发表时间:2019 (IJCAI 2019)
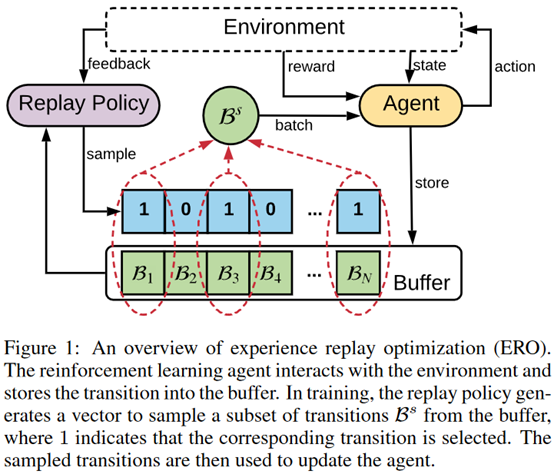
文章要点:这篇文章提出experience replay optimization (ERO)算法,通过learning a replay policy来采样,相对于rule-based replay,可以自动调整采样策略。所以整个过程会交互更新两个policy,agent policy和replay policy,agent policy最大化累计回报,replay policy选择最有用的experience。
具体的,replay policy会给每个状态输出一个0-1的得分作为采样的权重,然后更新的方式和PER一样,每次采到的时候才会再次更新。这个权重拿来用bernoulli分布采0-1的值作为label,然后从buffer里均匀采样的样本需要满足label为1.

这相当于是两阶段的采样,一个是均匀分布采样,另一个是用bernoulli来筛选样本。
下一个问题是如何训练replay policy,作者度量采样更新前后的reward差作为训练的reward,

然后这个reward直接从最近的episodes里面拿出来的,不用重新做evaluate。有了这个之后,就用REINFORCE训练。
作者最后结合了DDPG算法,看起来有一点效果,但是也不明显
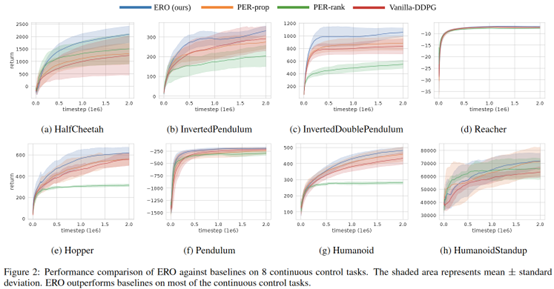
作者最后分析,这个方法更倾向于采more recent transition,low TD error以及high reward(作者认为是因为训到后面buffer里的reward都比较高)。
总结:应该是第一个来学experience replay的,不过效果不是很明显。
疑问:无。
- Optimization Experience Replayoptimization experience replay replay conservative estimation experience experience efficient tables replay experience framework reverb replay fundamentals revisiting experience replay experience remember forget replay prioritized experience sequence replay topological experience replay replay experience