Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Revisiting Consistency Regularization for Semi-Supervised Learning
论文作者:Yue Fan、Anna Kukleva、Bernt Schiele
论文来源:2020 GCPR
论文地址:download
论文代码:download
视屏讲解:click
1-介绍
摘要
一致性正则化是半监督学习(SSL)中最广泛的技术之一。一般来说,其目的是训练一个对各种数据扩充不变的模型。在本文中,我们重新讨论了这一想法,并发现通过减少来自不同增强图像的特征之间的距离来增强不变性可以提高性能。然而,鼓励等方差,通过增加特征距离,进一步提高性能。为此,我们提出了一种改进的一致性正则化框架,通过一种简单而有效的技术,特征距离损失,分别对分类器和特征级别施加一致性和等方差。实验结果表明,我们的模型为各种数据集和设置定义了一种新的技术状态,并显著优于以前的工作,特别是在低数据状态下。
正文
动机:
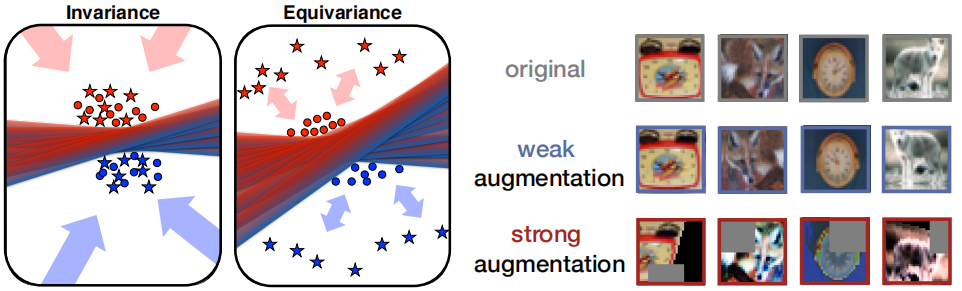
图示:
-
- 在 图1 的右边,说明了强大的数据增强导致感知上高度多样化的图像;
- 在 图1 的左边,等变(equivariance)鼓励同一样本的增广尽可能分开,从而覆盖了更多的空间。不变(invariance)使同一语义类的表示更加紧凑;
贡献:
-
- (1)我们通过一种简单而有效的SSL技术,改进了基于数据增强的一致性正则化,该技术正则化了来自同一类的不同增强图像的特征表示之间的距离;
- (2)我们表明,虽然鼓励不变性会导致良好的性能,但鼓励等方差的不同增强版本的相同图像一致会导致更好的泛化性能;
- (3)我们提供了全面的消融研究,不同的距离函数和不同的增强与提出的FeatDistLoss;
- (4)结合其他强大的技术,我们在各种标准的半监督学习基准中实现了新的最先进的结果,特别是在低数据机制中;
2-方法
一致性正则化
一致性正则化 的想法是为了鼓励模型预测对输入扰动是不变的。给定一批 $n$ 个未标记的图像 $\mathbf{u}_{i}, i \in(1, \ldots, n)$,一致性正则化可以表示为以下损失函数:
$\frac{1}{n} \sum_{i=1}^{n}\left\|f\left(\mathcal{A}\left(\mathbf{u}_{i}\right)\right)-f\left(\alpha\left(\mathbf{u}_{i}\right)\right)\right\|_{2}^{2}$
通过最小化扰动图像之间的 L2 距离,因此鼓励表示对不同的增强变得更不变,这一点帮助实现泛化。这背后的直觉是,一个好的模型应该对图像的数据增强是健壮的。
模型框架
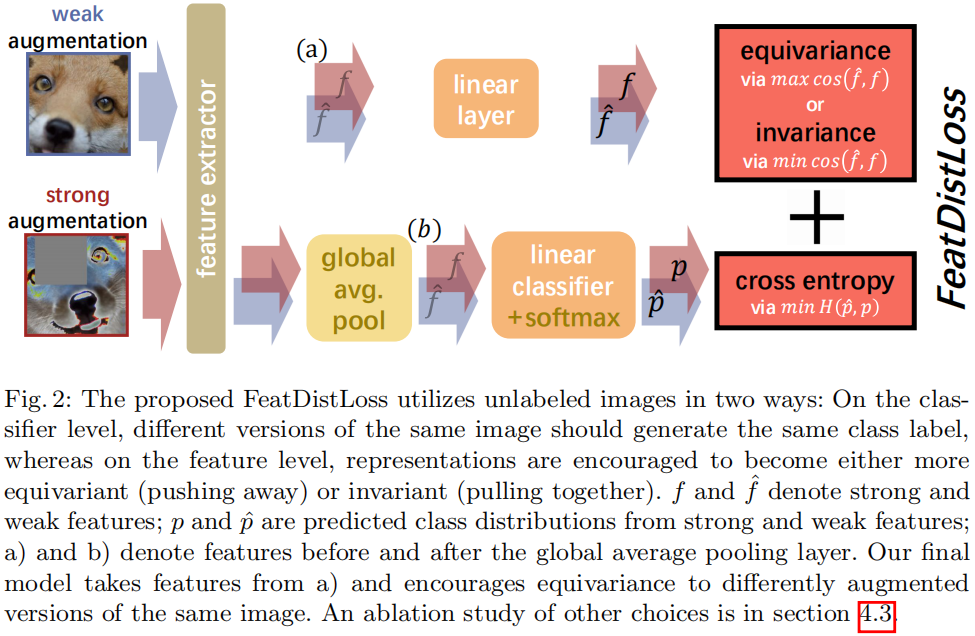
FeatDistLoss 的最终目标包括两个术语:$\mathcal{L}_{\text {Dist }}$(在特征级),明确地规范嵌入之间的特征距离,以及基于伪标记的标准交叉熵损失 $\mathcal{L}_{\text {PseudoLabel }}$(在分类器级别)。
利用 $\mathcal{L}_{\text {Dist }}$,可以减少或增加从原始特征空间投影出来的低维空间中同一图像的弱增强版本和强增强版本之间的特征距离,以克服维数诅咒。
$\mathcal{L}_{\text {Dist }}$ 计算如下:
$\mathcal{L}_{\text {Dist }}\left(\mathbf{u}_{i}\right)=d\left(z\left(f\left(\mathcal{A}\left(\mathbf{u}_{i}\right)\right)\right), z\left(f\left(\alpha\left(\mathbf{u}_{i}\right)\right)\right)\right)$
后文研究了执行 $\mathcal{L}_{\text {Dist }}$ 的不同选择,我们发现在 Figure 2 (a) 上应用 $\mathcal{L}_{\text {Dist }}$ 具有最好的性能。
同时,来自强增强和弱增强的图像应该具有相同的类标签,因为它们本质上是由相同的原始图像生成的。受[46]的启发,给定一个未标记的图像 $\mathbf{u}_{i}$,首先由 $\hat{\mathbf{p}}_{i}=g\left(f\left(\alpha\left(\mathbf{u}_{i}\right)\right)\right)$ 从弱增广图像中生成一个伪标签分布,然后计算伪标签与相应的强增广版本的预测之间的交叉熵损失为:
$\mathcal{L}_{\text {PseudoLabel }}\left(\mathbf{u}_{i}\right)=\ell_{C E}\left(\hat{\mathbf{p}}_{i}, g\left(f\left(\mathcal{A}\left(\mathbf{u}_{i}\right)\right)\right)\right)$
把它们放在一起,功能数据损失处理一批未标记的数据 $\mathbf{u}_{i}, i \in\left(1, \ldots, B_{u}\right)$,损失如下:
$\mathcal{L}_{U}=\frac{1}{B_{u}} \sum_{i=1}^{B_{u}} \mathbb{1}\left\{c_{i}>\tau\right\}\left(\mathcal{L}_{\text {Dist }}\left(\mathbf{u}_{i}\right)+\mathcal{L}_{\text {PseudoLabel }}\left(\mathbf{u}_{i}\right)\right)$
其中:$c_{i}=\max \hat{\mathbf{p}}_{i}$;
总目标:
$\mathcal{L}_{S}(\mathcal{X})+\lambda_{u} \mathcal{L}_{U}(\mathcal{U})+\lambda_{r} \mathcal{L}_{R o t}(\mathcal{X} \cup \mathcal{U})$
- Semi-Supervised Regularization Consistency Revisiting Supervisedsemi-supervised regularization consistency revisiting supervised semi-supervised regularization adversarial semi-supervised consistency adaptation supervised fixmatch semi-supervised consistency simplifying semi-supervised lstm-autoencoder semi-supervised autoencoder semi-supervised supervised laplacian learning ecacl semi-supervised adaptation supervised mixmatch semi-supervised supervised holistic semi-supervised convolutional supervised insights