发表时间:2018(AAAI 2018)
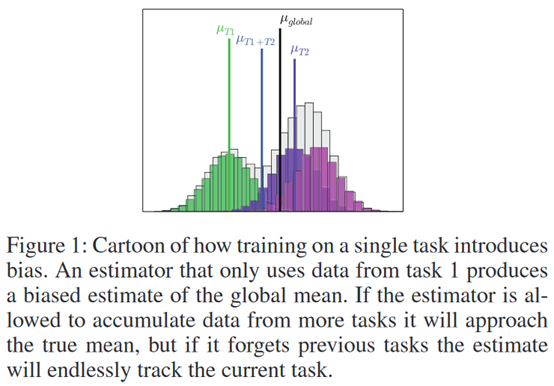
文章要点:这篇文章想解决强化学习在学多个任务时候的遗忘问题。作者提出了一种对通常的experience replay增广的方式,就是在保持之前的buffer的同时,再维持一个buffer用来存少部分有代表性的experience作为long-term memory。作者研究了四种挑选experience的方式:favoring surprise, favoring reward, matching the global training distribution, and maximizing coverage of the state space.结果表明distribution matching和coverage maximization可以避免catastrophic forgetting。
具体的,作者基于DQN,所以多任务的DQN其实就是采多个任务的experience一起训练

然后这四种选样本的方式都比较直观,其中surprise就是TD error

Reward依据的是reward绝对值的大小。Global Distribution Matching就是从所有的样本里面做down sample。Coverage Maximization搞了一个聚类的方式,每次用新的样本替换掉距离最近的样本。结果上看可以缓解catastrophic forgetting。
总结:无。
疑问:普通的强化会不会有遗忘的问题,比如学到后面忘了前面?(应该会吧,但是每次reset又会采到前面的样本,估计就还好。)
- Experience Selective Lifelong Learning Replayexperience selective lifelong learning replay conservative estimation experience experience efficient tables replay optimization experience replay experience framework reverb replay fundamentals revisiting experience replay experience remember forget replay prioritized experience sequence replay topological experience replay experience learning contexts buffers