一、目标
1、能够用bs4来抓取网络的文字、图片、音频、视频;音频和视频还没有爬取过,哈哈哈!
2、爬取顶点小说中的一部非常好看的修仙类小说《凡人修仙传》链接:https://www.ddyueshu.com/1_1562/
3、以前已经爬过一次了,再爬一次,记录一下过程
二、思路
1、直入正题,利用bs4来爬取数据,首先准备好环境,如果没有安装,请先安装
pip install Beautiful Soup4
pip install lxm
2、小说的链接是:https://www.ddyueshu.com/1_1562/,先对链接进行分析看一下,分析后,章节的链接和每个章节的内容都可以找到,先获取章节链接或每个章节的内容都可以的

3、先获取每个章节链接内容,可以在网页中看到,每个章节链接在标签div = list下面的dd标签里面,可以用soup.find('div',id = 'list').findAll('dd'),先获取list,让在再获取所有的dd标签就可以拿到链接了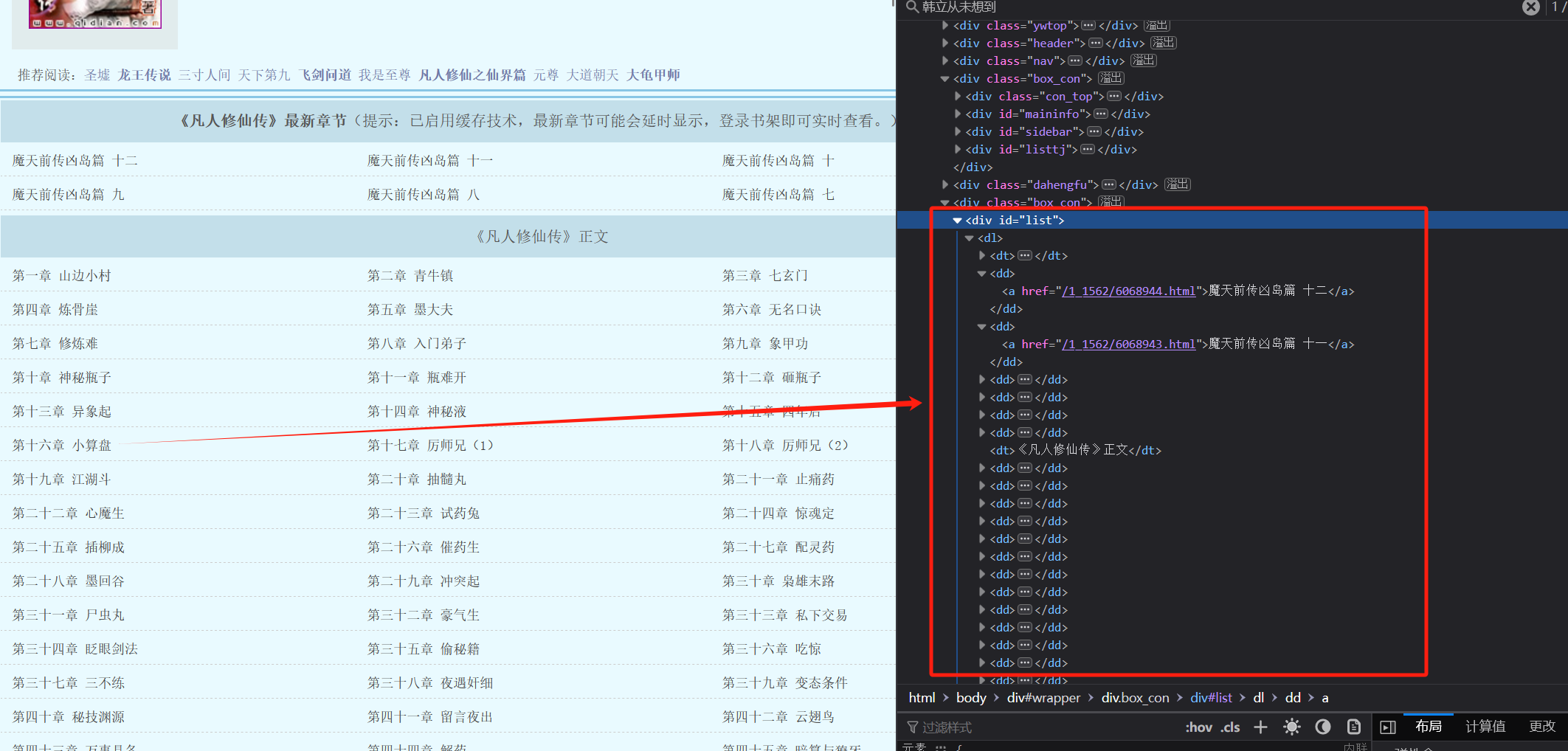
代码如下:
import re,os from bs4 import BeautifulSoup import time if __name__ =="__main__": headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:100.0) Gecko/20100101 Firefox/100.0" } # 1、对首页页面数据进行爬取 url = 'https://www.ddyueshu.com/1_1562/' response = requests.get(url=url,headers=headers) response.encoding = response.apparent_encoding page_text = response.text # 2、实例化一个BeautifulSoup对象,需要讲页面源代码加载到该对象中 soup = BeautifulSoup(page_text,'lxml') # 3、解析章节标题和详情页的url dd_list = soup.find('div',id = 'list').findAll('dd') name = soup.find('h1').text #获取小说名称
4、遍历dd_list,分别用.get_text()获取文本数据和a['href']获取章节链接
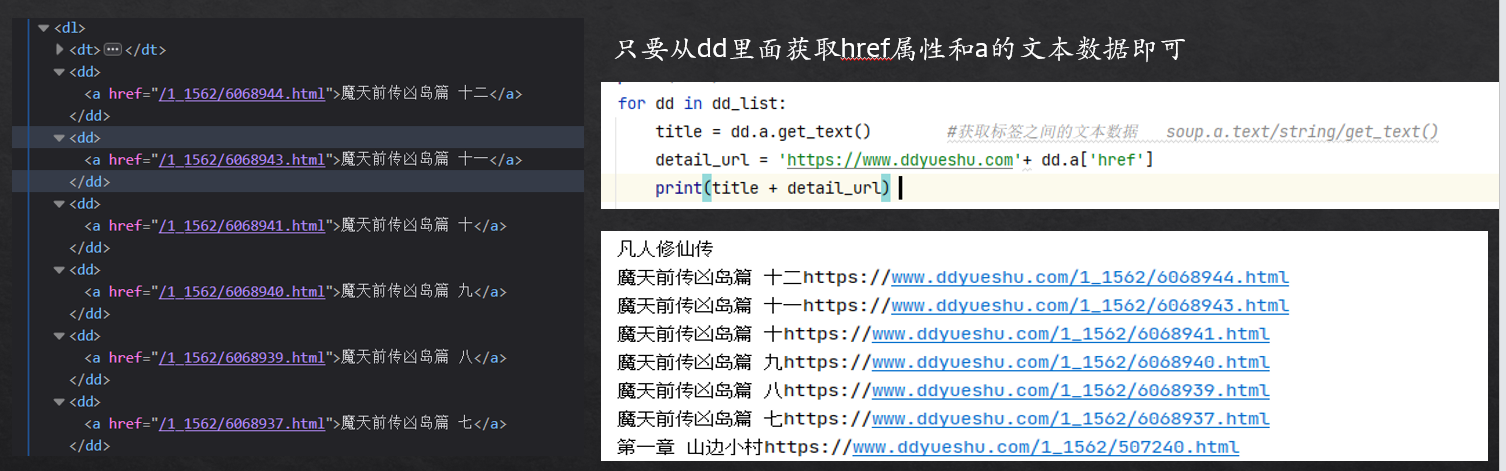
5、章节内容名称和链接都已经拿到了,再次对链接进行request请求,然后把html的内容给到bs4去处理,
#4、对详情页面发起请求,解析章节内容 detail_page= requests.get(detail_url,headers=headers) detail_page.encoding = detail_page.apparent_encoding #5、解析出详情页的章节内容 detail_soup = BeautifulSoup(detail_page.text,'lxml') content = detail_soup.find('div',id = 'content').get_text().replace(u'\xa0',u'')
注意:这里遇到几个问题:
问题1、[Python]"no encoding declared 错误,需要在第一行加入一行代码
#coding=utf-8
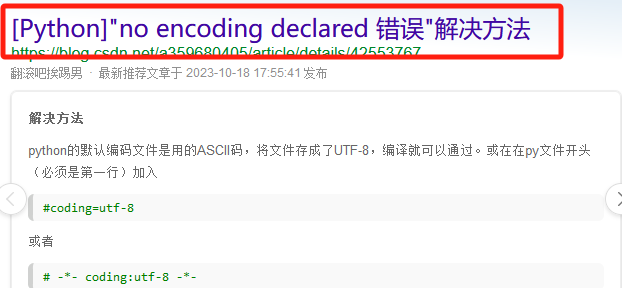
问题2、解决方式:https://blog.csdn.net/qq_35273499/article/details/78011428

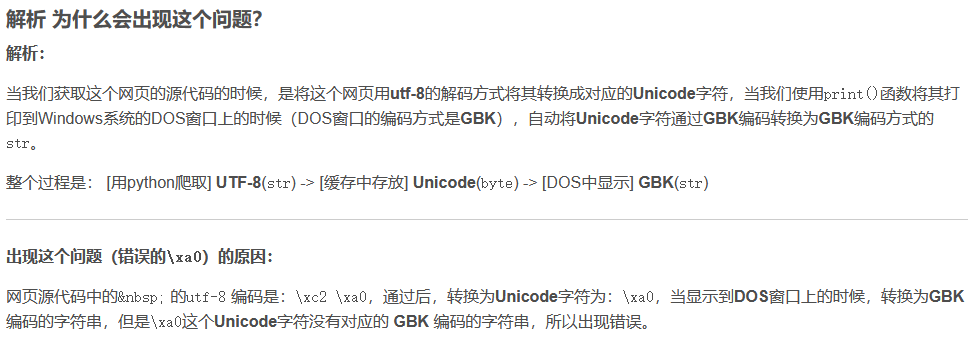
用 ‘’ 来替换 ‘\xa0’ ( ): print(item['detail'][i].replace(u'\xa0 ', u' '))
6、保存数据
with open(name,mode='a')as f: #a追加写入 f.write('\n'+ title +'\n'+content) time.sleep(0.5) print(title,'爬取成功!!!!') print('整部小说下载完成!!!!')
7、下载过程中,显示进度条,下载过程更加优雅,可以用tqdm,需要先安装 pip install tqdm;
用命令没有安装成功,然后就导入模块,然后利用提示进行安装的成功的
只需要在for循环中加上tqdm
for dd in tqdm(dd_list):
三、步骤
完整代码如下:
""" 使用BeautifulSoup来获取整部小说内容 1、爬取凡人修仙传所有章节的标题及章节内容 ;https://www.ddyueshu.com/1_1562/ 2、对首页页面数据进行爬取 3、在首页中解析出章节的标题和详情页的url 4、实例化一个BeautifulSoup对象,需要讲页面源代码加载到该对象中 5、解析章节标题和详情页的url 6、拼接字符串,获取详情页的url,并对其进行请求 7、解析出详情页的相关内容 8、保存数据到本地中 """ import requests import re,os from bs4 import BeautifulSoup import time from tqdm import tqdm if __name__ =="__main__": headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:100.0) Gecko/20100101 Firefox/100.0" } # 1、对首页页面数据进行爬取 url = 'https://www.ddyueshu.com/1_1562/' response = requests.get(url=url,headers=headers) response.encoding = response.apparent_encoding page_text = response.text # 2、实例化一个BeautifulSoup对象,需要讲页面源代码加载到该对象中 soup = BeautifulSoup(page_text,'lxml') # 3、解析章节标题和详情页的url dd_list = soup.find('div',id = 'list').findAll('dd') name = soup.find('h1').text print(name) for dd in tqdm(dd_list): title = dd.a.get_text() #获取标签之间的文本数据 soup.a.text/string/get_text() detail_url = 'https://www.ddyueshu.com'+ dd.a['href'] #4、对详情页面发起请求,解析章节内容 detail_page= requests.get(detail_url,headers=headers) detail_page.encoding = detail_page.apparent_encoding #5、解析出详情页的章节内容 detail_soup = BeautifulSoup(detail_page.text,'lxml') content = detail_soup.find('div',id = 'content').get_text().replace(u'\xa0',u'') with open(name,mode='a')as f: f.write('\n'+ title +'\n'+content) time.sleep(0.5) print(title,'爬取成功!!!!') print('整部小说下载完成!!!!')
四、总结
参考文章:
1、https://cuijiahua.com/blog/2020/04/spider-7.html
2、https://zhuanlan.zhihu.com/p/498392135 bs4的基础内容参考这里