Hyperparameter tuning
Tuning process
到目前为止,接触到的超参数有:
- 学习效率learning-rate:\(\alpha\)
- Momentum算法的参数:\(\beta\) 加权平均的参数
- Adam算法的参数:\(\beta_1、\beta_2、\epsilon\)
- 神将网络层数:L
- 隐藏层中神经单元数:\(n^{[l]}\)
- 学习效率衰退参数:learning rate decay
- mini-batch size
上述超参数的重要性:
- 首先最重要的是,学习效率learning-rate:\(\alpha\)
- 其次是:Momentum算法的参数:\(\beta\approx 0.9\)、隐藏层中神经单元数:\(n^{[l]}\)、mini-batch size
- 然后是:神将网络层数:L、学习效率衰退参数:learning rate decay
- 最后是基本不太需要调试的用缺省值就挺好,Adam算法的参数:\(\beta_1 = 0.9、\beta_2=0,999、\epsilon=10^{-8}\)
如何选择超参数:
-
因为无法预先知道那个超参数对神经网络更为重要,所以可以进行随机取值。如果说明确某个超参数重要性非常高或者超参数比较少的情况可以进行网格顶定点取值。
-
现在整体范围内粗略的取值进行搜索,然后再取表现好的区域精确搜索。
Using an appropriate scale to pick hyperparameters
上面所说“随机”取值,并不是随便取值,而是在合理的范围内均匀搜索。使用对数标尺搜索参数会更合理一些。
比如超参数\(\alpha ∈[0.0001,1]\),如果直接取值,那可能大约有90%的概率取到[0.1,1]这个范围内,这显然不是我们期望的结果。可以把取值的范围转换到对数标尺上\([log_{10}0.0001,log_{10}1] \Rightarrow [-4,0]\)就相当于把这个取值的范围转换成了\([-4,0]\)区间内均匀取值。这样做实现了对\(\alpha ∈[0.0001,1]\)上的均匀取值。
在python的实现方式,通过对r的取值实现了对α在区间上的均匀取值。
r = -4 * np.random.rand() # r取值范围是[-4,1]的均匀分布
α = 10^r
另外比如指数加权平均参数\(\beta\)的取值的范围是\(\beta ∈[0.9,0.999]\)。对于\(\beta\) 而言并不是很容转换到对数标尺。但是可以通过对\(1-\beta\)的取值来实现对\(\beta\)在区间上的均匀取值。就像上面那也,\(1-\beta∈[10^{-3},10^{-1}],\beta=1-10^{r}\)
β取值0.9和0.905的区别很小,相当于取最近10个或10.5个均值的差异。但同样增加0.005,0.994和0.999就截然不同,前者相当于对最近200个数值的加权平均,而后者相当于最近1000个数值的加权平均。当?接近 1 时,?就会对细微的变化变得很敏感。所以整个取值过程中,需要更加密集地取值。
当然,如果你使用均匀取值,应用从粗到细的搜索方法,取足够多的数值,最后也会得到不错的结果
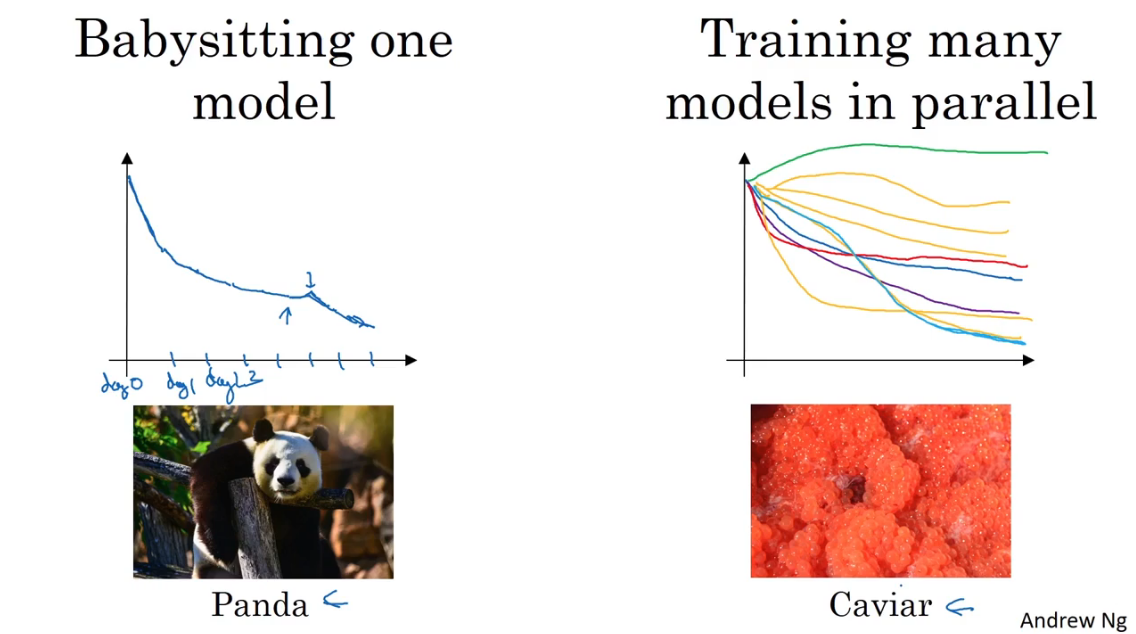
Hyper parameters tuning in practice:Panda vs. Caviar
- 不同的算法和场景,对超参的scale敏感性可能不一样.
- 根据计算资源和数据量,可以采取两种策略来调参
- Panda(熊猫策略):对一个模型先后修改参数,查看其表现,最终选择最好的参数。老师说就像熊猫照顾还小熊猫一样,精心细养。
- Caviar(鱼子酱策略):计算资源足够,可以同时运行很多模型实例,采用不同的参数,然后最终选择一个好的。像鱼养育后代,生意一大堆优胜劣汰。
Normalizing activations int a network
基本思想:在机器学习算法中,可以通过将输入的数据X进行归一化处理,使得每个特征都在同一尺度上,从而加快梯度下降的速度。同样在深度学习的网络中,也可以对X进行归一化处理。把这个思想推广到深度学习的网络中的隐藏层中,隐藏层的输入是上一层的输出,可能也面临尺度不一致的问题,因此也可以对隐藏层的输入A[l]进行归一化(normalizing)处理。所以可以对每个隐藏层的输入进行归一化的,来使得工作效果好的超参数变更等多(反正大体上就是优化了算法,可以更快找出好的超参数,我这么想的捏)。
对于隐藏层输入进行归一化,这里老师说实践中通常是对\(Z^{[l](i)}\)进行归一化处理。
归一化操作如下:省略了对每一层的上标[l],以及\(\varepsilon\)是为了防止方差为非常接近0的数字,一般取10-8。
实际上在深度学习的神经网络中,我们并不希望每层的输入都有相同的分布(平均值为0,方差为1)即不同的\(\mu, \sigma^2\)。尤其是对于sigmoid等激活函数,在0附近密集分布就不能充分利用其non-linear特性。
所以会再次进行处理
\(\tilde z^{(i)}\)将服从均值为\(\beta\),方差为\(\gamma\)的分布,需要注意的是,\(\beta\)和\(\gamma\)不是超参,而是梯度下降需学习的参数。用\(\tilde z^{(i)}\)代替\(z^{(i)}\)输入到激活函数中计算。
Fitting Bactch norm into a neural network
如何把Batch Norm(BN)拟合进神经网络呢?
前向传播:
在原本的神经网络向前传播的过程中,每层是先计算\(z^{[l]}\)然后是计算\(a^{[l]}\)。将BN插入到计算z和a之间。
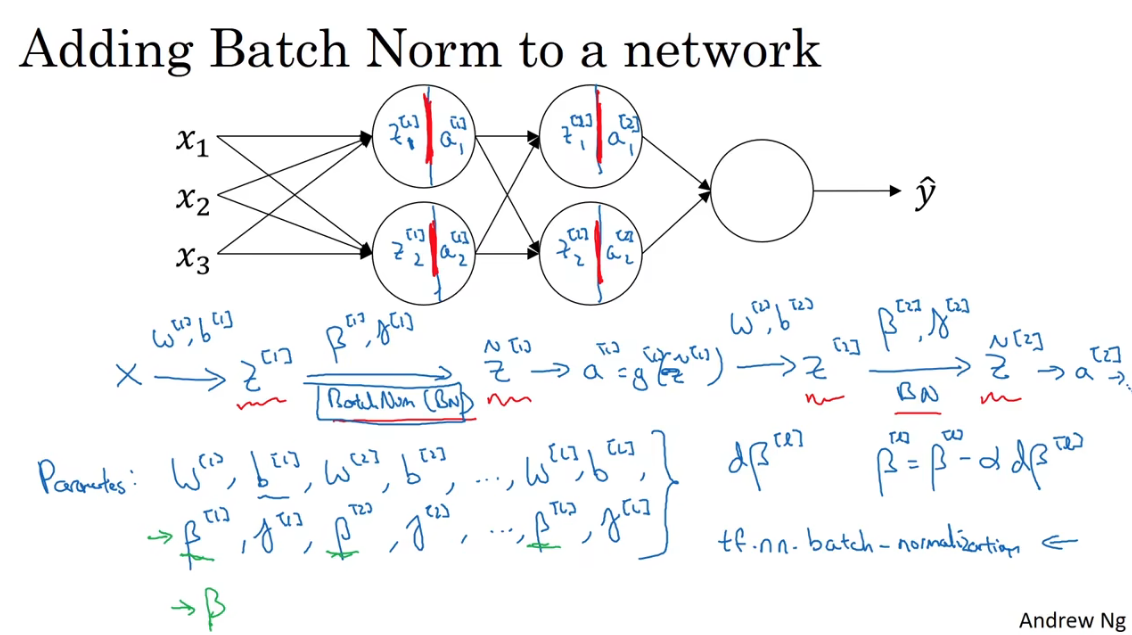
对于Batch Norm,引入了新的参数\(\beta、\gamma\),要注意的是这里的参数不是超参数,是需要“学习”的参数。
参数 \(\beta\) 不同于之前学到的Adma、RMSProp、Momentum梯度下降中的参数。
(在深度学习的框架中,使用一行代码就可以实现Batch Norm)
Working with mini-batches
在实践中,Batch Norm通常和mini-batch一起使用。
在标准化的计算过程中,要先计算z的均值,然后再减去均值,所以这样在此前加入入的常数项就会被均值减法抵消了,所以原来的参数b(bias)就可以省略了,可以设置为0。
所以在应用batch-norm的情况下,参数b就省略了,实际要训练的参数只有W,β和γ。
伪代码实现
for t =1,num of mini batch:
compute forward prop on X^{t}
in each hidden layer, use BN to replace Z^[l]
use backprop to compute dW^[l], dβ^[l], dγ^[l]
update parameters
W^[l] -= α * dW^[l]
β^[l] -= α * dβ^[l]
γ^[l] -= α * dγ^[l]
上面是将min-batch和BN结合,这种batch-norm改进过的梯度下降算法,同样可以使用到前面学过的momentum、RMSprop和Adam。
Why does Batch Norm work?
-
首先,起到了normalization的作用,与对输入的特征值做归一化处理可以加快神经网络的学习类似,BatchNorm让输入隐藏层的数据做相似的事情。
-
Batch Norm让每一层的学习都相对独立,在一定程度上解耦了上一层参数与本层参数。在学习的过程中,尽管上一层的输出会因为参数W和b梯度下降而产生变化,但是通过对隐藏层输入的Norm处理,能让输入保持稳定的分布,即通过\(\gamma、\beta\)维持均值和方差。(就像老师画的那个图)
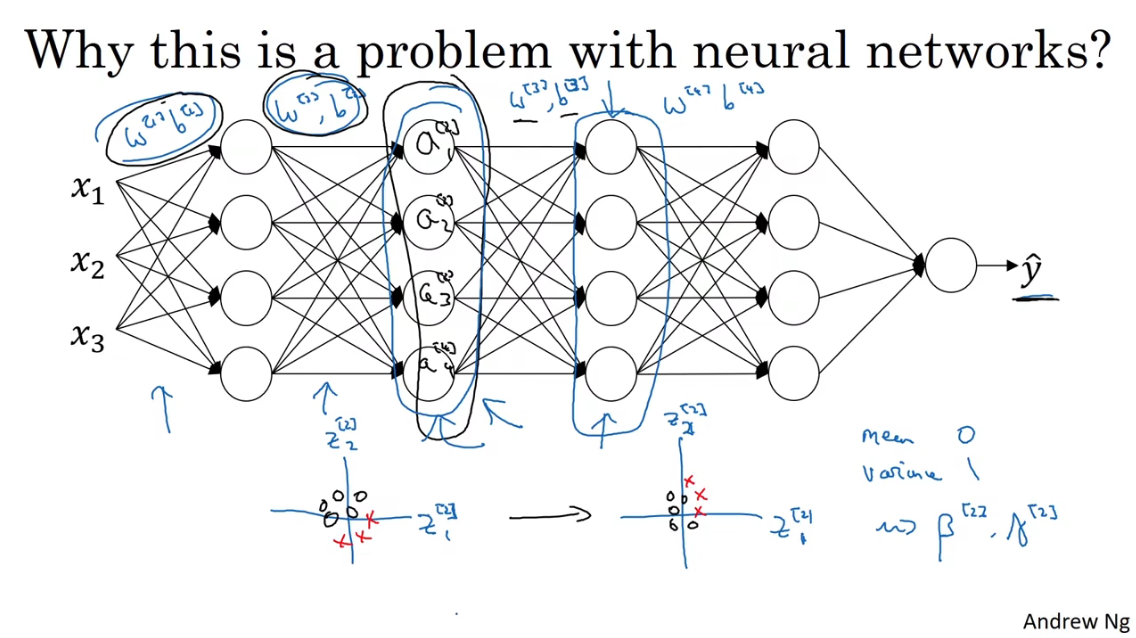
-
另外,Batch Norm还有轻微正则化的效果。虽然不是BN算法的本意,是顺带的副作用。 对于min-batch来说,每一个mini-batch得到的均值/方差不一样,相当于对z的计算引入了一定的噪声,类似于dropout算法,对a的计算引入了噪声,让下游的hidden units不过度依赖于上层的某个hidden unit。mini-batch的size越大,regularization effect越小。
Batch归一化一次只能处理一组mini-batch数据
此外还提到了一个名词Covariate Shift
宏观上讲,Covariate Shift是指模型的输入数据和测试数据来自不同的分布;微观上讲,Covariate Shift是指,每次迭代模型都会经过反向传播调整参数,这样就使得每次迭代,神经网络各个层的输出数据分布都是变化的,这就导致神经网络参数要进行相应的调整从而拟合新的数据分布,疲于奔命。
Batch Norm at test time
BN算法在训练时,是一次处理一个批次的样本;在测试阶段,测试的样本可能只有一个,这种情况下用一个样本的均值和方差进行BN是没有意义的,那该如何在测试阶段进行BN呢?用所有训练集的均值和方差?这显然是不适合的,数据量太大了。
在实践中,常用于测试集的方差和均值是求每个mini-batch的均值和方差的加权均值。进行粗略的估计后,将该方差和均值应用于测试集。
Multi-class classification
之前学习到的神经网络的学习结果都是二分类,比如识别一个图片是不是猫咪,输出是或者不是。如果要识别的多种分类中的一个而不是只识别两类,如识别图中的动物是什么。下面介绍如何处理。
SoftMax Regression
假设要是别的类别个数记为\(C\),比如下面的例子中,要求输出猫、狗、b abykun和其他。这四类,所以\(C=4\)。也就是最后一层神经网络单元的个数\(n^{[l]}=4\)或者说\(n^{[l]}=C\),这四个的概率之和应该近似为1。
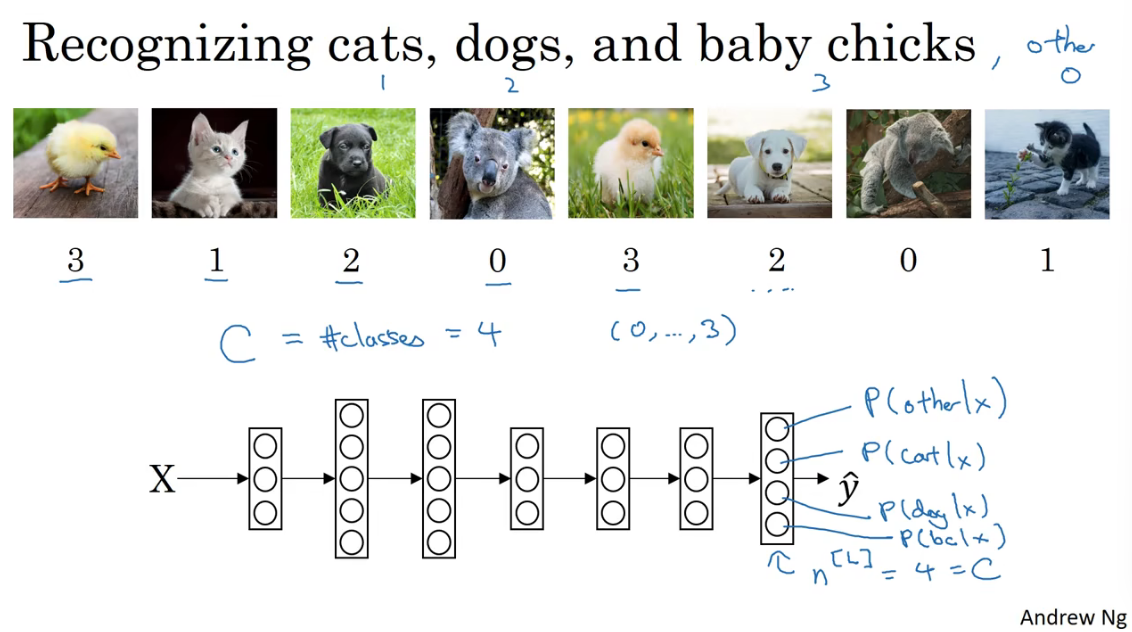
为了实现上述的设,最后一层要使用Softmax Layer。
实现Softmax Layer的方法是在最后一层(输出层)使用Softmax activation function输出a。
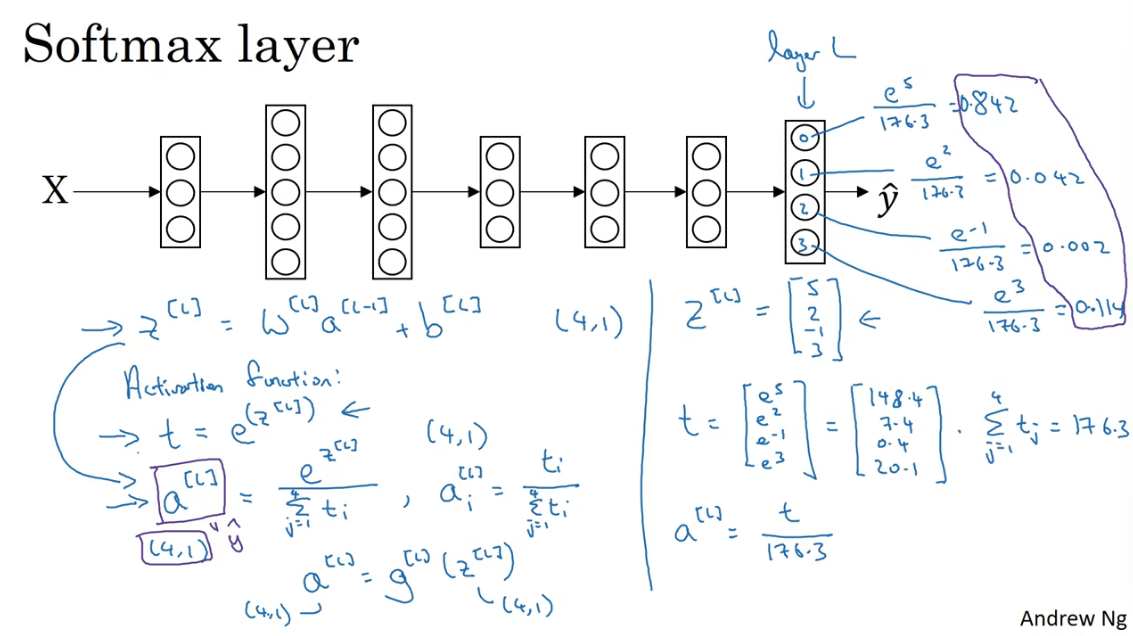
具体来说,就是对最后一层的每个神经单元的输出做e的指数,然后每个占总体的输出。(为什么要这么算嗯,一方面输出结果都是正数;另一方面我们最后一层的要求得各个类型得概率,所以求占比就好了。为什么是e?大概是因为是作为自然常数独有的魅力吧。)
Training a softmax classifier
Softmax regression将logistics regression推广到了C个分类。如果C=2,Softmax regression实际上又变回了logistics regression。
Lost function:$ L(\hat y, y) = -\sum\limits^C_{j=1}y_j\log\hat y_j)$。这个式子就是逻辑回归损失方程的推广,就像C=2,那就是两项求和。
Cost fuction:\(J(W, b, ...) = \frac{1}{m} \sum^m_{i=1}L(\hat y^{(i)}, y^{(i)})\)
。
梯度下降:与二分类的梯度下降主要求别在于最后一层的求偏导上,\(dz^{[L]} = \hat y- y\)
Introducton to programming frameworks
Deep learning frameworks
在我们了解基本的原理之后,可以不再从头开始实现算法,可以调用框架。
常见的框架有下面这些:Caffe/Caffe2、CNTK、DL4J、Keras、Lasagne
、mxnet、PaddlePaddle、TensorFlow、Theano、Torch。
(看弹幕大部飘pytorch或者是后面老师用的TensorFlow,but whatever)
选择框架的标准
- Ease of programming (development and deployment)
- Running speed
- Truly open (open source with good governance)
- Hyperparameter Normalization Programming Frameworks 课程hyperparameter normalization programming frameworks hyperparameter frameworks use_frameworks permissions frameworks directory framework frameworks libraries packages modules frameworks registered languages settings vulnerability frameworks cdeepfuzz automated normalization use_frameworks frameworks作用ios