
发表时间:2015(Deep Reinforcement Learning Workshop, NIPS 2015)
文章要点:这篇文章基于DDPG探索了buffer里面experience的组成对性能的影响。一个重要的观点是,次优的经验也是有利于训练的,少了这些experience会很大程度影响性能(the importance of negative experiences that are not close to an optimal policy.
training with samples that are insufficiently spread over the state-action space can cause the method to fail.
when the neural network training data are not varied enough, the network is likely to over fit)。
作者分别直接训DDPG,用随机收集的样本训DDPG,以及用最好的policy收集的样本训DDPG,发现只用最好的policy收集的样本训练的效果是最差的
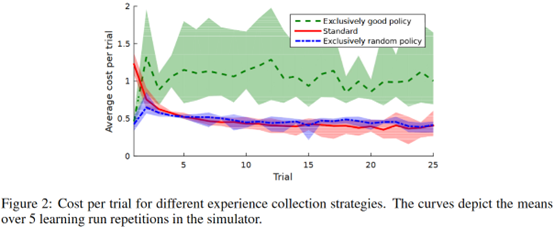
作者又做了另一个实验来说明多样性的问题,如下图
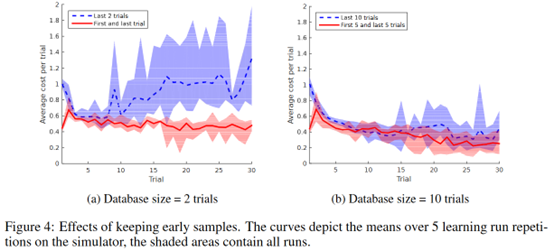
只保留两条最后的轨迹作为训练样本,或者保留一条最开始的和一条最后的。发现存了最开的trial的效果更好,也就是说还是要多样化的样本更好,这样能避免网络overfit。
总结:简单的实验,取了两个极端的变量来做测试,结论至少在简单的实验上是有道理的。扩展到更复杂的任务可能会有点问题,就像之前的paper说的,可能最开的样本已经偏离当前policy很多了,用这个更新可能用处不大。既要考虑多样性,也要考虑on policy才行。
最近感觉,coverage不够造成的主要的问题还是外推误差(extrapolation error),只要用in distribution的更新方式去学value,应该就不会有前面的问题了。
疑问:无。
- reinforcement composition importance experience databasereinforcement composition importance experience reinforcement minimization experience off-policy likelihood-free experience likelihood importance composite composition compositionality reinforcement architecture composite vdm layering compositionality measuring narrowing language springsecurity configuration composition annotation