发表时间:2022(ICLR 2022)
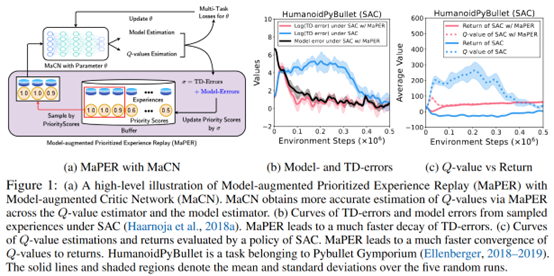
文章要点:这篇文章想说Q网络通常会存在under- or overestimate,基于TD error的experience replay通常都是无效的,因为TD error是基于Q网络的值计算的。作者提出了model-augmented prioritized experience replay (MaPER),用model based的辅助任务来帮助计算priority的score,这样就可以避开Q网络估计不准的问题。
具体的,作者修改了网络结构,让critic网络同时预测reward和状态转移,modify the critic network by additionally predicting the reward and the transition with shared weights, which we call Model-augmented Critic Network (MaCN).然后提出MaPER,计算priority的时候同时考虑模型估计误差和TD error。这个方式的好处是前期可能会更多考虑model error的样本,后期会更多考虑TD error的样本,同时learn model这个辅助任务也会帮助Q value的拟合

具体的,网络的损失变成三项
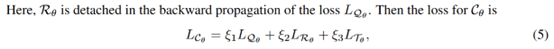
这里R是reward的预测,T是transition的预测,Q就是Q value,注意这里target Q的计算
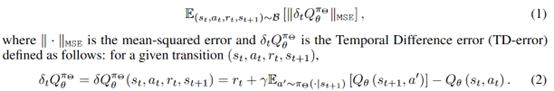
现在这个r不再是真实的环境reward,而是基于model预测的reward了
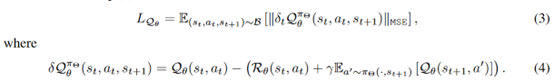
有了这个训练之后,另一个问题就是priority的计算,作者直接三项求和

剩下的就是PER的方式计算采样概率以及权重修正

整个算法如下

效果看起来也不错


总结:出发点是非常有道理的,毕竟TD error确实可能就不准。整个计算代价增加的不多,效果看起来也不错,值得借鉴一下。另外补充材料里面把所有环境的图都贴一遍介绍一下,又学到了。
疑问:这几个error引入了三个权重参数,是看成一个multi-task的任务自适应调整的,也没具体给出数值,感觉可以看看这篇引文,A simple general approach to balance task difficulty in multi-task learning。
- MODEL-AUGMENTED PRIORITIZED EXPERIENCE AUGMENTED REPLAYmodel-augmented prioritized experience augmented prioritized experience sequence replay model-augmented replay conservative estimation experience prioritized perspective revisiting experience experience efficient tables replay optimization experience replay experience framework reverb replay fundamentals revisiting experience replay experience remember forget replay