正则表达式
shell :/bin/bash
正则表达式:匹配的是 文章中的字符
通配符:匹配的是文件名 ? 任意单个字符
元字符:不表示本来的含义,在正则表达式中有特殊含义的字符
正则表达式元字符的使用:自己写很容易,读取别人的很困难
正则表达式想用好:
-
记忆元字符的含义
-
多用
正则表达式分为:
- 代表字符
- 表示次数
- 位置锚定
- 分组 或
- 基本正则表达式
- 扩展正则表达式
代表字符
. :表示单个任意字符 [ ]:表示单个字符 [abc] :匹配的是 a b c [[:space:]]:表示空格,制表符 [[:alnum:]]:表示字母和数字 [[:alpha:]]:表示任何英文的大小写,亦a-z,A-Z [^]:表示取反,匹配指定范围外的任意字符
表示次数
*:表示前面的字符出现0到正无穷次,包括0次 . *:表示任意长度,不包括0次 \?:表示0或1次,可有可无 \+表示1次到正无穷 \{3\}:表示前面的字符出现3次 \{n\} \{3,5}:表示前面的字符出现3到5次
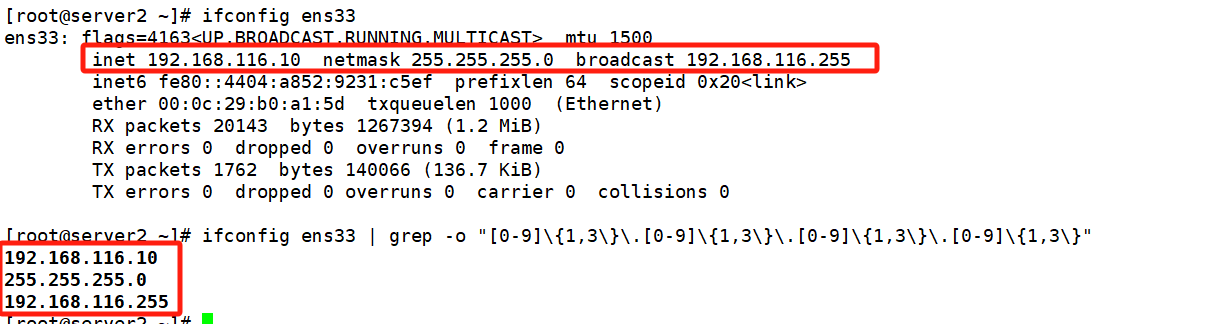
#将网卡信息提取出来
位置锚定
^:开头 $:结尾 \b:字符串的开头\< \b:字符串的结尾\>
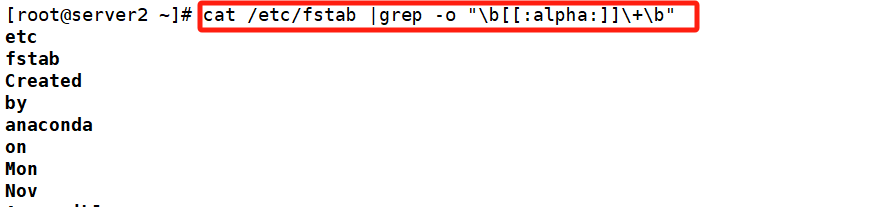
#字符串的开头与字符串的结尾
分组 或
分组( ):就是用括号将需要组合的字符括起来
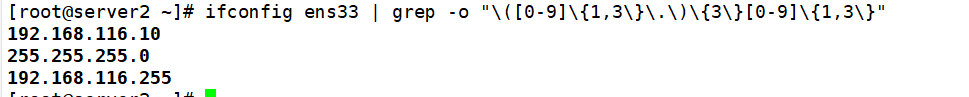
扩展正则表达式
就是将斜杠去掉
表示次数: * 匹配任意字符,任意次 ? 0或1次 + 1次或多次 {n} 匹配n次 {m,n} 至少m次,最多n次 {,n} 匹配前面的字符至多n次,<=n n可以为0 表示分组: 分组:( )将多个字符捆绑在一起,当作一个整体处理 向后引用:\1,\2.... | 或者 a|b a或者b

#表示qq号

#表示邮箱

#表示手机号
grep
grep [选项]...查找条件 目标文件
-color=auto 对匹配到的文本着色显示 -m # 匹配#次后停止 grep -m 1 root /etc/passwd #多个匹配只取第一个 -v 显示不被pattern匹配到的行,即取反 grep -Ev '^[[:space:]]*#|^$' /etc/fstab -i 忽略字符大小写 -n 显示匹配的行号 -c 统计匹配的行数 grep -c root /etc/passwd #统计匹配到的行数 -o 仅显示匹配到的字符串 -q 静默模式,不输出任何信息 -A # after, 后#行 grep -A3 root /etc/passwd #匹配到的行后3行业显示出来 -B # before, 前#行 -C # context, 前后各#行 -e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file grep -e root -e bash /etc/passwd #包含root或者包含bash 的行 grep -E root|bash /etc/passwd -w 匹配整个单词 grep -w root /etc/passwd useradd rooter -E 使用ERE,相当于egrep -F 不支持正则表达式,相当于fgrep -f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件 -r 递归目录,但不处理软链接 -R 递归目录,但处理软链接

#过滤出以b开头,以/结尾的内容
面试题:
统计当前主机的连接状态
ss -nta | grep -v '^state'|cut -d" " -f1|sort |uniq -c

统计当前连接的主机数
ss -nta | tr -s " " |cut -d" " -f5|cut -d ":" -f1 |sort |uniq -c

sed
sed [选项]... {脚本(如果没有其他脚本)} [输入文件]
常用选项: -n 不输出模式空间内容到屏幕,即不自动打印 -e 多点编辑[root@www data]#sed -n -e '/^r/p' -e'/^b/p' /etc/passwd -f FILE 从指定文件中读取编辑脚本 -r, -E 使用扩展正则表达式 -i.bak 备份文件并原处编辑 #说明: -ir 不支持 -i -r 支持 -ri 支持 -ni 会清空文件

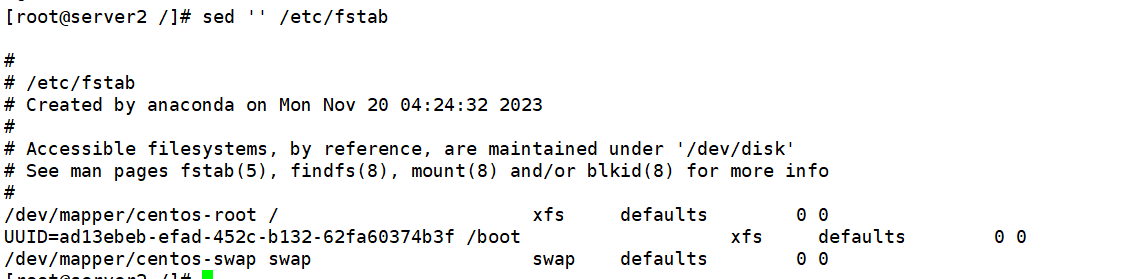
#将查看的内容打印出来
awk:
ask是一种文本处理工具
awk:加载一行处理一行
vim:把整个文件加载到内存中处理,如果内存不足,无法打开文件
ask 选项 ‘表达式{处理动作}’
选项: -F:指定分隔符 -v:指定变量 表达式:(program) awk的语言的表达式 不写就是没有 找到特定的行 处理动作: print 打印 printf 打印
$0 全文
$1 第一列
$2 第二列
awk 内置变量和 shell 环境中的变量会有冲突 ‘{}’

默认是以空格为分隔符
awk常见的内置变量
FS:指定每行文本的字段分隔符,缺省默认为空格和制表符(tab) 与-F作用相同 -v "FS=:" OFS:输出时的分隔符 NF:当前处理的行的字段个数 #字段的个数,倒数第一列 $NF 倒数第二列$(NF-1) NR:当前处理的行的行号(序数) #NR==2 只显示第二行 $0:当前处理的行的整行内容 $n:当前处理行的第n个字段(第n列)
FS:
awk -v FS=':' '{print $1FS$3}' /etc/passwd #此处FS 相当于变量 -v 变量赋值

NF:
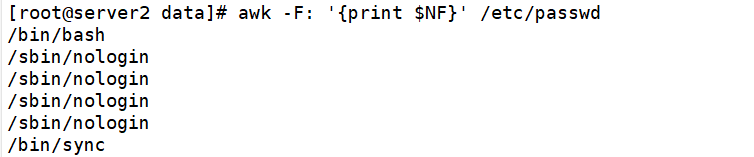
awk -F:'{print NF}' /etc/passwd #表示字段 awk -F:'{print $NF}' /etc/passwd #$NF表示最后一个字段

NR:
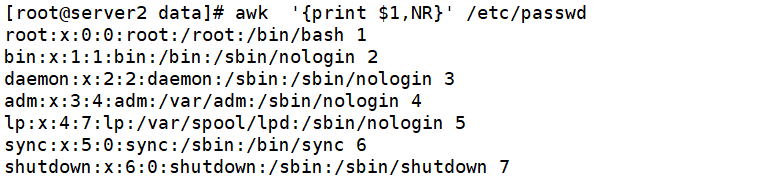
awk '{print $1,NR}' /etc/passwd #NR 表示当前处理的行号 awk 'NR==2{print $1}' /etc/passwd #只取第二行的第一个字段

面试题:
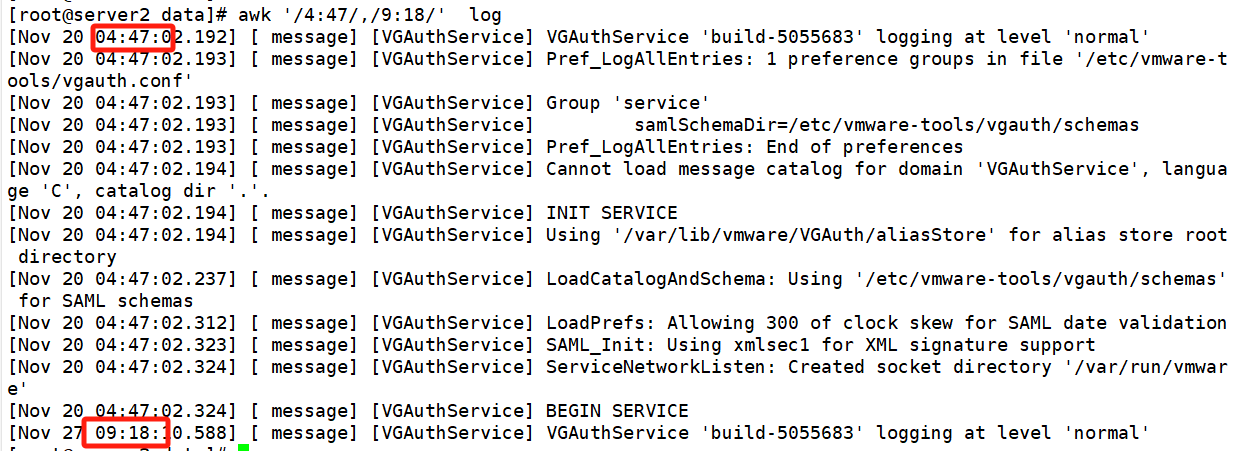
找到4:47到9:18的日志
awk '/4:47/,/9:18/' log
找取奇数行和偶数行
seq 10 | awk 'i=!i' #奇数行 seq 10 | awk '!(i=!i)' #偶数行

使用for循环计算1到100的和
awk 'BEGIN{sum=0;for(i=0;i<=100;i++){sum+=i}print sum}'
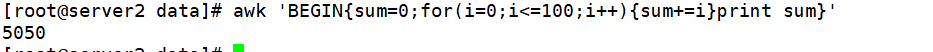
awk 数组计算
awk 建立数组 awk 'BEGIN{a[1]="lisi";a[2]="liwu";print a[1],a[2]}' awk 'BEGIN{a[1]="lisi";a[2]="liwu";for(i in a)print a[i]}'

统计/etc/fstab文件中每个文件系统类型出现的次数
cat /etc/fstab | grep -v '^#' | grep -v '^$' | awk '{print $3}' |sort | uniq -c

统计/etc/fstab文件中的每个真单词
grep -Eo "\b[a-zA-Z]+\b" /etc/fstab | wc -l
查出/tmp/的权限,以数字方式显示
stat /tmp/ |awk -F"[(/]" 'NR==4{print $2}'

查出用户UID最大值的用户名、UID及shell类型
cat /etc/passwd |sort -t: -k3 -n |tail -n1
