input("请输入微博链接或文件地址:如(https://m.weibo.cn/detail/4835751314857743)", key="请输入内容")
sel = ["啥也不选","已有数据集","在线爬取数据集"]
spy = st.radio("这是单选按钮", sel)
y = st.button("开始执行")
if y:
if spy == "啥也不选":
st.write("你啥也没选")
elif spy == "已有数据集":
st.write("模型加载完毕,开始推导数据")
# msg1 = dm2.sp.main(text)
text2 = dm2.reprocfun(text)
x = dm2.predict2(model,text2,cfggb)
st.write("数据推导完毕,开始分析数据")
print(x)
cont,prov,date,like = dm2.da.ana()
st.write("数据分析完毕,正在进行可视化")
emo = []
for i in cont:
x = dm2.predict2(model,i,cfggb)
emo.append(x)
if text == "":
text = "result2.csv"
mt.fun(text)
st.write("可视化图表生成完毕,请在左边选择数据分析结果查看")
st.title("评论内容")
df1 = pd.read_csv(text)
st.dataframe(df1,width=1500)
f11 = open("mid.txt",'w+',encoding="utf-8")
f11.write(text)
else:
st.write("链接获取成功,开始爬取数据")
f = open('result.csv', mode='w+', encoding='utf-8', newline='')
fieldnames = ['评论','地区', '日期', '点赞','情绪']
writer = csv.writer(f)
writer.writerow(fieldnames)
msg1 = dm2.sp.main(text)
st.write("数据获取成功")
st.write("模型加载完成,开始推导")
st.write("数据推导完毕,开始分析数据")
st.write(msg1)
print(x)
cont,prov,date,like = dm2.da.ana()
st.write("数据分析完毕,正在进行可视化")
emo = []
for i in cont:
x = dm2.predict2(model,i,cfggb)
emo.append(x)
for i in zip(cont,prov,date,like,emo):
writer.writerow([i[0],i[1],i[2],i[3],i[4]])
mt.fun()
cont = []
prov = []
date = []
like = []
emo = []
st.write("可视化图表生成完毕,请在左边选择数据分析结果查看")
st.title("评论内容")
df1 = pd.read_csv("result.csv")
st.dataframe(df1,width=1500)
# global flname
f22 = open("mid.txt",'w+',encoding="utf-8")
print("改成了result")
f22.write("result.csv")
if a == 1:
df = pd.read_csv("result.csv")
st.dataframe(df) # st.dataframe(df)可以用st.write(df)来代替,效果一样
elif la == "数据分析结果":
env=["分析总览","数据总览"]
la2 = st.sidebar.selectbox("请选择模块",env)
if la2 == "分析总览":
st.title("分析总览")
st.title(" ")
st.title(" ")
r0,r1= st.columns([3,3])
with r1:
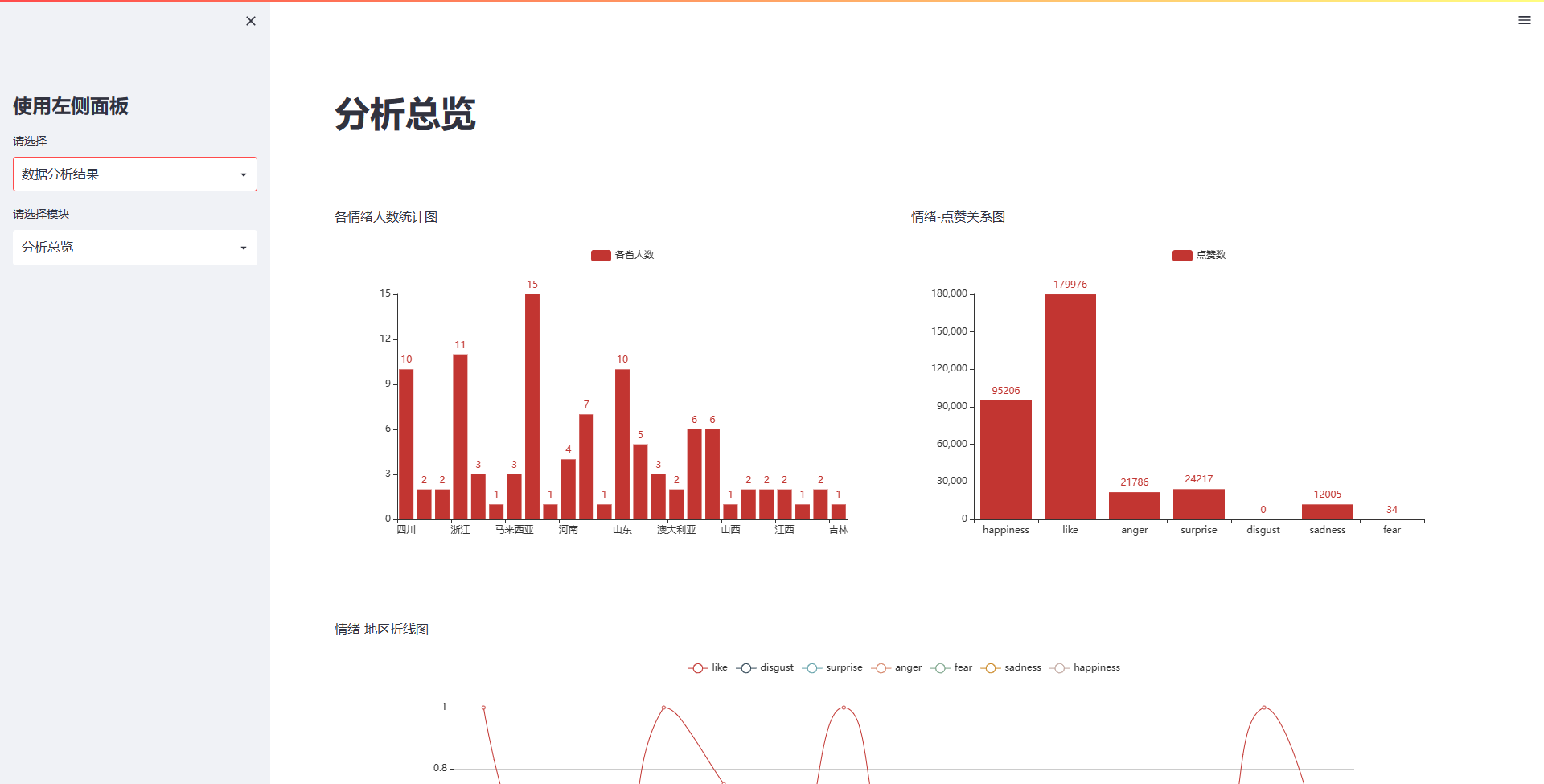
st.write("情绪-点赞关系图")
with open("emolk.html") as fp1:
text001=fp1.read()
components.html(text001,height=400,width=700)
with r0:
st.write("各情绪人数统计图")
with open("procnts.html") as fp2:
text001=fp2.read()
components.html(text001,height=400,width=700)
st.write(" ")
st.write(" ")
st.write(" ")
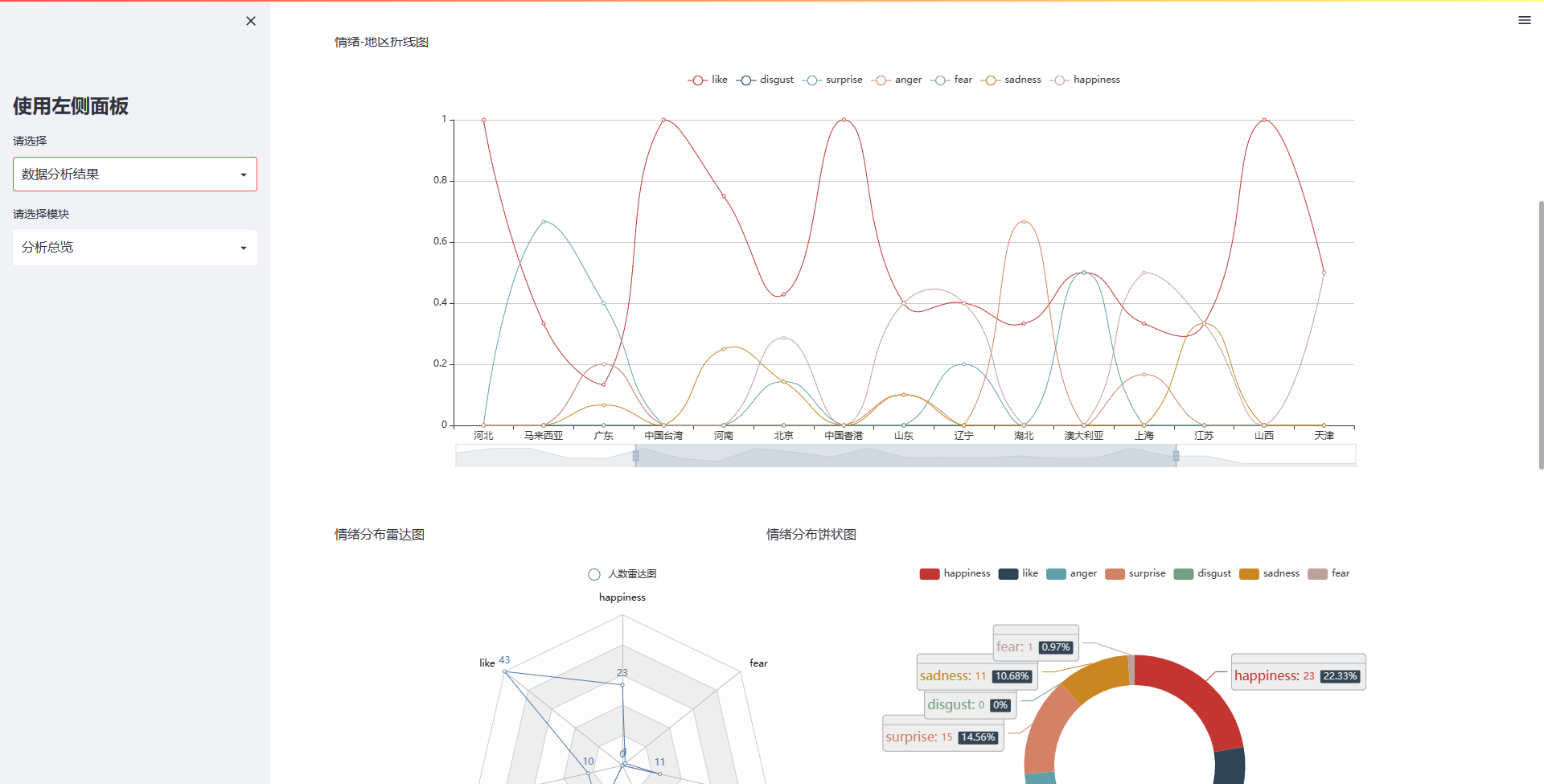
st.write("情绪-地区折线图")
with open("nwpe.html") as fp3:
text001=fp3.read()
components.html(text001,height=500,width=1400)
st.write(" ")
st.write(" ")
st.write(" ")
r3,r4 ,r5= st.columns([3,3,2])
with r3:
st.write("情绪分布雷达图")
with open("radar.html") as fp2:
text001=fp2.read()
components.html(text001,height=500,width=900)
with r4:
st.write("情绪分布饼状图")
with open("pie_rich_label.html") as fp2:
text001=fp2.read()
components.html(text001,height=500,width=900)
st.write(" ")
st.write(" ")
st.write(" ")
r6,r7 = st.columns([1,1])
with r6:
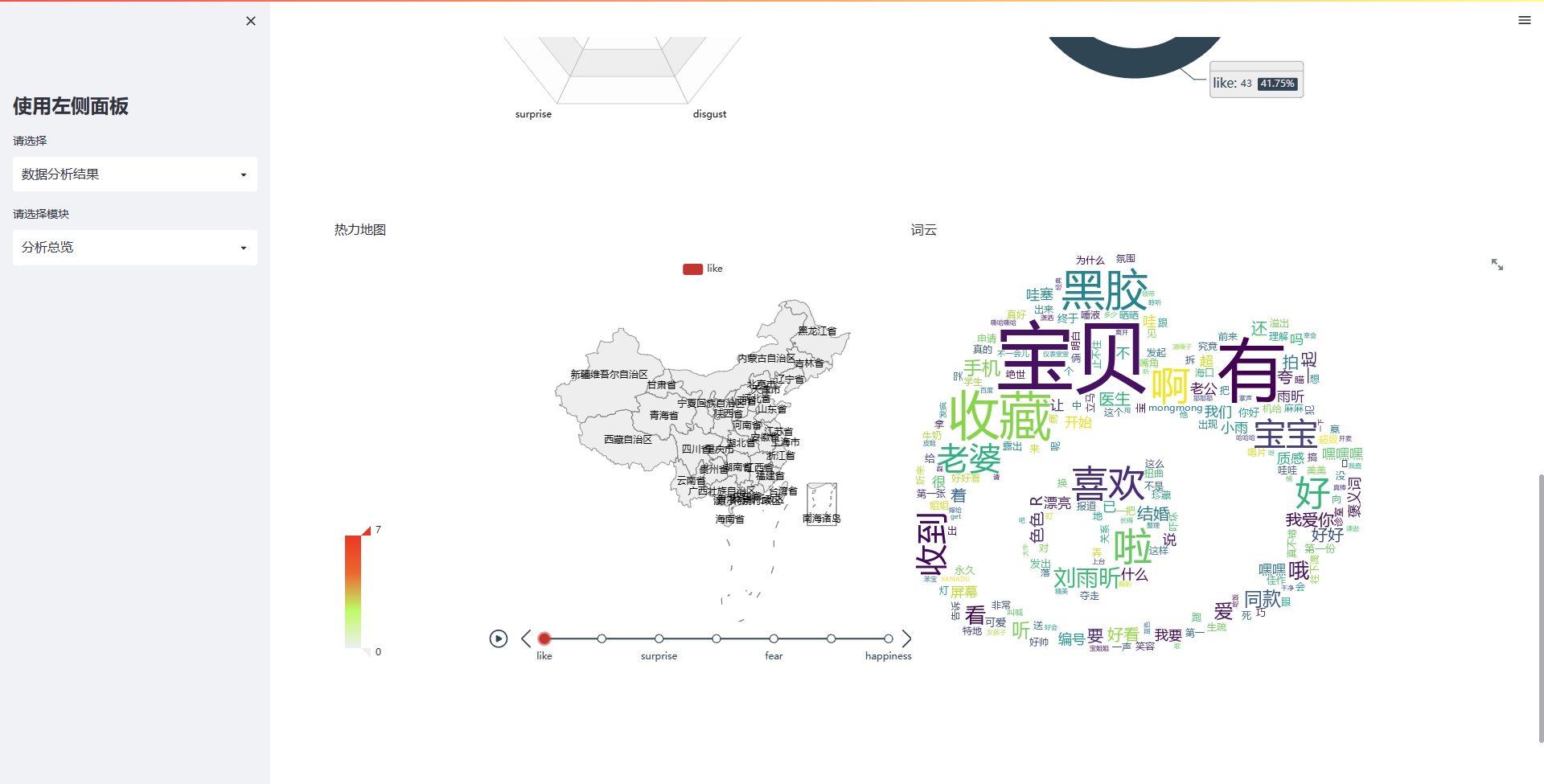
st.write("热力地图")
with open("new_map.html") as fp2:
text001=fp2.read()
components.html(text001,height=600,width=900)
with r7:
st.write("词云")
image = Image.open('pics/wdc.png')
st.image(image, use_column_width=False)
if la2 == "数据总览":
r9,r10 = st.columns([1,3])
with r10:
st.title("评论内容")
f11 = open("mid.txt",'r',encoding="utf-8")
flname = f11.readline()
print(flname)
df1 = pd.read_csv(flname)
st.dataframe(df1,width=1500,height=1500)
功能讲解
准备工作
a = 'mydata'
b = '123'
print("主函数开始")
start_time = dm2.time.time()
dm2.torch.manual_seed(1)
dm2.torch.cuda.manual_seed_all(1)
dm2.torch.backends.cudnn.deterministic = True
config = dm2.Config(a,b)
vocab_path= 'mydata/data/vocab3.pkl'
vocab = dm2.pkl.load(open(vocab_path, 'rb'))
time_dif = dm2.get_time_dif(start_time)
print("Time usage:", time_dif)
config.n_vocab = len(vocab)
global cfggb
cfggb = len(vocab)
model = dm2.Model(config).to('cpu')
model.load_state_dict(dm2.torch.load(config.save_path))#加载模型,定式
side = ["主界面","数据分析结果"]
st.sidebar.title("使用左侧面板")
la = st.sidebar.selectbox("请选择",side)
a = 0
主界面代码
if la == "主界面":
r1,r2,r3 = st.columns([3,6,3])
with r2:
st.title("情绪分析(单句)")
test = st.text_input("请输入文字:", key="请输入内容")
x = st.button("开始分析")
res = ""
if x:
print("x")
res = dm2.predict(model,test,cfggb)
st.write("情感倾向为: "+res)
st.title("情绪分析(本地数据集/链接)")
text = st.text_input("请输入微博链接或文件地址:如(https://m.weibo.cn/detail/4835751314857743)", key="请输入内容")
sel = ["啥也不选","已有数据集","在线爬取数据集"]
spy = st.radio("这是单选按钮", sel)
y = st.button("开始执行")
if y:
if spy == "啥也不选":
st.write("你啥也没选")
elif spy == "已有数据集":
st.write("模型加载完毕,开始推导数据")
# msg1 = dm2.sp.main(text)
text2 = dm2.reprocfun(text)
x = dm2.predict2(model,text2,cfggb)
st.write("数据推导完毕,开始分析数据")
print(x)
cont,prov,date,like = dm2.da.ana()
st.write("数据分析完毕,正在进行可视化")
emo = []
for i in cont:
x = dm2.predict2(model,i,cfggb)
emo.append(x)
if text == "":
text = "result2.csv"
mt.fun(text)
st.write("可视化图表生成完毕,请在左边选择数据分析结果查看")
st.title("评论内容")
df1 = pd.read_csv(text)
st.dataframe(df1,width=1500)
f11 = open("mid.txt",'w+',encoding="utf-8")
f11.write(text)
else:
st.write("链接获取成功,开始爬取数据")
f = open('result.csv', mode='w+', encoding='utf-8', newline='')
fieldnames = ['评论','地区', '日期', '点赞','情绪']
writer = csv.writer(f)
writer.writerow(fieldnames)
msg1 = dm2.sp.main(text)
st.write("数据获取成功")
st.write("模型加载完成,开始推导")
st.write("数据推导完毕,开始分析数据")
st.write(msg1)
print(x)
cont,prov,date,like = dm2.da.ana()
st.write("数据分析完毕,正在进行可视化")
emo = []
for i in cont:
x = dm2.predict2(model,i,cfggb)
emo.append(x)
for i in zip(cont,prov,date,like,emo):
writer.writerow([i[0],i[1],i[2],i[3],i[4]])
mt.fun()
cont = []
prov = []
date = []
like = []
emo = []
st.write("可视化图表生成完毕,请在左边选择数据分析结果查看")
st.title("评论内容")
df1 = pd.read_csv("result.csv")
st.dataframe(df1,width=1500)
# global flname
f22 = open("mid.txt",'w+',encoding="utf-8")
print("改成了result")
f22.write("result.csv")
if a == 1:
df = pd.read_csv("result.csv")
st.dataframe(df) # st.dataframe(df)可以用st.write(df)来代替,效果一样
创建文本框,用于输入文本和触发情感分析。
根据用户输入的文本,使用模型进行情感分析,并显示结果。
提供文本框和按钮,用于输入微博链接或文件地址,选择数据集来源,并进行数据分析和可视化。
如果选择了已有数据集,加载模型,推导数据,进行情感分析,生成可视化图表,并显示评论内容。
如果选择了在线爬取数据集,爬取数据,加载模型,推导数据,进行情感分析,生成可视化图表,并显示评论内容。
数据分析结果代码
elif la == "数据分析结果":
env=["分析总览","数据总览"]
la2 = st.sidebar.selectbox("请选择模块",env)
if la2 == "分析总览":
st.title("分析总览")
st.title(" ")
st.title(" ")
r0,r1= st.columns([3,3])
with r1:
st.write("情绪-点赞关系图")
with open("emolk.html") as fp1:
text001=fp1.read()
components.html(text001,height=400,width=700)
with r0:
st.write("各情绪人数统计图")
with open("procnts.html") as fp2:
text001=fp2.read()
components.html(text001,height=400,width=700)
st.write(" ")
st.write(" ")
st.write(" ")
st.write("情绪-地区折线图")
with open("nwpe.html") as fp3:
text001=fp3.read()
components.html(text001,height=500,width=1400)
st.write(" ")
st.write(" ")
st.write(" ")
r3,r4 ,r5= st.columns([3,3,2])
with r3:
st.write("情绪分布雷达图")
with open("radar.html") as fp2:
text001=fp2.read()
components.html(text001,height=500,width=900)
with r4:
st.write("情绪分布饼状图")
with open("pie_rich_label.html") as fp2:
text001=fp2.read()
components.html(text001,height=500,width=900)
st.write(" ")
st.write(" ")
st.write(" ")
r6,r7 = st.columns([1,1])
with r6:
st.write("热力地图")
with open("new_map.html") as fp2:
text001=fp2.read()
components.html(text001,height=600,width=900)
with r7:
st.write("词云")
image = Image.open('pics/wdc.png')
st.image(image, use_column_width=False)
if la2 == "数据总览":
r9,r10 = st.columns([1,3])
with r10:
st.title("评论内容")
f11 = open("mid.txt",'r',encoding="utf-8")
flname = f11.readline()
print(flname)
df1 = pd.read_csv(flname)
st.dataframe(df1,width=1500,height=1500)
如果选择了“分析总览”:
调用可视化图形,显示情感-点赞关系图、各情绪人数统计图、情感-地区折线图、情感分布雷达图、情感分布饼状图、热力地图和词云。
如果选择了“数据总览”:
显示评论内容。