发表时间:2021
文章要点:这篇文章想说Prioritized experience replay这类方法通过surprise (the magnitude of the temporal-difference error)来采样,但是surprise只能量化unexpectedness,experience的重要性还是不清楚(importance)。作者定义experience的重要度在于可以给更新带来多大的累计回报的提升(We define the value of experience as the increase in the expected cumulative reward resulted from updating on the experience)。作者提出了三个指标来度量experience的重要性,然后理论证明了surprise是上界,最后做实验验证效果。
首先,作者定义expected value of backup

这个式子就定义了更新前和更新后的value的区别。然后这个式子可以拆开写成两项,evaluation improvement value和policy improvement value

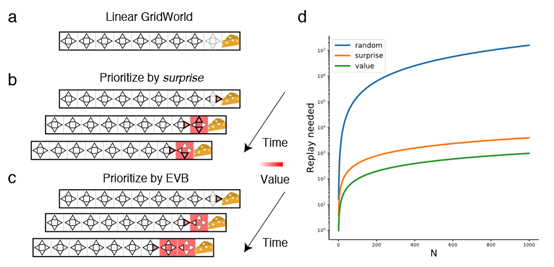
根据这个式子,作者推了Q-learning和soft Q-learning的情形。然后基于这个新的指标去采样。最后的结果如下
作者中间还证了一下bound,贴到这里

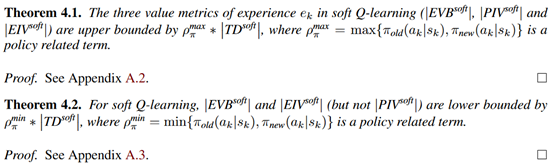
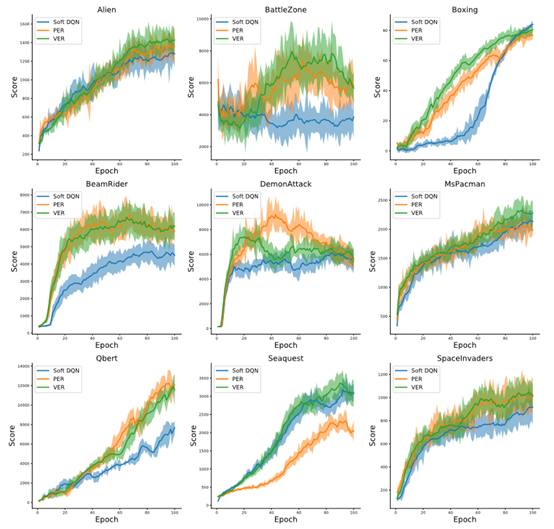
总结:从最后的结果来看,基本没有提升,可能主要还是做理论吧,毕竟只有bound变紧了才有效果,文章里的指标也不好说到底紧了没,紧了多少。
疑问:证明没看。
- Prioritized Perspective Revisiting Experience Replayprioritized perspective revisiting experience fundamentals revisiting experience replay prioritized experience sequence replay model-augmented prioritized experience augmented replay conservative estimation experience experience efficient tables replay optimization experience replay experience framework reverb replay experience remember forget replay topological experience replay