来自美团技术团队♪(^∀^●)ノシ
论文地址:https://arxiv.org/abs/2104.13840
代码地址:https://git.io/Twins
一、写在前面
本文提出了两种视觉转换器架构,即Twins-PCPVT和Twins-SVT。
- Twins-PCPVT 将金字塔 Transformer 模型 PVT [2] 中的固定位置编码(Positional Encoding)更改为团队在 CPVT [3] 中提出的条件式位置编码 (Coditional Position Encoding, CPE),从而使得模型具有平移等变性(即输入图像发生平移后,输出同时相应发生变化),可以灵活处理来自不同空间尺度的特征,从而能够广泛应用于图像分割、检测等变长输入的场景。
- Twins-SVT 提出了空间可分离自注意力机制(Spatially Separable Self-Attention,SSSA)来对图像特征的空间维度进行分组,分别计算各局部空间的自注意力,再利用全局自注意力机制对其进行融合。这种机制在计算上更高效,性能更优。
架构高效且易于实现,仅涉及在现代深度学习框架中高度优化的矩阵乘法。更重要的是,所提出的架构在广泛的视觉任务上取得了优异的性能,包括图像级分类以及密集的检测和分割。简单性和强大的性能表明论文提出的体系结构可以作为许多视觉任务的更强大的骨干。
二、Motivation
1.还是计算量这个历史遗留问题,因此设计更高效的视觉注意力模型,并更好地适配下游任务成为了当下研究的重点。
香港大学、商汤联合提出的金字塔视觉注意力模型 PVT 借鉴了卷积神经网络中的图像金字塔范式来生成多尺度的特征,这种结构可以和用于稠密任务的现有后端直接结合,支持多种下游任务,但由于 PVT 使用了静态且定长的位置编码,通过插值方式来适应变长输入,不能针对性根据输入特征来编码,因此性能受到了限制。另外,PVT 沿用了 ViT 的全局自注意力机制,计算量依然较大。
微软亚研院提出的 Swin 复用了 PVT 的金字塔结构。在计算自注意力时,使用了对特征进行窗口分组的方法,将注意力机制限定在一个个小的窗口(红色格子),而后通过对窗口进行错位使不同组的信息产生交互。这样可以避免计算全局自注意力而减少计算量,其缺点是损失了全局的注意力,同时由于窗口错位产生的信息交互能力相对较弱,一定程度上影响了性能。
2.视觉注意力模型设计的难点
简单总结一下,当前视觉注意力模型设计中需要解决的难点在于:
- 高效率的计算:缩小和卷积神经网络在运算效率上的差距,促进实际业务应用;
- 灵活的注意力机制:即能够具备卷积的局部感受野和自注意力的全局感受野能力,兼二者之长;
- 利于下游任务:支持检测、分割等下游任务,尤其是输入尺度变化的场景。
三、Contribution
从这些难点问题出发,基于对当前视觉注意力模型的细致分析,美团视觉智能部重新思考了自注意力机制的设计思路,提出了针对性的解决方案。首先将 PVT 和 CPVT 相结合,形成 Twins-PCPVT 来支持尺度变化场景的下游任务。再从自注意机制的效率和感受野角度出发,设计了兼容局部和全局感受野的新型自注意力,叫做空间可分离自注意力 (Spatially Separable Self-Attention,SSSA), 形成了 Twins-SVT。
四、Method
4.1 Twins-PCPVT
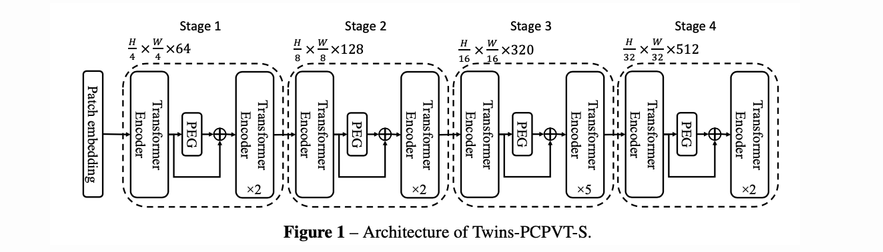
Twins-PCPVT 通过将 PVT 中的位置编码(和 DeiT 一样固定长度、可学习的位置编码)替换为 CPVT 中的条件位置编码 (Conditional Positional Encodings,CPE)。生成 CPE 的模块叫做位置编码器(Positional Encoding Generator, PEG),PEG 在 Twins 模型中的具体位置是在每个阶段的第 1 个 Transformer Encoder 之后,如下图 4所示:
代码部分:
采用了最简单的二维深度卷积实现。
class PEG(nn.Module):
def __init__(self, in_chans, embed_dim):
super(PEG, self).__init__()
self.peg = nn.Conv2d(in_chans, embed_dim, 3, 1, 1, bias=True, groups=embed_dim)
def forward(self, feat_token, H, W):
B, N, C = feat_token.shape
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
x = self.peg(cnn_feat) + cnn_feat
x = x.flatten(2).transpose(1, 2)
return x
由于PEG是通过动态卷积来生成位置编码的,所以可以适应不同大小的输入,灵活处理不同空间尺度的特征,另外 PEG 采用卷积实现,因此 Twins 同时保留了其平移等变性,这个性质对于图像任务非常重要,如检测任务中目标发生偏移,检测框需随之偏移。实验表明 Twins-PCPVT 系列模型在分类和下游任务,尤其是在稠密任务上可以直接获得性能提升。该架构说明 PVT 在仅仅通过 CPVT 的条件位置编码增强后就可以获得很不错的性能,由此说明 PVT 使用的位置编码限制了其性能发挥。
4.2 Twins-SVT
全局注意力策略的计算量会随着图像的分辨率成二次方增长,因此如何在不显著损失性能的情况下降低计算量也是一个研究热点。Twins-SVT 提出新的融合了局部-全局注意力的机制,可以类比于卷积神经网络中的深度可分离卷积 (Depthwise Separable Convolution),并因此命名为空间可分离自注意力(Spatially Separable Self-Attention,SSSA)。SSSA由局部分组自注意(LSA)和全局次抽样注意(GSA)两部分组成。与深度可分离卷积不同的是,Twins-SVT 提出的空间可分离自注意力(如下图所示)是对特征的空间维度进行分组,并计算各组内的自注意力,再从全局对分组注意力结果进行融合。空间可分离自注意力采用局部-全局自注意力(LSA-GSA)相互交替的机制,分组计算的局部注意力可以高效地传导到全局。
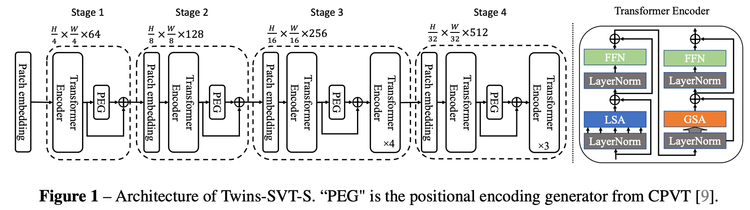
4.2.1 Locally-grouped self-attention (LSA)
局部分组自注意力首先将 2D 特征图平均划分为子窗口,使得自注意力通信仅发生在每个子窗口内。这种设计也与 selfattention 中的多头设计产生了共鸣,其中通信只出现在同一个头的通道内。
分组局部注意力 LSA 关键实现(初始化函数略)如下:
class LSA(nn.Module):
def forward(self, x, H, W):
B, N, C = x.shape
h_group, w_group = H // self.ws, W // self.ws # 根据窗口大小计算长(H)和宽(W)维度的分组个数
total_groups = h_group * w_group
x = x.reshape(B, h_group, self.ws, w_group, self.ws, C).transpose(2, 3) # 将输入根据窗口进行分组 B* h_group * ws * w_group * ws * C
qkv = self.qkv(x).reshape(B, total_groups, -1, 3, self.num_heads, C // self.num_heads).permute(3, 0, 1, 4, 2, 5) # 计算各组的 q, k, v
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale # 计算各组的注意力
attn = attn.softmax(dim=-1) # 注意力归一化
attn = self.attn_drop(attn) # 注意力 Dropout 层
attn = (attn @ v).transpose(2, 3).reshape(B, h_group, w_group, self.ws, self.ws, C) # 用各组内的局部自注意力给 v 进行加权
x = attn.transpose(2, 3).reshape(B, N, C)
x = self.proj(x) # MLP 层
x = self.proj_drop(x) # Dropout 层
return x
虽然LSA是计算友好型的,但是图象被划分为了各个不重叠的子窗口,因此,需要一种机制来进行不同子窗口的通信,像swin一样。否则,自注意力的计算会被限制在窗口内,感受野非常小。
4.2.2 Global sub-sampled attention (GSA)
一个简单的解决方案是在每个局部关注块之后添加额外的标准全局自关注层,这可以实现跨组信息交换。然而,这种方法会带来一定的计算复杂性。
GSA使用一个有代表性的值来代表每个 sub-windows这也就是相当于将其作为self-attention 中的 key。
相比于 ViT 原始的全局自注意力,GSA 的 K、V 是在缩小特征的基础上计算的,但 Q 是全局的,因此注意力仍然可以恢复到全局。这种做法显著减少了计算量。
class GSA(nn.Module):
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # 根据输入特征 x 计算查询张量 q
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # 缩小输入特征的尺寸得到 x_
x_ = self.norm(x_) # 层归一化 LayerNorm
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # 根据缩小尺寸后的特征后 x_,计算 k, v
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale # 计算全局自注意力
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # 根据全局自注意力对 v 加权
x = self.proj(x)
x = self.proj_drop(x)
return x
五、补充
5.1 为什么需要位置编码?
从自然语言任务中我们可以发现,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。例如:
I do not like the story of the movie, but I do like the cast. I do like the story of the movie, but I do not like the cast.
句子中的单词位置发生改变后,句子的意义完全不一致了。
5.2 什么是深度可分离卷积
Depthwise Separable Convolution深度可分离卷积是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution不同于常规卷积操作,Depthwise Convolution的1个卷积核负责1个通道,1个通道只被1个卷积核卷积。
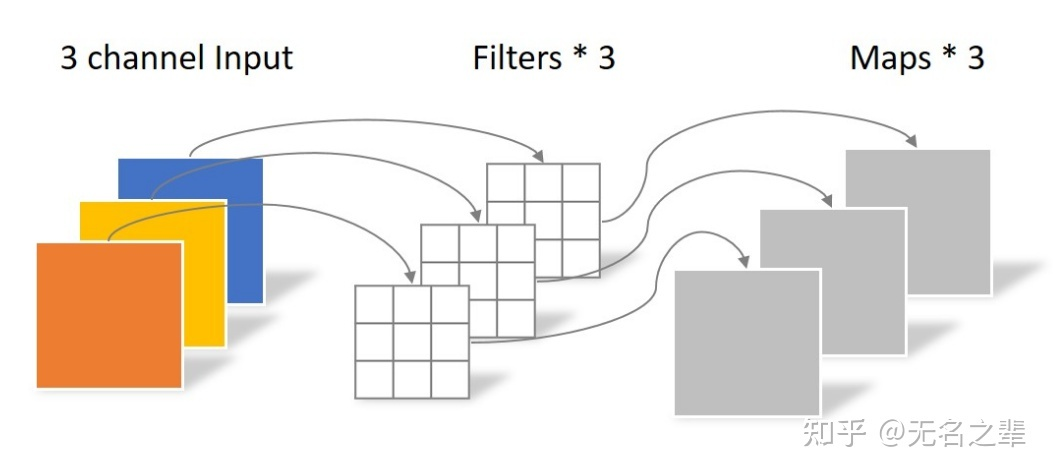
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。

- Transformers Revisiting Attention Spatial Designtransformers revisiting attention spatial self-attention local-global interactions transformers revisiting spatial prototypical revisiting few-shot learning spatial-temporal prioritized perspective revisiting experience fundamentals revisiting experience replay cvpr_spatial-frequency reference spatial change export