PointerNet_Chinese_Information_Extraction
代码地址:https://github.com/taishan1994/PointerNet_Chinese_Information_Extraction
利用指针网络进行信息抽取,包含命名实体识别、关系抽取、事件抽取。
整体结构:
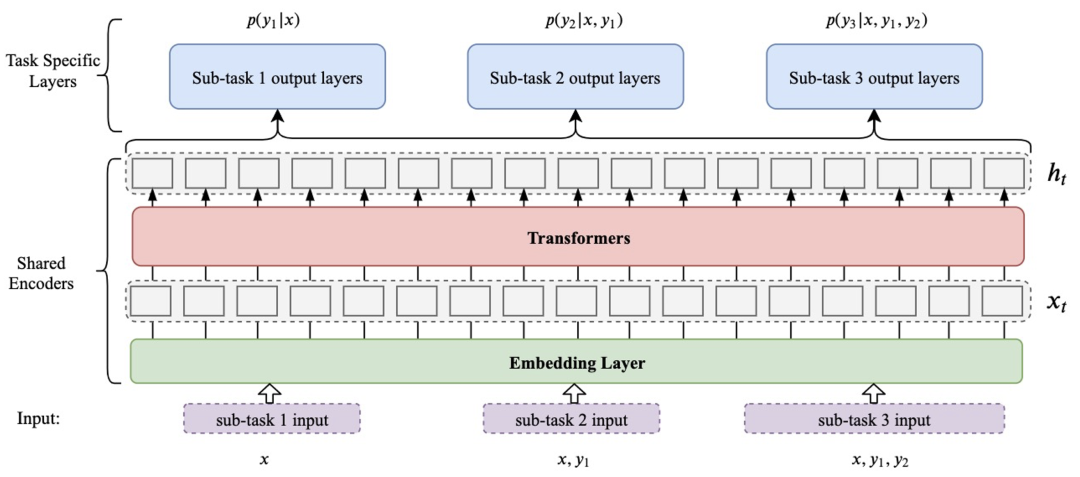
整个目录结构非常简洁,
--[ee/ner/re]_main.py为主运行程序,包含训练、验证、测试和预测。
--[ee/ner/re]_data_loader.py为数据加载模型。
--[ee/ner/re]_predictor.py是联合预测的文件。
--config.py:配置文件,实体识别、关系抽取、事件抽取参数配置。
--model.py是模型。
前期准备,在hugging face上下载chinese-bert-wwm-ext到model_hub/chinese-bert-wwm-ext文件夹下。
依赖
pytorch
transformers
命名实体识别任务
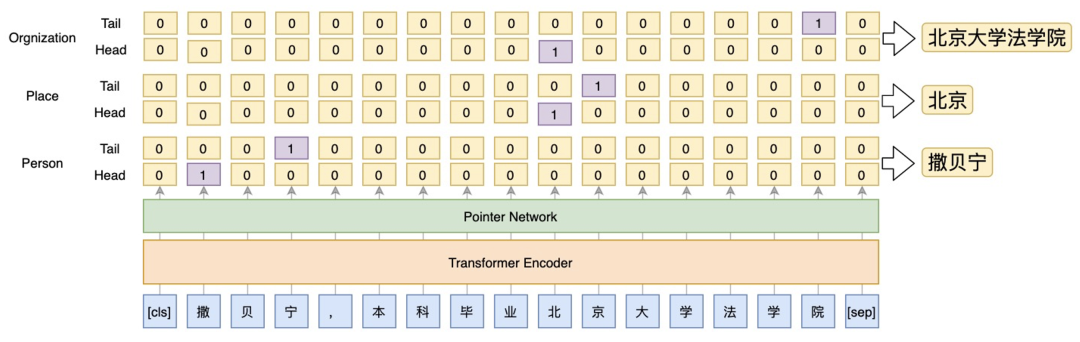
识别每一个类型实体的首位置和尾位置。数据位于data/ner/cner/下,数据的具体格式是:
[
{
"id": 0,
"text": "高勇:男,中国国籍,无境外居留权,",
"labels": [
[
"T0",
"NAME",
0,
2,
"高勇"
],
[
"T1",
"CONT",
5,
9,
"中国国籍"
]
]
},
...
]
运行:python ner_main.py,可进行训练、验证、测试和预测,如若只需要部分的功能,注释相关代码即可。结果:
[eval] precision=0.9471 recall=0.9389 f1_score=0.9430
precision recall f1-score support
TITLE 0.94 0.93 0.94 854
RACE 1.00 1.00 1.00 14
CONT 1.00 1.00 1.00 28
ORG 0.94 0.93 0.93 571
NAME 1.00 1.00 1.00 112
EDU 0.99 0.97 0.98 115
PRO 0.89 0.91 0.90 35
LOC 1.00 0.83 0.91 6
micro-f1 0.95 0.94 0.94 1735
顾建国先生:研究生学历,正高级工程师,现任本公司董事长、马钢(集团)控股有限公司总经理。
{'TITLE': [('正高级工程师', 12), ('董事长', 24), ('总经理', 40)], 'ORG': [('本公司', 21)], 'NAME': [('顾建国', 0)], 'EDU': [('研究生学历', 6)]}
关系抽取任务
该任务只要由四个部分组成:实体识别、主体抽取、主体-客体抽取、关系分类。由于GPU的限制,在re_main.py里面加载验证和测试数据时限制了取10000条,可自行修改。
实体识别
用于识别出主体或者客体的类型。实体识别是可选的,因为有的数据是不需要识别实体的。
主体抽取
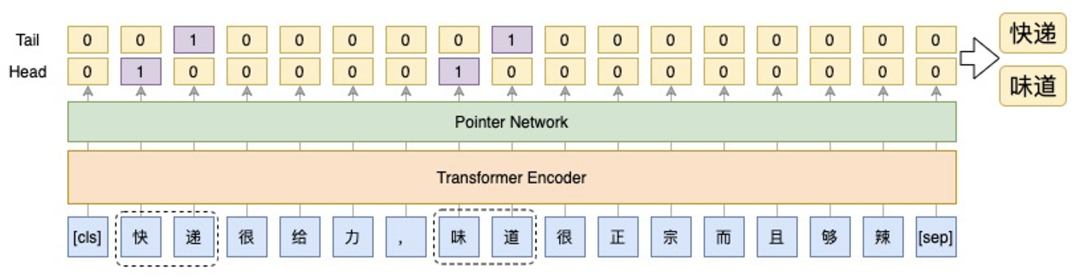
主体抽取是实体识别类似,只不过这里只有一类,识别主体的首、尾位置。
主体-客体抽取
客体抽取要首先知道主体,然后输入是:[CLS]主体[SEP]文本[SEP]。同样的,抽取的是客体的首、尾位置。
关系分类
关系分类采用的是多标签分类,因为主客体之间可能存在多个关系,输入是:[CLS]主体[SEP]客体[SEP]文本[SEP]。注意这里是对整个句子进行分类,不再是token级别的了。
数据位于data/re/ske/下,数据的具体格式为:
[{"tokens": ["《", "步", "步", "惊", "心", "》", "改", "编", "自", "著", "名", "作", "家", "桐", "华", "的", "同", "名", "清", "穿", "小", "说", "《", "甄", "嬛", "传", "》", "改", "编", "自", "流", "潋", "紫", "所", "著", "的", "同", "名", "小", "说", "电", "视", "剧", "《", "何", "以", "笙", "箫", "默", "》", "改", "编", "自", "顾", "漫", "同", "名", "小", "说", "《", "花", "千", "骨", "》", "改", "编", "自", "f", "r", "e", "s", "h", "果", "果", "同", "名", "小", "说", "《", "裸", "婚", "时", "代", "》", "是", "月", "影", "兰", "析", "创", "作", "的", "一", "部", "情", "感", "小", "说", "《", "琅", "琊", "榜", "》", "是", "根", "据", "海", "宴", "同", "名", "网", "络", "小", "说", "改", "编", "电", "视", "剧", "《", "宫", "锁", "心", "玉", "》", ",", "又", "名", "《", "宫", "》", "《", "雪", "豹", "》", ",", "该", "剧", "改", "编", "自", "网", "络", "小", "说", "《", "特", "战", "先", "驱", "》", "《", "我", "是", "特", "种", "兵", "》", "由", "红", "遍", "网", "络", "的", "小", "说", "《", "最", "后", "一", "颗", "子", "弹", "留", "给", "我", "》", "改", "编", "电", "视", "剧", "《", "来", "不", "及", "说", "我", "爱", "你", "》", "改", "编", "自", "匪", "我", "思", "存", "同", "名", "小", "说", "《", "来", "不", "及", "说", "我", "爱", "你", "》"], "entities": [{"type": "图书作品", "start": 1, "end": 5}, {"type": "人物", "start": 13, "end": 15}, {"type": "图书作品", "start": 23, "end": 26}, {"type": "人物", "start": 30, "end": 33}, {"type": "图书作品", "start": 44, "end": 49}, {"type": "人物", "start": 53, "end": 55}, {"type": "图书作品", "start": 60, "end": 63}, {"type": "人物", "start": 67, "end": 74}, {"type": "图书作品", "start": 79, "end": 83}, {"type": "人物", "start": 85, "end": 89}, {"type": "图书作品", "start": 99, "end": 102}, {"type": "人物", "start": 106, "end": 108}, {"type": "影视作品", "start": 132, "end": 134}, {"type": "作品", "start": 146, "end": 150}, {"type": "影视作品", "start": 152, "end": 157}, {"type": "作品", "start": 167, "end": 176}, {"type": "影视作品", "start": 183, "end": 190}, {"type": "图书作品", "start": 183, "end": 190}, {"type": "人物", "start": 194, "end": 198}], "relations": [{"type": "作者", "head": 4, "tail": 5}, {"type": "改编自", "head": 14, "tail": 15}, {"type": "作者", "head": 0, "tail": 1}, {"type": "作者", "head": 2, "tail": 3}, {"type": "作者", "head": 6, "tail": 7}, {"type": "作者", "head": 8, "tail": 9}, {"type": "作者", "head": 10, "tail": 11}, {"type": "改编自", "head": 12, "tail": 13}, ... ]
运行:python re_main.py,可进行训练、验证、测试和预测,如若只需要部分的功能,注释相关代码即可。需要注意的是,我们要在config.py里面设置ReArgs类里面的tasks=["ner or sbj or obj or rel"]来选择相应的子任务。结果:
# 实体识别
test】 precision=0.7862 recall=0.8263 f1_score=0.8057
precision recall f1-score support
行政区 0.33 0.17 0.22 6
人物 0.81 0.91 0.85 1405
气候 0.00 0.00 0.00 3
文学作品 0.00 0.00 0.00 5
Text 0.65 0.64 0.65 56
学科专业 0.00 0.00 0.00 0
作品 0.00 0.00 0.00 8
奖项 0.00 0.00 0.00 14
国家 0.90 0.61 0.73 62
电视综艺 0.69 0.88 0.77 25
影视作品 0.77 0.79 0.78 253
企业 0.69 0.62 0.66 125
语言 0.00 0.00 0.00 1
歌曲 0.87 0.81 0.84 159
Date 0.82 0.87 0.84 127
企业/品牌 0.00 0.00 0.00 3
地点 0.88 0.29 0.44 24
Number 0.79 0.83 0.81 23
图书作品 0.76 0.81 0.78 179
景点 0.00 0.00 0.00 2
城市 0.00 0.00 0.00 4
学校 0.69 0.83 0.76 65
音乐专辑 0.70 0.81 0.75 32
机构 0.69 0.75 0.72 107
micro-f1 0.79 0.83 0.81 2688
《父老乡亲》是由是由由中国人民解放军海政文工团创作的军旅歌曲,石顺义作词,王锡仁作曲,范琳琳演唱
{'人物': [('石顺义', 31), ('王锡仁', 37), ('范琳琳', 43)], '歌曲': [('父老乡亲', 1)]}
# 主体抽取
【test】 precision=0.8090 recall=0.8466 f1_score=0.8273
precision recall f1-score support
主体 0.81 0.85 0.83 2646
micro-f1 0.81 0.85 0.83 2646
# 客体抽取
【test】 precision=0.8017 recall=0.5274 f1_score=0.6362
precision recall f1-score support
客体 0.80 0.53 0.64 1771
micro-f1 0.80 0.53 0.64 1771
# 关系多标签分类
【test】 precision=0.9302 recall=0.9187 f1_score=0.9244
precision recall f1-score support
编剧 0.79 0.59 0.68 44
修业年限 0.00 0.00 0.00 0
毕业院校 1.00 0.98 0.99 49
气候 1.00 1.00 1.00 3
配音 1.00 1.00 1.00 18
注册资本 1.00 1.00 1.00 5
成立日期 1.00 1.00 1.00 94
父亲 0.91 0.95 0.93 88
面积 1.00 1.00 1.00 1
专业代码 0.00 0.00 0.00 0
作者 0.94 0.97 0.96 188
首都 0.00 0.00 0.00 2
丈夫 0.88 0.93 0.90 86
嘉宾 0.63 0.89 0.74 19
官方语言 0.00 0.00 0.00 1
作曲 0.75 0.69 0.72 52
号 1.00 1.00 1.00 10
票房 1.00 1.00 1.00 11
简称 1.00 0.93 0.97 15
母亲 0.82 0.75 0.78 53
制片人 0.86 0.75 0.80 8
导演 0.94 0.95 0.95 101
歌手 0.91 0.87 0.89 119
改编自 0.00 0.00 0.00 11
海拔 1.00 1.00 1.00 1
占地面积 1.00 1.00 1.00 3
出品公司 0.95 0.97 0.96 39
上映时间 1.00 1.00 1.00 37
所在城市 1.00 1.00 1.00 2
主持人 0.91 0.78 0.84 27
作词 0.74 0.67 0.70 51
人口数量 1.00 1.00 1.00 2
祖籍 1.00 1.00 1.00 7
校长 1.00 1.00 1.00 16
朝代 1.00 1.00 1.00 36
主题曲 1.00 0.96 0.98 23
获奖 1.00 1.00 1.00 14
代言人 1.00 1.00 1.00 3
主演 0.97 0.99 0.98 239
所属专辑 1.00 1.00 1.00 35
饰演 1.00 1.00 1.00 17
董事长 1.00 0.96 0.98 56
主角 0.67 0.80 0.73 5
妻子 0.89 0.88 0.89 86
总部地点 1.00 1.00 1.00 16
国籍 1.00 1.00 1.00 67
创始人 0.85 1.00 0.92 11
邮政编码 0.00 0.00 0.00 0
没有关系 0.00 0.00 0.00 0
micro avg 0.93 0.92 0.92 1771
macro avg 0.80 0.80 0.80 1771
weighted avg 0.92 0.92 0.92 1771
samples avg 0.91 0.92 0.92 1771
事件抽取
事件抽取由两个部分组成:事件类型抽取、事件论元抽取。
事件类型抽取
可以当作实体识别。
事件论元抽取
可以当作obj的抽取,输入为:[CLS]事件类型对应的论元[SEP]文本[SEP]。
数据位于data/ee/duee/下,数据格式为:
{"text": "消失的“外企光环”,5月份在华裁员900余人,香饽饽变“臭”了", "id": "cba11b5059495e635b4f95e7484b2684", "event_list": [{"event_type": "组织关系-裁员", "trigger": "裁员", "trigger_start_index": 15, "arguments": [{"argument_start_index": 17, "role": "裁员人数", "argument": "900余人", "alias": []}, {"argument_start_index": 10, "role": "时间", "argument": "5月份", "alias": []}], "class": "组织关系"}]}
每一行是一条记录。
运行:python ee_main.py,可进行训练、验证、测试和预测,如若只需要部分的功能,注释相关代码即可。需要注意的是,我们要在config.py里面设置EeArgs类里面的tasks=["ner or obj"]来选择相应的子任务。结果:
# 事件类型抽取
【test】 precision=0.8572 recall=0.8587 f1_score=0.8579
precision recall f1-score support
财经/交易-出售/收购 0.88 0.88 0.88 24
财经/交易-跌停 0.93 0.87 0.90 15
财经/交易-加息 1.00 1.00 1.00 3
财经/交易-降价 1.00 0.70 0.82 10
财经/交易-降息 1.00 1.00 1.00 4
财经/交易-融资 0.93 0.81 0.87 16
财经/交易-上市 1.00 0.75 0.86 8
财经/交易-涨价 1.00 0.60 0.75 5
财经/交易-涨停 1.00 1.00 1.00 28
产品行为-发布 0.85 0.87 0.86 153
产品行为-获奖 0.59 0.62 0.61 16
产品行为-上映 0.91 0.91 0.91 35
产品行为-下架 1.00 0.96 0.98 24
产品行为-召回 0.95 1.00 0.97 36
交往-道歉 0.73 1.00 0.84 19
交往-点赞 0.85 1.00 0.92 11
交往-感谢 0.78 0.88 0.82 8
交往-会见 0.90 1.00 0.95 9
交往-探班 1.00 0.82 0.90 11
竞赛行为-夺冠 0.71 0.74 0.72 65
竞赛行为-晋级 0.89 0.89 0.89 36
竞赛行为-禁赛 0.88 0.78 0.82 18
竞赛行为-胜负 0.82 0.79 0.81 271
竞赛行为-退赛 0.85 0.94 0.89 18
竞赛行为-退役 0.92 1.00 0.96 11
人生-产子/女 0.85 0.73 0.79 15
人生-出轨 1.00 0.75 0.86 4
人生-订婚 0.80 0.89 0.84 9
人生-分手 0.89 0.89 0.89 18
人生-怀孕 1.00 0.88 0.93 8
人生-婚礼 0.75 1.00 0.86 6
人生-结婚 0.86 0.86 0.86 43
人生-离婚 0.95 0.95 0.95 38
人生-庆生 0.71 0.75 0.73 16
人生-求婚 0.91 1.00 0.95 10
人生-失联 0.77 0.71 0.74 14
人生-死亡 0.83 0.84 0.84 107
司法行为-罚款 0.94 0.88 0.91 33
司法行为-拘捕 0.87 0.92 0.90 90
司法行为-举报 0.86 1.00 0.92 12
司法行为-开庭 0.81 0.93 0.87 14
司法行为-立案 0.80 0.89 0.84 9
司法行为-起诉 0.76 0.90 0.83 21
司法行为-入狱 0.86 0.86 0.86 21
司法行为-约谈 0.97 1.00 0.99 33
灾害/意外-爆炸 1.00 0.80 0.89 10
灾害/意外-车祸 0.75 0.77 0.76 35
灾害/意外-地震 0.88 0.75 0.81 20
灾害/意外-洪灾 0.67 0.57 0.62 7
灾害/意外-起火 0.93 0.86 0.89 29
灾害/意外-坍/垮塌 1.00 0.91 0.95 11
灾害/意外-袭击 0.71 0.71 0.71 17
灾害/意外-坠机 0.85 0.85 0.85 13
组织关系-裁员 1.00 0.82 0.90 22
组织关系-辞/离职 0.84 0.97 0.90 71
组织关系-加盟 0.89 0.74 0.80 53
组织关系-解雇 0.85 0.85 0.85 13
组织关系-解散 1.00 1.00 1.00 10
组织关系-解约 0.83 1.00 0.91 5
组织关系-停职 1.00 1.00 1.00 11
组织关系-退出 0.77 0.77 0.77 22
组织行为-罢工 0.89 1.00 0.94 8
组织行为-闭幕 1.00 1.00 1.00 9
组织行为-开幕 0.91 0.97 0.94 30
组织行为-游行 0.89 0.67 0.76 12
micro-f1 0.86 0.86 0.86 1783
富国银行收缩农业与能源贷款团队 裁减200多名银行家
{'组织关系-裁员': [('裁减', 16)]}
# 事件论元抽取
【test】 precision=0.7829 recall=0.7406 f1_score=0.7612
precision recall f1-score support
答案 0.78 0.74 0.76 3682
micro-f1 0.78 0.74 0.76 3682
富国银行收缩农业与能源贷款团队 裁减200多名银行家
组织关系-裁员_裁员方
['富国银行']
联合预测
实体识别预测
python ner_predictor.py
文本: 顾建国先生:研究生学历,正高级工程师,现任本公司董事长、马钢(集团)控股有限公司总经理。
实体:
TITLE [('正高级工程师', 12), ('董事长', 24), ('总经理', 40)]
ORG [('本公司', 21)]
NAME [('顾建国', 0)]
EDU [('研究生学历', 6)]
关系抽取预测
python re_predictor.py
文本: 《神之水滴》改编自亚树直的同名漫画,是日本电视台2009年1月13日制作并播放的电视剧,共九集
实体:
人物 [('亚树直', 9)]
影视作品 [('神之水滴', 1)]
Date [('2009年1月13日', 24)]
主体: ['神之水滴', '亚树直', '日本电视台2009年1月13日', '2009年1月13日']
客体: [['神之水滴', '2009年1月13日'], ['亚树直', '2009年1月13日'], ['日本电视台2009年1月13日', '2009年1月13日'], ['2009年1月13日', '2009年1月13日']]
关系: [('神之水滴', '上映时间', '2009年1月13日'), ('亚树直', '上映时间', '2009年1月13日'), ('日本电视台2009年1月13日', '上映时间', '2009年1月13日'), ('2009年1月13日', '上映时间', '2009年1月13日')]
效果不是很好,因为数据集太大,这里只选取了训练集里面的10000条数据,训练了不到3个epoch,GPU足够的可以尝试数据多点,训练就一些。
事件抽取预测
python ee_predictor.py
文本: 2019年7月12日,国家市场监督管理总局缺陷产品管理中心,在其官方网站和微信公众号上发布了《上海施耐德低压终端电器有限公司召回部分剩余电流保护装置》,看到这条消息,确实令人震惊!
作为传统的三大外资品牌之一,竟然发生如此大规模质量问题的召回,而且生产持续时间长达一年!从采购,检验,生产,测试,包装,销售,这么多环节竟没有反馈出问题,处于无人知晓状态,问题出在哪里?希望官方能有一个解释了。
实体:
产品行为-召回 [('召回', 62), ('召回', 119)]
事件类型: 产品行为-召回
实体: [['产品行为-召回_时间', '2019年7月12日'], ['产品行为-召回_召回内容', '部分剩余电流保护装置'], ['产品行为-召回_召回方', '上海施耐德低压终端电器有限公司']]
补充
Q:怎么训练自己的数据?
A:参考每一个实例下面数据的格式。
Q:评价指标一直为0?
A:指针网络的收敛速度挺慢的,耐心等待。
Q:怎么进行观点评论抽取?
A:同样的可以转换任务为:ner、sbj、obj、rel。比如实体识别就是识别出文本里面的方面及评价,主体识别就是方面,客体识别就是评价,关系分类就是评价的情感,不过这里要做修改,因为不是多标签分类,而是多分类。
这里不提供训练好的模型了,自行训练即可。
参考
一种基于Prompt的通用信息抽取(UIE)框架_阿里技术的博客-CSDN博客 (思想和大部分图片都来自这)