时间:2023
学校:慕尼黑大学
创新点:
1.据我们所知,这是第一个试图在TKGF背景下研究零射击关系学习的工作。
2.我们设计了一种基于llm的方法zrLLM,并设法在零射击关系推理中增强各种基于嵌入的TKGF模型。
3.实验结果表明,zrLLM有助于大大提高所有考虑的TKGF模型对包含未见零射关系的事实的预测能力,表明它是有效的和高度自适应的。
摘要:
解决的问题:没有先验图上下文的看不见的零射击关系进行建模、
给出的方案:
1.将KG关系的文本描述输入到LLM中用以生成关系表示
2.将生成的文本输入到基于嵌入的TKGF(TKG forecasting)方法中
优势:
支持llm的表示可以捕获关系描述中的语义信息。这使得具有相似语义的关系,无论是看到的还是不看到的,在嵌入空间中保持紧密,使得TKGF模型即使在没有观察到任何图上下文的情况下也能识别零射击关系。
介绍:
现有方法的局限:现有模型是根据一组关系R的TKG事实进行训练的。它们不能处理任何0 -shot(看不见的)关系,因为训练数据中不存在关于0 -shot关系的图上下文,因此在训练中无法学习到合理的关系表示。
因此我们需要改进现有的方法以此去适应0-shot关系。
我们提出的方法:
1.基于TKG数据集中提供的关系文本描述,我们首先使用LLM来生成一个丰富的关系描述(ERD),其中包含每个KG关系的更多细节
2.然后,我们通过利用另一个LLM(即T5-11B[28])来生成关系表示。我们将ERD输入T5的编码器,并将其输出转换为TKGF模型的关系表示
3.我们设计了一个关系历史学习器(RHL)来捕获历史关系模式,其中我们利用llm授权的关系表示来更好地对零采样关系进行推理
目标:我们将llm提供的自然语言空间与TKGF模型的嵌入空间对齐,而不是让模型仅从观察到的图上下文中学习关系表示。即使没有任何观察到的相关事实,零射击关系也可以用包含语义信息的llm授权表示表示。
相关工作
传统TKGF:
这些方法可以分为两类:基于嵌入的和基于规则的
对TKG的归纳学习:
第一类方法侧重于对看不见的实体进行推理[4,9,10,32],而第二类方法旨在处理看不见的关系[8,24,26]。大多数归纳学习方法基于少射学习(few-shot learning, FSL),如FILT[9]、MetaTKGR[37]、FITCARL[10]、OAT[26]、Most[8]和OSLT[24]。他们首先根据在推理过程中观察到的?-associated事实(?是一个小数字,例如1或3)计算新出现的实体或关系的归纳表示,然后使用它们来预测关于少数镜头元素的事实。这些工作的一个限制是,如果没有?-shot示例,就无法学习归纳表示,这使得它们很难解决零射击问题。与FSL方法不同,SST-BERT[4]对TKG推理进行了时间增强的BERT[7]预训练。它可以对看不见的实体进行归纳学习,但在零概率关系的推理方面还没有显示出它的能力。最近的另一项工作MTKGE[5]能够同时处理看不见的实体和关系。然而,它需要一个包含大量与看不见的实体和关系相关的数据示例的支持图,这与我们关注的零射击问题相去甚远。
基于语言模型的TKG推理:
近年来,越来越多的研究将LMs引入TKG推理中。SST-BERT[4]基于训练TKG生成了一个小规模的预训练语料库,并预训练了一个LM用于编码TKG事实。然后将编码的事实输入到LP的评分模块中。ECOLA[14]将事实与其他与事实相关的文本对齐,并提出了一个联合训练框架,该框架通过bert编码的语言表示增强TKG推理。PPT[34]将TKGF转换为预训练的LM掩码令牌预测任务,并为TKGF微调BERT。
它直接将TKG事实输入到LM中进行答案预测。除此之外,最近的一项研究[17]探索了在llm中使用情境学习(ICL)[3]来预测未来事实而无需调整的可能性。最近的另一项研究GenTKG[21]对LLM进行了微调,即Llama2-7B[30],并让LLM直接在TKGF中生成LP答案。它挖掘时间逻辑规则,并使用它们检索历史事实以生成提示。
局限性:
(1)这些研究都没有研究是否可以使用LMs来更好地推理零枪关系。
(2)仅使用ICL, llm在性能上优于传统的TKG推理方法[17]。通过微调llm(如GenTKG[21])可以大大提高性能,但微调llm需要大量的计算资源。
(3)由于BERT和Llama2等LMs是使用来自不同信息源的庞大语料库进行预训练的,因此在用于解决TKG推理任务之前,它们不可避免地已经看到了世界知识。大多数流行的TKGF基准是从2020年之前构建的TKGs中提取的,例如ICEWS14, ICEWS18和ICEWS05-15[15]。其中的事实是基于2019年之前的世界知识,这意味着LMs可能在其训练语料库中遇到它们,这对lm驱动的TKG推理模型构成了信息泄露的威胁。
模型方法:
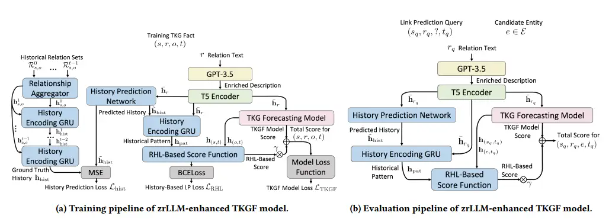
上图表示了zrllm增强的TKGF模型说明:(a)培训管道。(b)评价管道。所有与RHL相关的组件用蓝色块表示。RHL在培训和评估方面的工作方式不同。在训练过程中,由于我们知道训练事实中的两个实体(图1a中的?,?),因此我们可以找到它们之间随时间变化的真实历史关系。我们训练了一个历史预测网络,其目的是在给定两个实体之间的当前关系的情况下生成它们之间的历史关系历史。在评估过程中,我们直接使用训练好的历史预测网络来推断关系历史。
用ERD生成文本表示:
基于KG关系的文本描述,我们使用T5-11B生成文本表示。由于TKG数据集提供的关系文本短小精辟,我们使用另一个LLM GPT-3.5对其进行丰富,以提取更全面的语义。我们的描述充实提示如图2所示。对于每个关系,我们将其关系文本和llm生成的解释的组合视为其ERD。下表中有两个浓缩示例。然后将erd输入T5-11B。T5采用编码器-解码器架构,其编码器可以作为一个模块,帮助理解文本输入,解码器仅用于文本生成。我们将T5-11B编码器的输出,即隐藏表示,用于我们关于TKG推理的下游任务。请注意,尽管erd是由GPT-3.5生成的,GPT-3.5在2021年底之前使用语料库进行训练,但下游TKGF使用的表示仅使用T5-11B生成,以防止信息泄漏。而且,通过我们的提示,GPT-3.5并不知道我们TKGF的潜在任务。我们手动检查GPT-3.5生成的erd,确保不包括2020年后实体的事实信息。

将文本表示对齐到TKG嵌入空间
对于每个KG关系?,生成的文本表示形式为参数矩阵\({\bar{\mathbf{H}}_r\in \mathbb{R} ^{L\times d_w}}\)?为T5中变压器[31]的长度,??为T5编码器输出的每个单词的嵌入大小。\({\bar{\mathbf{H}}_r}\)中的第l行对应于丰富描述中第 ? 词的 T5 编码隐藏表示\({{\mathbf{w}}_l\in \mathbb{R} ^{d_w}}\)。为了将\({\bar{\mathbf{H}}_r}\) 与基于嵌入的 TKGF 模型对齐,我们首先使用多层感知器(MLP)将每个 w? 映射到 TKGF 模型关系表示的维度。\({\mathbf{w}_{l}^{\prime}=MLP\left( \mathbf{w}_l \right) ,where\,\,\mathbf{w}_{l}^{\prime}\in \mathbb{R} ^d\,\,}\)
然后我们使用 GRU 学习 ? 的 ERD\({\bar{\mathbf{h}}_{r}}\)的表示:
\({\bar{\mathbf{h}}_{r}^{\left( l \right)}=GRU\left( \mathbf{w}_{l}^{\prime},\bar{\mathbf{h}}_{r}^{\left( l-1 \right)} \right) ;\bar{\mathbf{h}}_{r}^{\left( 0 \right)}=\mathbf{w}_{0}^{\prime}}\)
\({\bar{\mathbf{h}}_r=\bar{\mathbf{h}}_{r}^{\left( L-1 \right)};l\in[0,L-1] }\) \({ \bar{\mathbf{h}}_{r} }\)
包含来自 ERD 的语义信息,因此,我们可以将其视为基于 LM 的关系表示。我们用基于 LM 的表示替换 TKGF 模型的关系表示,以实现语义集成。
我们修复了每个 \({\bar{\mathbf{H}}_r}\)的值,以在模型训练期间保持 LLM 提供的语义信息完整。这是因为我们不希望关系表示过度强调零样本关系从未出现的训练数据。我们希望模型能够最大限度地受益于语义信息,以获得更好的泛化能力。意义相近的关系的文本描述会表现出相似的语义。由于对于每个关系 ?,\({\bar{\mathbf{H}}_r}\)都是基于 ? 的 ERD 生成的,因此具有密切含义的关系自然会导致 T5 编码器产生高度相关的表示,从而在自然语言空间之上建立连接,而不管观察到的 TKG 数据如何。我们利用这些连接进行零样本关系学习。
关系历史学习:
这些时间模式与实体无关,并且可以反映任何两个实体之间随时间的动态关系。为此,我们开发了 RHL,旨在捕获此类模式。具体来说,我们挑选出在t之前所有和s,o实体有关的历史事实,并按照时间戳进行分组,对于每一组,我们进行关系聚合生成一个关系集合。
\({\mathbf{h}_{s,o}^{t_i}=a_m\bar{\mathbf{h}}_{r_m};a_m=\mathrm{soft}\max \left( \bar{\mathbf{h}}_{r_m}^{\top}MLP_{agg}\left( \bar{\mathbf{h}}_r \right) \right)}\)
\({r_m\in \mathbb{R} _{s,o}^{t_i}}\)表示在 ?? 处桥接 ? 和 ? 的关系。请注意,当我们计算\({\mathbf{h}_{s,o}^{t_i}}\)时,我们还会考虑 ?,以更好地合并与目标事实相关的信息 (?, ?, ?, ?)。为了捕捉历史关系动态,我们采用另一种历史编码 GRU,即 GRURHL:
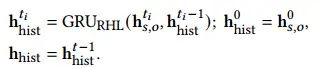
\({\mathbf{h}_{hist}}\) 被视为编码关系历史,直到 ? − 1。请注意,在评估过程中,TKGF 要求模型预测每个 LP 查询的缺失对象 (??, ??, ?, ??),这意味着我们不知道哪两个实体应该用于历史事实搜索4。为了解决这个问题,在训练过程中,我们训练另一个历史预测网络,旨在根据训练事实关系?直接推断关系历史。
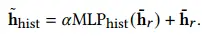
这里,? 是超参数标量,MLPhist 是 MLP。\({\bar{\mathbf{h}}_{hist}}\) 是给定的预测关系历史记录。由于我们希望 \({\bar{\mathbf{h}}_{hist}}\) 代表真实关系历史,因此我们使用均方误差 (MSE) 损失来约束它接近 \({\mathbf{h}_{hist}}\)。
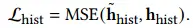
这样,在评估时,我们可以直接使用公式5生成有意义的\({\bar{\mathbf{h}}_{hist}}\)以进行进一步计算。给定 \({\bar{\mathbf{h}}_{hist}}\),我们在 GRURHL 中再执行一步来捕获关系模式,直到t时刻:

\({\mathbf{h}_{pat}}\) 可以被视为包含时间关系模式的综合信息的隐藏表示。受 TuckER [1] 的启发,我们计算训练目标 (?, ?, ?, ?) 的基于 RHL 的分数:

其中 \({\mathcal{W} \in \mathbb{R} ^{d\times d\times d}}\)是一个可学习的核心张量,×1、×2、×3 是三个运算符,表示三种不同模式下的张量积。 h(?,?) 和 h(?,?) 分别是 TKGF 模型计算的 ? 和 ? 的时间感知实体表示。基于 RHL 的分数可以被视为衡量两个实体与关系历史生成的关系模式的匹配程度。我们将此分数与原始 TKGF 模型 ? ′ ( (?, ?, ?, ?)) 计算的分数相结合,并使用 LP 的总分数。

? 是一个可学习的参数。 RHL 使 TKGF 模型能够通过额外考虑时间关系模式来做出决策。仅使用 LLM 授权的关系表示来捕获模式。这保证了 RHL 能够很好地推广到零样本关系。
实验:
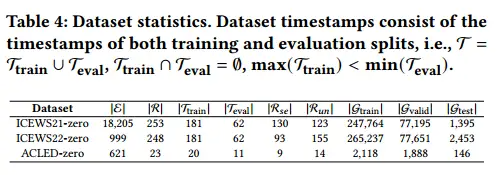
数据集:
我们首先基于综合危机预警系统(ICEWS)[2]数据库构建两个数据集,即 ICEWS21-zero 和 ICEWS22-zero,该数据库是构建 TKG 的最流行的知识库(KB)之一。我们从 ICEWS 每周事件数据中检索 ICEWS 事件以进行数据集构建。 ICEWS21-zero包含2021年1月1日至2021年8月31日发生的事实,而ICEWS22-zero中的所有事实发生于2022年1月1日至2022年8月31日。此外,我们还构建了另一个数据集,即 ACLED-zero,基于较新的知识库:武装冲突地点和事件数据项目 (ACLED6)。在ACLED-zero中,所有事实都发生在2023年8月1日至2023年8月31日期间的非洲、亚太地区、欧洲和中亚。所有三个数据集中的所有事实均基于所描述的社会政治事件用英语。
构建过程:
1.对于每个数据集,我们首先从相关知识库中收集感兴趣时间段内的所有事实(例如,对于 ICEWS21-0,相关知识库是 ICEWS),然后按时间顺序对它们进行排序。
2.然后我们将收集到的事实分成两个部分,其中第一个部分(训练部分)包含用于模型训练的事实,第二个部分包含用于评估的所有事实。第二次分割(评估分割)中的任何事实都晚于第一次分割中所有事实的最大时间戳。由于我们正在研究零样本关系,因此我们在评估分割中排除了其实体未出现在训练分割中的事实,以避免未见过的实体的潜在影响。
3.根据评价分割事实计算所有关系的频率,并设置频率阈值
4.我们将频率低于阈值的每个关系视为零样本关系,并将评估分裂中包含它的每个事实视为零样本评估数据Gtest。我们从训练分割中排除与零样本关系相关的事实,以确保模型在训练过程中看不到这些关系,并将其余的作为训练集 Gtrain。评估分割中的其余事实(其实体和关系在训练期间被TKG模型看到)被视为常规评估数据Gvalid。我们通过 Gvalid 进行模型验证并通过 Gtest 进行测试。我们想要研究当模型在所见关系上达到最大性能时,它们在零样本关系上的表现如何。
实验设置:
所有 TKGF 模型均在 Gtrain 上进行训练。我们将在 Gvalid 上获得最佳验证结果的模型检查点作为最佳模型检查点,并在 Gtest 上报告其测试结果,以研究零样本推理能力。为了在整个测试过程中保持零样本关系“始终不可见”,我们限制所有模型仅在训练集中基于真实 TKG 信息进行 LP,遵循几种流行的 TKGF 方法(例如 CyGNet [38])采用的设置] 和 RE-GCN [20]。许多 TKGF 模型,例如 TiRGN [18],允许使用地面实况 TKG 数据,直到 LP 查询时间戳,包括验证和测试集中的事实。这将违反零样本设置,因为每个看不见的关系都会在评估数据中出现多次,并且在模型观察到它的任何事实后不再是零样本。因此,我们将它们的设置更改为 RE-GCN。请注意,在我们的工作中,Gvalid 和 Gtest 共享同一时间段。这是因为我们希望确保 zrLLM 能够增强零样本推理,同时保持 TKGF 模型在具有可见关系的事实上的性能。以牺牲已知关系的太多性能为代价来提高零样本推理能力是不受欢迎的。为此,我们同时进行验证和测试,并报告模型达到最大验证性能时在 Gvalid 和 Gtest 上的实验结果。
基线模型:
我们考虑最近七种基于嵌入的 TKGF 方法,即 CyGNet [38]、TANGO-TuckER [13]、TANGO-Distmult [13]、RE-GCN [20]、TiRGN [18]、CENET [35] 和 RETIA [ 22]。我们将它们与 zrLLM 结合起来,并展示了它们在 TKG 上的零样本关系学习方面的改进。
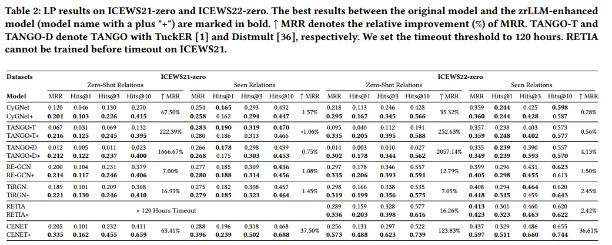
CEWS21-0 和 ICEWS22-0 的 LP 结果。原始模型和 zrLLM 增强模型(模型名称带有加号“+”)之间的最佳结果以粗体标记。 ^ MRR 表示 MRR 的相对改善 (%)。 TANGO-T 和 TANGO-D 分别用 TuckER [1] 和 Distmult [36] 表示 TANGO。我们将超时阈值设置为 120 小时。在 ICEWS21 上超时之前无法训练 RETIA。
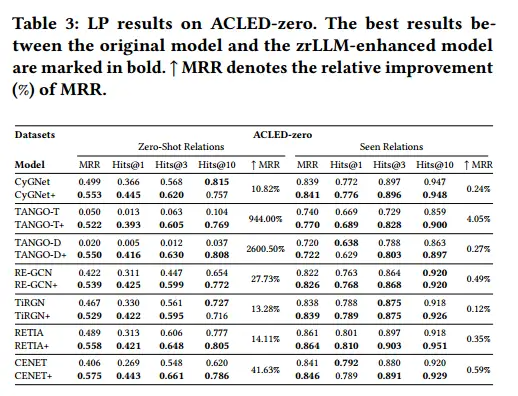
在acled0上的LP结果。原始模型与zrllm增强模型之间的最佳结果以粗体标记。↑MRR为MRR的相对改善(%)。
实验结果:
我们报告了在表2和表3中三个数据集上所有考虑的基线及其zrllenhanced版本的LP结果。研究发现:
(1)zrLLM极大地帮助TKGF模型预测不存在零射关系的事实。
(2)更令人惊讶的是,通过将基线与zrLLM耦合,大多数基线在预测具有已知关系的事实时甚至表现出更强的推理能力。虽然在某些情况下,zrllm增强的模型在包含已见关系的事实上的表现略差,但在整个评估数据(Gvalid∪Gtest)上的总体性能8仍然得到了提高。
(3)对于所有的zrllm增强模型,对于零射击关系的相对改进要远远高于对于具有已知关系的事实的相对改进。
这些发现证明,基于嵌入的TKGF模型受益于从llm中提取的语义信息,特别是当它们处理零射击关系时。
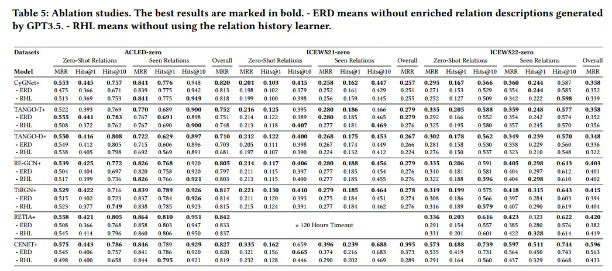
消融实验:
我们从两个方面进行消融研究。(1)首先,我们将数据集提供的关系文本直接输入到T5-11B编码器中,忽略GPT-3.5生成的关系解释,将其输出作为TKGF。从表5,我们观察到,在几乎所有情况下,模型的性能下降的事实,既见零关系和零。在没有erd的情况下,TANGO-TuckER在acled0的零射击情况下表现更好。但是,考虑到整体性能(总体MRR),完全zrLLM的模型仍然显示出最好的结果。这证明了erd的有用性。(2)接下来,我们从所有zrllm增强模型中去除RHL。从表5中,我们发现所有考虑的TKGF模型都可以从学习关系历史中受益,特别是CENET,这证明了RHL的有效性。
- Relational Zero-Shot Knowledge Learning Languagerelational zero-shot knowledge learning distillation relational knowledge construction zero-shot knowledge prompting zero-shot reasoners language models knowledge unifying language roadmap 样本zero-shot learning zero transferable supervision learning language relational zero-shot distillation prediction relational linkless