
发表时间:2021(ICLR 2021)
文章要点:这篇文章想说,之前的experience replay的priority比如PER,都是单个transition独立设置的,并没有考虑transition之间的关系。这篇文章提出了一个叫Neural Experience Replay Sampler (NERS) 的learning-based sampling method。这个方法用强化的方式来学采样,它的输入同时考虑了单个的transition的特征和全局的特征(design a novel permutation-equivariant neural architecture that takes contexts from not only features of each transition (local) but also those of others (global) as inputs)。这个方式可以采到diverse并且meaningful的transition,提高了sample efficiency。
作者首先举了个Pendulum的例子来说明rule-based方法的问题在哪
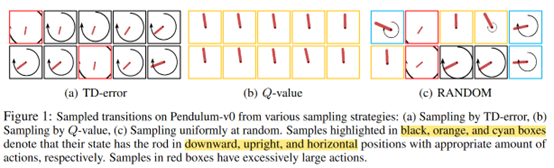
图里三个方法分别基于TD error,Q-value和random。作者想说,TD error大的地方基本上都是棍子朝下的时候,也就是游戏差不多刚开始的时候 。Q-value采到的样本基本都是快成功的时候。这些状态单个来看都是meaningful的,一类是TD error大,一类是return很高,都有助于学习,但是合到一起看样本多样性太少,冗余度太高。然后random采到的样本,diversity够了,但是经常会采到一些和训练无关的transition,比如图中红框标出的样本TD error和return都很小。
然后作者的出发点就是设计一个sample method采样diverse并且meaningful的样本,这就需要考虑采样出来的batch里面的样本多样性(measure the relative importance among sampled transitions since the diversity should be considered in them, not all in the buffer)。作者提出的NERS就是通过学习的方式来度量相对重要性。
具体来说,作者存的transition为
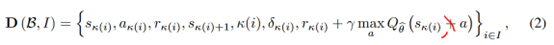
含义分别是{状态,动作,回报,下一个状态,timestep,TD error,估计的Q value}
然后有三个网络\(f_l\),\(f_g\),\(f_s\)。\(f_l\),\(f_g\)分别考虑local和global的特征,\(f_s\)用来计算最后的score用来采样。把transition作为特征输入到网络里面,先过\(f_l\),\(f_g\),再到\(f_s\)得到score,
然后就用PER的方式计算采样概率和权重修正


接着的问题是这个网络如何训练,作者定义了一个replay reward来度量performance gain,其实就是当前policy和前一个policy的期望回报的差
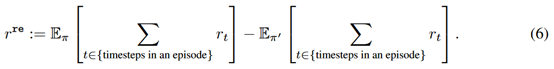
然后就用REINFORCE训练。
这里另一个问题是replay reward怎么来,通常重新evaluate会更准,不过作者实验发现直接从buffer里面找之前的transition也可以,影响不大。
最后结果如下
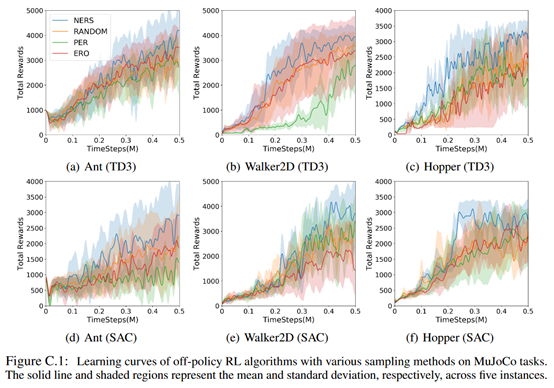

总结:从效果上看,在某一些任务上有一定的提升,但是也不是很明显其实,而且这个过程多了好多计算量啊。
疑问:是不是可以直接搞一个rule based方式来考虑TD error,reward,diversity之类的,这样计算量也少。
- EXPERIENCE LEARNING CONTEXTS BUFFERS GLOBALexperience learning contexts buffers experience selective lifelong learning consistency learning global local local-global dependency learning mapping contexts dbus_contexts contexts warning oldest active contexts quot dbus_contexts directory buffers 组件contexts页面 地图