Replay
Experience Replay with Likelihood-free Importance Weights
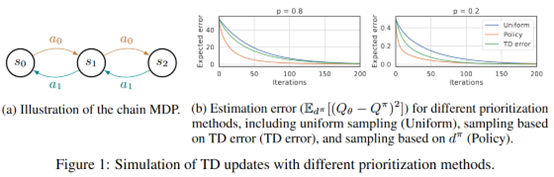 **发表时间:**2020 **文章要点:**这篇文章提出LFIW算法用likelihood作为experienc ......
Experience Replay Optimization
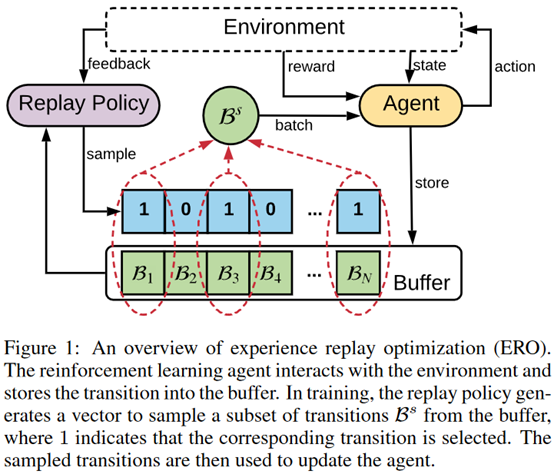 **发表时间:**2019 (IJCAI 2019) **文章要点:**这篇文章提出experience rep ......
The importance of experience replay database composition in deep reinforcement learning
 **发表时间:**2015(Deep Reinforcement Learning Workshop, NIPS ......
Selective Experience Replay for Lifelong Learning
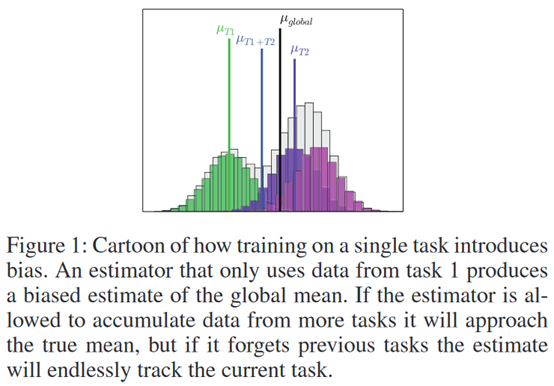 **发表时间:**2018(AAAI 2018) **文章要点:**这篇文章想解决强化学习在学多个任务时候的遗忘 ......
Reverb: A Framework For Experience Replay
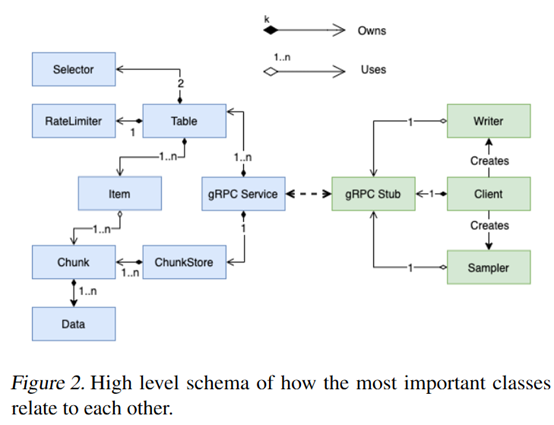 **发表时间:**2021 **文章要点:**这篇文章主要是设计了一个用来做experience replay的框 ......
TOPOLOGICAL EXPERIENCE REPLAY
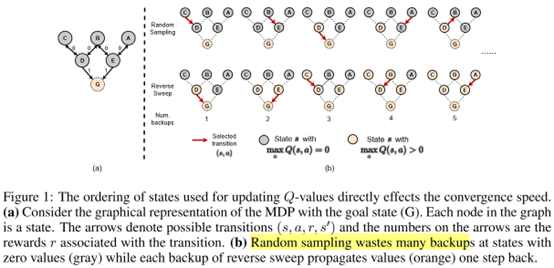 **发表时间:**2022(ICLR 2022) **文章要点:**这篇文章指出根据TD error来采样是低效的 ......
Regret Minimization Experience Replay in Off-Policy Reinforcement Learning
**发表时间:**2021 (NeurIPS 2021) **文章要点:**理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with highe ......
MODEL-AUGMENTED PRIORITIZED EXPERIENCE REPLAY
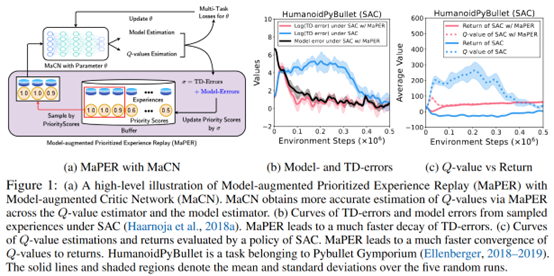 **发表时间:**2022(ICLR 2022) **文章要点:**这篇文章想说Q网络通常会存在under- or ......
Remember and Forget for Experience Replay
**发表时间:**2019(ICML 2019) **文章要点:**这篇文章想说如果replay的经验和当前的policy差别很大的话,对更新是有害的。然后提出了Remember and Forget Experience Replay (ReF-ER)算法,(1)跳过那些和当前policy差别很大 ......
LEARNING TO SAMPLE WITH LOCAL AND GLOBAL CONTEXTS FROM EXPERIENCE REPLAY BUFFERS
 **发表时间:**2021(ICLR 2021) **文章要点:**这篇文章想说,之前的experience r ......
Prioritized Sequence Experience Replay
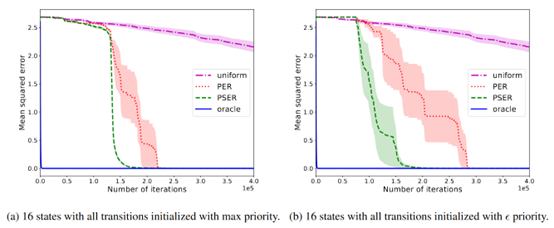 **发表时间:**2020 **文章要点:**这篇文章提出了Prioritized Sequence Exper ......
Revisiting Fundamentals of Experience Replay
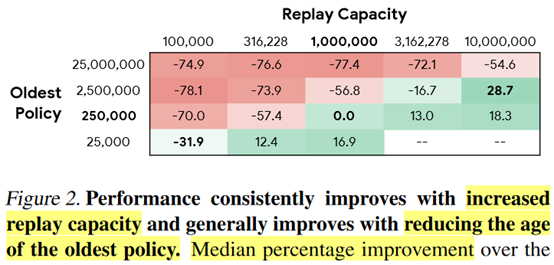 **发表时间:**2020(ICML2020) **文章要点:**这篇文章研究了experience repla ......
Revisiting Prioritized Experience Replay: A Value Perspective
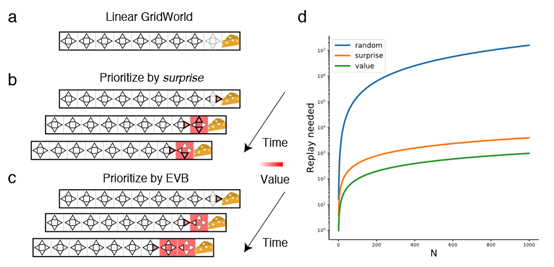 **发表时间:**2021 **文章要点:**这篇文章想说Prioritized experience repla ......
Apr 2021-Lucid Dreaming for Experience Replay: Refreshing Past States with the Current Policy
本文提出了用于经验回放的清醒梦(LiDER),一个概念上的新框架,允许通过利用智能体的当前策略来刷新回放体验。 ......
Feb 2023-Replay Memory as An Empirical MDP: Combining Conservative Estimation with Experience Replay
将 replay memory视为经验 replay memory MDP (RM-MDP),并通过求解该经验MDP获得一个保守估计。MDP是非平稳的,可以通过采样有效地更新。基于保守估计设计了价值和策略正则化器,并将其与经验回放(CEER)相结合来正则化DQN的学习。 ......
May 2022-Neighborhood Mixup Experience Replay: Local Convex Interpolation for Improved Sample Efficiency in Continuous Control Tasks
提出了邻域混合经验回放(NMER),一种基于几何的回放缓冲区,用状态-动作空间中最近邻的transition进行插值。NMER仅通过混合transition与邻近状态-动作特征来保持trnaistion流形的局部线性近似。 ......
APRIL 2022-Explanation-Aware Experience Replay in Rule-Dense Environments
#I. INTRODUCTION 解释是人类智能的关键机制,这种机制有可能提高RL代理在复杂环境中的表现 实现这一目标的一个核心设计挑战是将解释集成到计算表示中。即使在最小的规则集变化下,将规则集(或部分规则集)编码到智能体的观察空间等方法也可能导致严重的重新训练开销,因为规则的语义被明确地作为输入 ......
Event Tables for Efficient Experience Replay
#Abstract 事件表分层抽样(SSET),它将ER缓冲区划分为事件表,每个事件表捕获最优行为的重要子序列。 我们证明了一种优于传统单片缓冲方法的理论优势,并将SSET与现有的优先采样策略相结合,以进一步提高学习速度和稳定性。 在具有挑战性的MiniGrid域、基准RL环境和高保真赛车模拟器中的 ......
MEMORY REPLAY WITH DATA COMPRESSION FOR CONTINUAL LEARNING--阅读笔记
MEMORY REPLAY WITH DATA COMPRESSION FOR CONTINUAL LEARNING--阅读笔记 摘要: 在这项工作中,我们提出了使用数据压缩(MRDC)的内存重放,以降低旧的训练样本的存储成本,从而增加它们可以存储在内存缓冲区中的数量。观察到压缩数据的质量和数量之间 ......