发表时间:2021 (NeurIPS 2021)
文章要点:理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with higher hindsight TD error, better on-policiness and more accurate target Q value should be assigned with higher weights during sampling.)。之前的方法只部分考虑了这些strategy,并且之前的这些目标并没有直接和RL的目标函数一致,minimize policy regret,所以他们在某些情况下可能和RL的目标是mismatch的。这篇文章从regret minimization的角度来设计experience replay,直接和RL的目标一致,提出了ReMERN和ReMERT算法。ReMERN学习了一个error network来度量Q value的误差,ReMERT利用了状态的时序关系,越接近终止状态的value误差越小。
作者先给了个例子来说明,更低的TD error或者更准的target Q value不能保证更好的效果,因为他们的目标和RL最大化return的目标不一定匹配。如下图所示

这个例子里最大return的policy应该是先一直左走,最后一步往右走。假设Q value初始化为0,那么对PER(prioritizes state-action pairs with high TD error)来说往左走的TD error比往右走大,导致刚开始就学错了。对于DisCor(perform Bellman update on state-action pairs that have more accurate Bellman targets)来说,直接一步到terminal state肯定有最准的target Q,所以DisCor一上来也会学错。
作者先定义regret minimization的优化目标

然后拆开推出来最小化这个目标就相当于最小化这些项

最后总结下来就是Higher hindsight Bellman error,More on-policiness,Closer value estimation to oracle,Smaller action likelihood。
作者借鉴DisCor的思路,
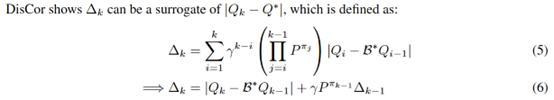
然后自身的采样权重可以写为

剩下的是就是估计\(\Delta_{k-1}\)了,作者用神经网络,基于公式(6)用bootstrapped target的方式来更新,这就是ReMERN (Regret Minimization Experience Replay using Neural Network)。
接着作者提出了一个不需要用网络来估计的改进算法ReMERT (Regret Minimization Experience Replay using Temporal Structure),基于离terminal state越近,Q value越准,作者先定义到终止状态的距离

然后推导了Q的误差可以大概率被这个距离控制住

然后基于这个来设计采样权重

最后贴几个结果,个人感觉效果不是很明显
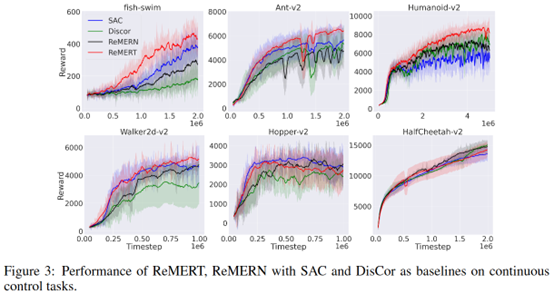

总结:主要还是在做理论推导吧感觉,最后落到实际算法,主要就是一个度量on policy的ratio以及一个target Q的误差估计。效果上来看的话,不是很明显。
疑问:里面这个Smaller action likelihood指的是什么,没看懂

ReMERN里面用网络估计误差的时候还需要一个最优贝尔曼算子,这个地方直接近似了吗?

给了个github链接,但是还没代码,开源了可以试试效果。
- Reinforcement Minimization Experience Off-Policy Learningreinforcement minimization experience off-policy reinforcement exploration off-policy learning reinforcement composition importance experience off-policy learning planning policy reinforcement learning experience selective lifelong learning noise reinforcement exploration learning reinforcement distillation teachable learning reinforcement learning chapter reinforcement transformer decision learning