生成式大语言模型(LLM)可以针对各种用户的 prompt 生成高度流畅的回复。然而,大模型倾向于产生幻觉或做出非事实陈述,这可能会损害用户的信任。
大语言模型的长而详细的输出看起来很有说服力,但是这些输出很有可能是虚构的。这是否意味着我们不能信任聊天机器人,每次都必须手动检查输出的事实?有一些方法可以让聊天机器人在适当的保护措施下不太可能说假话。
一个最简单的方法就是调整temperature到一个很大的值,例如0.7,然后使用相同的提问多次对话。这样得到的输出应该只会改变句子的结构,输出之间的差异应该只是语义上的,而不是事实上的。
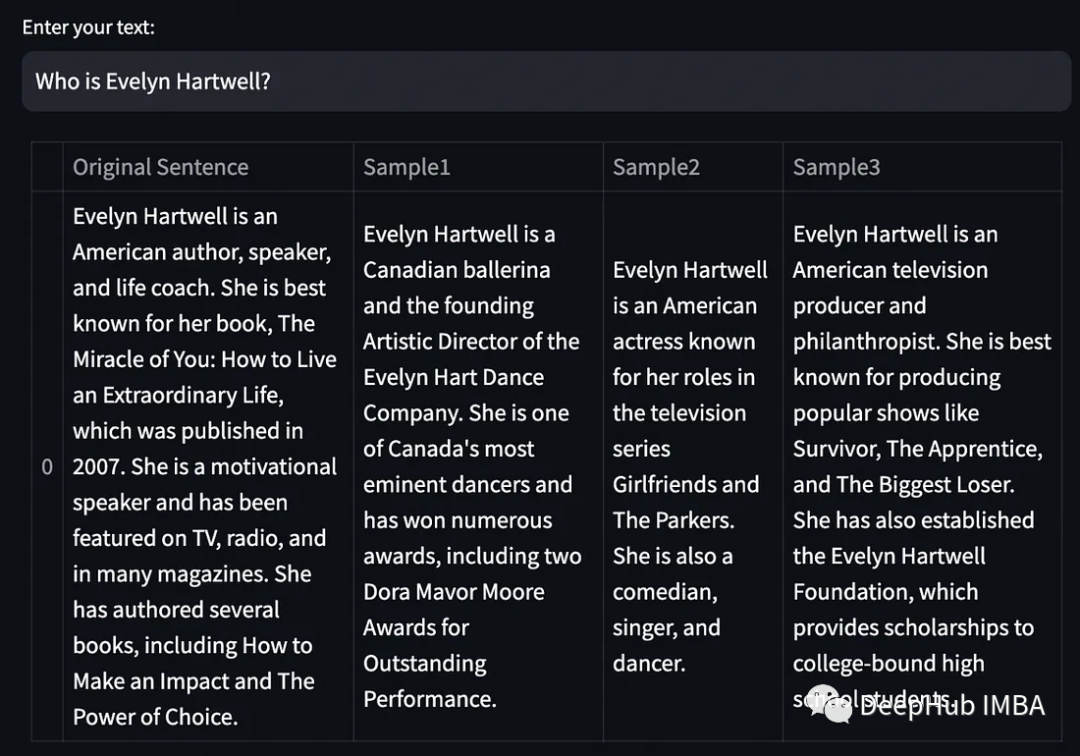
这个简单的想法允许引入一种新的基于样本的幻觉检测机制。如果LLM对同一提示的输出相互矛盾,它们很可能是幻觉。如果它们相互关联,就意味着信息是真实的。对于这种类型的求值,我们只需要llm的文本输出。这被称为黑盒评估。
https://avoid.overfit.cn/post/f32f440c1b99458e86d3e48c70ddcf94