理解赛题,跑通竞赛实践全流程
跑通实践基线Baseline,获得自己的成绩
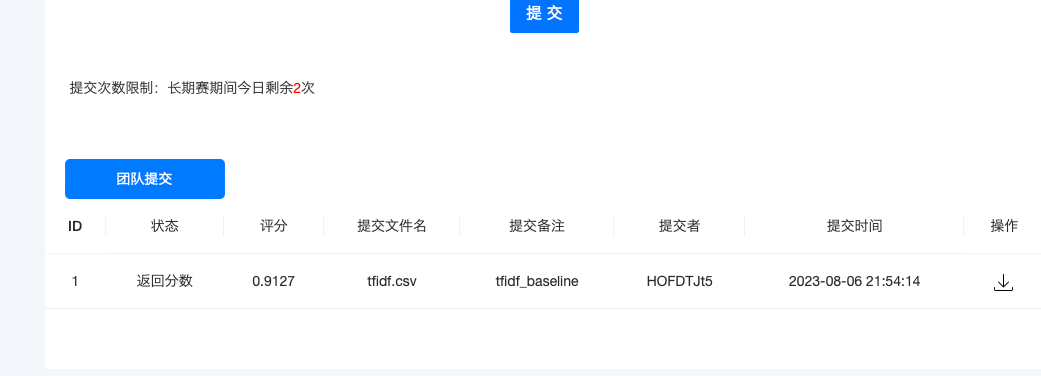
提交任务一打卡,查看个人成绩排行榜
赛题理解
赛题链接
本赛题要求构建一个文本分类器,来区分真实对话和由AI产生的对话,训练的数据包括一系列真实对话和ChatGPT生成的对话样本,参赛选手需要设计并训练一个模型,使其能够准确地将这两种类型的对话进行分类。使用准确率作为评价指标。
baseline代码理解
本赛题是一个文本分类任务
主要分为几个步骤
-
数据收集与预处理: 首先,需要收集用于文本分类的数据集。数据集应包含已标注好的文本样本,每个样本都对应一个预定义的类别或标签。在预处理阶段,对文本数据进行清洗、分词、去除停用词和特殊字符等操作,以便为后续的特征提取和模型训练做准备。
-
特征提取: 特征提取是将文本数据转换为计算机可处理的数值表示的过程。常用的特征提取方法包括词袋模型(Bag of Words)、TF-IDF(词频-逆文档频率)、Word2Vec、BERT(Bidirectional Encoder Representations from Transformers)等。这些方法能够将文本数据转换为向量形式,保留了文本的语义和语法信息。
-
建立分类模型: 在特征提取之后,我们需要选择一个适合的分类模型来训练。常见的分类模型包括朴素贝叶斯(Naive Bayes)、支持向量机(Support Vector Machine, SVM)、逻辑回归(Logistic Regression)、决策树(Decision Tree)、随机森林(Random Forest)和深度学习模型如卷积神经网络(Convolutional Neural Networks, CNN)和循环神经网络(Recurrent Neural Networks, RNN)等。
-
模型训练: 将预处理后的特征数据输入选择的分类模型,并对模型进行训练。在训练过程中,模型根据已标注的数据样本进行学习和优化,调整模型的参数以最小化分类错误。
-
模型评估: 使用测试集来评估训练好的模型的性能。常见的评估指标包括准确率、精确率、召回率、F1 分数等。
-
调优优化: 根据评估结果,可以对模型进行调优优化,以提高模型的性能。调优方法包括调整模型参数、优化特征提取过程、尝试不同的分类模型等。
数据样例
| name | label | content |
|---|---|---|
| 1 | 0 | [4509 3181 1253 2278 290 3562 2051 599 3125 4790 1504 5219 4390 4544 ... ] |
两个baseline的思路
https://aistudio.baidu.com/bj-cpu-01/user/680935/6614735/lab/tree/main.ipynb
思路一:就是人工选取一些特征,然后使用逻辑回归模型进行训练和预测
样例代码
import glob # 导入glob模块,用于查找符合特定规则的文件路径名
import numpy as np # 导入NumPy库,用于数值计算
import pandas as pd # 导入Pandas库,用于数据分析和操作
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
# LogisticRegression原理: https://juejin.cn/post/7192114678812639293
# 读取训练和测试数据
train_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/train.csv') # 读取训练数据
test_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/test.csv') # 读取测试数据
# 移除内容列中的第一个和最后一个字符
train_data['content'] = train_data['content'].apply(lambda x: x[1:-1]) # 移除训练数据中内容列的每个字符串的第一个和最后一个字符
test_data['content'] = test_data['content'].apply(lambda x: x[1:-1]) # 移除测试数据中内容列的每个字符串的第一个和最后一个字符
def simple_feature(s):
if len(s) == 0:
s = '123 123' # 如果字符串为空,则设为'123 123'
w = s.split() # 这行代码将字符串s按照空格分割,得到一个单词列表w。
# 统计字符出现次数
w_count = np.bincount(w)
# 这行代码过滤掉w_count中的0,即过滤掉没有出现过的单词。
w_count = w_count[w_count != 0]
return np.array([
len(s), # 原始字符长度
len(w), # 字符个数
len(set(w)), # 不重复字符个数
len(w) - len(set(w)), # 字符个数 - 不重复字符个数
len(set(w)) / (len(w) + 1), # 不重复字符个数占比
np.max(w_count), # 字符的频率的最大值
np.min(w_count), # 字符的频率的最小值
np.mean(w_count), # 字符的频率的平均值
np.std(w_count), # 字符的频率的标准差
np.ptp(w_count), # 字符的频率的极差
])
# 对训练和测试数据的内容列应用上述特征提取函数
train_feature = train_data['content'].iloc[:].apply(simple_feature) # 对训练数据的内容列应用特征提取函数
test_feature = test_data['content'].iloc[:].apply(simple_feature) # 对测试数据的内容列应用特征提取函数
# 将特征堆叠成NumPy数组(其实形状没有改变)
train_feature = np.vstack(train_feature.values) # 将训练数据的特征堆叠成NumPy数组
test_feature = np.vstack(test_feature.values) # 将测试数据的特征堆叠成NumPy数组
m = LogisticRegression() # 初始化逻辑回归模型
m.fit(train_feature, train_data['label']) # 使用训练数据拟合模型
test_data['label'] = m.predict(test_feature) # 对测试数据进行预测
test_data[['name', 'label']].to_csv('simple.csv', index=None) # 将预测结果保存到CSV文件
思路二:采用TD-IDF统计特征,然后使用逻辑回归模型进行训练和预测
下面的代码选取了三种不同的tf-idf构造,分别是
- 初始化TF-IDF向量化器,设置单词的最小长度为1,最大特征数量为2000
- 初始化TF-IDF向量化器,设置单词的最小长度为1,最大特征数量为5000
- 初始化TF-IDF向量化器,设置单词的最小长度为1,最大特征数量为5000,n-gram范围为1到2
最后的结果是使用第三种的结果
样例代码
# 思路二完整代码如下:
import glob # 导入glob模块,用于查找符合特定规则的文件路径名
import numpy as np # 导入NumPy库,用于数值计算
import pandas as pd # 导入Pandas库,用于数据分析和操作
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.feature_extraction.text import TfidfVectorizer # 导入TF-IDF向量化器,用于将文本数据转换为数值特征
from sklearn.model_selection import cross_val_predict # 导入交叉验证预测函数
from sklearn.metrics import classification_report # 导入分类报告函数,用于评估模型性能
# 读取训练和测试数据
train_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/train.csv') # 读取训练数据
test_data = pd.read_csv('./ChatGPT生成文本检测器公开数据-更新/test.csv') # 读取测试数据
# 移除内容列中的第一个和最后一个字符
train_data['content'] = train_data['content'].apply(lambda x: x[1:-1]) # 移除训练数据中内容列的每个字符串的第一个和最后一个字符
test_data['content'] = test_data['content'].apply(lambda x: x[1:-1]) # 移除测试数据中内容列的每个字符串的第一个和最后一个字符
# 使用第1种TF-IDF参数进行特征提取
tfidf = TfidfVectorizer(token_pattern=r'\w{1}', max_features=2000) # 初始化TF-IDF向量化器,设置单词的最小长度为1,最大特征数量为2000
train_tfidf = tfidf.fit_transform(train_data['content']) # 将训练数据的内容列转换为TF-IDF特征
test_tfidf = tfidf.transform(test_data['content']) # 将测试数据的内容列转换为TF-IDF特征
# 使用交叉验证进行预测,并打印分类报告
print(classification_report(
cross_val_predict(
LogisticRegression(), # 使用逻辑回归模型
train_tfidf, # 训练数据的特征
train_data['label'], # 训练数据的标签
),
train_data['label'], # 真实的训练数据标签
digits=4 # 设置打印的小数位数为4
))
# 使用第2种TF-IDF参数进行特征提取
tfidf = TfidfVectorizer(token_pattern=r'\w{1}', max_features=5000) # 初始化TF-IDF向量化器,设置单词的最小长度为1,最大特征数量为5000
train_tfidf = tfidf.fit_transform(train_data['content']) # 将训练数据的内容列转换为TF-IDF特征
test_tfidf = tfidf.transform(test_data['content']) # 将测试数据的内容列转换为TF-IDF特征
# 使用交叉验证进行预测,并打印分类报告
print(classification_report(
cross_val_predict(
LogisticRegression(), # 使用逻辑回归模型
train_tfidf, # 训练数据的特征
train_data['label'], # 训练数据的标签
),
train_data['label'], # 真实的训练数据标签
digits=4 # 设置打印的小数位数为4
))
# 使用第3种TF-IDF参数进行特征提取
tfidf = TfidfVectorizer(token_pattern=r'\w{1}', max_features=5000, ngram_range=(1,2)) # 初始化TF-IDF向量化器,设置单词的最小长度为1,最大特征数量为5000,n-gram范围为1到2
train_tfidf = tfidf.fit_transform(train_data['content']) # 将训练数据的内容列转换为TF-IDF特征
test_tfidf = tfidf.transform(test_data['content']) # 将测试数据的内容列转换为TF-IDF特征
# 使用交叉验证进行预测,并打印分类报告
print(classification_report(
cross_val_predict(
LogisticRegression(), # 使用逻辑回归模型
train_tfidf, # 训练数据的特征
train_data['label'], # 训练数据的标签
),
train_data['label'], # 真实的训练数据标签
digits=4 # 设置打印的小数位数为4
))
# 使用第3种TF-IDF参数训练逻辑回归模型,并进行预测
m = LogisticRegression() # 初始化逻辑回归模型
m.fit(
train_tfidf, # 训练数据的特征
train_data['label'] # 训练数据的标签
)
test_data['label'] = m.predict(test_tfidf) # 对测试数据进行预测
# 将预测结果保存到CSV文件
test_data[['name', 'label']].to_csv('tfidf.csv', index=None) # 将测试数据的名称和预测标签保存到CSV文件
结果提交