Abstract
事件表分层抽样(SSET),它将ER缓冲区划分为事件表,每个事件表捕获最优行为的重要子序列。
我们证明了一种优于传统单片缓冲方法的理论优势,并将SSET与现有的优先采样策略相结合,以进一步提高学习速度和稳定性。
在具有挑战性的MiniGrid域、基准RL环境和高保真赛车模拟器中的实证结果表明,SSET比现有的ER缓冲采样方法具有优势和通用性。
Introduction
如果事件与最优行为相关,并且历史足够长,与使用均匀采样甚至PER相比,SSET可以显著加快非策略学习的收敛速度。即使这些条件不满足,偏置校正项也会保留Bellman目标,尽管收敛速度可能会减慢。
虽然SSET是一种从ERB中优化采样的新方法,但它是许多现有优先级方法或行为塑造技术的补充。具体来说,SSET可以基于每个表中使用的具有TD-error PER的已知事件应用,从而将重点放在也需要值更新的关键状态上。
贡献:
(1)介绍事件表和事件表SSET框架
(2)我们推导出理论保证,通过适当设计的事件量化样本复杂性的改善,并提供偏差校正,确保Bellman目标保持不变。
(3)我们在具有挑战性的MiniGrid环境和连续RL基准(MuJoCo和Lunar Lander)中实证证明了SSET优于均匀采样或PER的优势,并发现将SSET与TD-error PER或基于潜在的奖励塑造相结合可以进一步改善学习
Related Work
人们提出了许多ERB优先采样的方法。使用最广泛的是优先经验回放(PER) (Schaul等人,2016),它优先考虑具有最大TD错误的状态/动作。然而,PER并不专门关注与最优策略一致的状态:实际上,即使在行为策略改变后,在一个策略下具有零TD误差的经验也可能永远不会再次采样。除了与PER的经验比较外,本文表明,SSET可以与PER一起使用,以利用这两种方法的好处:专注于依赖与最优策略一致的高价值事件轨迹,但也对那些具有高贝尔曼误差的轨迹上的状态进行优先级排序。其他基于模型误差(Oh等人,2021年)或元学习过程(Zha等人,2019年)的优先级来增强vanilla PER的方法也可以类似地与SSET结合使用
SSET并不试图使用同一轨迹的小批量数据,而是依靠采样将轨迹分散到多个小批量中,从而提供沿着轨迹的稳定性和备份。
SSET允许任何基于状态的事件对ERB进行划分,更重要的是存储导致事件的轨迹,而不仅仅是事件本身,这对于确保样本复杂度至关重要。
事件表分层抽样
直观地说,每个表都包含了在接近事件发生区域训练值函数所需的数据,并链接在一起形成了备份的“快车道”(图1),与单一的ER相比,这些数据会被过度采样
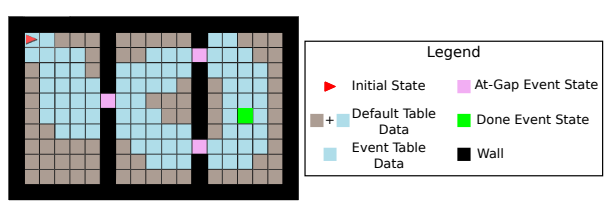
一个示例MiniGrid域,具有达到目标或房间之间的间隙的事件条件。蓝色方块表示可以过度采样的状态的“快车道”,因为它们同时出现在事件表和默认表中。灰色状态只出现在默认表中。
与PER和其他ERB优先级方案一样,SSET在随机环境中会引入偏差

- Experience Efficient Tables Replay Eventexperience efficient tables replay replay conservative estimation experience optimization experience replay experience framework reverb replay fundamentals revisiting experience replay experience remember forget replay prioritized experience sequence replay topological experience replay replay efficient