摘要:经验回放(ER)通过允许智能体在回放缓冲区中存储和重用其过去的经验,提高了离线强化学习(RL)算法的数据效率。虽然已经提出了许多技术,以通过偏差如何从缓冲区中采样来增强ER,但迄今为止,它们还没有考虑在缓冲区内刷新经验的策略。本文提出了用于经验回放的清醒梦(LiDER),一个概念上的新框架,允许通过利用智能体的当前策略来刷新回放体验。
LiDER由三个步骤组成:首先,LiDER将智能体移动回过去的状态。其次,从该状态,LiDER然后让智能体通过遵循其当前策略执行一系列动作——就像智能体在“做梦”过去,并可以尝试不同的行为以在梦中遇到新的体验。第三,如果新的体验结果比代理之前体验的更好,LiDER存储和重用它,即刷新它的记忆。
LiDER被设计成可以轻松地合并到异策略中,使用ER的多worker RL算法;在这项工作中,我们提出了一个将LiDER应用于基于演员评论家的算法的案例研究
1 Introduction
最近成功地将强化学习(RL)与深度学习相结合的关键因素之一是经验回放(ER)机制[27]。
现有的ER方法通常基于一组固定的经验。也就是说,一旦一个经验被存储,它将在缓冲区中保持静态,直到老化。前几个步骤的经验对于当前策略的重演可能不再有用,因为它是在过去更糟糕的策略中产生的。
如果agent有机会在同一点再次尝试,其当前策略可能会采取不同的行动,从而获得比过去更高的回报。因此,agent应该重播的是更新的体验,而不是旧的体验
LiDER通过三个步骤刷新回放体验:
- 首先,LiDER将agent移动回它之前访问过的状态。
- 其次,LiDER让agent遵循其当前策略,从该状态生成新的轨迹。
- 第三,如果新轨迹带来的结果比智能体之前从该状态中经历的更好,LiDER将新经验存储到单独的回放缓冲区中,并在训练期间重用它。
我们将这个过程称为“经验回放的清醒梦”,因为这就好像智能体在“做”关于过去的梦,并且可以控制梦在过去的状态下再次练习,以获得更好的回报
LiDER的一个限制是它需要环境交互来刷新过去的状态。
2 Background
2.1 Reinforcement Learning
2.2 Asynchronous Advantage Actor-Critic
2.3 Transformed Bellman Operator for A3C
2.4 Self Imitation Learning for A3CTB
3 Lucid dreaming for experience replay
LiDER被设计为可以轻松地合并到使用ER的离线、多worker RL算法中。
我们使用SIL在A3C框架中实现LiDER有两个原因。
- 首先,A3C架构允许我们方便地与A3C和SIL worker并行添加“刷新”组件,这节省了训练的时间。
- 其次,SIL框架是一个非策略的actor-critic算法,它以直接的方式集成了经验回放缓冲区与A3C,使我们能够直接利用片段的返回G进行策略更新——这是liDER的一个关键组件
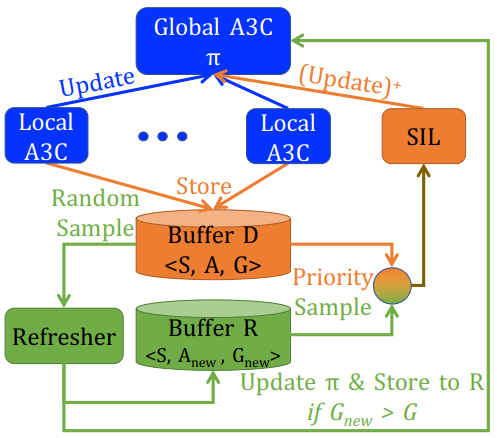
上图显示了LiDER实现架构。
- A3C组件用蓝色表示:k个并行worker与它们自己的环境副本交互,以更新全局策略π。
- SIL组件为橙色:一个SIL worker和一个优先重放缓冲区D被添加到A3C。
- 缓冲区D以D= {S, A, G}的形式存储来自A3C worker的所有经验。缓冲区D按优势值优先,这样好的状态更有可能被采样。
- SIL工作程序与A3C工作程序并行运行,但不与环境交互;它只从缓冲区D中采样,并使用具有正优势值的样本更新π
- 引入了刷新工作者(绿色)的新概念,通过利用智能体的当前策略,从缓冲区D随机采样的过去状态中生成新的体验。如果新体验获得的收益高于当前存储在replay buffer D中的内容,则用于更新全局策略π,并将其存储到replay buffer R中以供重用。
我们引入了与A3C和SIL并行的“刷新”工作者的新概念,以从过去的状态生成新数据(以绿色显示)。刷新器可以访问环境,并从缓冲区D中随机采样状态作为输入。对于采样的每个状态,刷新器将环境重置为该状态,并使用代理的当前策略执行rollout,直到到达终端状态(例如,代理失去生命)。
如果新轨迹的蒙特卡罗返回值Gnew高于之前的返回值G(从缓冲区D中采样),则新轨迹立即用于更新全局策略π。更新以与A3C工人相同的方式完成(公式(1),用Gnew替换Q”)。
如果Gnew > G,则新的轨迹也存储在优先级缓冲区R = {S, new, Gnew}中(优先级由优势决定,就像在缓冲区D中一样)。
最后,SIL worker从两个缓冲区中采样如下。从缓冲区D和R 优先级各取一批样本。将两批样品混合在一起放入临时缓冲液中,如图1中绿橙圈所示;临时缓冲区以同等优先级处理所有样本。然后从两批的混合物中(如棕色箭头所示)取一批样品(替换),SIL使用该批的好样品进行更新。
需要注意的是,虽然临时缓冲区中的样本以同等优先级初始化,但采样过程并不是均匀随机的,随机优先级的优先级采样实现。有了这个临时缓冲区来混合缓冲区D和R的transition,代理就可以灵活地选择过去和/或刷新的经验,而不需要固定的采样策略。
我们总结了算法1中LiDER的刷新工作者过程。A3C和SIL工作者的完整伪代码。
Algorithm 1


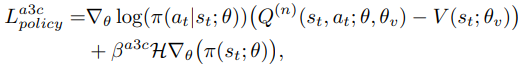
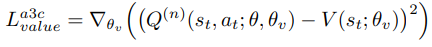
LiDER的主要好处是,它允许代理利用其当前策略来刷新过去的经验。但是,LiDER确实需要刷新器使用额外的环境步骤(参见算法1行11:我们在测量全局步骤时考虑了刷新步骤),如果在环境中行动是昂贵的,这可能会引起关注。似乎刷新体验的高质量补偿了代理需要学习的额外体验数量。也就是说,通过利用刷新工作器,与没有刷新相比,LiDER可以在更短的时间内达到一定程度的性能——这是一个重要的好处,因为RL算法通常需要大量数据。
Algorithm 2

Algorithm 3

- Experience Refreshing Dreaming Current Replayexperience refreshing dreaming current replay conservative estimation experience experience efficient tables replay experience framework reverb replay optimization experience replay fundamentals revisiting experience replay experience remember forget replay prioritized experience sequence replay topological experience replay refreshing