发表时间:2020(ICML2020)
文章要点:这篇文章研究了experience replay in Q-learning,主要考虑了两个方面:replay capacity(buffer的大小,the total number of transitions stored in the buffer)和ratio of learning updates(replay ratio,样本收集和更新的比例, the number of gradient updates per environment transition)。这里的replay ratio没有考虑batch size的大小,只考虑多少个step更新一次,比如DQN是每4步更新一次,那replay ratio就是0.25。
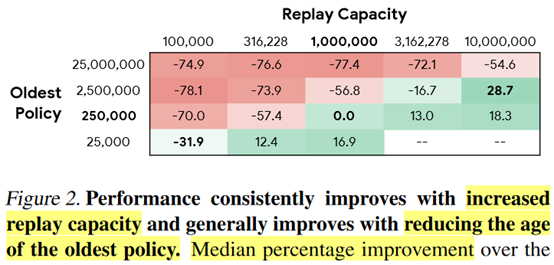
这里作者引入了一个oldest policy,就是说这个buffer里面的样本是由多少个不同的policy产生的,比如1M的buffer,然后replay ratio为0.25,每更新一次网络其实就改变了policy,那么总共oldest policy就有250,000个。
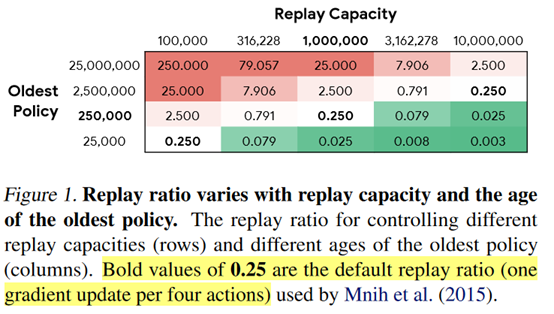
然后主要结论是更大的capacity可以提高性能,n-step return虽然有偏,但是相对于PER, Adam, C51,对性能的提升是最大的。
具体的,(1)Increasing replay capacity improves performance.
这里更大的capacity,其实replay ratio是改变了的,不变的是oldest policy的数量,就相当于我的buffer变大了,同时我的更新频率变低了,这样保持oldest policy的数量不变。
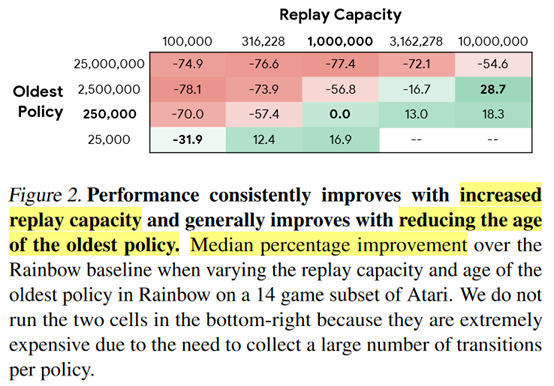
这其实也可以理解,相当于我的样本更多了,state-action coverage更大了,当然就会好些。但是这有个问题就是,fix the total number of gradient updates,同时replay ratio降低,这就意味着和环境的交互次数会变大,sample efficiency其实下降了,每个样本被用到的次数变少了。
(2)Reducing the oldest policy improves performance.
这个结论还是从图2得到的,就是说每一列里面可以看到,oldest policy越少,效果就越好。然后作者就说learning from more on-policy data may improve performance。这里其实还是那个问题,减少oldest policy其实是增加了和环境交互的次数,感觉效果好也是理所当然的。
(3)Increasing buffer size with a fixed replay ratio has varying improvements.
这个实验相当于说这个时候是没有一个一致的结论的。不过我个人觉得这才是最公平的实验,因为这个时候和环境交互的次数是一样的。
之前的实验在Rainbow上做的,接着作者做了一个DQN的实验,然后发现对于DQN来说,基本没啥用
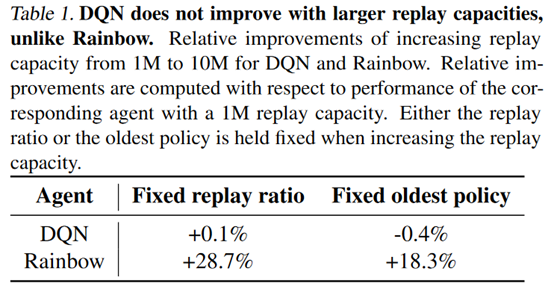
接着作者就研究到底是Rainbow里的哪个改进让它的效果提升了,得出的结论就是n-step return
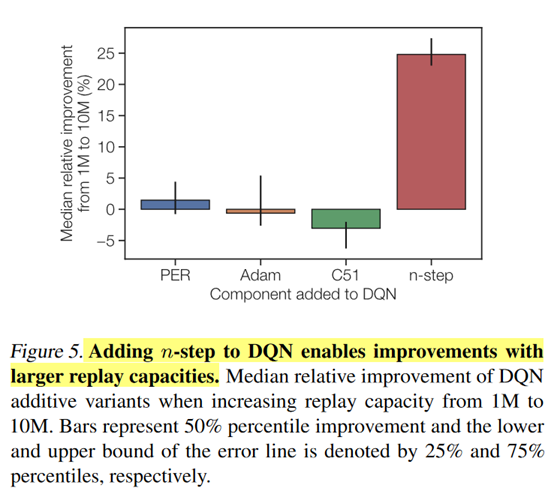
这个结论感觉也不是让人吃惊的。毕竟实验设置里面控制的是总的更新次数,改变replay capacity和oldest policy就会增加和环境的交互次数,这样用来估计n-step return肯定就比DQN的1-step效果好,自然就和replay capacity以及oldest policy这两个因素相关了。
总结:从不同的角度研究了replay buffer的作用吧,个人感觉实验设置是不太科学的。
疑问:感觉还是这个问题,因为是固定了梯度更新次数,那么其实改变replay capacity或者oldest policy会改变和环境交互的次数,这么比较真的公平吗?
- Fundamentals Revisiting Experience Replay offundamentals revisiting experience replay replay conservative estimation experience experience efficient tables replay prioritized perspective revisiting experience optimization experience replay experience framework reverb replay experience remember forget replay prioritized experience sequence replay topological experience replay revisiting