1. Scala 概述
Martin Odersky 于 2001 年开始设计 Scala。Scala 是将「面向对象」和「函数式编程」结合的一种简洁的高级语言。
1.1 语言特点
Scala 是一门以 Java 虚拟机(JVM)为运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言(静态语言需要提前编译的如 Java、C、C++ 等,动态语言如 Js)。
(1)Scala 是一门多范式的编程语言,Scala 支持面向对象和函数式编程(多范式,就是多种编程方法的意思。有面向过程、面向对象、泛型、函数式四种程序设计方法) 。
(2)Scala源代码(.scala)会被编译成 Java 字节码(.class),然后运行于 JVM 之上,并可以调用现有的 Java 类库,实现两种语言的无缝对接。
(3)Scala 单作为一门语言来看,非常的简洁高效。 Scala 在设计时,Martin 参考了 Java 的设计思想,可以说 Scala 是源于 Java,同时 Martin 也加入了自己的思想,将函数式编程语言的特点融合到 Java 中。
对于学习过 Java 的同学,只要在学习 Scala 的过程中,搞清楚 Scala 和 Java 相同点和不同点,就可以快速的掌握 Scala 这门语言。Scala 与 Java 的关系如下:

- Scala 源文件是以“.scala” 为扩展名的
- Scala 程序的执行入口是 main 方法
- Scala 语言严格区分大小写
- Scala 方法由一条条语句构成,每个语句后不需要分号(Scala 语言会在每行后自动加分号),这也体现出 Scala 的简洁性。
- 如果在同一行有多条语句,除了最后一条语句不需要分号,其它语句需要分号。
1.2 环境搭建
常规安装:
- 确保 JDK1.8 安装成功
- 下载对应的 Scala 安装文件 scala-2.12.18.zip
- 解压 scala-2.12.18.zip 到指定目录
- 配置 Scala 的环境变量
homebrew 安装:
brew install scala@2.12
vim ~/.bash_profile
--------------------------------------------------
export SCALA_HOME=/opt/homebrew/Cellar/scala@2.12
命令行窗口输入 scala 检查是否安装成功:

IDEA 配置:

这是 IDEA 第一次跑 Scala 程序可能遇到的问题:

1.3 HelloScala
package io.tree6x7.hello
/**
* @author tree6x7
* @description Helloworld
* @createTime 2023/8/8
*
* 1. 该 object 在底层会生成两个类 HelloScala 和 HelloScala$
* 2. object 表示一个伴生对象,可以先简单理解为一个对象。HelloScala 就是对象的名字,对象类型为 HelloScala$
* 3. Scala 是一个完全面向对象的语言,所以没有静态语法,为了能模拟静态,采用「伴生对象·单例」的方式调用方法:
* 用 object 调用方法的底层逻辑是对 'HelloScala$ 类的静态对象 MODULES$ 调用方法' 的包装。
*/
object HelloScala {
/**
* Scala完全面向对象,故Scala去掉了Java中非面向对象的元素,如static关键字,void类型
* 对于无返回值的函数,Scala定义其返回值类型为Unit类
*/
def main(args: Array[String]): Unit = {
println("HelloWorld")
}
}
采用反编译工具 jd-gui-1.6.6-min.jar 查看 object 编译后生成 HelloScala.class 和 HelloScala$.class 两个文件:

2. 变量
2.1 变量和常量
/* var 变量名 [: 变量类型] = 初始值 */ var i:Int = 13
/* val 常量名 [: 常量类型] = 初始值 */ val j:Double = 6.7
- 能用常量的地方不用变量,var 修饰的变量可改变,val 修饰的变量不可改;
- 声明变量时,必须要给初始值,Scala 要求变量/常量声明时就要初始化;
- 声明变量时,类型可以省略,编译器自动推导,即类型推断;
- 在 Scala 中,整数默认是 Int,小数默认是 Double
- 类型确定后,就不能修改,Scala 是强类型语言;
- var 修饰的对象引用可以改变,val 修饰的对象引用则不可改变,但引用的对象的状态(值)却是可以改变的。
补充:
(1)为什么设计 var 和 val?
在实际编程中,更多是在获取一个对象后,读取该对象的属性或者调用该对象的方法,很少对对象本身操作,比如重新引用个对象。这时,就可以直接定义常量类型,而且常量没有线程安全问题,因此效率高。被推荐使用。如果已知对象不会改变,建议直接定义成 val。
通过反编译可以看出,val 修饰的变量在编译后等同于加上 final。
(2)变量作用域
val a = 1
{
val a = 2
println(a)
}
println(a)
这段脚本执行时,会先打印 2 然后打印 1,这是因为在花括号中定义的 a 是不同的变量,这个变量只在右花括号结束之前处于作用域内。需要注意 Scala 跟 Java 的一个区别是,Scala 不允许你在内嵌的作用域使用一个跟外部作用域内相同名称的变量。在 Scala 程序中,内嵌作用域中的变量会遮挡外部作用域中相同名称的变量,因为外部作用域的同名变量在内嵌作用域内将不可见。
2.2 命名规范
Scala 对各种变量、方法、函数等命名时使用的字符序列称为标识符。即:凡是自己可以起名字的地方都叫标识符。
Scala 中的标识符声明,基本和 Java 是一致的,但是细节上会有所变化,有以下三种规则:
(1)以字母或者下划线开头,后接字母、数字、下划线
(2)以操作符开头,且只包含操作符(+ - * / # !等)
(3)用反引号 ` 包括的任意字符串,即使是 Scala 关键字(39 个)也可以。
- package, import, class, object, trait, extends, with, type, for
- private, protected, abstract, sealed, final, implicit, lazy, override
- try, catch, finally, throw
- if, else, match, case, do, while, for, return, yield
- def, val, var
- this, super
- new
- true, false, null
2.3 输入/输出
a. 字符串输出
基本使用:
- 字符串之间通过
+连接 - printf 同 C/Java,通过
%传值 - 字符串模板(插值字符串)通过
$获取变量值
示例:
object printDemo {
def main(args: Array[String]): Unit = {
val name: String = "liujiaqi"
val age: Integer = 25
println("name=" + name + ", age=" + age)
printf("name=%s, age=%d\n", name, age)
print(s"name=$name, age=$age")
// 如果要对变量进行运算,加 ${...}
println(s"\nname=${name + "NB"}, age=${age - 20}")
val s =
"""
| select
| name,
| age
| from user
| where name="tree"
""".stripMargin
println(s) // stripMargin 会把 "|" 吃掉
}
}
多行字符串,在 Scala 中是利用三个双引号包围多行字符串就可以实现。输入的内容带有空格、\t 之类而导致每一行的开始位置不能整洁对齐。应用 Scala 的 stripMargin 方法,在 Scala 中 stripMargin 默认是 | 作为连接符 —— 在多行换行的行头前面加一个 | 符号即可。
b. 键盘输入
在编程中,需要接收用户输入的数据,就可以使用键盘输入语句来获取。
- StdIn.readLine()
- StdIn.readShort()
- StdIn.readDouble()
- ...
2.4 数据类型
先回顾下 Java 数据类型:
- Java 基本类型:char、byte、short、int、long、float、double、boolean
- Java 引用类型:对象类型
由于 Java 有基本类型,而且基本类型不是真正意义的对象,即使后面产生了基本类型的包装类,但是仍然存在基本数据类型,所以 Java 语言并不是真正意义的面向对象。并且 Java 中基本类型和引用类型没有共同的祖先。
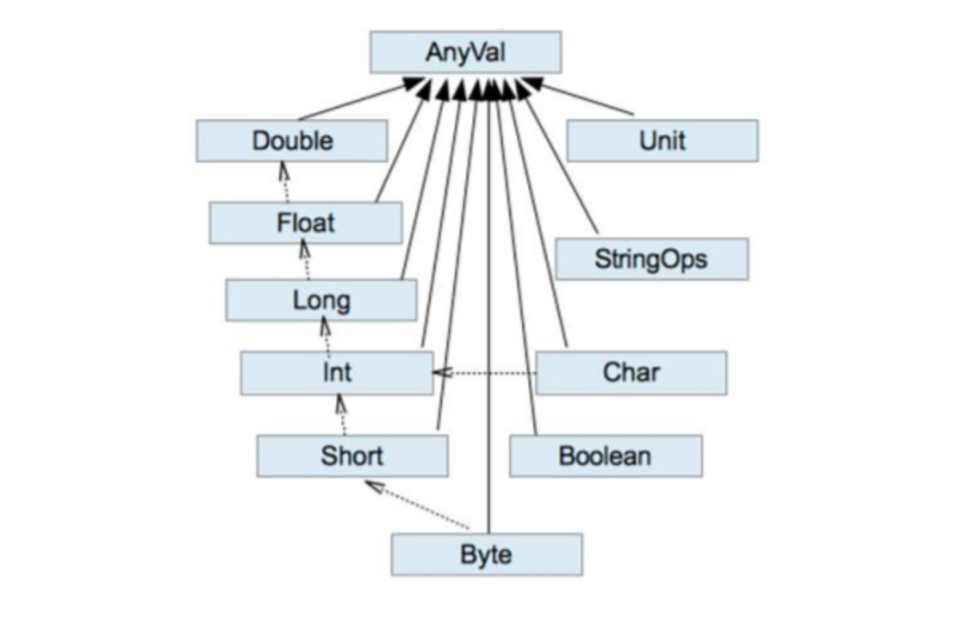
Scala 数据类型体系一览图:

- Scala 中一切数据都是对象,都是 Any 的子类。
- Scala 中数据类型分为两大类:数值类型(AnyVal)、引用类型(AnyRef),不管是值类型还是引用类型都是对象。
- Scala 数据类型仍然遵守,低精度的值类型向高精度值类型的自动转换(隐式转换) 。
- Scala 中的 StringOps 是对 Java 中的 String 增强。
- Unit 对应 Java 中的 void,用于方法返回值的位置,表示方法没有返回值。Unit 是 一个数据类型,只有一个对象就是
()。Void 不是数据类型,只是一个关键字。 - Null 是一个类型,只有一个对象就是 null。它是所有引用类型(AnyRef)的子类。
- Nothing 是所有数据类型的子类。
a. 整数类型
| 数据类型 | 描述 |
|---|---|
| Byte [1] | 8 位有符号补码整数。数值区间为 -128 到 127 |
| Short [2] | 16 位有符号补码整数。数值区间为 -32768 到 32767 |
| Int [4] | 32 位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long [8] | 64 位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 = 2^(64-1) - 1 |
(1)Scala 各整数类型有固定的表示范围和字段长度,不受具体 OS 的影响,以保证 Scala 程序的可移植性。
(2)Scala 的整型常量,默认为 Int 型,声明 Long 型须后加 'l' 或 ' L'。
(3)Scala 程序中变量常声明为 Int 型,除非不足以表示大数,才使用 Long。
b. 浮点类型
| 数据类型 | 描述 |
|---|---|
| Float [4] | 32 位,IEEE 754 标准的单精度浮点数 |
| Double [8] | 64 位,IEEE 754 标准的双精度浮点数 |
(1)Scala 的浮点型常量默认为 Double,声明 Float 型常量须后加 'f' 或 'F'。
(2)浮点型常量有两种表示形式:十进制数和科学计数法(如:5.12e2 = 5.12*10^2,5.12E-2 = 5.12/10^2)
(3)通常情况下,使用 Double 型,应为它比 Float 更精确。
c. 字符类型
字符类型可以表示单个字符(用单引号 ' ' 括起来的),字符类型是 Char。16 位无符号 Unicode 字符(2个字节),区间值为 U+0000 到 U+FFFF。
(1)当给一个 Char 类型变常量赋一个数值后,它打印的是该数字对应的字符(unicode 码表包含 ASCII)
(2)直接把一个字面量赋值给一个变量,编译器会进行范围的确定。
(3)Char 类型是可以进行运算的,它相当于一个整数,因为每个字符有对应的 unicode 码。
(4)如果把一个计算的结果赋值给一个变量,而计算会涉及类型的自动提升,编译报错。
d. 布尔类型
Booolean 类型数据只允许取值 true 和 false。占 1 个字节。
e. Unit/Null/Nothing
| 数据类型 | 描述 |
|---|---|
| Unit | 表示无值,和其他语言中 void 等同。用作不返回任何结果的方法的结果类型。Unit 只有一个实例值,写成 (),这个实例也没有实质意义。 |
| Null | null,Null 类型只有一个实例值 null。 |
| Nothing | Nothing 类型在 Scala 的类层级最低端;它是任何其他类型的子类型。 |
2.5 类型转换
a. 值类型隐式转换
当 Scala 程序在进行赋值或者运算时,精度小的类型自动转换为精度大的数值类型,这个就是自动类型转换(隐式转换)。数据类型按精度(容量)大小排序为:
(1)自动提升原则:有多种类型的数据混合运算时,系统首先自动将所有数据转换成精度大的那种数据类型,然后再进行计算。
(2)把精度大的数值类型赋值给精度小的数值类型时,就会报错,反之就会进行自动类型转换。
(3)Byte、Short 和 Char 之间不会相互自动转换;但它们三者可以计算,在计算时首先转换为 Int 类型。
b. 高级隐式转换和隐式函数
后面讲。
c. 强制类型转换
自动类型转换的逆过程,将精度大的数值类型转换为精度小的数值类型。使用时要加上强制转函数,但可能造成精度降低或溢出,格外要注意。
(1)将数据由高精度转换为低精度,就需要使用到强制转换。
(2)强转符号只针对于最近的操作数有效,往往会使用小括号提升优先级。
d. 值类型和字符串转换
在程序开发中,我们经常需要将基本数值类型转成 String 类型或将 String 类型转成基本数值类型。
(1)基本类型转 String 类型:将基本类型的值 + "" 即可
(2)String 类型转基本数值类型:s1.toInt、s1.toFloat、s1.toDouble、s1.toByte、s1.toLong、s1.toShort
3. 运算符
(1)算数运算符
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| + | 正号 | +3 | 3 |
| - | 负号 | b=4; -b | -4 |
| + | 加 | 5+5 | 10 |
| - | 减 | 6-4 | 2 |
| * | 乘 | 3*4 | 12 |
| / | 除 | 5/5 | 1 |
| % | 取模(取余) | 7%5 | 2 |
| + | 字符串相加 | "He" + "llo" | "Hello" |
(2)关系运算符
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| == | 相等于 | 4 == 3 | false |
| != | 不等于 | 4 != 3 | true |
| < | 小于 | 4 < 3 | false |
| > | 大于 | 4 > 3 | true |
| <= | 小于等于 | 4 <= 3 | false |
| >= | 大于等于 | 4 >= 3 | true |
(3)逻辑运算符
假定 A 为 true,B 为 false。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑与 | (A && B) 运算结果为 false |
| || | 逻辑或 | (A || B) 运算结果为 true |
| ! | 逻辑非 | !(A && B) 运算结果为 true |
补充:Scala 不支持三目运算符。
(4)赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
注意:Scala 中没有 ++、-- 操作符,可以通过 +=、-= 来实现同样的效果。
(5)位运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符 | a << 2 输出结果 240 ,二进制解释: 0011 0000 |
| >> | 右移动运算符 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
| >>> | 无符号右移 | a >>> 2 输出结果 15 ,二进制解释:0000 1111 |
【Scala 运算符本质】在 Scala 中其实是没有运算符的,所有运算符都是方法。
// (0) 标准的加法运算
val i: Int = 1.+(1)
// (1) 当调用对象的方法时,.可以省略
val j: Int = 1 + (1)
// (2) 如果函数参数只有一个,或者没有参数,()可以省略
val k: Int = 1 + 1
4. 流程控制
4.1 分支控制
(1)让程序有选择的的执行,分支控制有 3 种:单分支、双分支、多分支。
(2)Scala 中 if...else 表达式其实是有返回值的,具体返回值取决于满足条件的代码体的最后一行内容。
(3)如果大括号 { } 内的逻辑代码只有一行,大括号可以省略。如果省略大括号,if 只对最近的一行逻辑代码起作用。
4.2 for 循环控制
Scala 也为 for 循环这一常见的控制结构提供了非常多的特性,这些 for 循环的特性被称为 for 推导式或 for 表达式。
(1)基本语法 to / until
// 1 <= i <= 3,前后闭合
for (i <- 1 to 3) {
print("twice")
}
// 1 <= i < 3,前闭后开
for (i <- 1 until 3) {
print(i)
}
(2)循环守卫
for (i <- 1 until 50; if i / 6 != 7) {
print(i + " ")
}
(3)引入变量
// for 推导式一行中有多个表达式时,所以要加 ; 来隔断逻辑
for (i <- 1 to 3; j = i + 3) {
print(j)
}
// 不成文约定:当 for 推导式仅包含单一表达式时使用 (),当包含多个表达式时,一般每行一个表达式,并用 {} 代替 ()
for {
i <- 1 to 10
j <- 6 to 7
} {
print("i=" + i + ", j=" + j + ";")
}
(4)嵌套循环
for (i <- 1 to 2; j <- 1 to 3) {
print("i=" + i + ", j=" + j + ";")
}
(5)循环产出新集合
/* 将遍历过程中处理的结果返回到一个新 Vector 集合中,使用 yield 关键字 */
val res = for (i <- 1 to 10) yield i
println(res) // Vector(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val res2 = for (i <- 1 to 10) yield i * 2
println(res2) // Vector(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
val res3 = for (i <- 1 to 10) yield if (i % 2 == 0) "偶数" else "奇数"
println(res3) // Vector(奇数, 偶数, 奇数, 偶数, 奇数, 偶数, 奇数, 偶数, 奇数, 偶数)
(6)循环步长
// 1 3 5 7 9
for (i <- 1 to 11 by 2) {
print(i + "\t")
}
// 1 3 5 7 9 11
for (i <- Range(1, 11, 2)) {
print(i + "\t")
}
(7)倒序循环
for(i <- 1 to 10 reverse){
print(i + "\t")
}
4.3 while 循环控制
while 和 do...while 的使用和 Java 语言中用法相同。
因为 while 中没有返回值,所以当要用该语句来计算并返回结果时,就不可避免的使用变量,而变量需要声明在 while 循环的外部,那么就等同于循环的内部对外部的变量造成了影响,所以不推荐使用,而是推荐使用 for 循环(for 的循环变量在循环体里不能被修改,即 val 类型)。
4.4 循环中断
Scala 内置控制结构特地去掉了 break 和 continue,是为了更好的适应函数式编程,推荐使用函数式的风格解决 break 和 continue 的功能,而不是一个关键字。
- continue 就用循环里加 if 判断方式代替
- 使用 breakable 函数来实现 break 功能
/* scala.util.control 包的 Break 类给出了一个 break 方法, 可以被用来退出包含它的用 breakable 标记的代码块。*/
var sum = 0
breakable {
for (i <- 1 to 100) {
sum += i
if (sum > 20) {
println("=>" + i)
break()
}
}
}
/* -------------- Step Into 'breakable and break' Source Code -------------- */
/* Break 类实现 break 的方式是抛出一个异常,然后由外围的对 breakable 方法的应用所捕获。*/
def breakable(op: => Unit) {
try {
op
} catch {
case ex: BreakControl =>
if (ex ne breakException) throw ex
}
}
def break(): Nothing = { throw breakException }
5. 函数式编程基础
5.1 概念说明
(1)面向对象编程
解决问题,分解出对象、行为、属性,然后通过对象的关系以及行为的调用来解决问题。
- 对象:用户
- 行为:登录、连接 jdbc、读取数据库
- 属性:用户名、密码
Scala 语言是一个完全面向对象编程语言。万物皆对象。
(2)函数式编程
解决问题时,将问题分解成一个一个的步骤,将每个步骤进行封装(函数),通过调用这些封装好的步骤,解决问题。
例如:请求 => 用户名&密码 => 连接 jdbc => 读取数据库
Scala 语言是一个完全函数式编程语言。万物皆函数。
(3)函数式编程和面向对象编程是两种编程范式。Scala 把「函数式编程」和「面向对象编程」融合在一起了。
用简洁的话语帮我解释下方法(method)和函数(function)的区别
函数是一段代码,通过名字来进行调用。它能将一些数据(参数)传递进去进行处理,然后返回一些数据(返回值),也可以没有返回值。所有传递给函数的数据都是显式传递的。
方法也是一段代码,也通过名字来进行调用,但它跟一个对象相关联。方法和函数大致上是相同的,但有两个主要的不同之处:
- 方法中的数据是隐式传递的;
- 方法可以操作类内部的数据(对象是类的实例化:类定义了一个数据类型,而对象是该数据类型的一个实例化)。
方法和对象相关,函数和对象无关。Java 中只有方法,C 中只有函数,而 C++ 里取决于是否在类中。
5.2 函数基本语法

- 函数体之前的
=也有特别的含义,表示在函数式的世界观里,函数定义的是一个可以获取到结果值的表达式。 - Scala 语言可以在任何的语法结构中声明任何的语法。Scala 中函数可以嵌套定义。
- Scala 函数没有重载和重写的概念(方法可以进行重载和重写)。
方法声明 · 示例:
object TestFunctionDeclare {
def main(args: Array[String]): Unit = {
// 方法1:无参,无返回值
def test(): Unit = {
println("无参,无返回值")
}
test()
test // 如果没有入参,调用时可以不带()
// 方法2:无参,有返回值
def test2(): String = {
return "无参,有返回值"
}
println(test2())
// 方法3:有参,无返回值
def test3(s: String): Unit = {
println(s)
}
test3("jinlian")
// 方法4:有参,有返回值
def test4(s: String): String = {
return s + "有参,有返回值"
}
println(test4("hello "))
// 方法5:多参,无返回值
def test5(name: String, age: Int): Unit = {
println(s"$name, $age")
}
test5("dalang", 40)
}
}
【askGPT】是否可以理解为 AnyVal 的子类都是按值传递,AnyRef 的子类都是按引用传递?
在 Scala 中,无论是 AnyVal 的子类还是 AnyRef 的子类,参数传递方式都是按值传递(pass by value)。Scala 的参数传递方式与数据类型的继承层级无关,而是默认按值传递。
AnyVal 是 Scala 中所有值类型的基类,包括像整数、浮点数、布尔值等基本数据类型,它们在 Scala 内部实现时通常会被优化为非常高效的表示,但在函数调用时仍然是按值传递的。
AnyRef 是 Scala 中所有引用类型(类、对象等)的基类,它包括用户定义的类以及 Java 中的类。同样,无论是 AnyRef 的子类还是普通类,参数传递方式都是按值传递。
无论你传递的是值类型还是引用类型的对象,实际传递的都是值的副本。这与 Java 中的参数传递方式类似。
如果你想在函数内部修改引用类型的对象状态,并让调用者看到这些修改,你需要将对象本身作为参数传递,而不是对象的副本。但需要注意的是,这并不是按引用传递,而只是传递了对象的引用的副本,参数传递方式仍然是按值传递。
5.3 可变参数/默认值
(1)Scala 函数的形参,在声明参数时直接赋初始值(默认值),调用函数时如果没有指定实参,则会使用默认值。如果指定了实参,则实参会覆盖默认值。
(2)参数默认值,一般将有默认值的参数放置在参数列表的后面。
(3)如果函数存在多个参数,每一个参数都可以设定默认值,那么这个时候,传递的参数到底是覆盖默认值,还是赋值给没有默认值的参数,就不确定了(默认按照声明顺序从左到右)。在这种情况下,可以采用带名参数。
(4)Scala 函数的入参默认是 val 的,因此不能在函数中修改。
object FunArgs {
def main(args: Array[String]): Unit = {
// (1)可变参数
def test(s: String*): Unit = {
println(s)
}
// 有输入参数 output: WrappedArray(Hello, Scala)
test("Hello", "Scala")
// 无输入参数 output: List()
test()
// (2) 如果参数列表中存在多个参数,那么可变参数一般放置在最后
def test2(name: String, s: String*): Unit = {
println(name + "," + s)
}
test2("nayeon", "jeongyeon", "jihyo")
// (3) 参数默认值
def test3(name: String, age: Int = 25): Unit = {
println(s"$name, $age")
}
// 如果参数传递了值,那么会覆盖默认值
test3("jihyo", 20)
// 如果参数有默认值,在调用的时候,可以省略这个参数
test3("liujiaqi")
// 一般情况下,将有默认值的参数放置在参数列表的后面
def test4(sex: String = "女", name: String): Unit = {
println(s"$name, $sex")
}
// Scala 函数中参数传递是,从左到右
// test4("wusong") [x]
//(4)带名参数
test4(name = "liujiaqi")
}
}
5.4 函数至简原则
函数至简原则:能省则省
(1)return 可以省略,Scala 会使用函数体的最后一行代码作为返回值;
(2)如果函数体只有一行代码,可以省略花括号;
(3)返回值类型如果能够推断出来,那么可以省略(: 和返回值类型一起省略);
(4)如果有 return,则不能省略返回值类型,必须指定;
(5)如果函数明确声明 Unit,那么即使函数体中使用 return 关键字也不起作用;
(6)Scala 如果期望是无返回值类型,可以省略等号;
(7)如果函数无参,但是声明时加了小括号,那么调用时小括号可加可不加;
(8)如果函数无参,且声明时省略了小括号,那么调用时小括号也必须省略;
(9)如果不关心名称,只关心逻辑处理,那么函数名(def)可以省略。
示例:
object FuncRule {
def main(args: Array[String]): Unit = {
// 0. 函数标准写法
def f(s: String): String = {
return s + " twice"
}
println(f("Hello"))
// 至简原则:能省则省
// 1. return 可以省略,Scala 会使用函数体的最后一行代码作为返回值
def f1(s: String): String = {
s + " twice"
}
println(f1("Hello"))
// 2. 如果函数体只有一行代码,可以省略花括号
def f2(s: String): String = s + " twice"
// 3. 返回值类型如果能够推断出来,那么可以省略(:和返回值类型一起省略)
// 递归函数未执行前是无法推断出结果类型的,在使用时必须有明确的返回值类型
def f3(s: String) = s + " twice"
println(f3("nayeon"))
// 4. 如果有 return 则不能省略返回值类型,必须指定
def f4(): String = {
return "jeongyeon"
}
println(f4())
// 5. 如果函数明确声明 unit,那么即使函数体中使用 return 关键字也不起作用
def f5(): Unit = {
return "jihyo"
}
println(f5()) // ()
// 6. Scala 如果期望是无返回值类型,可以省略等号。并将无返回值的函数称之为「过程」。
def f6() {
"mina"
}
println(f6()) // ()
// 7. 如果函数无参,但是声明了参数列表,那么调用时,小括号,可加可不加
def f7() = "sana"
println(f7())
println(f7)
// 8. 如果函数没有声明参数列表,那么 () 可以省略,调用时 () 必须省略
def f8 = "momo"
// println(f8()) [x]
println(f8)
// 9. 如果不关心名称,只关心逻辑处理,那么函数名(def)可以省略,即「匿名函数」
// 箭头左边是参数列表 => 箭头右边是函数体
def var9 = (x: String) => {
println(s"Hi! $x")
}
def f10(f: String => Unit) = {
f("jihyo")
}
f10(var9) // Hi! jihyo
f10((x: String) => {
println(s">>>> $x <<<<")
})
println(
f10((x: String) => {
println(s"<<<< $x >>>>")
})
)
/*
Hi! jihyo
>>>> jihyo <<<<
<<<< jihyo >>>>
()
*/
}
}
练习:算出一个字符串所有字符的 ASCII 码的乘积
def test5(str: String): Long = {
var ret: Long = 1
val length = str.length
// for (c <- str) ret *= c
for (i <- 0 to length - 1) {
ret *= str.charAt(i)
}
ret
}
def test6(str: String): Long = {
var ret: Long = 1
// step1
// def f(c: Char) = { ret *= c }
// str.foreach(f)
// step2
str.foreach(c => ret *= c)
// step3
// str.foreach(_ => ret *= _)
str.foreach(ret *= _)
ret
}
def test8(str: String, idx: Int): Long = {
if (str.length == 1) {
return str.charAt(0)
}
if (idx == str.length) 1L else str.charAt(idx) * test8(str, idx + 1)
}
5.5 匿名函数
没有名字的函数就是匿名函数。
(x: Int) => { 函数体 }
(1)函数字面量(Function Literal)
- 函数字面量是一种表示匿名函数的语法结构,也被称为“Lambda 表达式”或“函数字面量”。
- 它由
=>符号分隔的参数列表和函数体组成。例如(x: Int) => x * 2表示一个接受一个整数参数并返回其两倍值的函数。 - 函数字面量可以作为函数值的构造方式,也可以直接传递给高阶函数。
- 下述示例中,使用函数字面量
(a, b) => a + b定义了一个接受两个整数参数并返回它们的和的函数。通过将函数字面量赋值给add变量,我们创建了一个函数值。val add: (Int, Int) => Int = (a, b) => a + b println(add(2, 3)) // 输出:5
(2)函数值(Function Value)
- 函数字面量被编译成类,并在运行时实例化成函数值。函数值实际上是函数字面量的实例化,即根据函数字面量创建的对象。
- 函数值是函数对象的实例,它可以像普通的变量一样被引用、传递和操作。
- 函数字面量和函数值的区别在于,函数字面量存在于源码,而函数值以对象形式存在于运行时。这跟类(源码)与对象(运行时)的区别很相似。
- 函数值可以像普通函数一样被调用,并提供相应的参数来执行函数体逻辑。
- 下述示例中,我们定义了一个函数值
multiply,它接受两个整数参数并返回它们的乘积。通过调用multiply(2, 3),我们执行了函数值的逻辑,并将结果赋值给result变量。val multiply: (Int, Int) => Int = (a, b) => a * b val result: Int = multiply(2, 3) println(result) // 输出:6
(3)传递匿名函数至简原则
- 参数的类型可以省略,会根据形参进行自动的推导;
- 类型省略之后,发现只有一个参数,则圆括号可以省略;没有参数和参数超过 1 的永远不能省略圆括号;
- 匿名函数如果只有一行,则大括号也可以省略;
- 如果入参只出现一次,则参数可省且 => 后参数可以用占位符 _ 代替。
示例:
def test5(str: String): Long = {
var ret: Long = 1
val length = str.length
// for (c <- str) ret *= c
for (i <- 0 to length - 1) {
ret *= str.charAt(i)
}
ret
}
def test6(str: String): Long = {
var ret: Long = 1
// step1
def f(c: Char) = { ret *= c }
str.foreach(f)
// step2
str.foreach(c => ret *= c)
// step3
str.foreach(_ => ret *= _)
str.foreach(ret *= _)
ret
}
def test8(str: String, idx: Int): Long = {
if (str.length == 1) {
return str.charAt(0)
}
if (idx == str.length) 1L else str.charAt(idx) * test8(str, idx + 1)
}
【补充】下述示例说明了为什么只有当每个参数在函数字面量中出现不多不少正好一次的时候才能使用这样的精简写法。多个下划线意味着多个参数,而不是对单个参数的重复使用。第一个下划线代表第一个参数,第二个下划线代表第二个参数,第三个下划线代表第三个参数,以此类推。

5.6 部分应用的函数
摘自《Scala编程-第4版》第8.5节
虽然前面的例子用下划线替换掉单独的参数,也可以用下划线替换整个参数列表。例如,对于 println(_) 也可以写成 println _。因此,这里的下划线并非是单个参数的占位符,它是整个参数列表的占位符。注意,你需要保留函数名和下划线之间的空格,否则编译器会认为你引用的是另一个符号,比如一个名为 println_ 的方法,这 个方法很可能并不存在。
val list = List(1, 2, 3)
list.foreach(println _) // = list.foreach(x => println(x))
当你这样使用下划线时,实际上是在编写一个「部分应用的函数(partially applied function)」。在 Scala 中,当你调用某个函数,传入任何需要的参数时,实际上是应用那个函数到这些参数上。
部分应用的函数是一个表达式,在这个表达式中,并不给出函数需要的所有参数,而是给出部分,或完全不给。
举例来说,要基于 sum 创建一个部分应用的函数,假如你不想给出三个参数中的任何一个,可以在“sum”之后放一个下划线。这将返回一个函数,可以被存放到变量中。
有了这些代码,Scala 编译器将根据部分应用函数 sum _ 实例化一个接收三个整数参数的函数值,并将指向这个新的函数值的引用赋值给变量 a。当你对三个参数应用这个新的函数值时,它将转而调用 sum,传入这三个参数。

背后发生的事情是:
名为 a 的变量指向一个函数值对象。这个函数值是一个从 Scala 编译器自动从 sum _ 这个部分应用函数表达式生成的类的实例。由编译器生成的这个类有一个接收三个参数的 apply 方法。生成的类的 apply 方法之所以接收三个参数,是因为表达式 sum _ 缺失的参数个数为 3。Scala 编译器将表达式 a(1, 2, 3) 翻译成对函数值的 apply 方法的调用,传入这三个参数 1、2 和 3。
这个由 Scala 编译器从表达式 sum _ 自动生成的类中定义的 apply 方法只是简单地将三个缺失的参数转发给 sum,然后返回结果。在本例中,apply 方法调用了 sum(1, 2, 3),并返回 sum 的返回值,即 6。
我们还可以从另一个角度来看待这类用下划线表示整个参数列表的表达式,即这是一种将 def 变成函数值的方式。
举例来说,如果你有一个局部函数,比如 sum(a: Int, b: Int, c: Int): Int,可以将它 “包”在一个函数值里,这个函数值拥有相同的参数列表和结果类型。当你应用这个函数值到某些参数时,它转而应用 sum 到同样的参数,并返回结果。虽然不能将方法或嵌套的函数直接赋值给某个变量,或者作为参数传给另一个函数,可以将方法或嵌套函数打包在一个函数值里(具体来说就是在名称后面加上下划线)来完成这样的操作。
至此,我们已经知道 sum _ 是一个不折不扣的部分应用函数,可能你仍然感到困惑,为什么我们会这样称呼它?
部分应用函数之所以叫作部分应用函数,是因为你并没有把那个函数应用到所有入参。拿 sum _ 来说,你没有应用任何入参。不过,完全可以通过给出一些必填的参数来表达一个部分应用的函数。参考下面的例子:

在本例中,提供了第一个和最后一个参数给 sum,但没有给出第二个参数。由于只有一个参数缺失,Scala 编译器将生成一个新的函数类,这个类的 apply 方法接收一个参数。当我们用那个参数来调用这个新的函数时,这个生成的函数的 apply 方法将调用 sum,依次传入:1、传给当前函数的入参和 3。
如果你要的部分应用函数表达式并不给出任何参数,比如 println _ 或 sum _,可以在需要这样一个函数的地方更加精简地表示,连下划线也不用写。

最后这种形式只在明确需要函数的地方被允许,比如本例中的 foreach 调用。编译器知道这里需要的是一个函数,因为 foreach 要求一个函数作为入参。在那些并不需要函数的场合,尝试使用这样的形式会引发编译错误。
5.7 惰性函数
惰性计算(尽可能延迟表达式求值)是许多函数式编程语言的特性。惰性集合在需要时提供其元素,无需预先计算它们,这带来了一些好处。首先,可以将耗时的计算推迟到绝对需要的时候。其次,您可以创造无限个集合,只要它们继续收到请求,就会继续提供元素。函数的惰性使用让您能够得到更高效的代码。Java 并没有为惰性提供原生支持,Scala 提供了。
当函数返回值被声明为 lazy 时,函数的执行将被推迟,直到我们首次对此取值,该函数才会执行。这种函数我们称之为惰性函数,在 Java 的某些框架代码中称之为懒加载(延迟加载)。
示例一:
object LazyDemo {
def main(args: Array[String]): Unit = {
// lazy修饰,sum()函数不会被立即执行,要首次被调用之后再执行
lazy val res = sum(10, 20)
println("================")
// println("res:" + res)
}
def sum(a: Int, b: Int): Int = {
println("sum execute")
a + b
}
}
输出:
================
示例二,代码同示例一,但把 println 那行放开,再次运行输出如下:
================
sum execute
res:30
注意:
(1)lazy 不能修饰 var 变量
(2)函数被 lazy 修饰后,会导致函数的运行被推迟,我们在声明一个变量,如果给变量加 lazy,那么变量的声明也会被推迟,只有被使用时才会声明生效。

5.8 递归编程
在所有的编程范式中,面向对象编程(Object-Oriented Programming)无疑是最大的赢家。但其实面向对象编程并不是一种严格意义上的编程范式,严格意义上的编程范式分为:命令式编程(Imperative Programming)、函数式编程(Functional Programming)和逻辑式编程(Logic Programming)。面向对象编程只是上述几种范式的一个交叉产物,更多的还是继承了命令式编程的基因。
在传统的语言设计中,只有命令式编程得到了强调,那就是程序员要告诉计算机应该怎么做。而递归则通过灵巧的函数定义,告诉计算机做什么。因此在使用命令式编程思维的程序中,是现在多数程序采用的编程方式,递归出镜的几率很少,而在函数式编程中,大家可以随处见到递归的方式。
def maxOfList(xs: List[Int]): Int = {
if (xs.isEmpty) throw new NoSuchElementException
if (xs.size == 1) xs.head
else if (xs.head > maxOfList(xs.tail)) xs.head
else maxOfList(xs.tail)
}
def reverseString(s: String): String = {
if (s.length == 1) s
else reverseString(s.tail) + s.head
}
def factorial(n: Int): Int = if (n == 0) 1 else n * factorial(n - 1)
6. 异常
6.1 catch
【抓】我们将可疑代码封装在 try 块中。在 try 块之后使用了一个 catch 处理程序来捕获异常。如果发生任何异常,catch 处理程序将处理它,程序将不会异常终止。
try {
// code
} catch {
case ex:EXCEPTION_TYPE_1 => { code }
case ex:EXCEPTION_TYPE_2 => { code }
} finally {
// code
}
- Scala 的异常的工作机制和 Java 一样,但是 Scala 没有「checked(编译期)异常」,即 Scala 没有编译异常这个概念,异常都是在运行的时候捕获处理。
- 在 Scala 里,借用了模式匹配的思想来做异常的匹配,因此在 catch 的代码里,是一系列 case 子句来匹配异常。
- 异常捕捉的机制与其他语言中一样,如果有异常发生,catch 子句是按次序捕捉的。 因此,在 catch 子句中,越具体的异常越要靠前,越普遍的异常越靠后,如果把越普遍的异常写在前,把具体的异常写在后,在 Scala 中也不会报错,但这样是非常不好的编程风格。
- finally 子句用于执行不管是正常处理还是有异常发生时都需要执行的步骤,一般用于对象的清理工作,这点和 Java 一样。
6.2 throw
【抛】用 throw 关键字,抛出一个异常对象。所有异常都是 Throwable 的子类型。虽然看上去有些自相矛盾,在 Scala 中 throw 是一个有结果类型的表达式 —— 类型为 Nothing,因为 Nothing 是所有类型的子类型,所以 throw 表达式可以用在需要类型的地方。
def main(args: Array[String]): Unit = {
val res = test()
println(res)
}
def test(): Nothing = {
throw new Exception("不对")
}
Scala 提供了 throws 关键字来声明异常。可以使用方法定义声明异常。它向调用者提供了此函数可能引发此异常的信息。有助于调用函数处理并将该代码包含在 try-catch 块中,以避免程序异常终止。
def main(args: Array[String]): Unit = {
f1()
}
@throws(classOf[NumberFormatException])
def f1() = {
"abc".toInt
}
Nothing 是一个没有此类型值的类型;而 throw 表达式的类型为 Nothing,表达式的计算结果也是一个值。二者不矛盾吗?
