0. 前言
最近想看点故事书,上网搜了一个盗版,但是只有日文。之前黄队搞了一个汉化教程,我也来试看看。
1. 解包
游戏文件夹里有一个 data.unity3d,很巨大。这说明游戏使用了 Unity 引擎。可以下载一个 Unity 解包器 (UABE)。解包后,Export Raw sharedassets0.assets 并打开,可以看到很多关键文件 (特效、文本、字体、图标等)。
2. 找文本
里面有很多 txt,大概是字母后面跟一个数字。
就改了 A1 的一句话。之后,用 UABE 的 Import Raw,把新文件塞回 sharedassets0.assets,再把这个塞回 data.unity3d。
(结果,游戏没变化)
稍作观察,游戏里的第一句话和 A1 里第一句话不尽相同!经过寻找,X 才是第一章,我们对 X1 进行同样的操作。
(还是一点变化都没有)
试错后,我终究把这种 txt 都删了,游戏照样运行。原来每个章还有一个 book 文件。但是想问开发者:有什么把文本写 2 遍的必要么?
3. 格式分析
这种文件如果随便打开,很乱码。用 Notepad2 把编码改成 UTF-8,可以看到这些日文,中间有神秘指令,旁边是一些游戏中的结构,还有很多黑色块。

我们选用 010 Editor,可以看到文件的每个 byte。原来黑色块的 ASCII 比可见字符小,且大多是 0。并且,非文本非 0 的某些地方也存在规律:对于一段文本的前面 1~2 个 byte,存了一个整数,表示这段文本占用的 byte 个数 (第 \(i+1\) 个 byte 的值是 \(2^i\)) (后面才意识到,是至多 4 个 byte)。
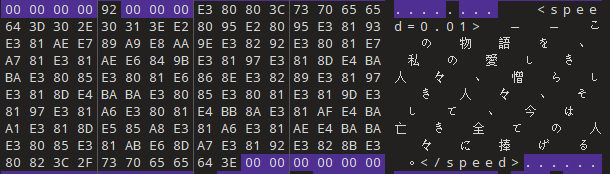
于是,我更改了第一句话及其长度,但是程序直接无法运行。经过多次试错,心态有点崩。最后,我钦定长度不变,把一个平假名改成汉字 (都是 3 个 byte),总算让程序跑起来了。
(此时,我还以为是程序对长度序列进行了 Hash,于是想找到这段代码在哪里。我下了很多逆向工程软件,有静态调试、动态调试,还有同步它们的插件。实力不佳,很长的代码/汇编不知道看哪里,浪费了很多时间。)
(此时还没把文本长度看作 32 位整数。)
4. 机翻
考虑到中文通常比日文短,可以不更改文本长度,翻译后在后面补空格。
申请了百度翻译 API,免费翻译 \(10^6\) 字符/月。上网抄了一份能调用它的 Python 代码,预编译成 pyc。
C++,启动!对于每行,正文前面有一些关键日文,不能动。我们可以选取每行最后一个有日文字符的连续段 (要理解 UTF-8 规则) 翻译。
(但是,文件中有很多 int,所以经常出现 0A byte 被误判为换行,导致误翻关键内容。幸好,正文以“「”或“ ”开头,加一道验证即可。)
X 章翻了 2 个小时。中文长于日文的地方很少,直接不管。塞回去,又是报错。我每次将一个已翻译的前缀和一个未翻译的后缀拼起来塞回去,略显二分地找出了错误地点。
原来是一段文本和后面的一个文本长度搞到同一个连续段里了。于是根据文本前的字串长度,又写了一个程序修了一下。
(此时我才发现,每个文本长度总是以文件种第 \(4k+1\) 个 byte 开头。)
原来,程序其实根本就没有对长度序列进行加密。之前改文本长度导致文件失效,只是因为没把一个 int 放在 4 的倍数的位置啊!但是懒得改了。
5. 改字体
翻译好了!字体感觉不如... 实际上,有 2 种字体混在一起,估计是其中 1 种字体不完全支持中文。
在 sharedassets0.assets 里找到了很多字体。根据这篇文章操作,反复试错后,终于找到了最关键的字体。
大功告成。
6. 尾声
这次历程,聚降智,罗趣味。不过现在我可以看中文故事了,很值得。