GCR: Gradient Coreset based Replay Buffer Selection for Continual Learning
摘要:本文提出了一种创新的重放缓冲区选择和更新策略,梯度核心集重放(GCR),使用一种设计优化标准。
该方法选择和维持一个“coreset” ,它非常接近迄今为止所有数据的当前模型参数的梯度。实验表明它的性能超过目前最先进方法性能的2%-4%。
1. Introduction
2. Related Work
3. Preliminaries
3.1. Notation
数据集有T个task,每个task有n个类。
模型参数分成特征提取层和线性分类层。
$ \Omega_\theta(x) $ :特征提取层的输出
\(h_\theta(x)\):模型逻辑输出
\(f_\theta(x) = \mathrm{SOFTMAX}(h_\theta(x))\):预测的分布
\(t\): 到目前为止观察到的最后一个任务
\(l\): 分类器损失函数
\(\chi\) : 重放以前任务的数据缓冲区
\(\mathcal{L}_{rep}(\theta,\mathcal{X})\) :在整个重放缓冲区\(\chi\) 的损失函数
3.2. Continual Learning
根据上述符号,在步骤t中持续学习的目标是最小化以下目标:
其中,\(l\)是交叉熵损失函数。我们只能访问任务t的数据点,使得直接优化上述目标很困难。特别是,我们必须确保当模型在学习新任务时,它不应该忘记以前的任务。
3.3. Replay-based Continual Learning
基于replay的CL方法保持着一个小的缓冲区的数据点和来自新任务的数据采样,使模型保留以前任务的知识。按照前面的符号,我们用\(\chi\)表示前面任务的重放缓冲区。基于重放的持续学习方法的一个可能的公式如下:
其中,\({L}_{re_p}\)为重放缓冲区样本上模型的重放损失,\(λ\)为表示重放损失系数的超参数。早期的工作使用交叉熵来处理重放损失,但是最近很多文献提议在选择时存储与数据点相关联的对数(\(z\)),以用于额外的蒸馏损失。作者表明,DER++在任务增量和类增量的离线持续学习场景中都优于之前的一系列建议。DER++的目标是:
4. GCR: Methods
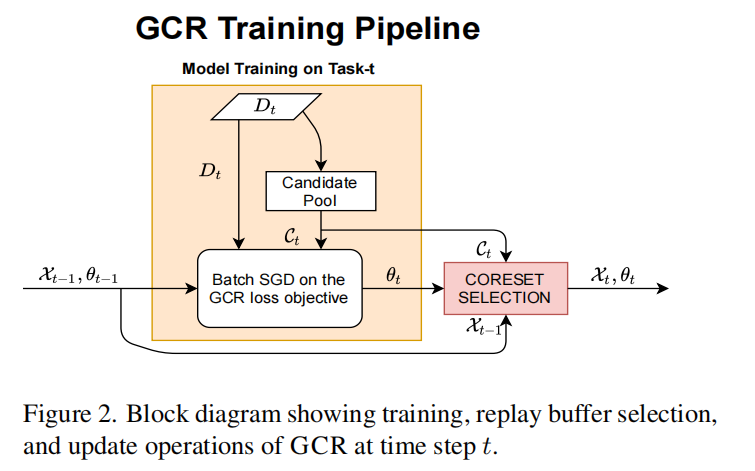
图2显示了整个GCR工作流。我们构建了一个增量更新过程,该过程从当前任务的数据\(D_t\)中选取先前选择的重放缓冲区\(\chi_{t−1}\)和候选池\(C_t\)。我们使用候选池\(C_t\)而不是任务数据\(D_t\),以便有一个更通用的公式,包括离线CL(所有当前任务数据都可用)和OnlineCL(数据在小缓冲区中顺序到达)场景
4.1. GradApprox for Replay Buffer Selection
本文提出了一个加权梯度近似选择重放缓冲的目标。
\(D=\{d_{i}\}_{i=1}^{i=|D|}\) : 给定的数据集
\(W_D=\{w_i\}_{i=1}^{i=|D|}\) : 给定数据集对应样本的权重
\(K\) : 子集的大小
\(\chi\) : 由GradAAcorox选择的一个数据子集(\(|\chi|=K\))
\(W_\chi\): \(\chi\) 对应的权重
优化目标:
在上式中,重放损失函数\(L_{rep}\)是一个加权的个体样本重放损失。GradAncrox选择数据的子集和相关的权重,这样单个样本的重放损失梯度的加权和最接近整个数据集的重放损失梯度。由于这种优化在每个任务后重复应用,近似目标(D上的梯度)也有从上一轮Gradectrox学习到的权重\(W_D\) .它允许我们只使用数据的一个子集来近似整体梯度。此外,这些权值必须在后续的学习算法中使用,因为梯度近似只在具有所选择权值的加权和的条件下才成立。
上述的核心集优化问题可以被应用在任何所选择的重放损失函数上。例如:在DER++上使用它,得到一个加权损失:
第一损失分量是蒸馏损失,第二损失分量是标签损失,每个损失按各自的超参数α和β进行缩放。
算法2给出了GradAptrox算法的详细伪代码:

4.2.GCR Loss objective
我们适应和修改来自DER++重放损失函数与以下两个目标: (a)演示GradApcrox作为回放缓冲选择算法和(b)实现结果,作为一个整体系统,打破当前已知的离线和在线持续学习SOTA性能。为了使用来自DER++ 的重放损失,对于重放缓冲区和候选池中的每个数据样本(x,y),我们还存储了历史模型的logit输出z。因此,重放缓冲区和候选池中的每个数据样本都由(x、y、z)组成。GCR所考虑的损失目标\(L(θ)\)的公式如下:
优化目标由四个组成部分组成。第一个组件(a)测量了与当前任务数据的地面真实标签相比的预测损失。第二和第三个组件(b,c)分别测量了来自重放缓冲区和当前任务候选池组合的数据计算的蒸馏损失和标签损失。第四个也是最后一个损失分量(d)是监督对抗损失的加权版本。这个损失项通过迫使来自同一类的数据样本在嵌入空间中比来自其他类的数据样本更接近,从而改进了模型的学习表示。在我们的工作中,我们总是使用来自组合候选池和重放缓冲区的数据样本作为监督对比学习损失的锚点
DER++还使用了类似于上述(a、b、c)的损失标准。与DER++相比,我们的损失函数的主要区别是(1)损失的加权和公式,并由Gradecrox优化选择权重(我们的主要贡献),以及(2)使用监督对比损失(d)进一步改进学习模型(我们的次要贡献)。
4.3. The GCR algorithm
我们现在将上面描述的各种组件放在一个持续不断地学习的工作流中。GCR算法的图示如图2所示,算法1中有详细的伪代码。在每个步骤中,GCR对当前任务数据对模型进行训练,并使用从候选池\(C_t\)和前一个重放缓冲区\(X_{t−1}\)中选择的大小为\(K\)的加权和来更新重放缓冲区。
候选池中的每个点最初被分配单位权重;例如,\(W_{C_t}\) =1。如伪代码所示,我们使用随机采样来选择候选池。

7. Conclusion, Limitations, and Future Work
我们提出了GCR,一种基于梯度的核心集选择方法,用于基于重放的连续学习,其中我们提出梯度近似作为选择核心集的优化标准,基于监督学习设置的最新进展。我们将这一目标整合到持续学习工作流程中,以选择和更新未来训练的重放缓冲区。我们还在我们的CL目标中包括了一个监督表示学习损失,在模型的生命周期中增强了学习表示。在数据集、重放缓冲区大小和CL设置(离线/在线、classIL/task-IL)中进行的广泛实验表明,GCR在类似设置中显著优于以前的方法,在离线设置中准确率达到2-4%,在在线设置中准确率高达5%。消融研究表明,GCR共复位选择目标优于之前的最佳选择机制,而表征损失也独立地有助于性能的提高。根据高任务数量和图像复杂度的实验,我们的核心集选择方法的规模很好,随着任务数量的增加,提供了越来越显著的收益。我们通过结合GCR,证明了它们的核心思想适用于离线和在线设置(通常是单独研究的)。我们希望进一步的思想交叉融合将继续发生。然而,在将GCR与该领域以前的想法集成起来(例如,维护范例(iCaRL )、函数正则化和自我监督)方面仍然是一个挑战。此外,我们通过使用一个可丢弃的候选缓冲区来简化对候选对象的选择,这增加了在在线CL中可能会有问题的内存开销。在未来,我们将致力于开发流媒体核心集选择机制来解决这些挑战。