Abstract
在多种多样的设备上部署深度学习模型是一个重要的话题,专用硬件的蓬勃发展引入了一系列加速原语和多维张量计算方法。这些新的加速原语和不断出现的新的机器学习模型,带来了工程上的巨大挑战。本文提出了TensorIR,是为了优化这些有张量计算原语的张量化程序而设计的编译器抽象。TensorIRT概括了现有机器学习编译器使用的嵌套循环表示,使得张量计算称为一等公民。最后,我们在抽象层之上构建了端到端框架,能够自动根据给定的张量计算原语优化深度学习模型。实验结果表明,TensorIR自动使用给定硬件后端的计算原语进行编译,与最先进的手工跨平台优化系统相比具有竞争力。
1 Introduction
部署高性能机器学习模型在多个领域成为了一个新的挑战,包括图像识别,自然语言处理和游戏。机器学习技术的进步带来了广泛的模型需求。与此同时,将智能应用部署到从服务器到嵌入式等各种多样环境的需求也在不断增长。

硬件专业化使这个问题更加复杂化(图1)。为了实现机器学习模型加速的目标,现代硬件后端引入了专用的原语加速张量计算(e.g. Nvidia Tensor Core, Google TPU)。领域专家也开始开发微内核原语,精心组织一系列高度优化的指令序列,加速领域特定张量算子库。这些硬件指令和微内核原语通常在多为张量区域运行,并高效地进行张量计算,例如多维加载,点乘,矩阵乘。我们称这些不透明的张量计算加速构造为张量指令(tensorized intrinsics),使用这些指令的转换过程称为张量化(tensorization)。为了达到这些硬件后端最好的性能,现代机器学习系统需要优化这些包含多层嵌套循环,多维加载,和张量指令的程序。我们将这个问题称为张量化程序优化。
目前大多数张量化程序是领域专家优化的,将张量原语与多维循环,线程模式和数据cache组合在一起,制作专门的算子库,例如Intel MKL-DNN,ARM Compute Library和NVIDIA cuDNN。这些算子库被机器学习框架使用,例如TensorFlow,PyTorch和MXNet。但是支持新的模型和后端带来了庞大的工程量,而这些算子库需要迭代周期才能适配这些变化和新的机器学习应用,这阻碍了机器学习模型的发展。
本文提出使用一种自动编译方法解决张量程序优化问题。先前多数工作主要研究机器学习编译如何在嵌套循环变换的空间中搜索一个程序,没有解决自动处理张量化程序的问题。将自动张量化程序优化引入能够释放现代硬件后端领域特定加速的能力,我们提出为了实现这个目标面临的关键挑战:
- abstraction for tensorized programs。为了构建张量化程序的自动编译器,我们需要一个抽象来务实地捕获给定机器学习算子可能的等价张量化计算。尤其是,这种抽象需要能够表示出多维内存访问,线程层次,和不同硬件后端的张量计算原语。这种抽象还需要能够表示机器学习种常见的大多数算子。
- large design sapce of possible tensorized program optimizations。另一个挑战是为给定算子自动生成优化的张量化程序。一个编译器可能会使用到领域专家可能用到的丰富知识,包括高效使用循环分块,数据layout变换。并且这些变化需要和张量化计算结合进行,为分析和自动化带来了更高的复杂性。这些组合形成了庞大的搜索空间,我们需要一种高效的方法在给定空间中找到优化的张量化程序。
为了解决这些挑战,我们提出了TensorIR,一种自动化张量程序优化抽象。首先,我们引入了一种新的结构,称为block,能够划分张量程序,并与外部嵌套循环隔离。这种新的抽象使得我们能有效地表示张量化计算,并将它们与嵌套循环,线程与内存层次进行组合。我们还引入程序变换原语来表示可能优化的丰富空间。我们在抽象和变换原语的顶层采用了一种新的自动化调度算法。另外,TensorIR抽象允许我们表示和优化那些包含不规则计算和张量计算的混合程序,扩展了正常张量表达式的支持。本文作出了以下贡献:
- 提出了一种全新的张量化程序抽象,能够从循环变换中隔离出张量化计算,同时,这种抽象允许我们统一表示张量计算指令和硬件约束。
- 构建了变换原语来生成丰富的张量化程序搜索空间,并有正确性验证。
- 设计并实现了张量化感知自动调度器。
我们将TensorIR与端到端编译框架整合,结果超越了现有的机器学习编译方法,最高有7的加速,自动为给定平台生成高性能的程序。
2 Overview
本章介绍我们方法的关键灵感,并给出本文的概述。为了便于思考,我们从一个领域专家如何优化张量化程序的例子开始(图2)。张量计算指令通常对应原始张量算子的一个子问题。所以,领域专家自然会想到分而治之的方法,将原程序划分为张量化计算和嵌套循环,分别进行优化。这种分而治之的方法能够让开发者专注于子问题,不需要担心外部的影响。另外,这能够让我们针对多个张量计算实现。

多数现有的机器学习编译器采用两种方法(图3)。Halide,TVM,Tiramisu,AKG,MLIR/Affine,和AMOS采用自底向上的方法,根据标量算子周围的循环迭代器建模搜索空间,然后搜索最优的嵌套循环变换(通过搜索或多面体优化)进行优化。HTA,Fireiron和Stripe使用自顶向下的方法,通过嵌套多面体结构,逐步拆解问题为子问题。在手工优化时分而治之十分有效,自然会想到能否将这种思想引入机器学习编译器的设计。
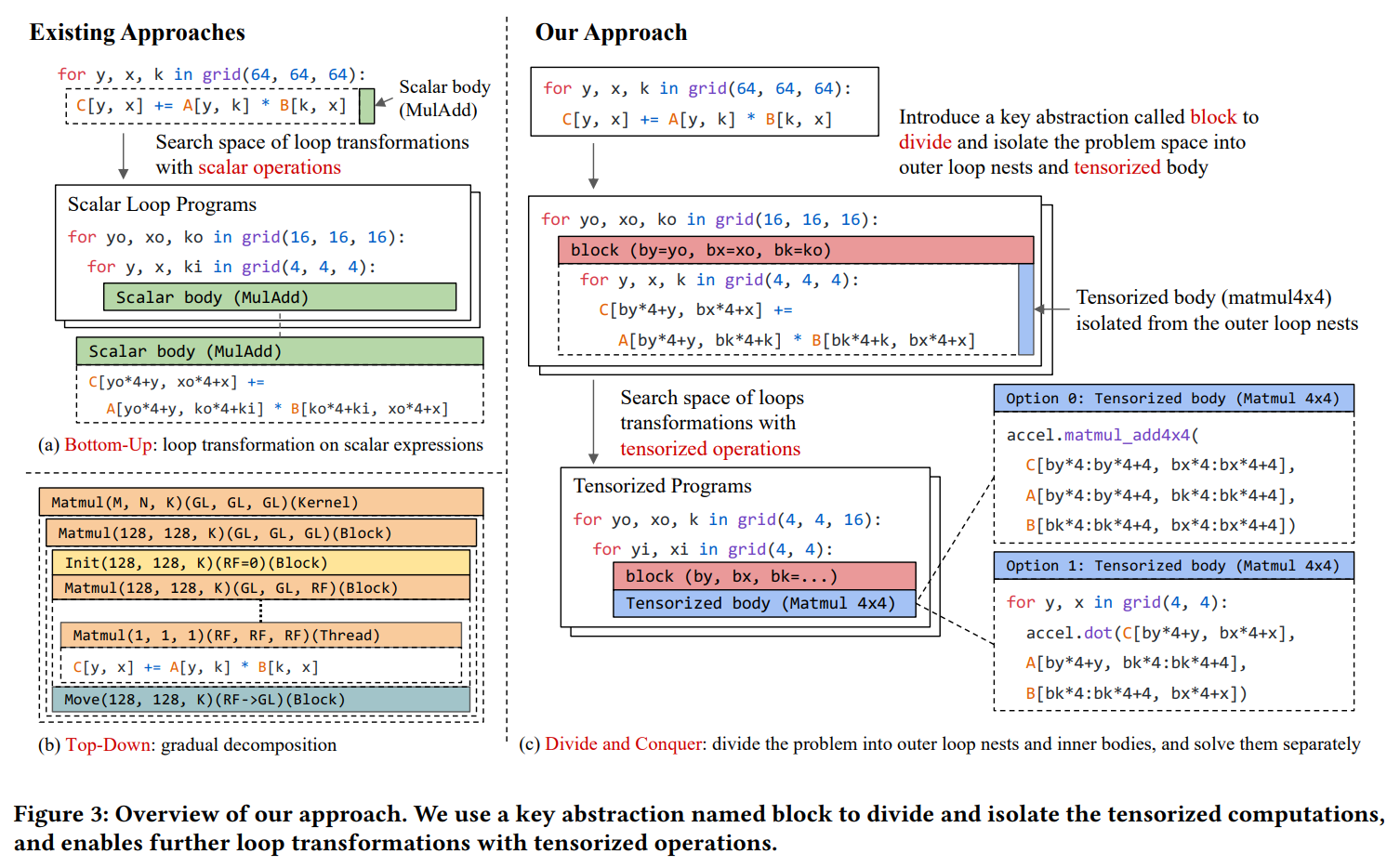
我们在本文中给出了肯定的回答。特别地,我们在嵌套循环种引入了block抽象,一个block包含一些签名信息,以此将内部问题空间和外部问题隔离。利用block,我们能够继续在外部和内部分别进行变换,使用block前面作为接口。类似于手工分而治之方法,block一个常见的使用场景是表示后端的张量计算原语,但是我们可以隔离更大的子问题,如果分而治之有效的话。重要的是,张量计算是TensorIR的一等公民。包含blocks的嵌套循环可以视为迭代空间的抽象。在第3章中我们对TensorIR抽象进行详细设计。
为了自动进行张量程序优化,我们构建了一个可能方法的搜索空间,划分由硬件张量计算原语指导的问题。进一步搜索可能的方法来解决程序变换子问题。我们在第4章介绍张量程序自动调度算法。
我们分而治之的方法涵盖了之前的编译器方法(自底向上,自顶向下)构建的搜索空间,并且概括了HPC和ML工程的典型优化技巧为一个抽象,允许自动张量化。我们自动化手工库和编译pipeline的常见决策,能够自动的生成与供应商提供库相当的性能,我们在第五章阐述实验结果。
3 TensorIR Abstraction
本章介绍TensorIR抽象。图4给出了TensorIR程序的一个例子。我们引入TensorIR的Python-AST(抽象语法树)方言来让开发者直接使用Python构建并转换程序。一个TensorIR程序包含三个主要元素:多维buffers,嵌套循环(包含可能的GPU线程绑定),以及blocks。一个block可以包含一个或多个有子block的嵌套循环,也可以包含对应计算内容的命令语句序列。这种表示方法允许我们将计算划分到对应的block子区域,然后根据block前面存储的信息对程序进行有效的变换,我们将在3.1中讨论技术细节。

3.1 Block
TensorIR中的一个block表示在多维buffers的一个子区域上进行张量计算。图5展示了一个矩阵乘法计算的block例子。block的body由一组块迭代变量vy,vx,vk参数化,代表了抽象张量计算。通过不同的block迭代变量组合进行实例化,block对应不同的运行实例。迭代器变量可以绑定到包含外部循环变量的表达式上,指明block实例的执行顺序。

Rationale。设计block的主要目的是为了隔离张量计算,我们希望能够不关注循环体内的操作,对block外的嵌套循环进行变换。但是不同于标量计算,我们不能从张量计算主体中提取出变换需要的依赖信息。所以我们引入了block签名,包含了变换需要的足够依赖信息。我们在3.2中讨论这些变换。此外,签名也可以单独使用,用于检查迭代器绑定在变换中的正确性(3.3)。
Block Iterator Domain。虽然可以把block主体计算绑定到任何的嵌套循环上,但大多数实例并不对应相同的计算。为了保证变换时计算的等效性,我们存储迭代器的域信息,迭代器的约束条件到block签名中。对于图5中的例子,我们直到vx,vy和vk必须绑定到域为[0, 16)的迭代器上。此外,由于vk是规约轴,我们知道不能将其绑定到并行循环上,除非规约是原子的。域约束仍然给外部循环变换留下了巨大的操作空间,因为有很多种方法构建符合约束的循环。我们的域签名可以视为表示整数值域集合与迭代器关系的一种特定方法。我们选择这种特定的表示是因为它实现的效率和简洁性,但需要指出,相同的设计理念适用于其他整数集和关系的表示方法。
Access Region and Dependency。为了提供有效的依赖信息,一个block签名包含对多维buffers的访存区域和读写依赖。图5中block的写区域为\(C[vy*4:vy*4+4, vx*4:vx*4+4]\),还有A、B的读区域。这些依赖信息在变换时被使用。我们只需要标记块对应的多维buffers即可,不需要关注其他语句,blocks。这间接支持了更多的变换,例如data layout变换,re-computation,在张量程序优化中必不可少。
Reduciton Block and Initialization。规约计算通常包含初始化步骤和更新步骤。我们可以自然地将规约计算映射为两个block。但是,把它们连接在一起有助于进行schedule决策,例如分块和计算位置。我们引入了blocks中可选的初始化语句。初始化语句在规约的第一次迭代时被执行,这种规约block表示有利于变换。我们提供变换原语转换两个block的表示,和init block的表示,所以我们可以选择最好的一种表示进行低级代码生成。
3.2 scheduling Transformations
对于给定的输入程序,我们需要生成包含相同语义的丰富搜索空间。我们引入原语将TensorIR程序变换为等价的优化程序。遵循张量程序优化的现有约定,我们称为procedure scheduling。
一个block如果仅包含以子block作为子块的嵌套循环,那么它是可调度的。我们可以通过分析子block签名和依赖信息,变换嵌套循环,以及变换子块在可调度块内的计算位置。尤其,可调度的块可能包含不可调度的子块,例如Tensor Core计算。一个不可调度的块也可能包含可调度的的子块。基于block的隔离,我们能够有效地搜索这部分可以调度的程序,并保持不透明块。我们在本章的剩下部分讨论调度原语。
Loop Transformations。循环变换,例如循环分块(split,reorder),枚举计算位置,是优化程序以获得更好的内存局部性的重要方法。我们提供了这些循环变换原语(图6)。不同于现有的张量编译器直接提前每个叶子标量计算语句的依赖关系,我们只需要检查block签名就能计算依赖。除了循环变换,我们还支持将loops绑定到GPU线程,以及提供注解(例如vectorization,unrolling)。注意到block的隔离没有影响blocks之间的协同优化(例如inlining,cooperative fetching)。我们的循环变换覆盖了先前工作提供的循环变换,这使得TensorIR能够构建如第2章所说的搜索空间。

Blockization。循环变换原语保留了blocks的全面层次,如我们在第2章介绍的,有时通过隔离子区域的计算为一个新的子block来划分问题是有利的。我们将这种变换称为blockization,图7,一个blockized程序不再基于标量,而是用一个新的子block对应一个张量计算。我们可以用blockization隔离可能进行张量计算的部分。除了blcokization,我们还引入了其他可以改变block层次的原语。例如,我们提出caching原语,将子blocks的数据cache到shared memory中。我们还提供单个规约块和对应的init,update块的来回转换。

Separation of Scheduling and TensorIR。多数已有的张量编译器依赖声明式的调度语言来生成调度树。添加新的调度原语需要同时修改调度树的数据结构和对应的代码下降规则。我们采用不同的方法,将每个调度原语实现为从一个TensorIR程序到另一个程序的单独变换。这种设计是易于扩展的,因为不同的开发者能够基于一个稳定的TensorIR抽象同时开发发新的原语。此外,开发者能够在变换的任何阶段输出程序,利于debug和混合使用变换。
3.3 Validation
blocks和对应buffer的读写关系与原始计算是等价的,使用这一点可以进行嵌套循环和线程的正确性的检查。
Loop Nest Validation。嵌套循环检查迭代器绑定是否符合迭代器值域的约束,包括值域大小和依赖关系。例如两个数据并行的block迭代器v1 = i; v2= 2i,如果v1和v2不符合依赖关系,对应的程序是无效的。但是如果是v1=i/4; v2=i%4,可以是有效的。我们构建了模式匹配器来查找循环迭代器到块迭代器的拟仿射变换,使用这种模式检验依赖关系和值域。除此之外,检查生产者消费者关系也是十分重要的,确保生产者写入buffer区域总是能涵盖下游消费者的读区域。
Threading Validation。在为GPUs和其他加速器构建程序时,需要考虑线程支持,这部分对应的线程和内存层次需要额外的验证。我们做3种验证:
- Thread binding:确保绑定到同一线程的不同的迭代器是一致的,并且满足后端硬件的约束。
- Cooperative memory access:对于那些使用线程协同将数据写入shared memory的blocks,我们需要确保block能够满足来自相同group所有线程的下游的要求。同时,给当前block提供输入的上游block需要满足当前block的同一group的所有线程的要求。
- Execution scope:验证张量指令在正确的执行范围内。(e.g. TensorCore needs to run at the warp-level)
Correctness of Schedule Primitives。我们为每个调度原语加入检查,确保变换的正确性。当一个调度原语只改变嵌套循环时,我们能够使用检验过程确保正确性。因为block迭代域和依赖关系在这种情况下不变。我们发现了改变blocks的调度原语的特定条件(e.g. blockization)。
注意到嵌套循环检查和线程检查被用来过滤掉无效的TensorIR程序,调度原语检查用于确保TensorIR程序在变换前后等价。用户将在他们编写,导入,调度错误TensorIR程序时得到错误信息。当用户使用编译器自动生成程序(第4章),检查能够帮助在搜索空间种过滤掉错误的程序。因此,检验对于用户程序和编译程序都是有帮助的。
3.4 Programming Effort
如图4所示,我们提供了TensorIR的Python-AST方言,允许开发者直接使用Python构建,修改,变换程序。如果用户需要手动指定所有计算和优化,那么开发的工程量是很大的。我们的框架允许用户从TensorFlow/PyTorch种导入模型,并自动从高层算子生成TensorIR程序。此外,系统对给定的硬件后端,使用自动调度(第4章)自动进行优化,例如分块和cache。我们仍然允许用户使用Python方言手写一些定制的算子,在这些情况下,系统自动进行优化,将手工开发的工程量降至最小。
4 Auto-Scheduling Tensorized Program
在最后一章中,我们介绍TensorIR抽象和一组变换原语。为了得到最好的性能,我们需要一种自动化的方法在多种变换和映射计算到张量计算指令的组合中找到最优的方案。本章我们阐释张量感知的自动调度器来解决这个问题。
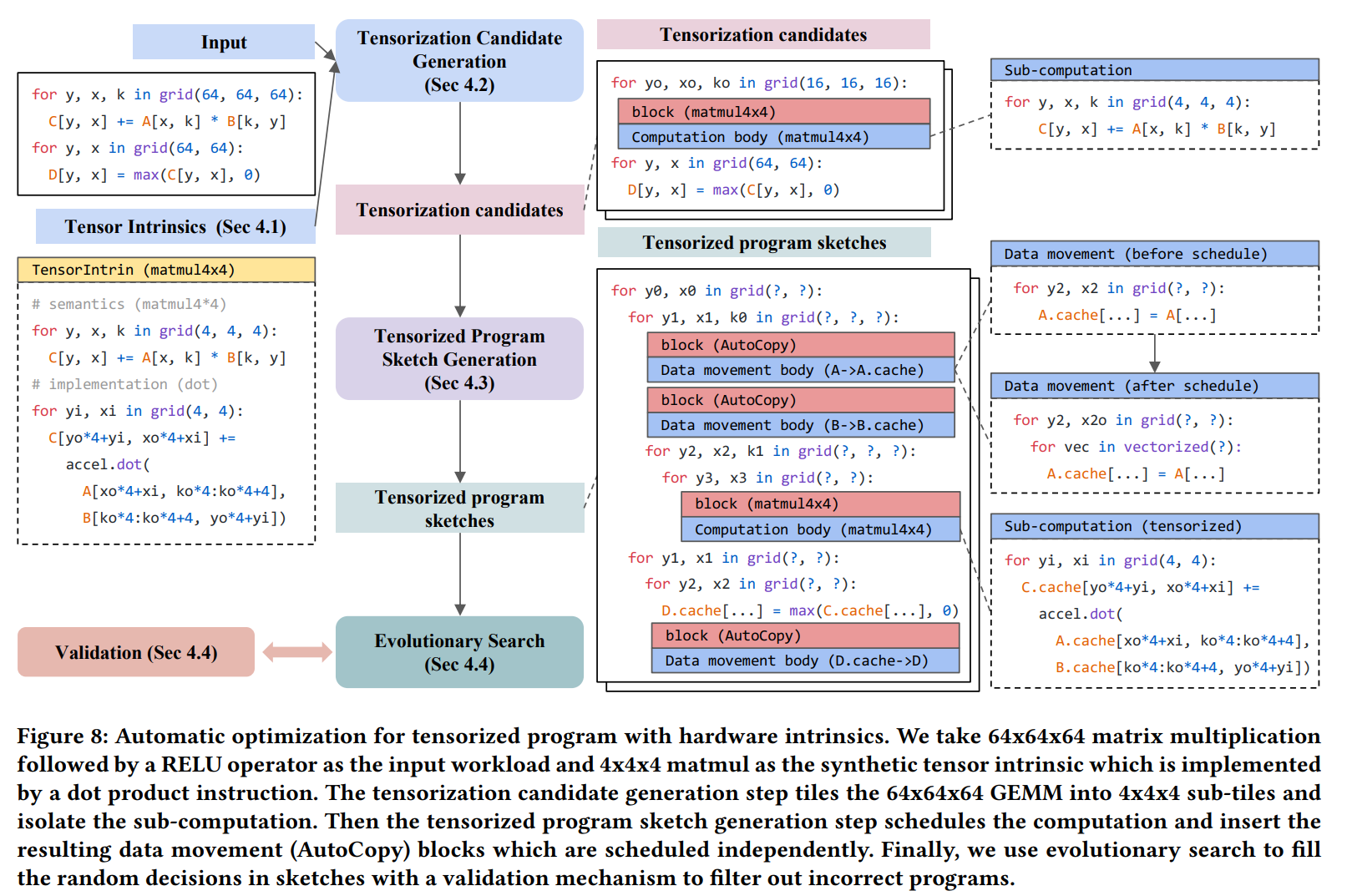
图8展示了我们方法的总体思想。系统将用户给定的一个工作流和硬件平台的张量指令描述作为输入。自动调度器首先检查计算模式,生成可能的张量化候选。然后使用张量计算生成程序框架的候选,并根据计算模式决定数据移动。对于给定的张量程序框架的搜索空间,我们使用基于学习的代价模型指导,进行进化搜索。整体的处理围绕张量化,并利用新的block抽象隔离张量化计算,我们将在剩下的子章节中讨论详细步骤。
4.1 Abstraction for Tensor Intrinsics
为了在优化时利用到硬件后端的张量指令,我们需要一种方法来为系统提供指令的语义和后端的实现。我们同样使用TensorIR抽象来描述给定硬件后端的张量指令。对于给定的张量指令,我们引入TensorIntrin结构,包含两个blocks,一个block描述计算语义,另一个提供low-level的实现。
在图8的例子中,我们使用标量计算作为循环体的嵌套循环c[i, j] += A[i, k] B[k, j]表示计算语义,利用内部的点乘指令accel.dot作为指令实现。我们还在TensorIntrin中引入在buffer的数据类型,存储层次,内存布局和连续性约束。这些约束条件在验证阶段被使用。
值得注意的是,张量指令通常和特定的内存范围,数据布局和读写指令一起使用。例如NVIDIA GPUs上如果要使用nvcuda::wmma::mma_sync API进行密集计算,需要使用nvcuda::wmma::load_matrix_sync和nvcuda::wmma::store_matrix_xync来分别进行读写操作。在ARM CPUs上,如a64_gemm_u8_8*12这样的微内核需要存储为交错的layout,开发者可以通过为张量计算的输入输出指定特定的内存范围来提供这些约束。
4.2 Tensorization Candidate Generation
给定一对后端硬件和输入程序,我们首先将程序主体与可能的TensorIntrin匹配,生成张量程序候选。匹配使用渐进的方法,首先匹配计算模式C[]+=A[] B[],不考虑下标。然后通过提出下标可能的映射来完善匹配。图9给出了匹配流程的一个例子。在这个例子中,我们将矩阵乘法指令作为后端描述。张量指令的计算可以用公式表示\(C[x,y] += A[x,k] * B[k,y]\),可以容易地将batch矩阵乘匹配到这条指令上,计算公式为\(C[b,i,j] += A[b,i,r] * B[b,r,j]\)。

只需要将xyk映射到ijr,但是2d卷积等更复杂的工作流映射并不直接。
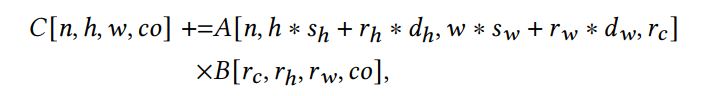
这种复杂的情况,我们重写计算表达式为一个等价的形式。
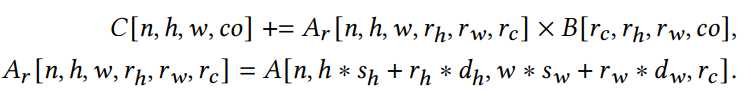
我们称这种变换为ReIndex,使用中间迭代器进行访问,重写buffer访问的模式。为了将这个新的计算与张量指令匹配,我们在每个迭代器出现的地方检查buffer访问。例如nhw和x在A(Ar),C中出现,co和y在B和C中出现,rh,rw,rc和k在A和C中出现。我们可以通过检查这些模式将迭代器映射到张量指令上。特别地,我们将fuse(n,h,w)映射到x,co映射到y,fuse(rh,rw,rc)映射到k。这里fuse()将多个迭代器融合在一起,可以递归地定义。
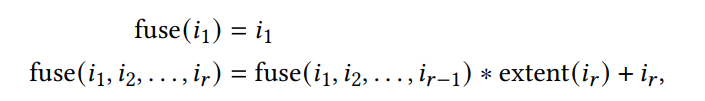
其中extent()是ir的范围,可以将计算变换为
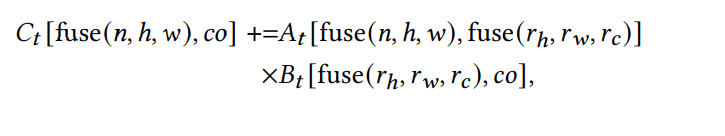
我们使用这个映射来reshape外部循环block实例空间,并变换ReIndex buffers的layout。我们插入layout重写blocks来分别重写A,B,C为At,Bt,Ct。然后使用At,Bt,Ct重写计算主体。经过这些步骤,计算主体就与张量指令相符合了。
Loop Reorganization and Early Blockize。除了计算主体,我们还需要确保张量计算的范围满足TensorIntrin提供的描述,重新组织的block实例空间的shape可能不能被划分为张量指令的子问题大小。对于每个计算体的最后一步,我们需要将计算block的输入输出padding到最接近的可分shape。然后进行分块,让最内层循环匹配张量指令的循环,进一步将内存循环作为一个block,隔离对应的张量计算。值得注意的是,这一步生成的候选程序不总是能成功的张量化。这是因为还有其他的约束,例如内存之后变换的layout和线程的约束。这些约束嵌入在张量候选程序中,在验证阶段检查。
Formal Description of Process。目前我们给出了高度概括的张量候选程序生成步骤,之后我们将对这个步骤进行正式的描述。假设标量表达式指令可以写为\(O[v0] = f(O[v0],I1[v1],I2[v2],...Ik[vk])\),其中O是输出,I是输入,v是一系列迭代器,f是计算模式。注意到这可以表示常见的点乘和矩阵乘,进一步,可以假设标量表达式的工作流为\(\widetilde{O}[g0(\widetilde{v}0)] = f(\widetilde{O}[g0(\widetilde{v}0)],\widetilde{I}1[g1(\widetilde{v}1)],\widetilde{I}2[g2(\widetilde{v}2)],...\widetilde{I}k[gk(\widetilde{v}k)])\),O,I,v对应各自的部分,f是一致的。g将迭代器集合映射到对应的buffer位置,在Conv2D的例子中,g = (n, hsh + rhdh, wsw + rwdw, rc)。
为了把问题化简为更简洁的形式,我们应用ReIndex变换,将生成中间cache buffer,根据迭代器的改变layout,形式上,如果我们运行重写block,\(\widehat{I}1[\widetilde{v}1] = \widetilde{I}1[g1(\widetilde{v}1)]\)。我们将标量表达式化简为
这里buffer访存将直接与迭代器相关。
为了与最初问题匹配,我们通过检查每个迭代器V0, V1, ..., Vk中是否包含v,构造v的特征向量。如图9,会返回1,0代表true或false,对于有相同特征向量的迭代器,我们可以进行映射,在映射后使得每个新迭代器的特征向量不同。
值得注意的是,融合迭代器的顺序不会影响特征向量的值,但是在融合时,融合的顺序影响数据在内存的组织。我们的实现目前使用一种默认的顺序,这在将来的工作中可以扩展为不同的融合顺序。
4.3 Tensorized Program Sketch Generation
对于一组给定的张量程序候选,我们需要构建包含这些张量化的搜索空间。我们根据已有的层次化搜索空间构造方法生成张量计算。首先生成包含张量化计算的程序sketches,然后枚举当前sketches的所有选择。如图8所示,一个程序框架将程序的部分结构写好,但是例如循环分块和计算caching的选择没有决定。生成的过程时递归地应用预定义的生成规则。通过查看block签名,我们可以规范生成规则,并在分析过程中利用访存信息。
Data Movement as First-Class Citizen。已有的张量程序自动调优器关注在计算调度上的设计,将不同内存范围的数据移动视为第二优先,然而,张量计算指令极大地提升了计算吞吐量,数据移动成为张量程序的瓶颈。并且数据移动通常受到计算调度的影响,例如分块,线程绑定,执行范围和生产者消费者数据粒度。我们考虑这些因素,并将数据移动作为我们自动调度器的头等公民,并与计算调度解耦。特别,当sketch生成规则需要执行数据移动时,我们插入AutoCopy blocks图8,copy块隐藏了内部的调度信息,只在block签名级别暴露buffer访问接口。隔离的copy块使得sketch生成无需考虑数据如何移动,只关注计算的调度。AutoCopy的主体由数据移动任务表示,包括buffer位置映射,线程和存储范围要求。一个数据移动调度器将这些信息作为输入,然后执行内存相关的调度变换,例如插入中间cache,利用数据移动张量指令,向量化,协同获取或stride padding避免带宽冲突。
4.4 Evolutionary Search
经过sketch生成阶段,我们可能会得到数十亿个程序,使用进化搜索在空间中搜索优化的程序。我们的进化搜索从一些随机的初始化程序中开始,执行变异,然后从中挑选认为比较好的程序在硬件后端上测试,收集数据并更新代价模型。
Cost Model for Tensorized Computation。我们构建了boosting tree ensemble,基于代价模型与程序中提取的特征。特征向量包括内存访问模式,重用,循环注释等信息。我们既采集block签名信息,也采集block内的信息(例如使用Tensor Core的标志),我们的代价模型可以视为之前方法的一种扩展,我们相信在将来,高效的代价模型会是研究的热点。
Validation。在搜索过程中随机变异程序可能会产生无效的程序,因为不符合张量计算指令或嵌套循环的约束。这种错误的样例需要我们在搜索时进行检验。我们使用3.3介绍的技术,在进化搜索时检验程序候选,并排除错误程序。检验步骤减少了进化搜索算法的负担,并允许我们在搜索过程中生成更少的错误样例。
5 Evaluation
我们在Apache TVM至上实现了TensorIR,本文的灵感同样来源于机器学习编译框架。本章将评估并解答以下问题:
- TensorIR能不能优化常见机器学习算子
- TensorIR能不能提升端到端神经网络的性能
- TensorIR能不能支持不同硬件平台的张量计算指令
为了在这些方面评价TensorIR,我们与现有CPU和GPU机器学习编译方法进行比较,我们将具体讨论实验的设置。
另外,我们还对以下问题感兴趣:TensorIR与供应商提供的库,以及使用这些库的框架对比如何。这些库通常是经过手工高度优化的,TensorIR端到端优化不需要调用这些外部的库。
5.1 Single Operator Evaluation
本章评估TensorIR在深度学习模型算子上的表现。我们选择常见的工作流:1D卷积,2D卷积,3D卷积,深度卷积,dilated卷积,通用矩阵乘,group卷积,transposed 2D 卷积。评估在有Tensor Core的NVIDIA RTX 3080平台完成。我们选择这个平台是因为其支持多种机器学习编译器和算子库,便于比较。我们使用float16作为算子的输入和计算数据类型。使用TVM(commit:27b0aad5,有自动调度),AMOS(commit:6aee6fe2)作为两个机器学习编译器基准,与两个供应商算子库比较CUTLASS(version2.9),TensorRT(PyTorch-TensorRT 22.06)。
与机器学习编译器比较。图10展示了与AMOS和TVM比较的结果,TVM在计算量较小的算子上表现较好(DEP),但是在计算密集型算子上,由于不能充分利用Tensor Core表现较差。AMOS可以使用Tensor Core,但是不如TensorIR做的好。总体上,TensorIR与现有机器学习编译器方案相比有7.5的加速。这些提升来自于抽象和自动调度,利用了对应的张量计算指令和数据移动。

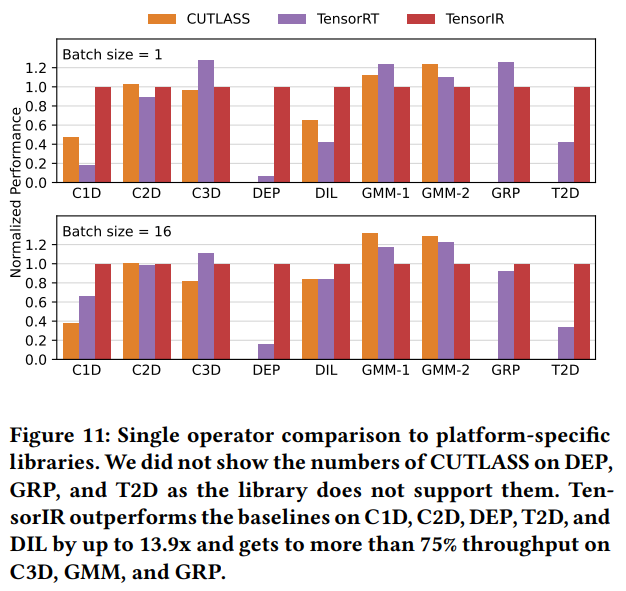
与平台专用库相比。图11展示了结果。TensorIR在几个算子上有最高13.9的加速,体现了TensorIR的优势,在C3D,GRP和GMM上有最好方案的75%,说明即使与最先进的手工优化方案相比,TensorIR也能取得接近的性能,我们希望通过从中不断学习,缩小差距。总体而言,这些库经过了高度的手工优化,而TensorIR根据给定的张量指令声明自动编译。
5.2 End-to-end Model Evaluation
本章测试端到端模型,我们在NVIDIA RTX 3080平台测试4个常用的模型。TVM和AMOS作为机器学习编译器的基准,PyTorch(version 1.13.0.dev20220612)作为框架,TensorRT作为供应商算子库。
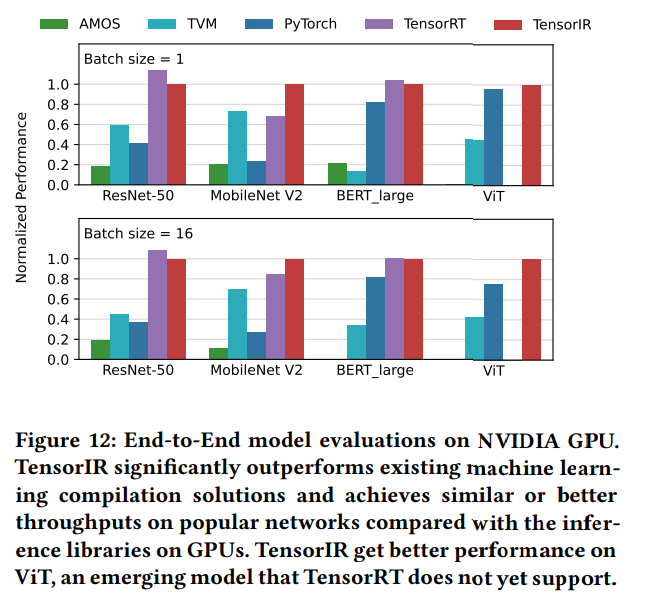
结果如图12所示,TensorIR性能优于PyTorch,TVM和AMOS,有1.2-8.8的加速,在MobileNet V2比TensorRT新跟那个更好,在其他模型上也有与TensorRT88%的性能。并且能够自动支持新的模型,例如Vision Transformer,而TensorRT不支持。结果表明我们的抽象和自动调度能带来接近或超越已有算子库。而且能够更快支持新的模型。
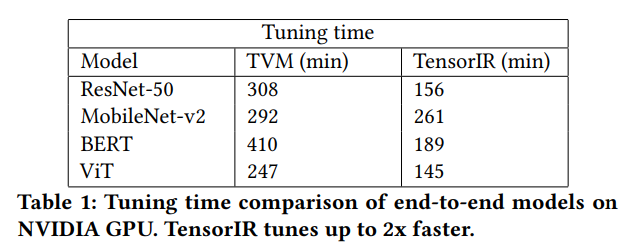
调优时间,是基于搜索的深度学习编译器是否具有实用性的一个重要方面。我们与TVM比较端到端的调优时间,如表1.我们的框架比TVM快2倍,这种提升来自于两方面。首先,硬件采样会导致更多的调优时间,而TensorIR能够生成更快的程序,因为能利用Tensor Core,所以采样时间缩短了。第二,我们分而治之的方法将问题分为外层嵌套循环和内部计算,内部计算利用硬件指令,只搜索外层的嵌套循环,搜索空间更小。这样的搜索空间是可以接受的,TensorIR能够进一步缩短调优时间,通过缓存历史代价模型和搜索记录,所以已经调优的算子不需要重新构建模型。
5.3 ARM CPU Evaluation
上两章讨论了TensorIR在Nvidia GPU的效果,本章讨论TensorIR如何应用到不同的平台,我们在ARM平台上进行实验,平台提供8-bit整数乘法指令(sdot)。这个指令与Tensor Core不同,我们只需要提供新的指令描述。实验在AWS Graviton2 CPU上进行。
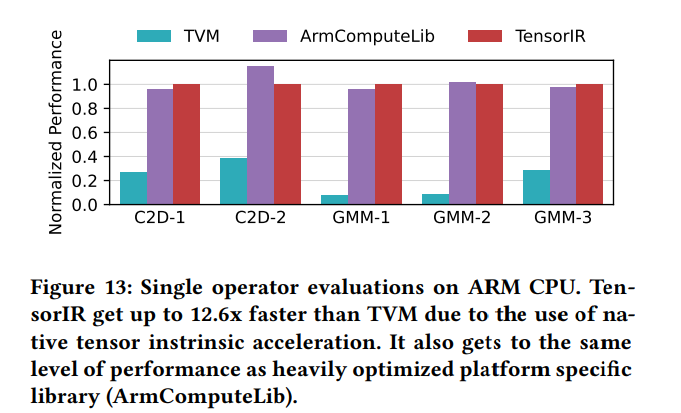
单算子结果。我们评估两个常见算子C2D和GMM,TVM作为机器学习编译器基准,ARMComputeLib作为平台算子库基准。结果如图13。TensorIR能够应用硬件指令,相比TVM有12.5的加速,取得了ARMComputeLib算子库85%-105%的性能,展示了与其相当的性能。
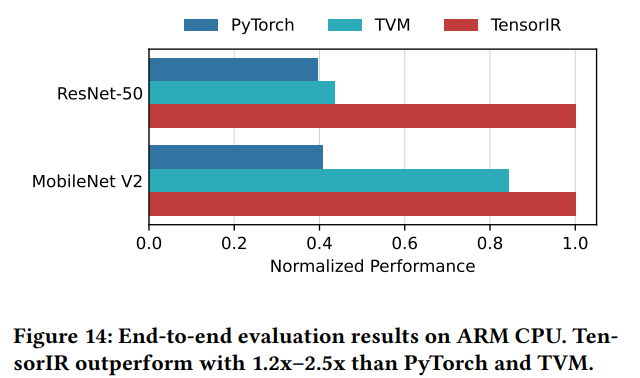
端到端结果。基准包括PyTorch和TVM,如图14所示,取得了2.3的加速,注意到PyTorch包含一个特别量化的QNNPACK后端模型支持。但这个后端不支持sdot指令,这也说明框架支持硬件的工程代价。TensorIR能够帮助减少这种开发负担,并提供有竞争力的性能。
6 Related Works
深度学习框架通过调用供应商优化的算子库(e.g. cuDNN,MKL-DNN,TensorRT,ArmComputeLibrary)优化深度神经网络。算子库需要工程量开发,并且只针对特定硬件。TensorIR减少了开发负担,并与算子库性能接近。这些框架能够利用TensorIR为多种硬件后端生成优化的张量程序。
计算密集型的线性代数算子,例如矩阵乘和点乘是HPC社区长期优化的目标(例如CUTLASS),因为他们在科学计算中十分重要。分而治之的思想在HPC和ML工程中是一种典型的优化技巧。TensorIR采用了这种思想,并应用到抽象上。
机器学习和张量编译器引入了不同的抽象,Halide和TVM使用调度语言,使用标量计算体描述嵌套循环的优化原语。Tensor Comprehensions,Tiramisu和MLIR/Affine使用多面体模型分析嵌套循环依赖。这些工作使用自底向上的方式优化标量计算。Fireiron和Stripe使用嵌套多面体结构建模,是一种自顶向下的方式。TensorIR组合了这些方法和思想,推广到张量程序。IREE是端到端编译链,使用平台特定的优化流程。TensorIR关注于自动张量化,为多平台自动生成代码。TACO是稀疏张量编译器,Cortex推广张量编译到递归计算。我们的工作与这些研究是垂直的。我们相信TensorIR抽象会在将来能与这些工作结合,支持更大范围的计算。
自动化是机器学习编译和张量程序优化的关键话题。AutoTVM引入基于学习的方法,使用可学习的代价模型和基于模板的搜索优化张量程序。Triton引入了基于分块的模板表示,能高效优化程序。FlexTensor自动生成模板。Halide使用Monte-Carlo tree search构建自动调度器。Ansor使用层次化搜索空间提升了自动调度。我们的自动调度算法从中学习,并推广到张量计算上,为硬件加速。
Auto-vectorization是编译器研究的长期目标。Tensorization可以认为是向量化问题的推广,使用现代加速器的张量指令。在这方面已有一些研究,AKG使用多面体方法搜索张量化空间,UNIT引入张量化的通用流,AMOS能通过张量表达式自动映射到张量指令。我们的方法推广了这些研究,通过提出一种新的张量计算抽象,并与其他优化结合。TensorIR可以作为将来开发可感知张量化自动调度方法的基础。
7 Conclusion
我们提出了TensorIR,一种针对自动张量化程序优化的抽象。我们设计了一个关键的抽象block,能够隔离张量化计算,并为程序优化提供高效的变换原语。我们提出了一种将张量化和其他优化共同使用的自动搜索算法,能够生成高性能的程序。我们希望这些研究能够激励张量程序优化领域的工作,并提供硬件和软件专用化的新的机会。