前面介绍了分类、目标检测、分割以及一些常见模型和实现,这一篇接着介绍关键点检测的相关深度学习方法。已经有一些文章记录了关键点在不同领域的应用,比如:人脸关键点检测综述 和 人体骨骼关键点检测综述,其比较详细介绍了人脸检测和骨骼点检测方面的一些论文,其他还有手势识别、服饰关键点检测等应用,这些大都是按照某一个方面的应用进行整理的,这里我按照个人的一些理解(不一定对,如果有错误或者补充各位大佬可以提醒下)将关键点检测分为基于坐标值回归、实例分割和热力图三个方面,并简单介绍常见的网络模型、数据集和评价指标。
一、基于坐标值回归的方法
这种方式比较直接,通过特征提取后,最后直接利用全连接层回归出关键点的坐标值。
1. Deep Convolutional Network Cascade for Facial Point Detection
Paper: https://sci-hub.hkvisa.net/10.1109/cvpr.2013.446
Code: https://github.com/zhaoyuzhi/Deep-Convolutional-Network-Cascade-for-Facial-Point-Detection
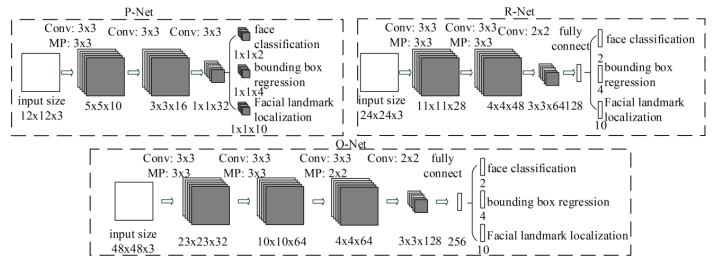
作者提出了拥有三个层级的级联卷积神经网络,最终输出10维向量分别表示人脸的五个关键点信息。



2. Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks(MTCNN)
Paper: https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
Code: https://github.com/BrightXiaoHan/FaceDetector
MTCNN是一种包含P-Net, R-Net和O-Net三个级联的多任务卷积神经网络,可以同时处理人脸检测和人脸关键点定位问题(人脸位置和关键点存在联系)。

二、基于实例分割的方法
这种方法基于实例分割的思路,每个实例都对应了各自的关键点,避免了多目标关键点检测时的配对问题。
1. Mask R-CNN
Paper: https://arxiv.org/pdf/1703.06870.pdf
Code: https://github.com/facebookresearch/Detectron 姿态估计:https://github.com/Superlee506/Mask_RCNN_Humanpose 服饰关键点检测:https://github.com/Hellcatzm/Mask_RCNN
相比于之前实例分割里面说到的,这里的区别是更换了输出Head,即把mask分支更换为关键点分支即可。
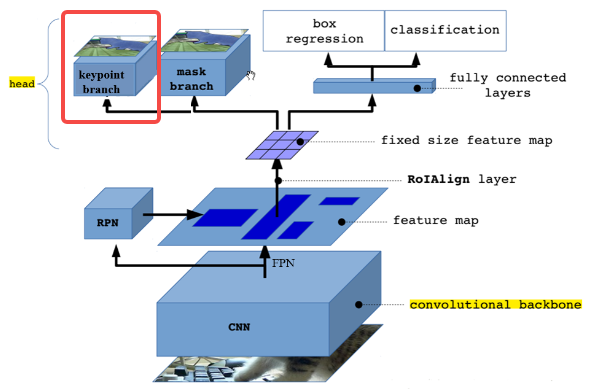
在实现上每一个关键点转换为COCO格式,由3个值组成:横坐标x,纵坐标y,状态v。每一个关键点使用一个56*56的掩码表示,大部分位置为0,仅关键点位置为1。

三、基于热力图的方法
Heatmap将每一个关键点坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键点的概率。
通常采用的是距离关键点位置越近的像素点的概率越接近1,距离关键点越远的像素点的概率越接近0(如Gaussian等)。

1. Robust Facial Landmark Detection via a Fully-Convolutional Local-Global Context Network(PFLD)
Paper: https://www.ce.cit.tum.de/fileadmin/w00cgn/mmk/Verschiedenes/cvpr2018.pdf
Code: https://github.com/ashxjain/Robust-Facial-Landmark 主页:https://www.ce.cit.tum.de/mmk/cvpr2018/
PFLD处理灰度图,通过堆叠卷积提取局部特征,然后利用空洞大卷积提取全局特征,最后输出的关键点融合了局部和全局特征。
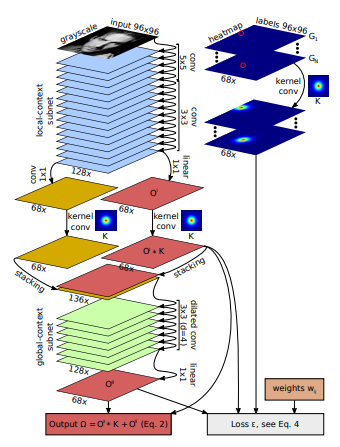
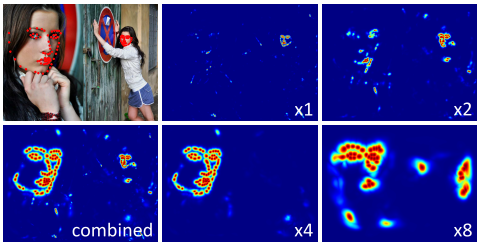
2. Stacked Hourglass Networks for Human Pose Estimation
Paper: https://arxiv.org/abs/1603.06937
Code: https://github.com/zhoujinhai/Stack_HourGlass
提出一种类似沙漏的堆叠网络结构,并利用该网络进行单人姿态估计。

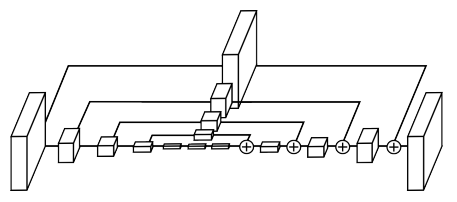
该模型只能对单人进行关键点检测。

3. Associative Embedding: End-to-End Learning for Joint Detection and Grouping
Paper: https://arxiv.org/pdf/1611.05424.pdf
Code: https://github.com/zhoujinhai/pose-ae-train
针对Stacked Hourglass只能检测单人关键点问题,提出了Associative Embedding用于解决多目标关键点配对问题。每一个关键点都对应一个embedding值用于后续配对,配对采用的是Munker算法。

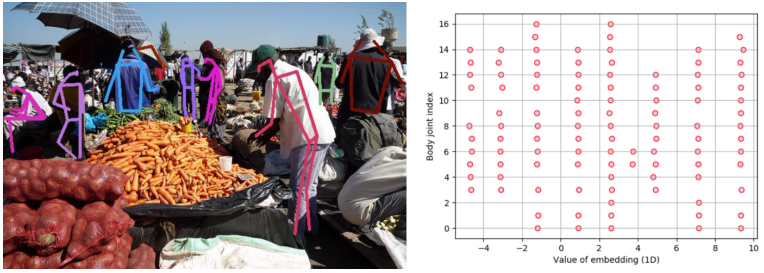
四、常见评价指标
1. PEL(Point-to-point Error for Landmark)
PEL验证关键点检测的准确性
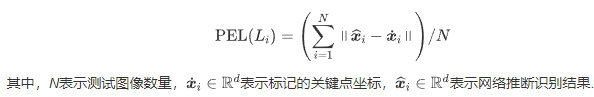
2. APE(Average Point-to-Point Errors)
APE衡量点对点误差的分散程度。

其中L表示每幅图像的关键点总数。
3. PCK(Percentage of Correct Keypoints)
PCK指标指正确检测的关键点所占百分比。

其中\(d_{pi}\)表示第p个人第i个关键点真实值和预测值的欧氏距离, \(T_k\)表示给定的阈值,\(d_{p}^{def}\)表示第P个人的尺度因子
4. OKS(Object Keypoint Similarity)
OKS指标受目标检测中的IoU指标启发,用于评估计算真值和预测人体关键点的相似度

其中\(d_{pi}\)表示第p个人第i个关键点真实值和预测值的欧氏距离,\(S_p\)表示当前人的尺度因子,这个值可以用此人真实目标框所占面积的平方根。\(\sigma_i\)表示第i个关键点真实标注的标准差,\(v_{pi}\)表示第p个人的第i个关键点是否可见,\(\delta\)用于统计可见点的个数。
五、相关数据集
1. 2D数据集
LSP(单人14个关键点):http://sam.johnson.io/research/lsp.html
FLIC(单人9个关键点):https://bensapp.github.io/flic-dataset.html
MPII(单人、多人16个关键点):http://human-pose.mpi-inf.mpg.de/
MSCOCO(多人17个关键点):http://cocodataset.org/#download
AI Chanllenge(多人14个关键点):https://challenger.ai/competition/keypoint/subject
Pose Track(多人15个关键点):https://www.posetrack.net/users/download.php
2. 3D数据集
Human3.6M:http://vision.imar.ro/human3.6m/description.php
HumanEva:http://humaneva.is.tue.mpg.de/
Total Capture:https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox、http://domedb.perception.cs.cmu.edu/dataset.html
JTA Dataset:http://aimagelab.ing.unimore.it/jta、https://github.com/fabbrimatteo/JTA-Dataset
MPI-INF-3DHP:http://gvv.mpi-inf.mpg.de/3dhp-dataset/
SURREAL:https://www.di.ens.fr/willow/research/surreal/data/
UP-3D:http://files.is.tuebingen.mpg.de/classner/up/
DensePose COCO:https://github.com/facebookresearch/DensePose、https://www.aiuai.cn/aifarm278.html、http://densepose.org/#dataset
六、参考链接:
https://zhuanlan.zhihu.com/p/42968117
https://zhuanlan.zhihu.com/p/187598353
https://www.ejournal.org.cn/CN/10.12263/DZXB.20200725
https://blog.csdn.net/litt1e/article/details/126259175
https://zhuanlan.zhihu.com/p/44418924