Abstract
为了实现性能提升,硬件专用化是一个趋势。空间硬件加速器利用专门的层次化计算和内存资源在张量程序,例如深度学习,科学计算,数据挖掘种展现出了高性能。为了利用硬件的功能,编程人员需要利用有着一定硬件约束的硬件指令。但是这些硬件加速器和硬件指令十分新颖,目前对其硬件抽象,性能优化空间和自动搜索空间的方法研究地还不多。现有编译器使用手工调优计算实现,或优化模板的方法,结果不一定是最优,并且开发代价较大。
本文提出了AMOS,针对空间硬件加速器的自动编译框架。框架的核心是硬件抽象,不仅清晰地定义了空间硬件加速器的行为,还形式化地定义了软件到硬件的映射问题。基于这种抽象,我们使用算法和性能模型自动搜索映射。最终,我们构建了编译框架,使用硬件抽象作为编译器的IR,搜索计算映射和内存映射,为不同硬件后端生成高性能程序。我们的实验结果表明,AMOS相比在Tensor Core上的手工优化库有2.5的加速比,Intel CPU AVX-512指令集的向量单元,相比TVM有1.37的加速比,在Mali GPU的点乘单元相比AutoTVM有25.04的加速比。AMOS的源代码已经开源。
KEYWORDS
spatial accelerators,code generation,mapping,tensor computations
1 Introduction
近年来,许多应用领域的领域特定框架取得了成功,在这些不同的硬件加速器上,空间加速器用结构化和层次化的形式组织大量的处理单元。在多种张量程序,如深度学习,科学计算和数据挖掘中十分高效。这种空间架构自然地与规则的循环结构和内存访问模式对齐,这种计算通常用嵌套循环表示。例如,谷歌TPU和Gemmini使用systolic array架构,定制化GEMM计算。这种空间架构随着新的张量程序不断改进。
取决于通用性和可编程性,硬件加速器可以被设计地十分多样,需要不同的映射策略。我们将现有的空间加速器映射分为两类,硬件感知和ISA(指令集)感知。对于特定领域,硬件设计和软件映射可以通过领域特定硬件和软件接口解耦。具体来说,编译器和映射器对于硬件架构十分了解,例如处理单元的数量,连接关系,映射可以形式化为有硬件约束的优化问题。我们将这种方式称为硬件感知映射。这种方法对于特定的应用领域能够取得很好的效果,但牺牲了灵活性。对于ISA感知的映射,硬件加速器可以通过ISA编程,将算法细节从硬件体系结构中分离,这些指令通常作为特定的张量加速指令暴露出去,使用这些指令进行张量计算称为张量化,我们在本文中关注ISA感知映射问题。
虽然张量指令提供了可编程性,ISA感知映射仍然是有挑战的问题,有两个原因。第一,有不同的方法进行张量指令映射。例如将7层循环的2d卷积映射到3d Tensor Core上有35种方法。显然,映射的质量对于性能十分关键,因为不同的映射方式在数据局部性和并行性上十分不同。但是现有的编译器高度依赖手工使用这些指令开发的库和模板,这可能导致得不到最优的映射选择。第二,不同的加速器提供不同的张量指令,计算和内存的语义会有不同。例如Tensor Core使用不同的内置函数描述load,store,矩阵乘和初始化,但是Mali GPU,只需要一条arm_dot指令,不需要其他的load和store指令。因此,在不同的加速器上支持同样的算法,开发者需要针对每个目标平台实现和调整算法。显然,理想的映射方式应该使用统一的接口暴露搜索空间,并自动搜索。
本文通过在指令之上的抽象层解决ISA感知映射问题。这基于以下见解:
-
虽然不同的加速器使用不同指令,但是这些指令可以重写为等价的标量形式,既能将原来不可见的指令打开为可分析的形式,还在高层张量层序和底层指令的鸿沟之间架起了桥梁。
-
虽然不同的空间加速器在体系结构的设计上不一样,但他们在映射的设计上有基本的相似性。例如,他们的硬件约束可以统一定义为问题大小约束和内存容量约束。
基于这些见解,我们能够使用统一的抽象来描述不同加速器的不同指令,并设计一种自动化的方法进行映射生成,检验,以及不同硬件的搜索。
具体而言,提出的抽象包含两部分,计算抽象和内存抽象,将指令内部的计算和访存操作描述为标量形式。基于这种抽象,我们进一步开发了两阶段映射生成流程,以及检验算法,能够生成有效的软硬件映射。生成流程首先将软件计算映射到虚拟硬件加速器上,不考虑硬件约束,然后再根据实际的硬件约束修改映射。但是,不是所有生成的映射都是有效的,因为它们可能与原始语义不同,所以我们设计了检验算法,基于二进制矩阵表示来检查有效的映射。进一步,通过组合调优和分析模型,我们能够在映射空间中高效搜索,在空间加速器上得到高性能程序。最后,我们将这些技术进行实现,设计了编译框架AMOS。
本文有以下贡献:
-
我们提出了一种硬件抽象,形式化地定义空间加速器计算和访存行为,以及软件到硬件的映射。
-
我们提出了针对ISA感知的映射问题的一种全自动解决方案,通过设计两阶段的映射生成流程,一种全新的检验算法和性能模型进行搜索。
-
我们提出了AMOS编译框架,支持在加速器上广泛的张量应用,包括算子级和完整网络级。
将张量计算映射到空间加速器上十分深奥,所以用户可能难以理解硬件映射(结构和约束),以及优化空间。AMOS解决了映射问题,通过指定了等价的迭代映射生成和检验问题。对映射空间进行搜索是必要的,因为不同的张量计算,输入shape,行为可能产生不同的硬件映射。
AMOS相比于其他方法(手工库,基于模板的编译器)的优势在于,硬件抽象能够表示不同的指令的计算和搜索为一种通用的格式,形成映射空间。核心的硬件抽象使得AMOS能系统地搜索不同的软件和硬件映射,并进行映射检验。同时,已有算子库和编译器受限于两方面,首先手工库和基于模板的方法只能通过编写好的模板和低级代码搜索一小部分固定的映射。并且,即使可以通过一些工程量来手工设计模板,但是由于对加速器的硬件抽象理解不足,仍然不知道什么映射是最优的。因此,之前的工作可能达不到最优的效果,并且开发代价较大。
AMOS的源代码已经开源(https: //github.com/pku-liang/AMOS)。
2 Background and Motivation
2.1 Spatial Accelerator
空间加速器通常是层次化设计的,最内层设计为空间结构,采用专用数据流结构和连接方式的处理元件(PE)阵列。不同的空间加速器在PE阵列的设计上是不同的,支持的计算也不同。每个PE包括一个乘加计算单元,硬件的外层有核心和子核心,共享buffers和全局内存。空间加速器嵌入在通用的体系结构,例如CPU和GPU种,作为专用的功能单元。图1a展示了3级加速器的例子。最内层对应空间加速器的PE阵列,最内的第二层是子核心和共享buffers,最外层是核心和全局内存。加速器例如有Tensor Core的Nvidia GPU,使用AVX-512指令集的Intel CPU,点乘单元Mali GPU,Ascend NPU有立方和向量单元,都遵循这种设计范式。

编译器和空间加速器之间的接口称为intrinsic。一个intrinsic可以被视为专用硬件的特殊指令。有两种指令:计算指令和内存指令(load和store),图1b展示了4种指令。AVX-512的mm512_add_pd是向量加指令,_mm512_loadu_ph是向量load指令,下面两条是Tensor Core WMMA。
2.2 Existing Mapping Flow
表1将目前的编译器和映射器分为两类。
-
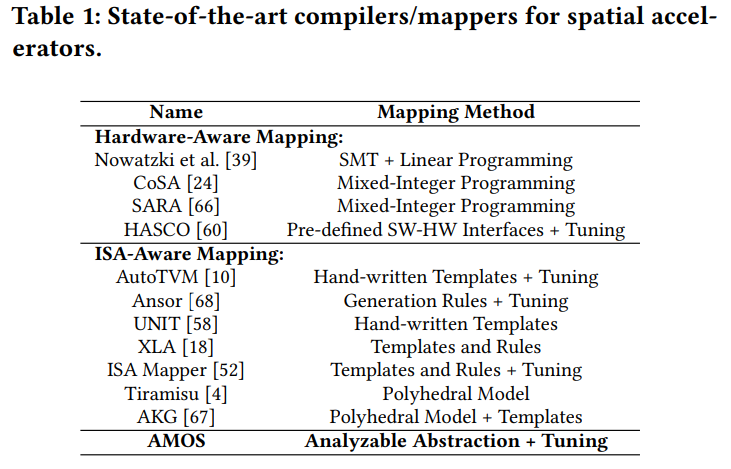
硬件感知的映射。编译器和映射器对详细的PE连接和buffer配置十分了解,所以能够使用领域特定接口将软件计算下降到PE和内存上。这一过程主要利用硬件和软件协同设计,映射器的主要目的是利用并行化和数据重用,在满足特定硬件的约束下优化硬件资源。通常通过求解等价的线性规划问题来避免在空间中的暴力搜索。这些编译器和映射器与本文是垂直的,我们关注解决映射到可编程指令的问题,不直接访问硬件的详细架构。
-
ISA感知的映射。对于一些空间加速器,它们暴露指令给编程人员。为了利用这些这些内置函数,编程人员需要手写模板,并在给定的调度空间中调优,例如TVM提供tensorize接口,可以配置内置函数,然后用户在软件层面实现时手动调用这些内置函数。多面体编译器例如AKG依赖多面体模型和模板的组合进行映射,AutoTVM和UNIT使用经过这些内置函数调优的模板,只能支持小部分算子和加速器。为了支持新的算子,需要手动开发新的模板。支持新算子和加速器是不容易的,Ansor使用生成规则的组合,例如分块,重排序和循环展开为通用硬件生成程序,但是这种方法在空间加速器上退回到基于模板的方法,需要用户手动为每个加速指令重写规则。
2.3 Motivational Example
为了说明我们的工作,首先展示为空间加速器手工设计模板,这对于真实的工作流可能是低效的。即使是最先进的编译器XLA在Nvidia V100上生成的代码,我们使用常见的DNN模型,包括ShuffleNet,ResNet-50,MobileNet,Bert,和MI-LSTM作为XLA的输入,XLA使用经过手工优化的复杂模板来优化算子。特别,一些模板将匹配模式用于Tensor Core,成功匹配的算子将被下降到低级的手工优化库例如CuDNN和CUTLASS,来调用Tensor Core指令。
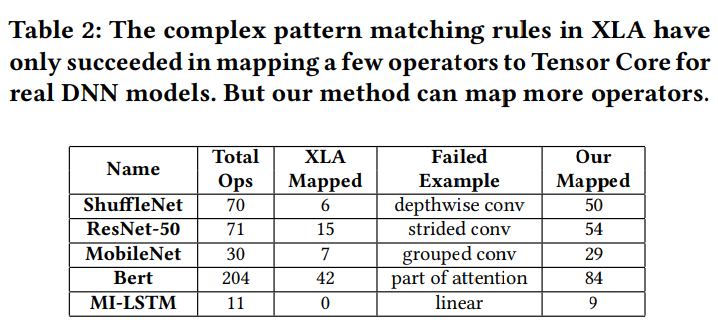
表2列出了采样结果。虽然XLA的模板是精心设计的,但只有一小部分算子能够映射到Tensor Core。进一步,我们发现其实有很多算子可以映射到Tensor Core。例如,ShuffleNet的depthwise卷积和grouped卷积是2d卷积的变体,乘加 操作同样适用于Tensor Core。如果我们能够映射到Tensor Core就能取得更好的性能。但是XLA无法做到,退回到用标量单元计算。这是因为算子的模式与XLA的手写模板不匹配,例如线性层,XLA希望匹配矩阵乘法到Tensor Core,但是匹配到MI-LSTM的batch size为1的线性层时,错过了这种模式。所以Tensor Core的利用率很低(对于以上5种模型,平均利用率不足10%)。相反,我们的框架能够将除了计算规则不同的全部算子映射到Tensor Core。例如(ReLU和MaxPooling)这类无法映射。表2还展示了我们映射到Tensor Core算子的数量,数据可以看第7.4章的实验。
手工设计的模板有两点限制。首先,这些模板依赖明确的编程来使用空间加速器提供的计算单元。例如,XLA依赖手工调优库(CuDNN,CUTLASS)生成包含指令的代码,AutoTVM和UNIT需要在固定的循环模式中显式调用计算指令,这是深奥和耗时的,并且只能将小部分算子映射到加速器。一些隐晦的修改就会导致方法的失效,例如改变layout,进一步减少了映射的成功率。
考虑到手工进行指令编程和模板开发的限制,我们设计了全自动的编译流程。
3 AMOS Overview
本章介绍AMOS工作流程概述,图2中,AMOS的输入是高层的程序,利用已有编译器的领域特定语言(DSL)编写。DSL用高级的语言,例如Python,定义循环和张量。循环结构和张量访问也通过DSL编写。图3a展示了2d卷积的例子。AMOS使用提出的硬件抽象表示硬件指令,包括计算和内存。我们将在第4章介绍。然后AMOS使用软件和硬件信息生成不同的软件硬件映射。一个软件硬件映射包括计算和访存的映射。计算映射指定软件定义的算子应当被映射到目标加速器上,通过对应的计算指令实现。内存映射指定如何从全局或共享内存中加载数据和存储数据。空间加速器加强了约束,例如固定的问题规模大小和内存容量,这点可以在指令中反映出来。详细的映射构建方法可以看5.1章。除了硬件约束之外,保证映射的语义正确性十分必要。我们使用5.2介绍的算法来检验生成映射的正确性。然后,我们将调优方法和分析模型(5.3)应用于搜索高性能的映射。最后,我们解释AMOS的实现和代码生成部分(6)。
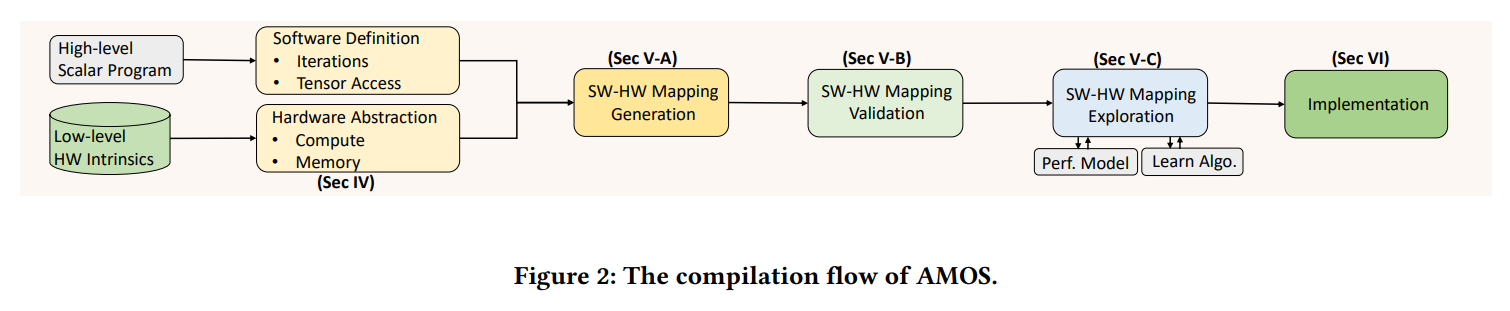
AMOS于先前的一些工作不同,因为不需要手工优化的模板和算子库,提供了全自动的编译流程,将张量程序映射到空间加速器上,进行自动映射生成。
4 Hardware Abstraction
本章介绍硬件抽象,主要思想是转换low-level的指令为等价的高层标量表达式。我们将抽象分为两个部分,硬件计算抽象和硬件内存抽象。抽象的目的是形式化定义加速器的行为,然后AMOS才能自动地分析不同加速器的指令。
4.1 Compute Abstraction
Compute Abstraction是一个语句,指定了变量,变量间的算数操作,数据访存索引。对应于一条硬件计算内置函数。索引的范围应当在抽象中表示,假定我们有M个数据源,第m个数据源Srcm是Dm维向量。输出Dst是N维向量,输出数据的索引表示为i = [i1,i2,iN],第m维数据索引表示为jm=[jm1,jm2,jmDm],语句可以写为:

解释,函数F表示算子,例如加法,乘法,或者乘加算子。矩阵A,Bm和C用于表示数据切片的映射形式。常量矩阵C用于表示这些切片的边界。例如,表示Tensor Core mma_sync指令,可以用特定shape[32,8,16]矩阵乘计算,我们可以将抽象写为:

4.2 Memory Abstraction
内存抽象是一组语句,每条语句指定范围,操作数和访存索引。类似于计算抽象使用的符号,我们使用Dst表示输出结果,Srcm表示输入数据矩阵。前缀global,shared,reg表示全局内存,共享内存和寄存器。ijk和l是不同范围的数据索引。
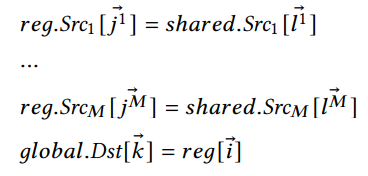
解释,内存抽象展示了输入数据在shared内存中,输出数据在global内存中。数据从global加载到shared的过程没有展示。不同内存范围的相同操作数索引可以不同。例如load_matrix_sync指令从shared memory读取数据到Tensor Core寄存器,store_matrix_sync存储数据从Tensor Core寄存器到global memory,可以共同表示为:
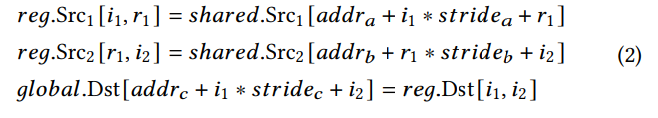
其中addra,addrb和addrc是内存基地址,stride是内存访问stride,这种模式应该在映射过程中由编译器设置,这些参数是有用的,因为load_matrix_sync和store_matrix_sync需要这些参数作为输入。
计算和内存抽象明确了硬件指令的模型,将不可见的指令转换为一系列标量操作,便于整体的分析。在现有的加速器中,很多指令实际上是类SIMD(单指令多数据,reduction也包括)指令,而SIMD的操作可以自然地用我们的抽象描述。因此,计算和内存抽象可以用于不同的加速器。
4.3 Software-Hardware Mapping
接下来我们介绍软件到硬件的映射。首先,我们引入软件迭代的概念,张量计算可以被完整的嵌套循环表示。软件迭代是在嵌套循环内地所有循环实例。(图3a)展示了2d卷积的例子,以及3b中列出的软件迭代。
类似地,我们可以基于这种计算抽象定义intrinsic interations,指令迭代是标量的计算实例,在计算抽象的切片范围内。例如,Tensor Core由3个指令迭代,等式1(i1,i2,r1)。给定软件迭代的定义,指令迭代,计算抽象和内存抽象,我们可以定义软硬件映射如下。
软硬件映射由两个部分组成:计算映射和内存映射。计算映射指定每个软件迭代到指令迭代。内存映射指定每个软件迭代到内存地址。

解释。为了使用加速器的指令来映射软件,我们必须知道软件中定义的每个标量算子的对应的计算和内存指令。基于计算和内存抽象,原始的指令被分为一系列标量运算,编译器能够在软件迭代和指令迭代中建立映射关系。除了计算的映射,内存映射也是可行的。在内存抽象中,不同内存范围的每个操作数访问切片是特别指定的,如果我们能将每个软件迭代与操作数的访存切片建立联系,访存就能够自动生成。接下来,我们解释如何生成软硬件映射,并自动生成能够调用加速器指令的高性能代码。
5 Mapping Generation,Validation,and Exploration
5.1 Software-Hardware Mapping Gerneration
为了生成4.3中定义的映射,我们提出了一种两阶段方法。首先我们将迭代映射到虚拟加速器上,虚拟加速器只有一个加载引擎,一个计算引擎和一个存储引擎。如图3i中描述的。内存的容量和计算能力在这一步不进行建模。然后,我们加入硬件的约束,并修改之前的映射,使其能够映射到硬件的指令上。为了解释映射生成流程,我们使用图3作为例子,虽然使用2d卷积的例子和简单的Tensor Core(2,2,2矩阵乘)作为说明,但我们的工作流程是通用的,可以用作其他的算子和指令。
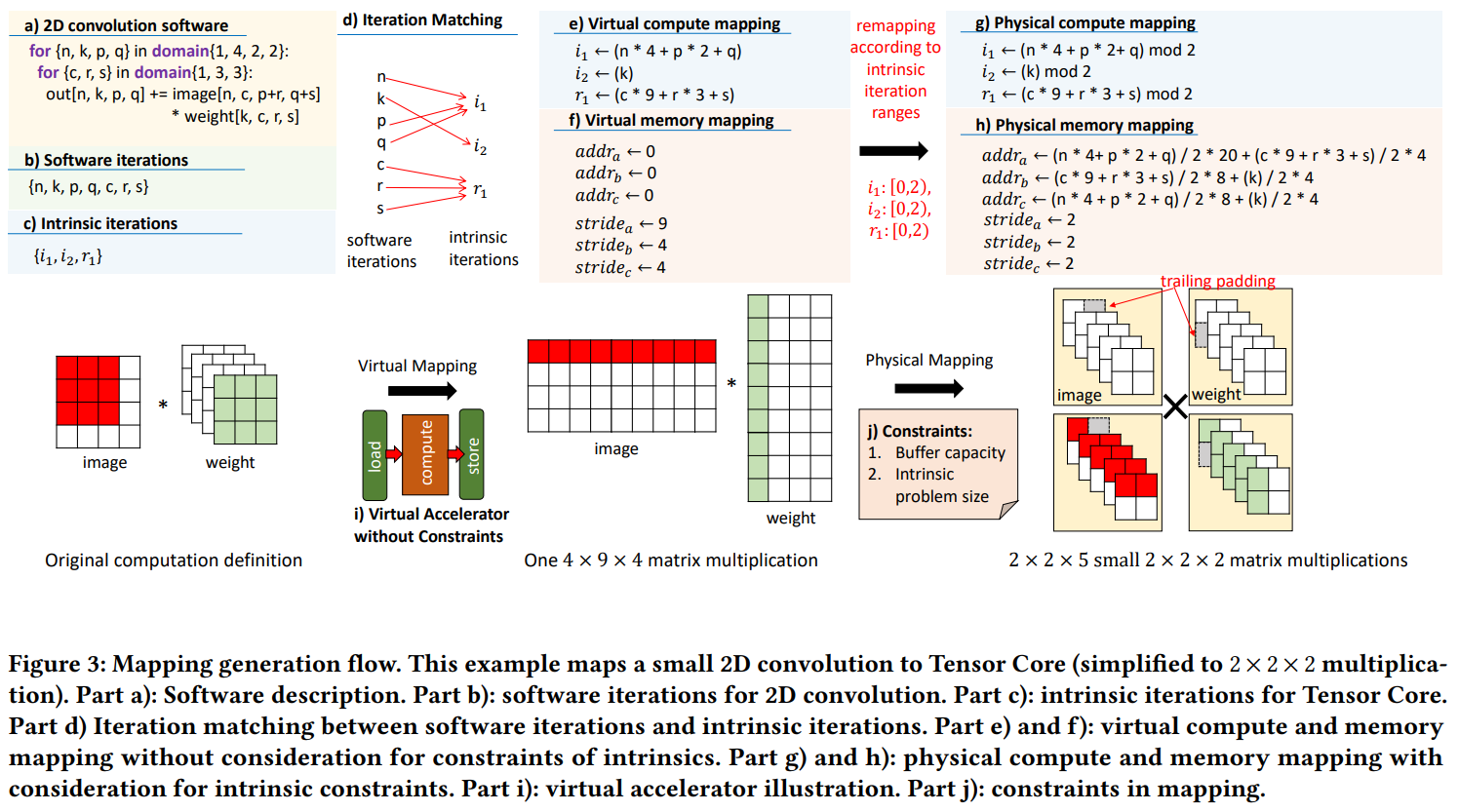
第一步,AMOS假定虚拟加速器能够加载任意数据到片上寄存器,并且有足够的硬件资源一次执行所有计算。这一步的主要问题是如何将软件定义的标量计算放入指令计算中。换句话说,要将软件迭代映射到指令迭代。在图3d中我们展示了映射的例子。原始的卷积被转换为等价的矩阵乘。虚拟加速器期待加载两个矩阵到寄存器中,完成矩阵乘,存储输出到全局内存。基地址被设置为0,stride设置为对应的矩阵shape,如图3e和f。但是,虚拟映射是不现实的,因为真实的加速器在buffer容量和计算资源上是有限的。所以我们需要在下一步中考虑这些限制。
第二步,两种约束被考虑近来:指令的问题规模和内存容量。硬件加速器一次只能计算一个固定size的结果,称为问题规模限制。AMOS通过对计算取模限制软件到指令的映射。指令的问题规模可以从切片范围提取出来,这在计算抽象中被表示,图3g,匹配的软件迭代被mod2,因为Tensor Core的规模是[2,2,2]。
对于内存容量约束,每个寄存器在加速器中只能存储有限的数据。因此,AMOS将整体输入输出数据分为小的切片,将切片分多次进行存取,这需要将虚拟加速器的基地址和步长进行对应更新。为了实现这一点,AMOS使用剩下的不在指令迭代中的软件迭代定位切片数据的位置,为物理地址映射生成基地址。步长也不再是完整数据的shape,而是改为对应的寄存器重量。在图3的例子中,Tensor Core只处理22矩阵。在3h中(n*4+p*2+q)/2对应没有映射到迭代i1的迭代。(c*9+r*3+s)/2对应没有映射到r1的迭代,所以这两个剩下的迭代器用来设置addra(i2)的地址,4是每个子矩阵的元素数量,20是一组矩阵的元素数量,所以5个子矩阵为一组。最后AMOS能够解决padding的问题,例子中,AMOS能够自动将拖尾的子矩阵进行padding。
5.2 Software-Hardware Mapping Validation
但是,一些生成的映射可能是无效的,AMOS使用检验算法来确保生成有效的映射。例如,如果我们将软件迭代n,k映射到同样的指令映射i1,图3d。我们将会得到错误的映射,即使满足硬件的约束。原因是软件迭代n和k在2d卷积中有不同的语义。n是输出和图片的索引,但是在权重中不出现,k是输出和权重索引,但是在图片中不出现,所以它们不能被映射到相同的指令迭代上。

我们的检验算法如算法1所示。首先解释算法的输入。access矩阵是二值矩阵,描述数据的访问关系。每行矩阵表示一个tensor,每列表示一个索引。如果索引在col列将访问row行的tensor数据,对应的(row,col)将被设置为1,其他则为0。matching矩阵也是二值矩阵,描述软件迭代和指令迭代的关系。例如图4展示的2d卷积的matching矩阵。映射关系由这个矩阵表示,这些二值矩阵的信息对于检验十分有用。

算法1通过检查软件访存关系和硬件访存关系进行验证。软件访存关系定义了某个软件迭代将访问哪个硬件内存。硬件访存关系定义了哪个指令迭代将访问的软件定义的张量。为了实现这一步,算法抽线使用intrinsic访问矩阵Z和matching矩阵Y计算软件访存关系ZY。如果X和X'相同,表示所有访问行为保持不变。类似地,算法计算硬件方寸行为。算法1对于检验十分有效,AMOS使用这个算法保证映射的语义正确性,对于图3,AMOS只找到了35个有效的映射,全体可能的映射是3^7=21087种。
5.3 Exploration of Mapping and Schedule
目前,我们已经能够选择有效的软硬件映射。但是在优化时评估性能是十分困难的,这些映射经过调度优化,例如分块,并行化。我们展示了AMOS考虑的调度优化,表3a。这些不同的调度优化与映射组合起来在性能上表现不同,因为它们对计算核与内存单元资源的利用率不同。组合的调度搜索空间核映射可能非常大(通常超过10^5),这样大的搜索空间需要合理的搜索策略。我们组合了性能模型和调优策略,进行高效的调度和映射搜索。考虑到加速器是层次化设计的,我们的性能模型也是一层层设计的(0层是指令),搜索的符号在表3b种列出,性能模型可以写为:

最大的计算延迟、读延迟,和存储延迟占据了整体pipeline的主要开销,计算延迟既包括了最内层计算的延迟(l-1层),也包括指令延迟(l=0)。指令延迟是一个固定值,可以通过Maestro和TENET等硬件模型估计。最终的延迟需要乘上串行循环的次数,因为这些循环没有绑定到并行核上,是串行执行的。DataIn和DataOut能够通过计算使用的buffers大小估计出来。LLVM和TVM等编译器提供了成熟的工具进行边界推理,我们在这里忽略细节。
我们将这个性能模型与现有的优化框架整合,对映射和优化调度共同组成的搜索空间进行搜索。我们在调优引擎中使用基因算法(Ansor),因为这个算法被证实是sota的。细节上,在调优的开始,AMOS枚举所有可能的映射,通过映射生成和检验步骤,然后为映射候选随机指定不同的调度参数。映射和调度就可以通过我们的性能模型进行评估。根据评估结果,AMOS选择一组较好的映射,然后注解它们的调度,产生新的选择。这个过程可能会重复上千次,最终的结果是一对好的映射和调度参数,用于最终的代码生成。
6 Implementation of AMOS
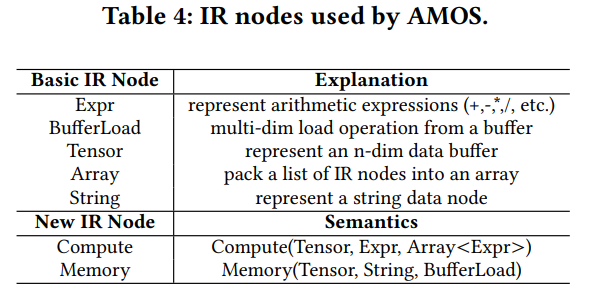
硬件抽象作为编译器IR节点(表4),我们加入了两种新的IR节点(Compute和Memory)。Compute和Memory节点可以表示所有我们需要的计算和存储抽象信息。Compute节点代表一个小的嵌套循环,对应一个计算指令。类似地,Memory节点对应读写操作以及对应的内存指令。这些IR节点有特定的属性,如表4.对于Compute节点,第一个属性是目的buffer,用于存储计算结果,用Tensor节点表示。第二个属性是表达式,描述具体的数学计算(加、乘等)。我们使用Expr节点表示。第三个属性描述指令的计算抽象。我们使用Expr数组表示。对于Memory节点,第一个属性是目的buffer,第二个属性是String节点,用于编码buffer范围信息(global,shared和register)。第三个属性是BufferLoad节点,表示源buffer和load索引。AMOS使用这个IR表示硬件指令,复用了TVM的张量化接口,将这些节点在下降和代码生成的过程中插入编译器的抽象语法树。
7 Experimental Results
7.1 Evaluation Setup
我们首先在三个常见的加速器上评估,包括Tensor Core GPU(V100和A100)的mma_sync指令,Intel CPU,指令集AVX-512(Xeon(R) Silver 4110)的mm512 dpusds epi32,Mali Bifrost GPU(G76)的arm_dot指令。另外,我们还在新的加速器架构和指令上进行了测试。
我们首先验证AMOS性能模型的准确性。然后评估在Tensor Core上对于单算子和DNN网络的效果,之后在AVX-512 CPU和Mali GPU的卷积上验证。最后,在新的加速器结构上,比较了PyTorch,CuDNN,Ansor,AutoTVM,UNIT和AKG的性能,我们选取图像处理和自然语言处理的DNNs作为基准,包括ShuffleNet,ResNet-18和ResNet-50,MobileNet-V1,Bert(基本配置),MI-LSTM。AMOS是全自动的,只需要输入软件的描述,而其他的编译器需要模板作为额外的输入。我们将在7.3章解释细节。
7.2 Model Validation
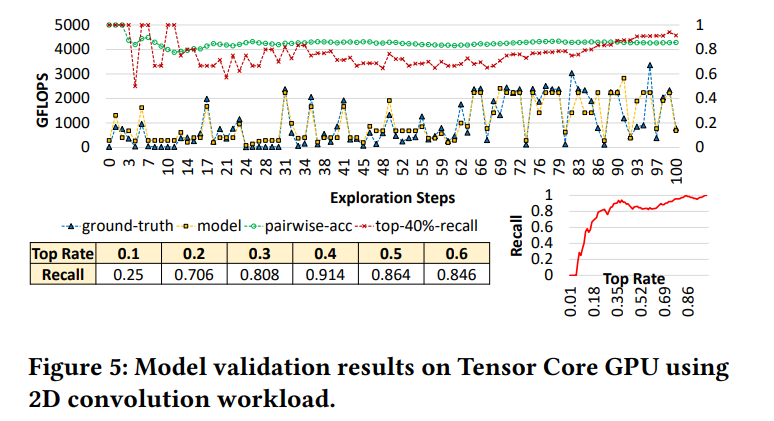
我们使用Tensor Core检验AMOS的性能模型。首先在V100 GPU上进行配置,包括SM的数量,一个SM上子核心的数量,内存大小,和估计的带宽。我们使用RestNet-18的2D卷积层,与真实性能进行对比,在图5展示的不同阶段对比。我们还比较了pairwise(rank)准确度(绿色),以top-40%映射的召回值(红)。对于每个搜索步骤,预测的性能与真实性能趋势上接近,pairwise准确度展示了AMOS能够预测相对的性能(整体准确率为85.69%,top-40%找回率展示了AMOS能够很大概率得到top 40%的映射(整体召回率为91.4%)),我们还列出了不同的top找回结果(图5)。结果展示了AMOS能够在搜索过程中获得较好结果,以80%的可能性得到top 30%的映射。基于这个性能模型,AMOS能成功过滤掉较差的映射,在搜索过程中只选择那些较好的映射。
7.3 Evaluation for Operators on Tensor Core
对于单个算子,我们考虑GEMV,GMM,1d卷积,2d卷积,3d卷积,转置2d卷积,组卷积,dilated 卷积,深度卷积,capsule 卷积,批卷积,grouped全连接层,矩阵评价和方差,以及扫描计算。我们测试了113种不同的配置(平均每个算子7-8个),并展示了加速比。所有的配置均来自于真实的网络。
首先,我们将AMOS与PyTorch对比。PyTorch使用手工优化的算子库,例如CuDNN,CuBlas和CUTLASS来支持不同种类的算子。我们展示了V100和A100上batch 1的结果(图6a和b)。AMOS在所有的算子上超过了PyTorch,在V100和A100上有评价2.5,2.8的加速比。AMOS能为不同平台生成高性能代码,取得加速的原因是软硬件的映射,而PyTorch只手工实现了固定的映射。
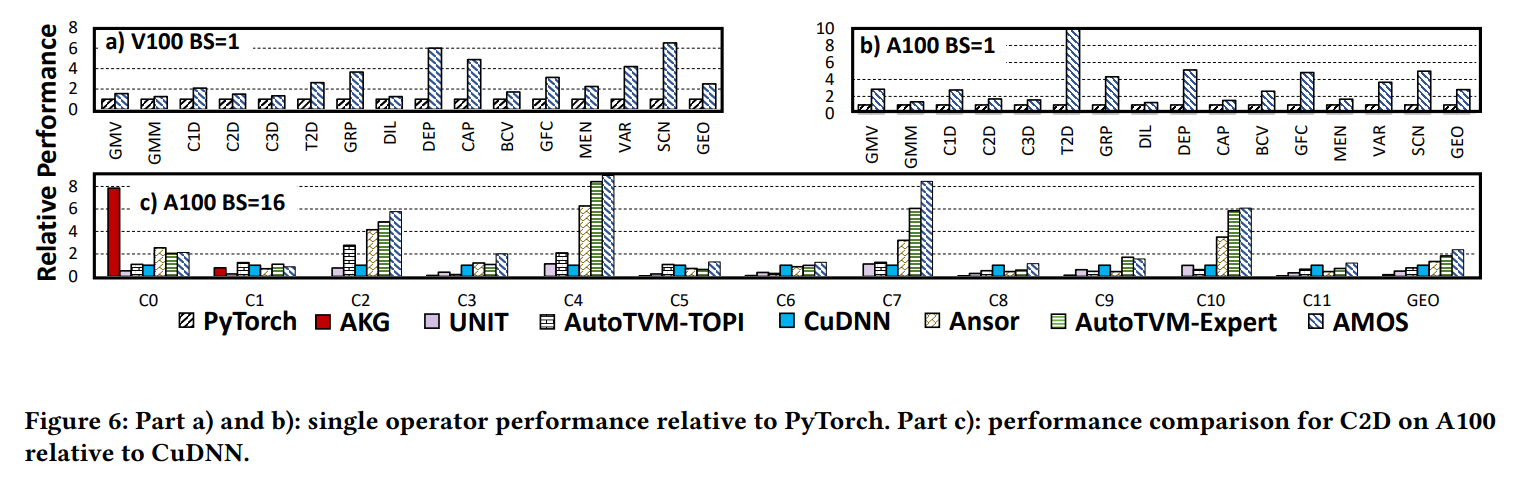
其次,我们比较了sota编译器,使用C2D的NCHW layout作为性能评估。我们使用ResNet-18的所有卷积层(公12种不同配置),C0-C11(表5)来表示。结果在图6c中展示。AMOS取得了最好的平均性能,(2.38 CuDNN,1.79 Ansor,1.30 AutoTVM-Expert,4.96 UNIT)的加速比。AKG只能映射很少的层,因为他的多面体模型不是为指令设计的,不能将卷积映射到Tensor Core。Ansor没有Tensor Core的代码生成规则,所以对所有层均不能使用Tensor Core。当这些编译器不能使用Tensor Core,它们将使用CUDA Core。但是不同的编译器有不同的优化技术,因此,在CUDA Core上的性能不同。UNIT的模板总是将高度和宽度维度映射到Tensor Core指令上,但是忽略了batch维度,导致低并行度,因此比AMOS显著地慢。AutoTVM错过了一些映射的机会,因为手写模板只设计了NHWC和HWNC的layout,NCHW layout在PyTorch等框架中广泛使用,但是NHWC在一些情况下更为适合。AMOS不限制特定的layout,所以,我们用NHWC的layout与AutoTVM相比,有2.83的加速比。我们还评估了手动添加新模板,支持NCHW layout的FP16精度。但是整体的性能仍然比AMOS差,因为模板只支持了固定的映射策略,而AMOS能够对C2D进行系统的搜索。

最终,AMOS为这12个卷积层,选择了8种不同的映射方法(表5)。例如,C7将npq映射到i1,c到r1,其他的编译器不能使用这种映射,因为模板是固定的。例如,UNIT模板只能映射pq到i1,AMOS的C9映射在图3d展示过了,C5的的映射与UNIT模板相同。所有这些映射均由AMOS自动生成。
7.4 Evaluation for Networks
AMOS能让更多算子被映射到Tensor Core上,并找到比手工调优更优的映射。我们使用batch size1和16进行全网络的性能比较。结果如图7a到d展示。Bert的batch size16在V100上没有展示,因为内存超过了限制。AMOS在所有Bert16的A100基准上超过了PyTorch(加速比从0.91到10.42)。Bert主要有GEMM组成,GEMM在算子库是高度优化过的。即使如此,对于batch size 16,AMOS仍然取得了90%接近这些库的性能。ShuffleNet的显著加速来自于group卷积和深度卷积的加速,在手工算子库上对Tensor Core支持较少。

我们对比了与UNIT和TVM不同batch sizes的网络表现,使用ResNet-18,ResNet-50和MobileNet-V1作为比较,图7e展示了A100的结果。对于多数测试样例,AMOS得到了最好的性能,对于ResNet,加速比的提升来自于常规卷积和strided卷积,strided卷积难以映射到Tensor Core,因为访存的索引,难以在编译过程种生成对应的地址,TVM没有使用Tensor Core指令。UNIT的模板没有考虑batch维度,他的性能差于TVM和AMOS。结果展示了AMOS的映射生成逻辑能够处理不同的复杂算子,利用Tensor Core得到高性能程序。
7.5 Evaluation On Other Accelerators
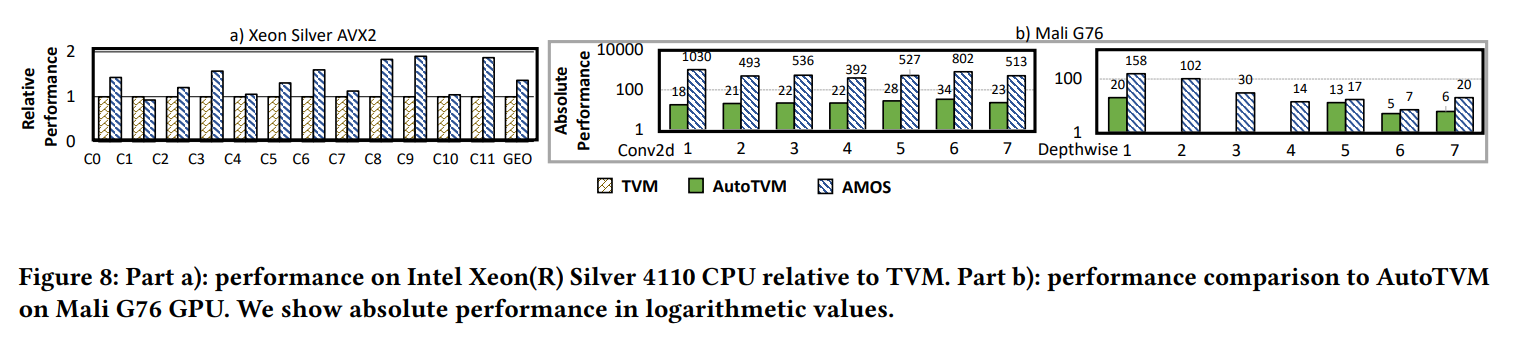
Vector Units in Intel CPU:在Intel CPU上,我们加入AVX-512 VNNI指令的硬件抽象(用于矩阵向量乘),使用AMOS为C2D生成代码。我们与TVM对比,TVM使用手写模板来生成VNNI指令。图8a展示了结果。C0-C11表示C2D在表5的配置。AMOS在除了C2的所有情况超过TVM,平均加速比1.37。
Dot Units in Mali GPU:在Mali GPU(Bifrost architecture),我们加入硬件抽象,与AutoTVM对比,C2D和DEP配置来自MobileNet-V2(共7个层)。AutoTVM对Bifrost架构使用手写模板,实验结果表明,模板对于DEP的一些层(2,3,4)优化不够,AutoTVM不能生成代码,因为内部的错误。所以,最终的AutoTVM性能比AMOS慢很多。绝对性能在图8b展示,加速比最多有25.04。
New Accelerators:为了展示AMOS的通用性,我们使用3个虚拟加速器,提供计算和内存指令。我们使用AXPY,GEMV和CONV三个指令,因为它们对应了BLAS算子的三个层次(GEMM比较简单,所以我们使用了更复杂的卷积,level=3)我们加入硬件抽象,使用C3D作为输入软件描述。AMOS能够找到15,7和31种不同映射,针对AXPY加速器,GEMV加速器和CONV加速器。例如,一个CONV加速器的映射是channel,height,width和input channel到卷积单元。实验结果展示了AMOS可以应用于新一代加速器,这些加速器有不同的指令,证明了本文提出技术的通用性。
7.6 Discussion
相比于sota的提升来自于两方面
-
AMOS能够系统地搜索映射空间
-
AMOS能够灵活地映射,得到更好的性能
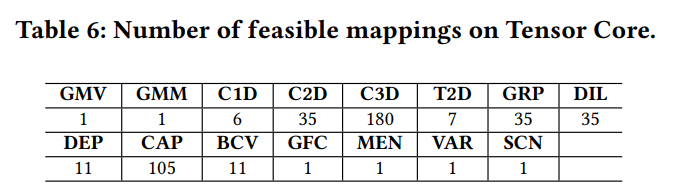
首先,我们展示AMOS针对不同workload找到的可行的映射(表6)。这些不同的映射在硬件抽象上映射到Tensor Core是不同的。例如,AMOS能够生成180种不同的C3D映射,其中一些需要复杂的变换。例如一些变换将3D卷积映射到2D矩阵乘,通过映射channel维度和图像height/width/depth维度到Tensor Core。而其他的一些映射首先将3D卷积变为一系列2D卷积,然后再将2D卷积转换为2D矩阵乘,映射到Tensor Core。
其次,AMOS能够灵活地映射不同的输入shape,而手工优化库和基于模板的编译器只能解决固定的映射。为了阐释这一点,我们使用C2D层(表5),将AMOS与CuDNN和固定映射比较。我们使用AMOS生成两种固定的,但是具有代表性的映射:AMOS-fixM1(使用固定的im2col映射)和AMOS-fixM2(使用固定的融合hw映射)。AMOS-fixM1将npq映射到Tensor Core的r1维度,AMOS-fixM2只映射c到r1,将pq映射到i1,这种im2col映射被CuDNN广泛使用,融合hw被UNIT广泛使用。为了比较,AMOS-fixM1和AMOS-fixM2有在AMOS上相同的调度搜索容量,但是使用固定的模板映射到Tensor Core用于比较。
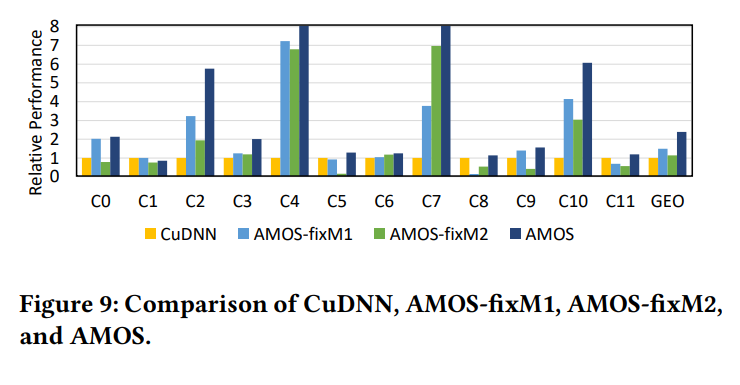
总体来看,相比于AMOS,fixM1和fixM2分别下降了36.8%和31.9%。例如,对于C3层,M1和M2由于启动了太多线程块,导致一个SM的high wave counts,性能下降。对于CuDNN,由于线程块数量设置地比较少,并行度比较低。此外,CuDNN将所有迭代crs都映射到Tensor Core,这需要比较大的shared memory存储输入数据,AMOS只映射cs到Tensor Core,在一个warp中将矩阵乘法分为三个步骤,这样可以复用shared memory,减少资源压力。所以AMOS比CuDNN快(3.66)。
8 Related Work
Using Accelerators with Hand-optimized Libraries。Nvidia GPU库,例如CuDNN,CuBlas,CUTLASS被开发出来,用于Tensor Core计算GEMM和卷积。在CPU上,oneDNN利用特殊的指令集,例如AVX-512来进行高性能计算。这些库是手工开发,调优的,需要数月甚至几年进行开发,深度学习框架PyTorch,TensorFlow和MXNet依赖这些库来部署DNN模型。
Hardware-aware Mapping。最近的编译器,映射器,例如Timeloop,dMazeRunner,Triton,CoSA,SARA和HASCO能够将软件映射到加速器上,并考虑硬件的约束,例如PE连接,内存容量。这些编译器利用硬件信息分析映射的质量,通常将映射问题转换为线性规划问题。对于能够感知硬件,硬件将体系结构能完整展示出来的场景,这些编译器是合适的。本文关注另一种场景,硬件的细节没有完全暴露,只提供了可编程的指令集(ISA-aware)。
9 Conclusion
加速器使得张量程序的性能进一步提升,但是加速器提供的内置函数科恩那个难以使用。现有的方法包括手工调优库,基于模板的编译器,依赖固定的模板优化代码,这导致可能得不到最好的性能,并且开发代价较大。本文提出了AMOS,一个为加速器的编译和优化框架。AMOS提出了一种全新的硬件抽象来表示加速器指令。能够系统的搜索映射空间,对多种kernels灵活进行映射。实验中,AMOS在Tensor Core,AVX-512 CPU和Mali GPU上,相比sota方法有显著加速比。
- Accelerators Computations Abstraction Automatic Enablingaccelerators computations abstraction automatic optimization abstraction tensorized automatic accelerators enabling computations flexibility the enabling focuses security spring enabling requests abstraction interpreters abstraction languages with abstraction object